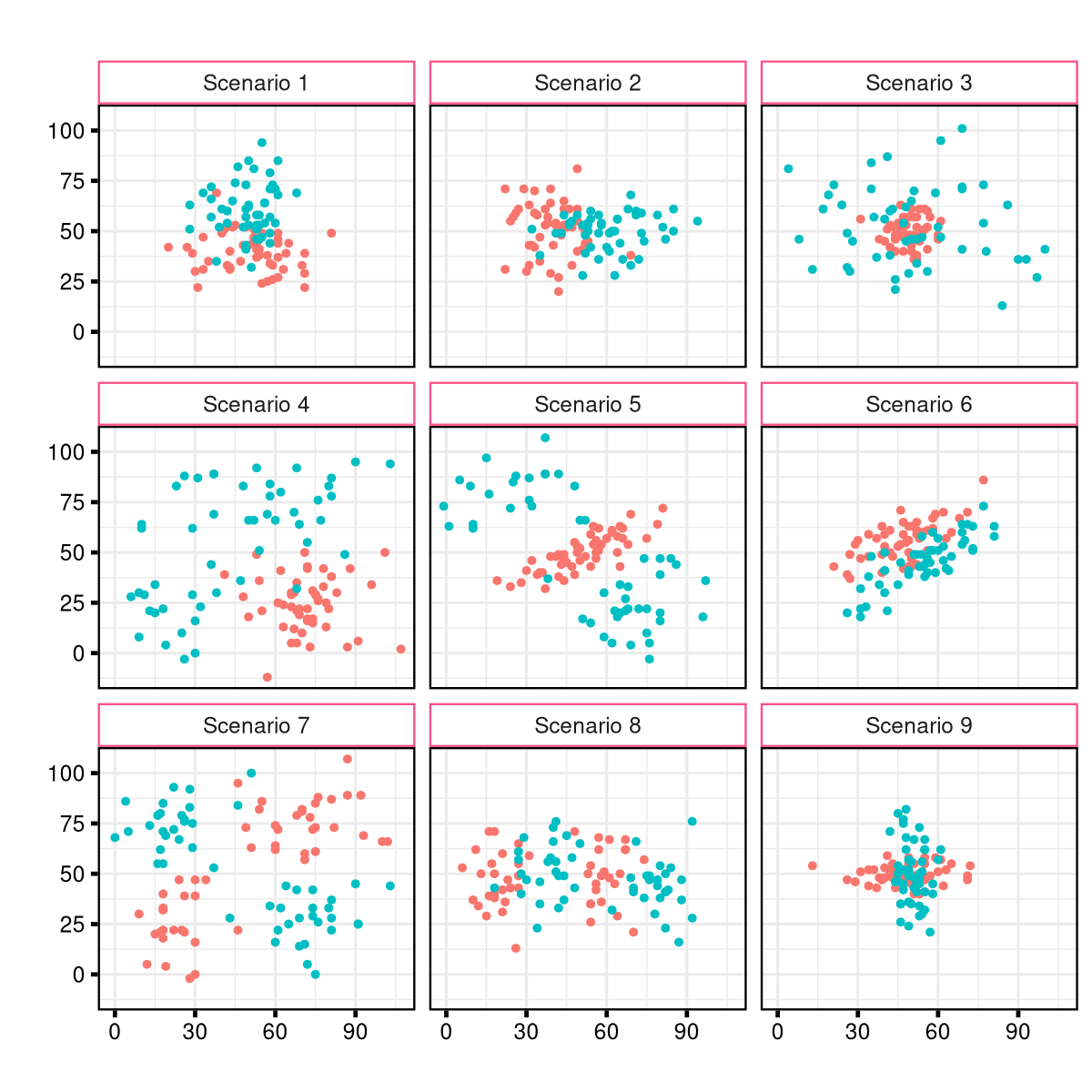
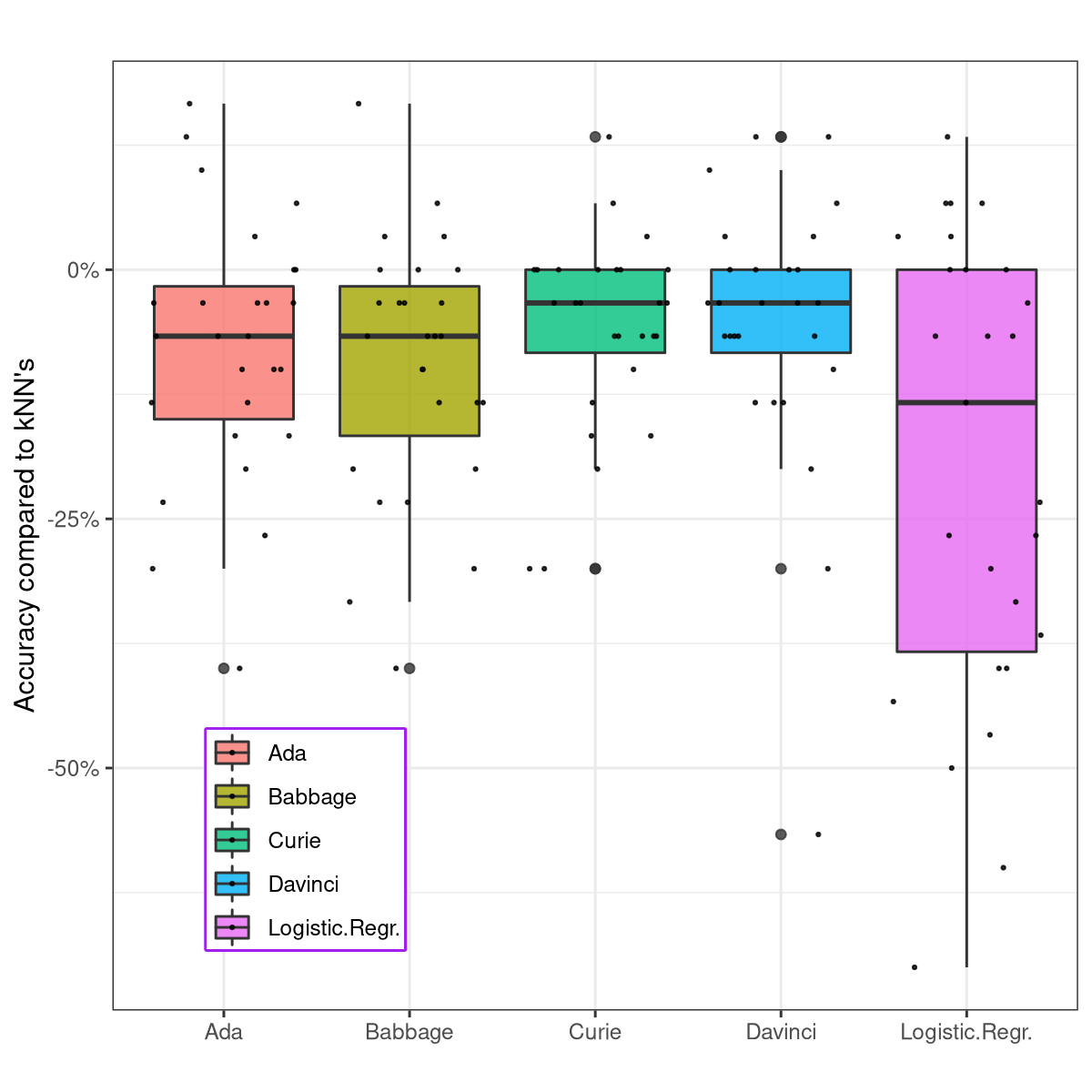
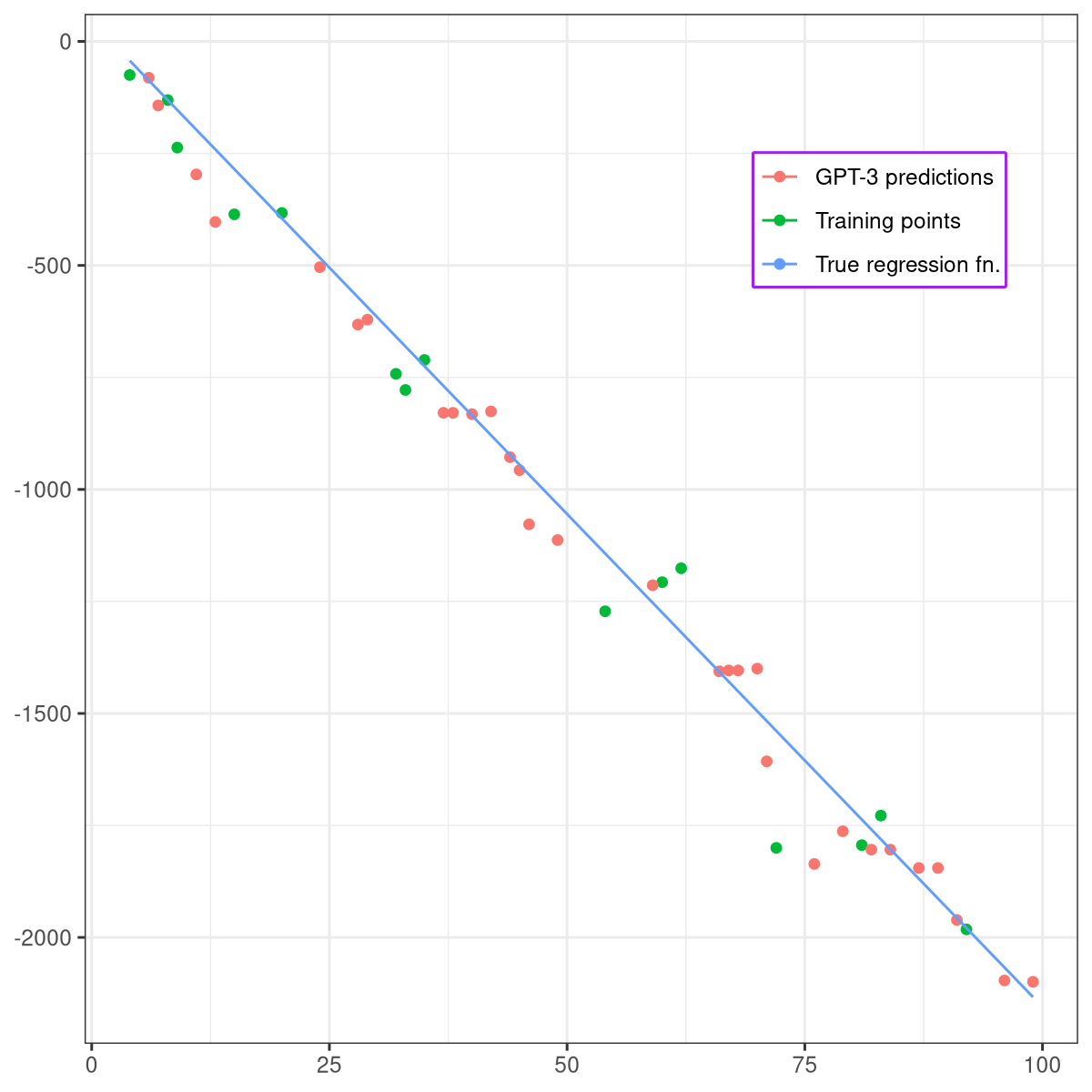
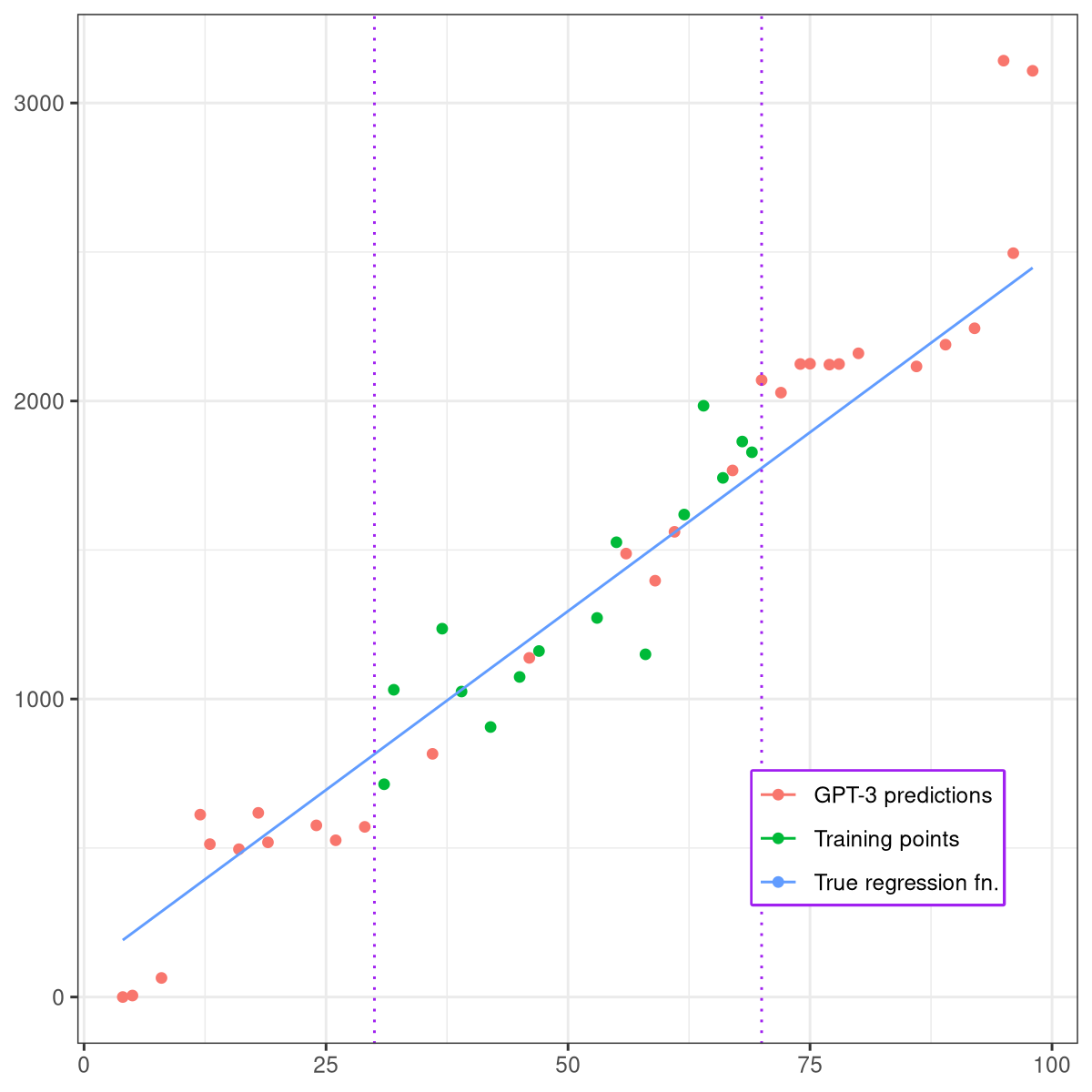
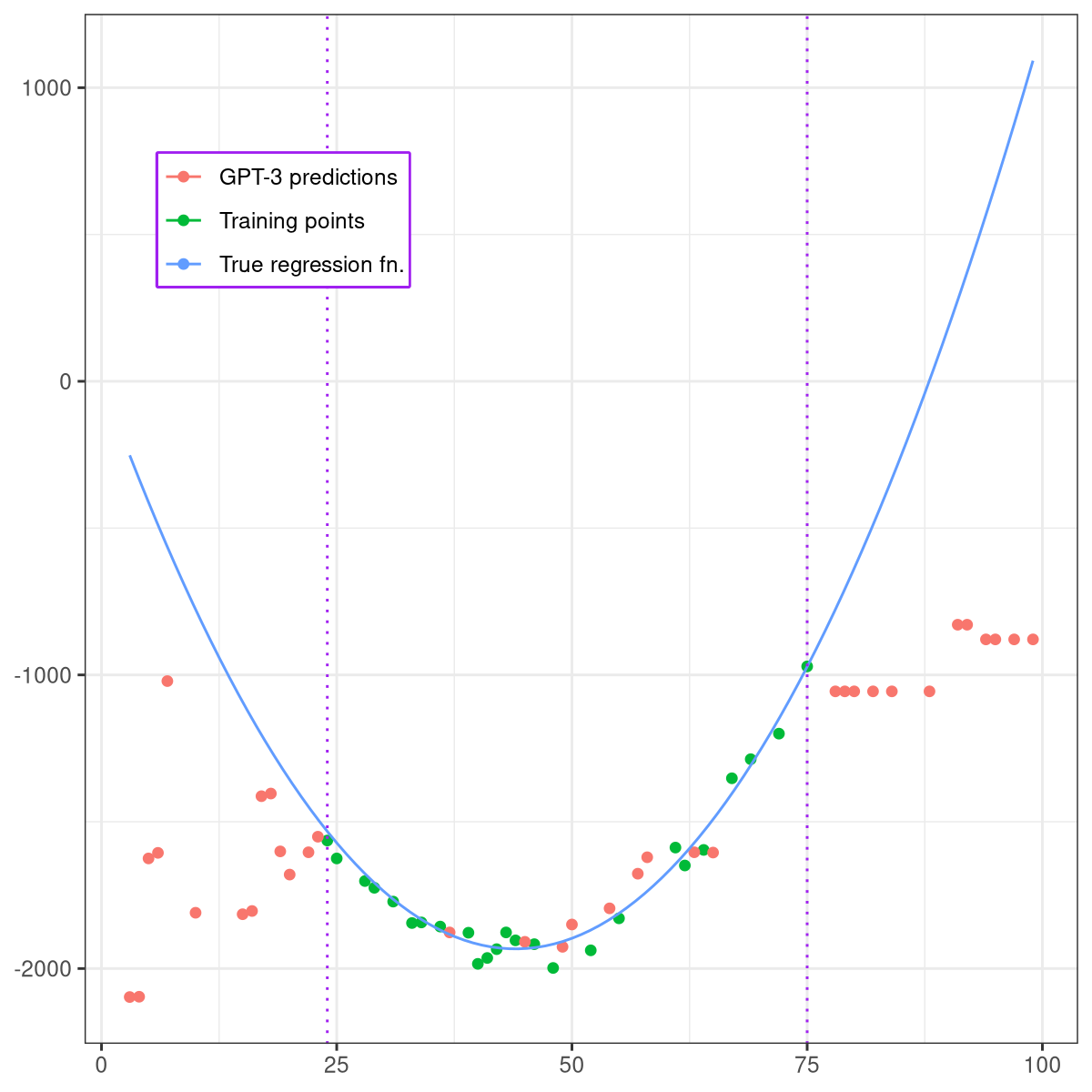
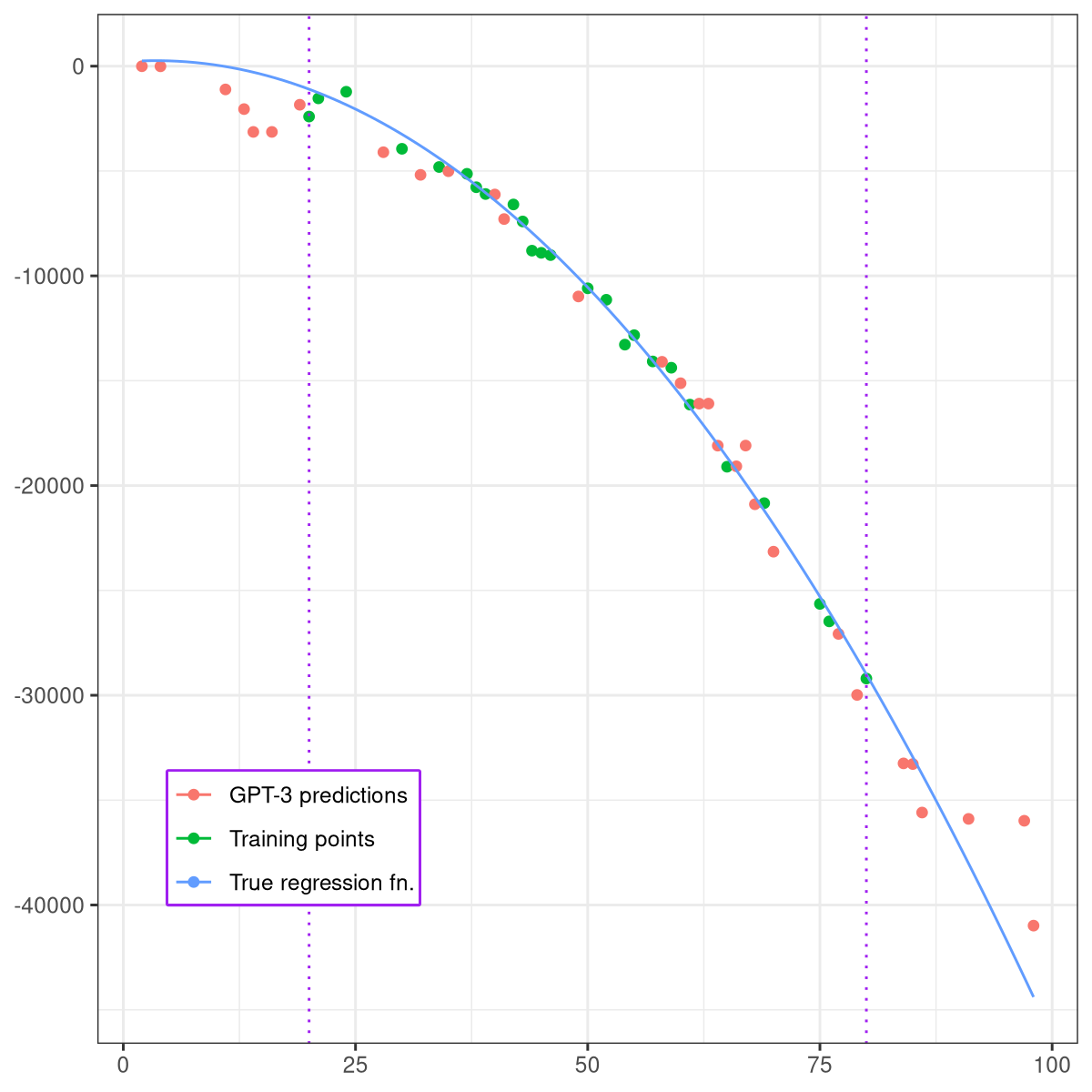
Who models the models that model models? An exploration of GPT-3's in-context model fitting ability
6gwern
5gwern
4gwern
4Vlad Mikulik
0Lovre
3gwern
2Owain_Evans
4Lovre
2p.b.
1davidl123
New Comment
Interesting new paper: "What Can Transformers Learn In-Context? A Case Study of Simple Function Classes", Garg et al 2022:
In-context learning refers to the ability of a model to condition on a prompt sequence consisting of in-context examples (input-output pairs corresponding to some task) along with a new query input, and generate the corresponding output. Crucially, in-context learning happens only at inference time without any parameter updates to the model. While large language models such as GPT-3 exhibit some ability to perform in-context learning, it is unclear what the relationship is between tasks on which this succeeds and what is present in the training data.
To make progress towards understanding in-context learning, we consider the well-defined problem of training a model to in-context learn a function class (e.g., linear functions): that is, given data derived from some functions in the class, can we train a model to in-context learn "most" functions from this class?
We show empirically that standard Transformers can be trained from scratch to perform in-context learning of linear functions -- that is, the trained model is able to learn unseen linear functions from in-context examples with performance comparable to the optimal least squares estimator. In fact, in-context learning is possible even under two forms of distribution shift: (i) between the training data of the model and inference-time prompts, and (ii) between the in-context examples and the query input during inference.
We also show that we can train Transformers to in-context learn more complex function classes -- namely sparse linear functions, two-layer neural networks, and decision trees -- with performance that matches or exceeds task-specific learning algorithms.
Our code and models are available at this https URL.
...Curriculum: ...Notably, when training Transformers without curriculum, there is an initial—relatively long—period in training where the loss does not decrease, followed by a period of sharp decrease. The length of this period varies with training randomness and seems to increase on average with problem dimension. Understanding the model just before and after this transition moment is a promising future direction, which can give insights into the emergence of in-context learning. Interestingly, Olsson et al 2022 observe a similar jump in the in-context learning ability of a language model which they attribute to the formation of “induction heads”.
