TL;DR: Shard theory is a new research program started by Quintin Pope and Alex Turner. Existing introductions tend to be relatively long winded and aimed at an introductory audience. Here, I outline what I think are the nine main theses of shard theory as of Dec 2022, so as to give a more concrete introduction and critique:
- Agents are well modeled as being made of shards---contextually activated decision influences.
- Shards generally care about concepts inside the agent's world model, as opposed to pure sensory experiences or maximizing reward.
- Active shards bid for plans in a way shaped by reinforcement learning.
- The optimization target is poorly modeled by the reward function.
- Agentic shards will seize power.
- Value formation is very path dependent and relatively architecture independent.
- We can reliably shape an agent's final values by changing the reward schedule.
- "Goal misgeneralization" is not a problem for AI alignment.
- Shard theory is a good model of human value formation.
While I broadly sympathize the intuitions behind shard theory, I raise reservations with each of the theses at the end of the post. I conclude by suggesting areas of future work in shard theory.
Acknowledgements: Thanks to Thomas Kwa for the conversation that inspired this post. Thanks also to Alex Turner for several conversations about shard theory and Charles Foster and Teun Van Der Weij for substantial feedback on this writeup.
Epistemic status: As I’m not a member of Team Shard, I’m probably misrepresenting Team Shard’s beliefs in a few places here.
Introduction
Shard theory is a research program that aims to build a mechanistic model between training signals and learned values in agents. Drawing large amounts of inspiration from particular hypotheses about the human reward learning system, shard theory posits that the values of agents are best understood as sets of contextually activated heuristics shaped by the reward function.
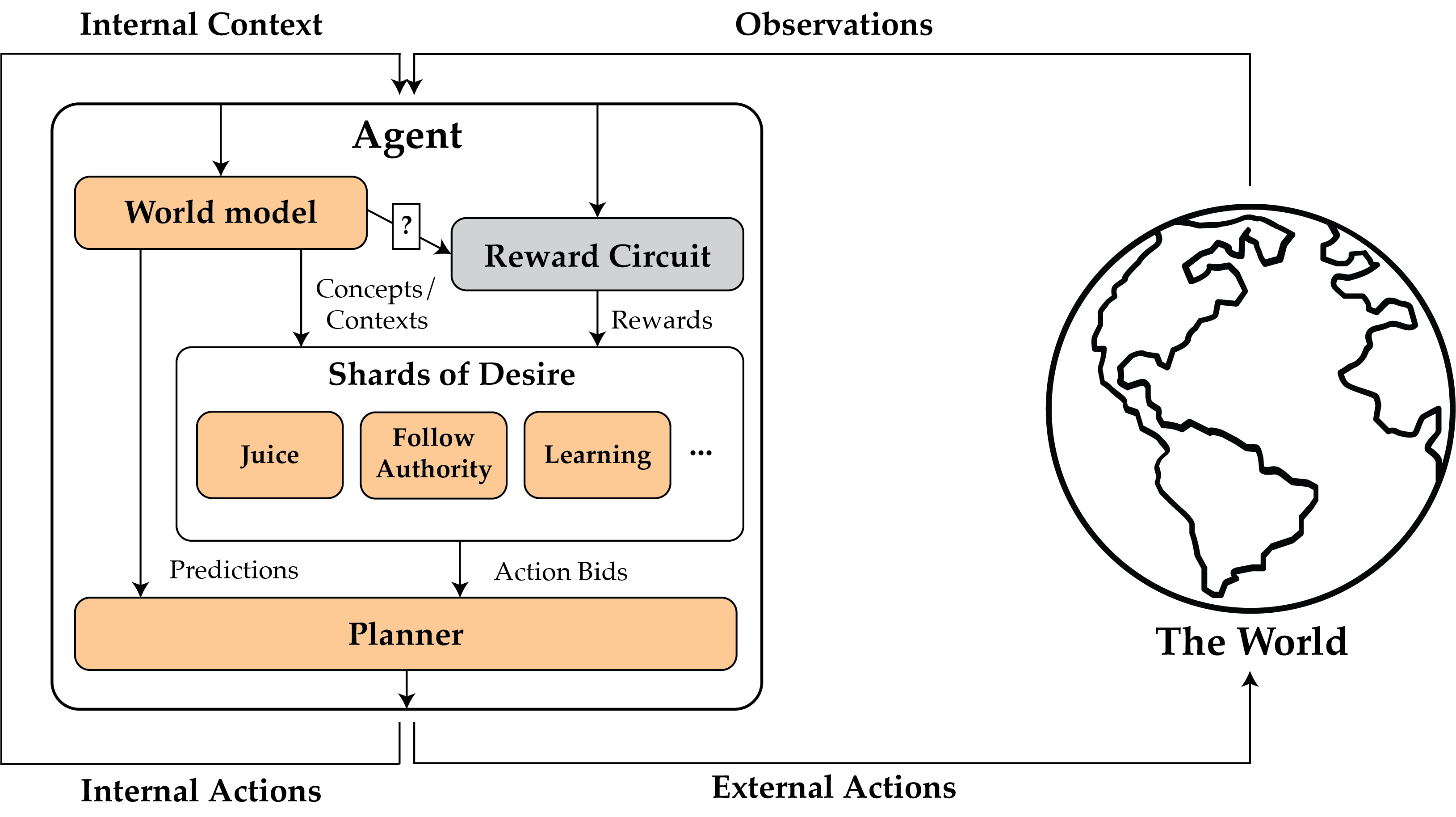
Learned components are orange, while hardcoded components are gray. The question mark on the line between the world model and the reward circuitry is because shard theorists are divided on whether the reward circuitry can depend on the world model.
In this post, I’ll attempt to outline nine of the main theses of shard theory, as of late 2022. I’ll explain the novelty of each thesis, how it constrains expectations, and then give my opinions and suggest some few experiments that could be done to test the theses.
Existing explainers of shard theory tend to be aimed at a relatively introductory audience and thus are relatively verbose. By default, I’ll be addressing this post to someone with a decent amount of AI/ML research background, so I’ll often explain things with reference to AI/ML terminology or with examples from deep learning. This post is aimed primarily at explaining what I see as the core claims, as opposed to justifying them; any missing justifications should not be attributed to failures of Team Shard. It’s also worth noting that shard theory is an ongoing research program and not a battle-tested scientific theory, so many of these claims are likely to be revised or clarified over time.
