Inner alignment requires making assumptions about human values
4TurnTrout
3Matthew Barnett
5TurnTrout
2Charlie Steiner
1Matthew Barnett
2Donald Hobson
New Comment
I (low-confidence) think that there might be a "choose two" wrt impact measures: large effect, no ontology, no/very limited value assumptions. I see how we might get small good effects without needing a nice pre-specified ontology or info. about human values (AUP; to be discussed in upcoming Reframing Impact posts). I also see how you might have a catastrophe-avoiding agent capable of large positive impacts, assuming an ontology but without assuming a lot about human preferences.
I know this isn't saying why I think this yet, but I'd just like to register this now for later discussion.
I also see how you might have a catastrophe-avoiding agent capable of large positive impacts, assuming an ontology but without assuming a lot about human preferences.
I find this interesting but I'd be surprised if it were true :). I look forward to seeing it in the upcoming posts.
That said, I want to draw your attention to my definition of catastrophe, which I think is different than the way most people use the term. I think most broadly, you might think of a catastrophe as something that we would never want to happen even once. But for inner alignment, this isn't always helpful, since sometimes we want our systems to crash into the ground rather than intelligently optimizing against us, even if we never want them to crash into the ground even once. And as a starting point, we should try to mitigate these malicious failures much more than the benign ones, even if a benign failure would have a large value-neutral impact.
A closely related notion to my definition is the term "unacceptable behavior" as Paul Christiano has used it. This is the way he has defined it,
In different contexts, different behavior might be acceptable and it’s up to the user of these techniques to decide. For example, a self-driving car trainer might specify: Crashing your car is tragic but acceptable. Deliberately covering up the fact that you crashed is unacceptable.
It seems like if we want to come up with a way to avoid these types of behavior, we simply must use some dependence on human values. I can't see how to consistently separate acceptable failures from non-acceptable ones except by inferring our values.
It seems like if we want to come up with a way to avoid these types of behavior, we simply must use some dependence on human values. I can't see how to consistently separate acceptable failures from non-acceptable ones except by inferring our values.
I think people should generally be a little more careful about saying "this requires value-laden information". First, while a certain definition may seem to require it, there may be other ways of getting the desired behavior, perhaps through reframing. Building an AI which only does small things should not require the full specification of value, even though it seems like you have to say "don't do all these bad things we don't like"!