Another: "From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples", Vacareanu et al 2024:
We analyze how well pre-trained large language models (e.g., Llama2, GPT-4, Claude 3, etc) can do linear and non-linear regression when given in-context examples, without any additional training or gradient updates. Our findings reveal that several large language models (e.g., GPT-4, Claude 3) are able to perform regression tasks with a performance rivaling (or even outperforming) that of traditional supervised methods such as Random Forest, Bagging, or Gradient Boosting. For example, on the challenging Friedman #2 regression dataset, Claude 3 outperforms many supervised methods such as AdaBoost, SVM, Random Forest, KNN, or Gradient Boosting. We then investigate how well the performance of large language models scales with the number of in-context exemplars. We borrow from the notion of regret from online learning and empirically show that LLMs are capable of obtaining a sub-linear regret.
One parallel case that occurs to me is Anthropic using their GPT-like to try to imitate the COMPAS prediction of criminal offending, which is a regression problem too; then in the appendix, they experiment with a movie recommender system:
Figure 8 shows that language models smoothly decrease in the standard Root Mean Square Error (RMSE, lower is better) metric on the widely used Movielens 1M movie recommendation system task [31] as they increase in size. The smallest model achieves a significantly better RMSE (1.06) than chance (RMSE 1.91), and the largest model achieves a significantly lower RMSE (0.94) than a strong baseline model (RMSE 0.98, see below for further details). Although no models achieve state of the art (SOTA) performance (RMSE 0.82), these results are still surprising because the language models (in our zero-shot setting) see two orders of magnitude less training data than the SOTA model.
Nice work!
This section in Anthropic's work on Induction heads seems highly relevant -- I would be interested in seeing an extension of your analysis that looks at what induction heads do in these tasks.
If we believe the claims in that paper, then in-context learning of any kind seems to driven by a fairly simple mechanism not unlike kNN -- induction attention heads. Since it's pretty tractable to locate induction heads in an automated way, we could potentially take a look at the actual mechanism being used to implement these predictions and verify/falsify the hypotheses you make about how GPT makes these predictions. (Although you'd probably have to switch to an open-source model.)
That seems like a great idea, and induction heads do seem highly relevant!
What you describe is actually one of the key reasons why I'm so excited about this whole approach. I've seen many interesting metalearning tasks, and they mostly just like work or not work, or they fail sometimes, and you can try to study their failures to perhaps glean some insight into the underlying algorithm -- but...they just don't have (m)any nontrivial "degrees of freedom" in which you can vary them. The class of numerical models, on the other hand, has a substantial amount of nontrivial ways in which you can vary your input -- and even more so, you can vary it not just discretely, but also ~continuously.
That makes me really optimistic about the possibility of which you hint, of reverse engineering whatever algorithm the model is running underneath, and then using interpretability tools to verify/falsify those findings. Conversely, interpretability tools could be used to make predictions about the algorithm, which can then be checked. Hence one can imagine a quite meaningful feedback loop between experimentation and interpretability!
https://twitter.com/volokuleshov/status/1619906183955095558 demos using ChatGPT to run a 'Python notebook' to 'train a neural net model' to 'predict' outputs for various functions like sin() or 5 / (1+x)**2 -1
Cool post! Did you try seeing whether GPT-3 can regenerate parts of the Iris dataset (or any other datasets that may appear in its training data)? I'd also be interested to see finetuning results, results for the latest InstructGPT, and to see analysis of the GPT-3 Embeddings for integers and floats.
Since I transformed the Iris dataset with a pretty "random" transformation (i.e. not chosen because it was particularly nice in some way), I didn't check for its regeneration -- since my feature vectors were very different to original Iris's, and it seemed exceedingly unlikely that feature vectors were saved anywhere on the internet with that particular transformation.
But I got curious now, so I performed some experiments.
The Iris flower data set or Fisher's Iris data set is a multivariate data set introduced by the British statistician and biologist Ronald Fisher in his 1936 paper
Feature vectors of the Iris flower data set:
Input = 83, 40, 58, 20, output = 1
Input = 96, 45, 84, 35, output = 2
Input = 83, 55, 24, 9, output = 0
Input = 73, 54, 28, 9, output = 0
Input = 94, 45, 77, 27, output = 2
Input = 75, 49, 27, 9, output = 0
Input = 75, 48, 26, 9, output = 0
So these are the first 7 transformed feature vectors (in one of the random samplings of the dataset). Among all the generated output (I looked at >200 vectors), it never once output a vector which was identical to any of the latter ones, and also... in general the stuff it was generating did not look like it was drawing on any knowledge of the remaining vectors in the dataset. (E.g. it generated a lot that were off-distribution.)