Related work
Alex Turner’s Reward is not the optimization target is probably the first real “shard theory” post. The post argues that, by default, the learned behavior of an RL agent is not well understood as maximizing reward. Instead, the post argues that we should try to study how reward signals lead to value formation in more detail. He uses a similar argument to argue against the traditional inner and outer alignment split in Inner and outer alignment decompose one hard problem into two extremely hard problems.
David Udell’s Shard Theory: An Overview first introduces the shard theory research program, as well as the terminology and core claims of shard theory. Turner and Pope’s The shard theory of human values applies the shard theory to human value formation. It outlines three assumptions that the shard theory of human values makes regarding humans (the cortex is randomly initialized, the brain does self-supervised learning, and the brain does reinforcement learning). Other posts flesh out parts of the shard theory of human values (e.g. “Human value and biases are inaccessible to the genome”) and justify the use of human values as a case study for alignment. (“Humans provide an untapped wealth of evidence about alignment”, “Evolution is a bad analogy for AGI”.) Geoffrey Miller’s The heritability of human values: A behavior genetic critique of Shard Theory argues that the high heritability of many kinds of human values contradicts the core claims of shard theory.
Thomas Kwa’s Failure modes in a shard theory alignment plan gives definitions for many of the key terms of shard theory and outlines a possible shard theory alignment plan, before raising several objections. Namely, he argues that it’s challenging to understand how rewards lead to shard formation and it’s hard to predict the process of value formation. Alex Turner’s A shot at the diamond-alignment problem applies the shard theory of human value to generate a solution for a variant of the diamond maximizer problem, while Nate Soares’s Contra shard theory in the context of the diamond maximizer raises four objections to this attempted solution.
Finally, this post is similar in motivation to Jacy Reese Anthis’s “Unpacking ‘Shard Theory’ as Hunch, Question, Theory, and Insight”, which divides the shard theory research program into the four named components. By contrast, this post aims to outline the key claims of the current shard theory agenda (for example, we don't describe the shard question except in passing).
