This is a linkpost for https://medium.com/@deepmindsafetyresearch/scalable-agent-alignment-via-reward-modeling-bf4ab06dfd84
Jan Leike and others from the DeepMind safety team have released a new research agenda on reward learning:
"Ultimately, the goal of AI progress is to benefit humans by enabling us to address increasingly complex challenges in the real world. But the real world does not come with built-in reward functions. This presents some challenges because performance on these tasks is not easily defined. We need a good way to provide feedback and enable artificial agents to reliably understand what we want, in order to help us achieve it. In other words, we want to train AI systems with human feedback in such a way that the system’s behavior aligns with our intentions. For our purposes, we define the agent alignment problem as follows:
How can we create agents that behave in accordance with the user’s intentions?
The alignment problem can be framed in the reinforcement learning framework, except that instead of receiving a numeric reward signal, the agent can interact with the user via an interaction protocol that allows the user to communicate their intention to the agent. This protocol can take many forms: the user can provide demonstrations, preferences, optimal actions, or communicate a reward function, for example. A solution to the agent alignment problem is a policy that behaves in accordance with the user’s intentions.
With our new paper we outline a research direction for tackling the agent alignment problem head-on. Building on our earlier categorization of AI safety problems as well as numerous problem expositions on AI safety, we paint a coherent picture of how progress in these areas could yield a solution to the agent alignment problem. This opens the door to building systems that can better understand how to interact with users, learn from their feedback, and predict their preferences — both in narrow, simpler domains in the near term, and also more complex and abstract domains that require understanding beyond human level in the longer term.
The main thrust of our research direction is based on reward modeling: we train a reward model with feedback from the user to capture their intentions. At the same time, we train a policy with reinforcement learning to maximize the reward from the reward model. In other words, we separate learning what to do (the reward model) from learning how to do it (the policy).
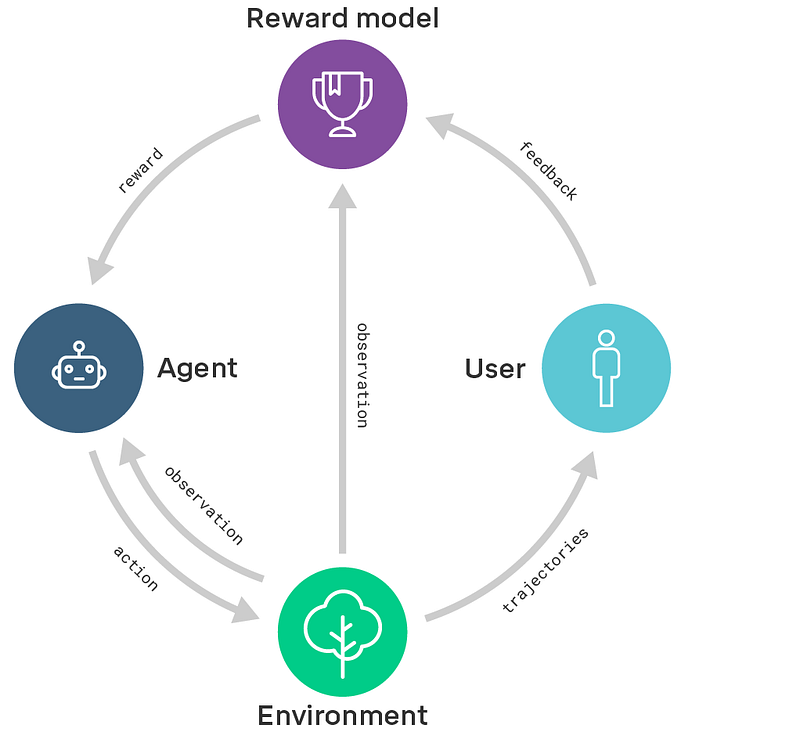
For example, in previous work we taught agents to do a backflip from user preferences, to arrange objects into shapes with goal state examples, to play Atari games from user preferences and expert demonstrations. In the future we want to design algorithms that learn to adapt to the way users provide feedback (e.g. using natural language)."