I also tried
Input = 83, 55, 24, 9, output = 0
Input = 73, 54, 28, 9, output = 0
[... all vectors of this class]
Input = 76, 52, 26, 9, output = 0
Input = 86, 68, 27, 12, output = 0
Input = 75, 41, 69, 30, output = 2
Input = 86, 41, 76, 34, output = 2
Input = 84, 45, 75, 34, output = 2
Where I cherrypicked the "class 2" so that the first coordinate is lower than usual for that class; and the generated stuff always had the first coordinate very off-distribution from the rest of the class 2, as one would expect if the model was meta-learning from the vectors it sees, rather than "remembering" something.
This last experiment might seem a little contrived, but bit of a problem with this kind of testing is that if you supply enough stuff in-context, the model (plausibly) meta-learns the distribution and then can generate pretty similar-looking vectors. So, yeah, to really get to the bottom of this, to become 'certain' as it were, I think one would have to go in deeper than just looking at what the model generates.
(Or maybe there are some ways around that problem which I did not think of. Suggestions appreciated!)
To recheck things again -- since I'm as worried about leakage as anyone -- I retested Iris, this time transforming each coordinate with its own randomly-chosen affine transformation:
And the results are basically identical to those with just one affine transformation for all coordinates.
I'm glad that you asked about InstructGPT since I was pretty curious about that too, was waiting for an excuse to test it. So here are the synthetic binary results for (Davinci-)InstructGPT, compared with the original Davinci from the post:
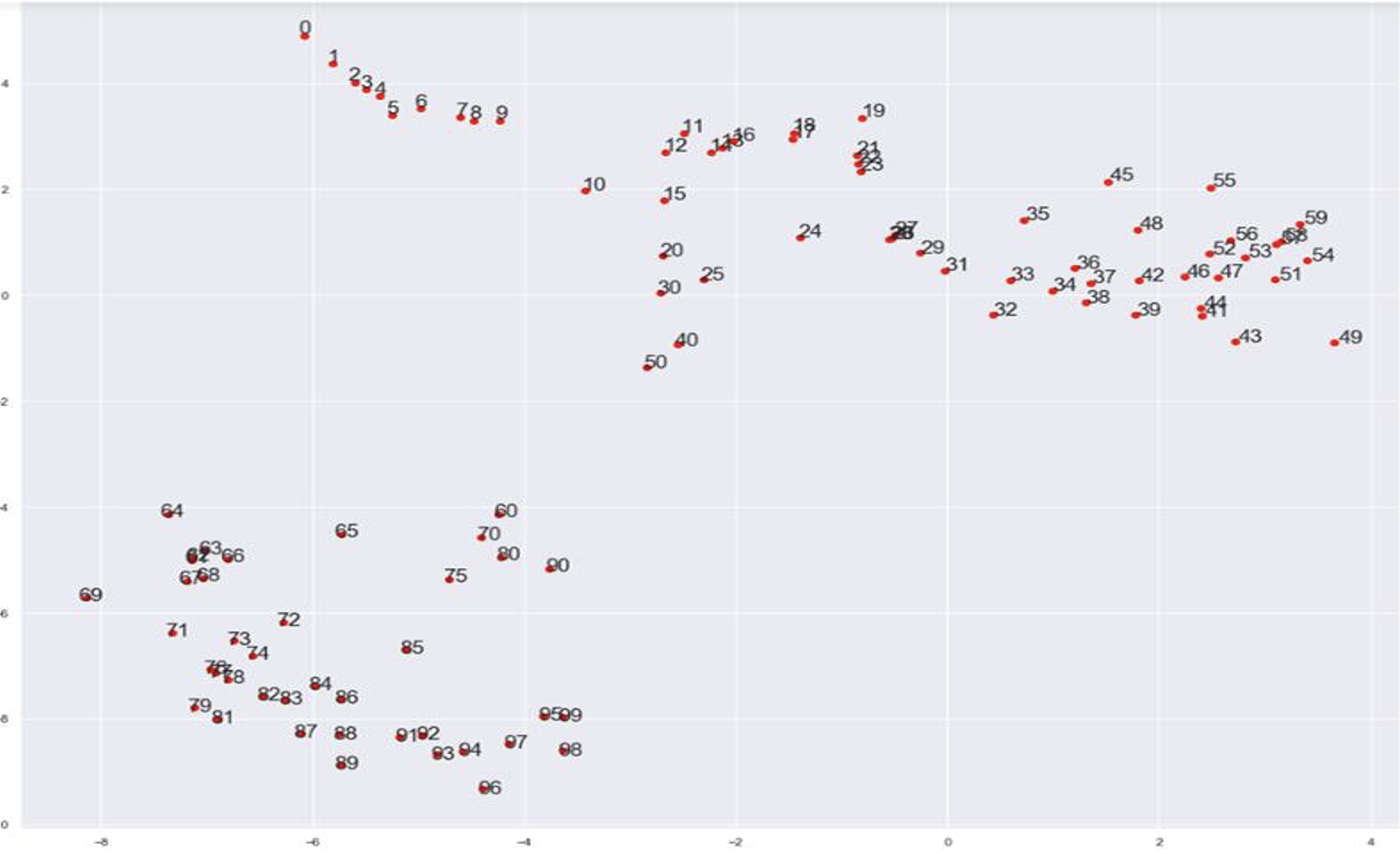
This is a t-SNE I made a couple of years ago of the glove-wordvectors for numbers. So it's not surprising that there is a "number sense", though I am definitely surprised how good some of the results are.