The nine theses of shard theory
1.Agents are (well modeled as being) made up of shards
The primary claim of shard theory is that agents are best understood as being composed of shards: contextually activated computations that influence decisions and are downstream of historical reinforcement events. For example, Turner and Pope give the example of a “juice-shard” in a baby that is formed by reinforcement on rewards activated by the taste of sugar, that then influences the baby to attempt to drink juice in contexts (similar to those) where they’ve had juice in the past.
To better understand what shard theory is claiming here, it’s worth comparing it to three other ways of understanding agents that are being trained via reinforcement learning: the rational agent model, where an agent is thought of as maximizing a particular utility function (often assumed to be the value function of the external reward); subagent models, where each “agent” is best modeled as being a collection of subagents, each of which maximize a utility function (shaped by some (possibly identical) reward); and Steven Brynes’s learning and steering model, which models the human brain as composed of a large learning subsystem “trained from scratch” and a much smaller steering subsystem consisting of mainly hardcoded components that guides the learning subsystem.
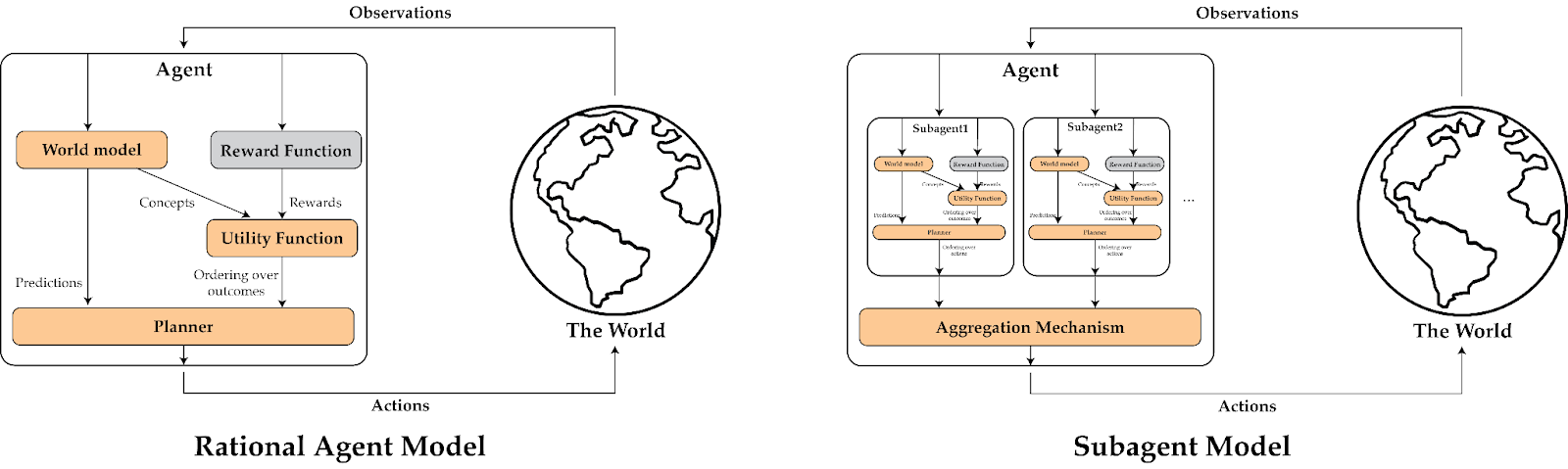
- Unlike the rational agent model, agents in shard theory are composed of many subparts that “want” different things, and should not be modeled as defined by a preference ordering over worlds + an optimal/near optimal search algorithm. That is, the baby can have a juice-shard, an “interact with adults”-shard, a “play with toys”-shard, etc., which in turn can lead to seemingly irrational behavior such as flip-flopping between an interesting adult and attempting to grab and drink juice from a bottle.
- Unlike in subagent models, the subcomponents of agents are not themselves always well modeled as (relatively) rational agents. For example, there might be shards that are inactive most of the time and only activate in a few situations. In addition, shard theory suggests that all of the behavior of shards is formed via a combination of self-supervised learning of world models and reinforcement learning on the shards themselves. In contrast, subagent models often allow for subagents with desires that are “hardcoded”, e.g. via evolutionary processes. In the baby example, the juice-shard might only activate when they see a particular type of juice bottle, which they’ve drunk juice from.
