(UPDATE: For a revised-and-improved version of this post, see this later post I wrote (especially Section 6.2.2).)
I’ve been playing around with a hypothesis about how decision-making is laid out in the human brain. Regular readers of my posts have seen this multiple times before; in particular I discussed it in great detail in Big Picture of Phasic Dopamine. But that’s a long post covering many topics, and recently I've found that I keep wanting to talk about (and solicit feedback about) just this one thing.
So here it is in brief, stripped of all the details, justifications, uncertainties, references, etc. Email me or comment at the lesswrong crosspost if you want to discuss, tell me I’m wrong, etc.
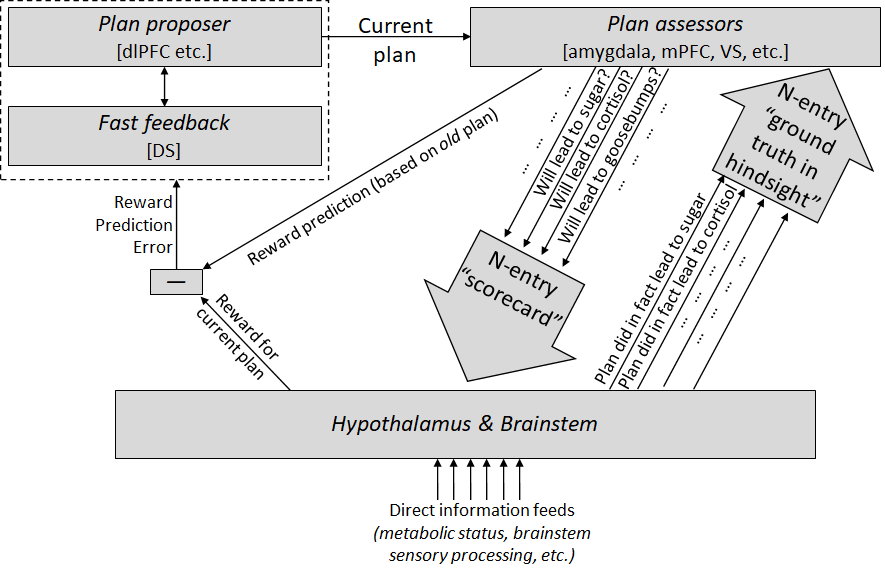
The model, in four steps
Step 1 (top-left of the diagram): there are parts of the cortex (dorsolateral prefrontal cortex, hippocampus) that propose thoughts, plans, etc. You can think of these as having some attractor dynamics or whatever, such that you start with a bubbly soup of partially-formed mutually-incompatible sub-thoughts, and then they quickly settle into a stable, fully-formed thought. The striatum intervenes during this process, making a quick rough guess at how promising the different pieces look, suppressing the less promising bits and enhancing the more promising bits, so that when you get a fully-formed thought, it’s likelier to be fairly promising.
Step 2 (top-right of the diagram): once you have a stable fully-formed thought, various other parts of the brain (mainly medial prefrontal cortex, anterior cingulate cortex, ventral striatum, amygdala, hippocampus (sorta)) “assess” that thought according to maybe dozens-to-hundreds of genetically-hardcoded criteria like “If I'm gonna do this plan, how appropriate would it be to cringe? To salivate? To release cortisol? To laugh? How much salt would I wind up eating? How much umami?” Etc. etc. And they send this scorecard down to the hypothalamus and brainstem.
Step 3 (bottom of the diagram): Finally, we're at the hypothalamus & brainstem. They look at the scorecard from the previous step, and they combine that information with other information streams that they have access to, like metabolic status information—if I'm hungry, a plan that will involve eating gets extra points, whereas if I’m over-full, the same plan would lose points. Taking all that information into account, they make the final decision as to whether the plan is good or bad, and relay that decision back to the proposer as a (positive or negative) dopamine signal. If the thought / plan is bad then it gets immediately suppressed; if the thought / plan is good then it gets strengthened and stabilized so it can start orchestrating motor commands and so on. (I'm oversimplifying by glossing over the "reward prediction" part for the moment; see below.)
Step 4 (left and right sides of the diagram): Learning algorithms make steps 1 & 2 get better over time. Step 1 improves because we learn to propose better plans, by treating the step 3 decisions as ground truth. Step 2 improves because the brainstem can sometimes recognize inaccurate assessments (in hindsight) and issue corrections. For example, if a plan gets a high score in the “will involve eating lots of food” category, and then the plan is executed, but you don’t wind up eating any food, then the hypothalamus & brainstem notice the discrepancy and send up a training signal to tweak the “will involve eating lots of food” assessment calculator. (The learning algorithms here are classified as “reinforcement learning” for step 1 and “supervised learning” for step 2.)
OK I suck at brevity, here’s just a couple side-notes:
- One of the Step 2 assessments is "reward prediction", i.e. a prediction about what the decision will be in step 3. Then we subtract that from the actual step 3 decision to get Reward Prediction Error (RPE), which is helpful for various reasons. In particular, when you switch from one plan to a different one, it turns out that RPE<0 corresponds to "this new plan is worse than the old one". And appropriately, that's the condition under which the new plan gets thrown out, allowing the old one to come back.
- I can’t resist mentioning that this system seems beautifully compatible with my poorly-researched sketchy theory of how the brain solves the “symbol grounding” problem for social instincts. The idea is: sometimes the proposed “thought” happens to be a brief empathetic simulation of another person, and then the Step 2 “scorecard” gives the brainstem information about what that other person is feeling. Then the brainstem can trigger various reactions associated with jealousy, pride, etc. at appropriate times.
Again, much more at Big Picture of Phasic Dopamine.