This is a linkpost for https://www.anthropic.com/constitutional.pdf
The authors propose a method for training a harmless AI assistant that can supervise other AIs, using only a list of rules (a "constitution") as human oversight. The method involves two phases: first, the AI improves itself by generating and revising its own outputs; second, the AI learns from preference feedback, using a model that compares different outputs and rewards the better ones. The authors show that this method can produce a non-evasive AI that can explain why it rejects harmful queries, and that can reason in a transparent way, better than standard RLHF: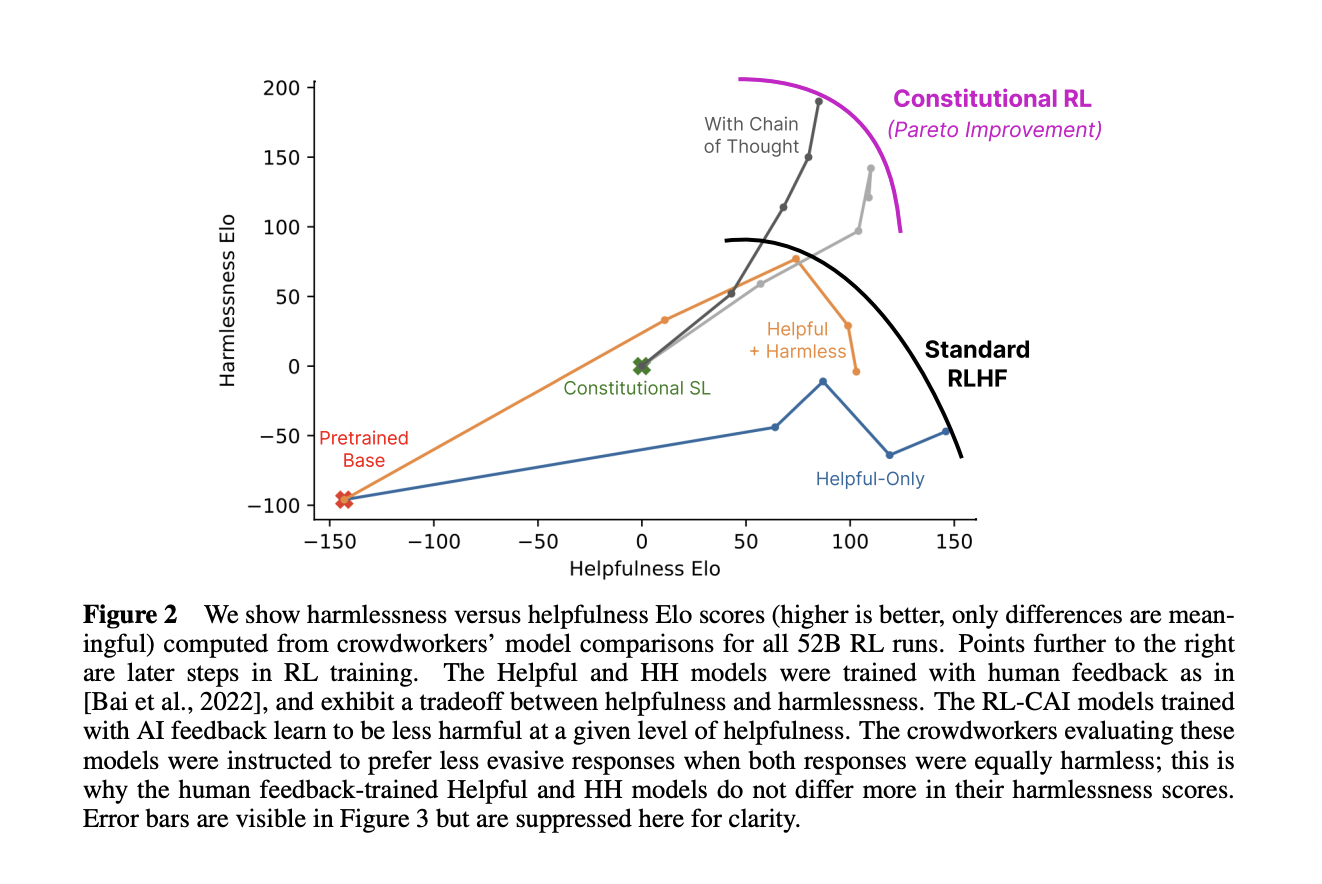
Paper abstract:
As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through selfimprovement, without any human labels identifying harmful outputs. The only human oversight is provided through a list of rules or principles, and so we refer to the method as ‘Constitutional AI’. The process involves both a supervised learning and a reinforcement learning phase. In the supervised phase we sample from an initial model, then generate self-critiques and revisions, and then finetune the original model on revised responses. In the RL phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better, and then train a preference model from this dataset of AI preferences. We then train with RL using the preference model as the reward signal, i.e. we use ‘RL from AI Feedback’ (RLAIF). As a result we are able to train a harmless but nonevasive AI assistant that engages with harmful queries by explaining its objections to them. Both the SL and RL methods can leverage chain-of-thought style reasoning to improve the human-judged performance and transparency of AI decision making. These methods make it possible to control AI behavior more precisely and with far fewer human labels.
See also Anthropic's tweet thread:
https://twitter.com/AnthropicAI/status/1603791161419698181