I liked the way you explained Markov Chain implementation in causal DAG. Similarly, I tried to use Markov Chain model to detect anomalies in time series sequence. My findings during the testing is computation of empirical joint distribution requires enormous amount of data and is generally not feasible.The joint probability is approximated with the product of conditional probabilities based on first order Markov Chain assumption p(xi+n|xi+n-1)p(xi+n-1|xi+n-2)…p(xi+1|xi).
Please let me know if I am correct with my statement.
The previous post in this sequence discussed how to throw away information in causal DAGs. This post provides a detailed example using a Markov chain.
Suppose we have an n-state Markov chain (CS people: picture a finite state machine with n states and random state transitions at each timestep). A matrix of state transition probabilities Tji gives the probability of transitioning to state j when the system starts the timestep in state i. Writing the state at time t as Xt, we have P[Xt+1=j|Xt=i]=Tji. More generally, P[Xt+m=j|Xt=i]=(Tm)ji, where Tm denotes a matrix power (i.e. T matrix-multiplied by itself m times). To complete the specification, we’ll assume that the system starts in a random state X0 at time 0, with the initial distribution P[X0] given.
As a causal DAG, this system is just a chain: the state at time t depends only on the state at time t−1:
X0→X1→X2→X3→...
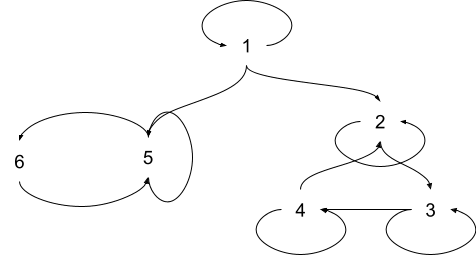
People typically draw basic Markov chains the same way we draw finite state machines: a graph with one node for each state, and arcs indicating transitions. Unlike an FSM, where the next arc is chosen by a symbol from some input stream, here the next arc is chosen randomly - so each arc has a probability associated with it. An example:
This is NOT a causal diagram, it is a state transition diagram. It says that, if the system is in state 1, then at the next timestep it will randomly transition to state 1, 2, or 5. (I haven’t included the probabilities on each arc; all that matters for our purposes is that each arc shown has nonzero probability.) Since we have two graph representations of the system (the state transition diagram and the causal DAG), I will generally refer to vertices in the state transition diagram “states” and vertices Xt in the causal diagram as “nodes”.
Pick the set of nodes from X0 to Xt+m−1 for some large-ish m (we’ll denote this set X<t+m)
Throw away all info from Xt which is not relevant to nodes outside X<t+m: replace Xt with X′t, a representation of the function x→P[Xt+m=x|Xt].
Let’s think about what that last piece looks like. Xt could be any of the states 1 through 6; X′t must assign different values to any two states with different distributions P[Xt+m|Xt]. But for large m, many of the states will have (approximately) the same long-run distribution P[Xt+m|Xt] - this is the foundational idea of ergodicity. In the example above, nodes 5 & 6 will have the same long-run distribution, and nodes 2, 3, 4 will have the same long-run distribution.
To see why, imagine what happens if we start in state 5, assuming that the 5 -> 6 transition is much more likely than the 5 -> 5 transition. Well, since 5 -> 6 is much more likely than 5 -> 5, we’ll probably jump to state 6 next. And state 6 always jumps back to 5, so in two steps we’ll be back to 5. And so forth - back and forth, alternating between state 5 and 6 every timestep. But every one in awhile, we’ll jump from 5 -> 5, throwing the back-and-forth oscillation out of sync. If we imagine two copies of this chain running side-by-side, they’d start out oscillating in sync, but eventually drift out of sync. If we walk away for a while and look back at the chain much later, we’d expect that it’s roughly equally likely to be in state 5 or 6, regardless of which it started in.
That’s the key: if the chain started in state 5 or 6, with 5 -> 6 much more likely than 5 -> 5, than after a while, it would be roughly equally likely to be in state 5 or state 6. P[Xt+m|Xt=5]≈P[Xt+m|Xt=6] for large m. Even if 5 -> 6 is not much more likely than 5 -> 5, the two long-run distributions will still be the same - the long-run probabilities of 5 and 6 just won’t be roughly equal (we’ll stay in state 5 somewhat more often than 6).
A more general criteria:
View the state transition diagram as a directed graph, and ask which states are connected in both directions - i.e. a set of states in which we can reach any state from any other by following the arrows
Some arrows “knock oscillations out of sync” - read up on reducibility and ergodicity in Markov chains for technical details (I first saw this stuff in an operations research class)
If both of these criteria are met for some set of states, then each of those states i implies the same long-run behavior P[Xt+m|Xt=i].
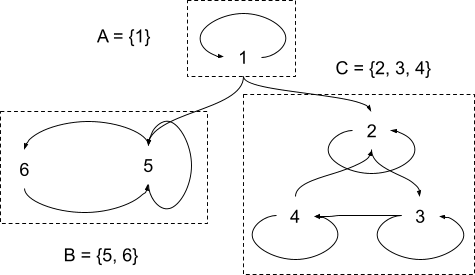
Getting back to our abstraction: X′t doesn’t need to distinguish between states 5 and 6, or between states 2, 3, 4. Our states are grouped like this:
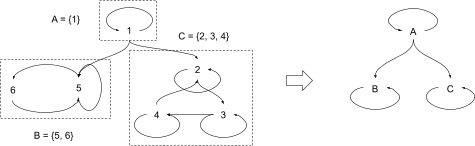
… and X′t is A, B, or C. Our causal diagram looks exactly like before, with X′t in place of Xt:
X0→...Xt−1→X′t→Xt+1…
We need to choose representative Xt-values for each of A, B, C, so we’ll pick A→1,B→6,C→3. So, if Xt−1=6, then X′t is B with probability 1 (since Xt is 5 or 6, both of which map to B). Xt+1 is then chosen as though Xt were 6, since 6 is our representative value for B.
Our abstract model no longer supports short-range queries around X′t. To see what goes wrong, consider P[Xt+1=6|Xt−1=6], assuming once again that 5 -> 6 is much more likely than 5 -> 5. In the original model, this gave rise to oscillation between states 5 and 6, so if the system was in state 6 at time t−1, then it would most likely be in state 6 again at time t+1. But in the new model, X′t throws away information distinguishing states 5 and 6 - both are just “B”. If Xt−1 = 6, then X′t = B, and Xt+1 behaves as though Xt were the representative value 6 - implying that Xt+1 is 5, rather than 6. No match :(.
Yet this does not impact the validity of long-range queries at all! Because both Xt=5 and Xt=6 imply the same long-run predictions, the model does support long-range queries, like P[Xt+m+4|Xt−1].
Finally, we can imagine cleaning up the model a bit by abstracting the whole chain, rather than just one node. Using the same info-throw-away transformation on every node, the abstraction looks like this:
Intuitively, not only do we have a Markov chain on the high-level variables X′t, we also have enough information in the high-level model to predict correlations between low-level Xt, as long as the Xt's we query are at least m timesteps apart. That's the property which makes this abstraction "natural" - more on that later.