- Unlike in the learning and steering model, all of the shards are shaped primarily via reinforcement learning; only the rewards, learning algorithms, and a few stimulus reactions can be hardcoded. In the learning and steering model, the steering subsystem contains hardcoded social instincts and complex drives such as disgust or awe. (EDIT: I think the claim I made here is imprecise, see the response from Steve Byrnes here.) In contrast, in the shard theory baby example, there are no in-built “listen to authority”-shards, the baby learns a “listen to authority”-shard as a consequence of their hardcoded reward circuitry and learning algorithm.
In other words, shard theory is both more general than other models (in the sense of allowing for many contextually activated shards that don’t have to be rational), but is also narrower than other models (in the sense that values must be downstream of past reinforcement events).
As far as I can tell, there currently isn’t a super precise definition of a shard, nor is there a procedure that identifies shards given the description of an agent; this is an active area of research. Shard theory also does not purport to explain how exactly in-built reward circuitry is implemented.
2. Shards care about concepts inside the agent’s world model
A second claim of shard theory is that shards generally end up caring about concepts inside the agent’s world model, instead of direct sensory inputs. That is, most shards can be well modeled as bidding for plans on the basis of certain concepts and not raw sensory experiences. (Shard theory makes an implicit but uncontroversial assumption that smart agents will contain world models largely shaped via unsupervised learning.) For example, the aforementioned “juice-shard” cares about juice inside of the baby’s world model, as opposed to directly caring about sensory inputs associated with juice or maximizing the reward signal. That being said, there can still be shards that care about avoiding or seeking particular sensory inputs. Shard theory just predicts that most shards will end up binding to concepts inside a (unitary) world model.
3. Active shards bid for plans in a way shaped via reinforcement learning
Shard theory claims that the process that maps shards to actions can be modeled as making “bids” to a planner. That is, instead of shards directly voting on actions, they attempt to influence the planner in ways that have “historically increased the probability of executing plans” favored by the shard. For example, if the juice shard bringing a memory of consuming juice to conscious attention has historically led to the planner outputting plans where the baby consumes more juice, then the juice shard will be shaped via reinforcement learning to recall memories of juice consumption at opportune times. On the other hand, if raising the presence of a juice pouch to the planner’s attention has never been tried in the past, then we shouldn’t expect the juice shard to attempt this more so than any other random action.
This is another way in which shard theory differs from subagent models—by default, shards aren’t doing their own planning or search; they merely execute strategies that are learned via reinforcement learning.
As far as I can tell, shard theory does not make specific claims about what form these bids take, how a planner works, how much weight each shard has, or how the bids are aggregated together into an action.
4. The optimization target is poorly modeled by the reward function
It’s relatively uncontroversial that agents with significant learned components do not have to end up optimizing for their reward function. This is generally known as inner misalignment or goal misgeneralization, see for example Hubinger 2019, Langosco et al 2022, or Shah et al 2022.

However, shard theory makes a more aggressive claim—not only is it not necessary, as a consequence of how shards form, we should expect sufficiently large degrees of goal misgeneralization that thinking of an agent as maximizing rewards is a mistake (e.g. see Turner’s Inner and outer alignment decompose one hard problem into two extremely hard problems and Reward is not the optimization target for a more detailed discussion). Shard theory instead claims that we should instead directly model how the optimization target is shaped via the reward signal (“reward as chisel”).
That is, because most shards end up caring about concepts inside a world model, the agent’s actions are determined primarily by shards that don’t bid to directly maximize reward. In rich environments with many possible actions, this will naturally cause the agent’s actions to deviate away from pure reward maximization. For example, a shard theorist might point to the fact that (most) people don’t end up maximizing only their direct hedonic experiences.
5. Agentic shards will seize power
While not all shards are agents, shard theory claims that relatively agentic shards exist and will eventually end up “in control” of the agent’s actions. Here, by “agentic shard”, shard theory refers to shards that have a specific goal that they attempt to achieve by behaving strategically in all contexts. In contrast, other shards may be little more than reflex agents. For example, a more agentic “be healthy” shard might steer me away from a candy store, preventing the candy shard from firing; a “do work” shard might steer me away from distractions like video games in favor of writing Alignment Forum content, etc. Competitiveness arguments imply that agentic shards that care about gaining power will end up in charge, while less agentic shards end up with progressively less influence on their agent’s policy.