Fun fact: Fitting the Iris dataset with a tiny neural network can be suprisingly fickle.
Great write-up. Inspired me to try how much further ICL could go beyond "simpler" mappings (OP shows pretty nice results for two linear and two quadratic functions). As such, I tried a damped sinusoid:
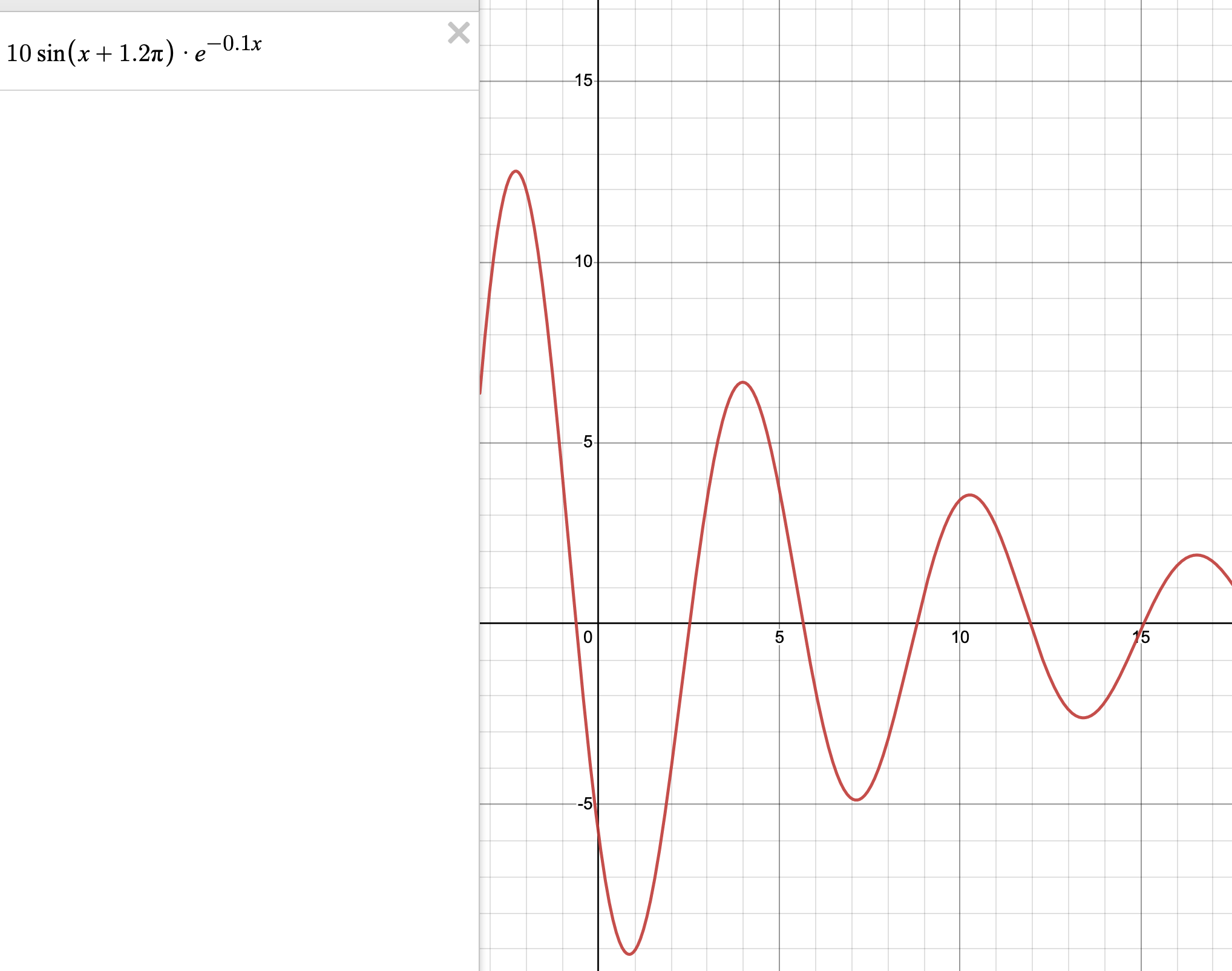
with the prompt:
x=3.984, y=6.68
x=2.197, y-2.497
x=0.26, y=-7.561
x=6.025, y=-1.98
x=7.126, y=-4.879
x=8.584, y=-0.894
x=9.97, y=3.403
x=11.1, y=2.45
x=12.09, y=-0.452
x=13.72, y=-2.48
x=14.81, y=-0.606
x=10, y=but didn't get any luck. Maybe I need more points, especially around the troughs and valleys.