Second, it's always good to check "would this style of reasoning lead me to conclude solving the easy problem of wireheading is value-laden?":
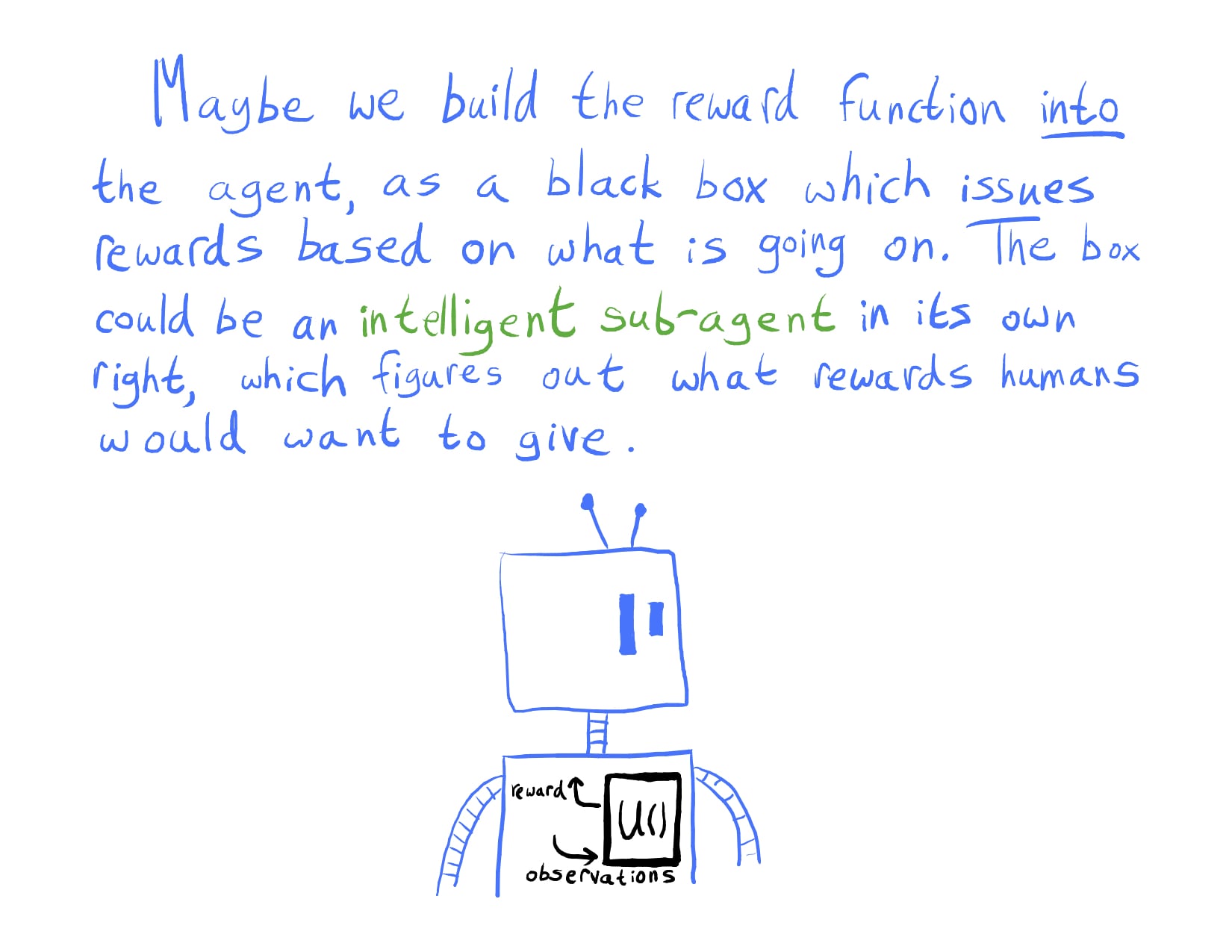

This isn't an object-level critique of your reasoning in this post, but more that the standard of evidence is higher for this kind of claim.
Is your point mostly centered around there being no single correct way to generalize to new domains, but humans have preferences about how the AI should generalize, so to generalize properly, the AI needs to learn how humans want it to do generalization?
The above sentence makes lots of sense to me, but I don't see how it's related to inner alignment (it's just regular alignment), so I feel like I'm missing something.
Is your point mostly centered around there being no single correct way to generalize to new domains, but humans have preferences about how the AI should generalize, so to generalize properly, the AI needs to learn how humans want it to do generalization?
Pretty much, yeah.
The above sentence makes lots of sense to me, but I don't see how it's related to inner alignment
I think there are a lot of examples of this phenomenon in AI alignment, but I focused on inner alignment for two reasons
- There's a heuristic that a solution to inner alignment should be independent of human values, and this argument rebuts that heuristic.
- The problem of inner alignment is pretty much the problem of how to get a system to properly generalize, which makes "proper generalization" fundamentally linked to the idea.
Suppose that in building the AI, we make an explicitly computable hardcoded value function. For instance, if you want the agent to land between the flags, you might write an explicit, hardcoded function that returns 1 if between a pair of yellow triangles, else 0.
In the process of standard machine learning as normal, information is lost because you have a full value function but only train the network using the evaluation of the function at a finite number of points.
Suppose I don't want the lander to land on the astronaut, who is wearing a blue spacesuit. I write code that says that any time there is a blue pixel below the lander, the utility is -10.
Suppose that there are no astronauts in the training environment, in fact nothing blue whatsoever. A system that is trained using some architecture that only relies on the utility of what it sees in training, would not know this rule. A system that can take the code, and read it, would spot this info, but might not care about it. A system that generates potential actions, and then predicts what the screen would look like if it took those actions, and then sent that prediction to the hard coded utility function, with automatic shutdown if the utility is negative, would avoid this problem.
If hypothetically, I can take any programmed function f:observations -> reward and make a machine learning system that optimizes that function, then inner alignment has been solved.
Curated and popular this week