One consequence of agentic shards steering away from situations that cause other shards to fire, is that it prevents the other shards from being reinforced. This implies that the nonagentic shards will slowly lose influence over time, as the agentic shards are still being reinforced.[1] This is probably sped along in many agents by implicit or explicit regularization, which may remove extraneous circuits over the course of training.
6. Value formation is very path dependent and architecture independent
Shard theory also claims that the values an agent ends up with is very path dependent. It’s trivially true that the final value of agents can depend on their initial experiences. A classic example of this is a q-learning agent in a deterministic environment with pessimistically initialized rewards and greedy exploration; once the q-learner takes a single trajectory and receives any rewards, they will be stuck following that trajectory forever.[2] Another classic result is McCoy et al’s BERTs of a feather do not generalize together, where varying the random seed and order of minibatches for fine-tuning the same BERT model lead to different generalization behavior.
Shard theory makes a slightly stronger claim: we should expect a large degree of path dependence for the values of agents produced by almost all current RL techniques, including most policy gradient algorithms.
Shard theorists sometimes also claim that value formation is relatively architecture independent. For example, a sufficiently large transformer and a sufficiently large conv net, given the same training data presented in the same order, should converge to qualitatively similar values.
This second claim is very controversial—it’s a common claim in the deep learning literature that we should invent neural networks that contain certain inductive biases that allow them to develop more human-like values. (See for example Building Machines That Learn and Think Like People or Relational inductive biases, deep learning, and graph networks).
7. We can reliably shape final values by varying the reward schedule
Even if the final values of an agent are path dependent and architecture independent, this does not mean that we can reliably predict its final values. For example, it might be the case that the path dependency could be chaotic or depend greatly on the random initialization of the agent, or the agent’s values could change unpredictably during rapid capabilities generalization.
Shard theory claims that we can not only find a reliable map from training descriptions to final agent values, but invert this map to design training curricula that reliably lead to desirable values. (That being said, we might not be able to do it before truly transformative AI.) As an example, Alex Turner gives a sketch of a training curriculum that would lead an AI that reliably cares about diamonds in A shot at the diamond alignment problem.
I think this is also a fairly controversial claim: most other approaches to building an aligned AI tend to assume that constructing this curriculum is not possible without strong additional assumptions (such as strong mechanistic interpretability or a practical solution to ELK) or only is possible for certain classes of AIs (such as myopic or low-impact agents). That being said, I don’t think this is completely out there – for example, Jan Leike argues in What is inner alignment? that we can build a value-aligned AI using recursive reward modeling combined with distributional shift detection and safe exploration.
8. “Goal misgeneralization” is not a problem for AI alignment
A common way of dividing up the alignment problem is into “outer” alignment, where we devise an objective that captures what we want, and “inner” alignment, where we figure out how to build an agent that reliably pursues that objective. As mentioned in thesis 4, many alignment researchers have discussed the difficulty of avoiding inner misalignment.

As previously mentioned in thesis 4, shard theory posits that this decomposition is misleading, and that both inner and outer misalignment may be inevitable. However, shard theorists also claim that inner and outer misalignment can "cancel out" in reliable ways. By gaining a sufficiently good understanding of how agents develop values, we can directly shape the agent to have values amenable to human flourishing, even if we cannot come up with an outer aligned evaluation algorithm.
Shard theory argues that inner misalignment need not necessarily be bad news for alignment: instead, by developing a sufficiently good understanding of how shards form inside agents, we don’t need to think about inner alignment as a distinct problem at all. That is, even though we might not be able to specify a procedure that generates an outer aligned reward model, we might still be able to shape an agent that has desirable values.
9. Shard theory is a good model for human value formation
Finally, humans are the inspiration for the shard theory research program, and shard theory purports to be a good explanation of human behavior. (Hence the eponymous Shard Theory of Human Values.)
In some sense, this is not a necessary claim: shard theory can be a useful model of value formation in AIs, even if it is a relatively poor model of value formation in humans. For one, existing approaches to AGI development certainly start out significantly more blank-slate than human development, so even if humans have several hardcoded values, it’s certainly possible that shard theory would apply to the far more tabula rasa AI agents.
That being said, failing to be a good model of human behavior would still be a significant blow to the credibility of shard theory and would probably necessitate a significantly different approach to shard theory research.
My opinions on the validity of each of the nine theses
In this section I’ll present my thoughts on both the main claims of shard theory listed above. It’s worth noting that some of my disagreements here are a matter of degree as opposed to a matter of kind; I broadly sympathize with many of the intuitions behind shard theory, especially the need for more fine-grained mechanistic models of agent behavior.
Theses 1-3: the shard theory model of agency. I strongly agree that we should attempt to model the internal dynamics of agents in more detail than the standard rational agent model, and I believe that smart agents can generally be well understood as having world models (thesis 2) and that their internals are shaped via processes like reinforcement learning.
However, I’m not convinced that shards are the right level of analysis. Part of this is due to disagreements with later theses, which I’ll discuss later, and another part is due to my confusion about what a shard is and how I would identify shards in a neural network or even myself. (It’s also possible that shard theorists should prioritize finding more realistic examples.) Consequently, I believe that shard theorists should prioritize finding a working definition of a shard or a formalism through which shard theory can be studied and discussed more precisely (see the discussion section for more of my thoughts on these topics).
Thesis 4: reward is not the optimization target. I agree that reward is not always the optimization target, and consequently that Goodharting on the true reward is not the only way in which alignment schemes can fail (and models of the alignment problem that can only represent this failure mode are woefully incomplete).
However, I think there is a good reason to expect sophisticated AIs to exhibit reward hacking–like behavior: if you train your AIs with reinforcement learning, you are selecting for AIs that achieve higher reward on the training distribution. As AIs become more general and are trained on ever larger classes of tasks, the number of spurious features perfectly correlated with the reward shrink,[3] and we should expect agents that optimize imperfect correlates of the reward to be selected against in favor of strategies that directly optimize a representation of the reward. I also think that a significant fraction of this argument goes through an analogy with humans that may not necessarily apply to AIs we make.
My preferred metaphor when thinking about this topic is Rohin Shah’s “reward as optimization target is the Newtonian mechanics to reward as chisel’s general relativity”. While reward as optimization target is not a complete characterization of what occurs over the course of training an RL agent (and notably breaks down in several important ways), it’s a decent first approximation that is useful in most situations.
Thesis 5: agentic shards will seize power. I think insofar as shard theory is correct, the amount of agency in the weighted average of shards should increase over time as the agent becomes more coherent. That being said, I’m pretty ambivalent as to the exact mechanics through which this happens – it’s possible it looks like a power grab between shards, or it’s possible it’s closer to shards merging and reconciling.
Thesis 6: path dependence and architecture independence of value formation. As I said previously, I think that some degree of path dependence of values in RL (especially via underexploration) is broadly uncontroversial. However, as I’ve said previously, AIs that are trained to achieve high reward on a variety of tasks have a strong incentive to achieve high reward. Insofar as particular training runs lead to the formation of idiosyncratic values that aren’t perfectly correlated with the reward, we should expect training and testing to select against these values modulo deceptive alignment. (And I expect many of the pathological exploration issues to be fixed via existing techniques like large-scale self-supervised pretraining, imitation learning on human trajectories, or intrinsic motivation.) So while I still do expect a significant degree of path dependence, my guess is that it’s more productive to think about it in terms of preventing deceptive alignment as opposed to the mechanisms proposed by shard theory.
I am personally quite confused about architecture independence. On one hand, it seems like many different neural network architecture have comparable capabilities at similar scales. On the other hand, this seems to contradict many results in the machine learning literature. In terms of my own experience, I’ve found that mechanistic interpretability on small neural networks on algorithmic tasks often shows that the mechanisms of these neural networks (and thus their generalization properties) depend greatly on the architecture involved. For example, in Neel’s modular addition setting, a 1-layer full transformer with 4 heads learns to add in 3-5 key frequencies, while a 2-layer MLP (with a comparable amount of parameters) learns to add in up to 50 key frequencies. I expect that further mechanistic interpretability work on larger networks will help clarify this problem.
That being said, I think that many of the architectural differences we’ll see in the future will look like different ways to compose large transformers together and less like going from LSTM+Attention or conv nets to just transformers, which may have a larger effect on how values form than existing architectural differences.
Thesis 7: reliably shaping final values by varying the reward schedule. I agree that there exists a procedure in principle that allows us to reliably shape the final values of agents via only changing the order the agent encounters certain scenarios and the reward that they receive in each scenario. However, I expect this to be quite difficult to do in practice. For example, in Neel’s toy modular addition task, the frequencies that 1-layer full transformers converged on seemed to vary with random seed, even though the networks were trained with full batch gradient descent on the same dataset:
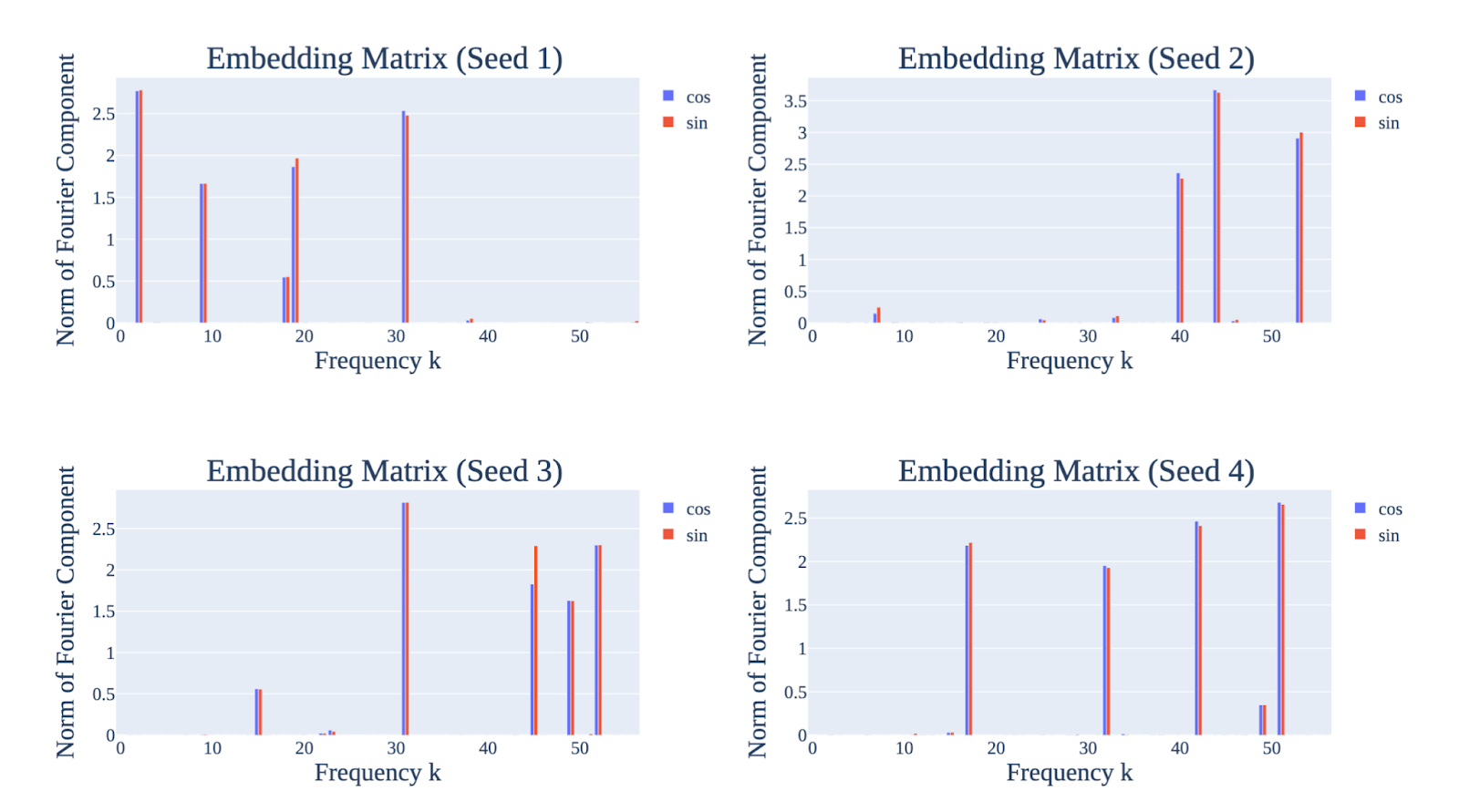
That being said, I think this is mainly an empirical question, and I’d like to see more concrete proposals and experiments validating this hypothesis in practice.
Thesis 8: necessity of studying goal misgeneralization. I’m broadly sympathetic to the approach of taking problems that are normally solved in two chunks and solving them end to end. I also think that the inner/outer alignment split is not particularly clean, and oftentimes introduces its own problems. Accordingly, I do think people should think more in the “reward as chisel” frame.
But while I agree with this approach directionally, I think that the inner/outer alignment split still has a lot of value. For example, it’s easier to work on approaches such as Debate or human feedback + ELK in the outer alignment frame by getting them to work well on average, while splitting off the difficulty of specifying human values allows us to more cleanly study approaches to preventing inner misalignment. While I agree that specifying a perfectly robust reward function (or even a method that will recover such a perfect reward in the limit of infinite data) is incredibly hard, it’s plausible to me that it suffices to have an overseer that is smarter than the agent it’s overseeing and that gets smarter as the agent gets smarter.
Thesis 9: shard theory as a model of human values. I’m personally not super well versed in neuroscience or psychology, so I can’t personally attest to the solidity or controversialness of shard theory as a theory of value formation. I’d be interested in hearing from experts in these fields on this topic.
That being said, I speculate that part of the disagreement I have with shard theorists is that I don’t think shard theory maps well onto my own internal experiences.
Discussion and future work
Despite my reservations with shard theory above, I do think that the core shard theory team should be applauded for their ambition. It’s not common for researchers to put forth an ambitious new theory of agency in this reference class, and I think that more projects of this level of ambition are needed if we want to solve the alignment problem. The fact that Alex and Quintin (and the rest of Team Shard) have posited a novel approach to attacking the alignment problem and made substantive progress on it in several months is worth a lot, and I expect them to produce good work in the future. This is the highest order bit in my assessment of the research program.
For all of our sakes, I also sincerely hope that they manage to prove my reservations entirely misguided and manage to solve (a significant chunk of) the alignment problem.
Accordingly, I’d like to offer some possible directions of future work on shard theory:
A formalism for shard theory
Currently, shard theory lacks a precise definition of what a shard is (or at least a working model of such). Making a formalism for shard theory (even one that’s relatively toy) would probably help substantially with both communicating key ideas and also making research progress.
Engagement with existing psychology, neuroscience, and genetics literature
It’s clear that the shard theory team has engaged substantially with the machine learning literature. (See, for example, Quintin’s Alignment Papers Roundups.) It’s possible that more engagement with the existing psychology, neuroscience, and genetics literature could help narrow down some of the uncertainties with shard theory. It’d also help us better understand whether shard theory is an accurate description of human value formation. (It’s possible that this has already been done. In that case, I’d encourage the shard theory team to make a post summarizing their findings in this area.)
Experimental validation of key claims
Finally, shard theory makes many claims that can be tested on small neural networks. For example, it should be possible to mechanistically identify shards in small RL agents (such as the RL agents studied in Langosco et al), and it should also be possible to empirically characterize the claims regarding path dependence and architecture independence. While I think the field of machine learning often overvalues empirical work and undervalues conceptual work, I think that empirical work still has a lot of value: as with formalisms, experiments help with both communicating research ideas and making research progress. (As with the psychology and neuroscience lit review above, it’s possible that these experiments have already been done, in which case I’d again encourage the shard theory team to post more about their findings.)
- ^
For a toy example, suppose that each shard outputs a single logit, and the agent follows the advice of each shard with probability equal to the softmax of said logits. If the logits of agentic shards increases over time while the logits of non-agentic shards doesn’t increase (because said shards are never reinforced), then over time the probability the agent follows the advice of non-agentic shards will drop toward zero.
- ^
Interestingly, this is just a problem when an RL agent fails to properly explore the environment (due to a bad prior) in general. Even AIXI can end up stuck on suboptimal policies, if it starts with a sufficiently bad Solomonoff prior and sees evidence consistent with a Turing machine that assigns massive negative reward unless it follows a particular course of action. If the actions it takes prevents it from gaining more evidence about which world it’s in—for example, if the course of action is “sit in the corner and turn off all sensors”---then the AIXI might just sit in the proverbial corner forever.
- ^
I’m drawing a lot of this intuition from the Distributionally Robust Optimization work, where rebalancing classes (and training again) is generally sufficient to remove many spurious correlations.