(Last revised: July 2024. See changelog at the bottom.)
8.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series.
Thus far in the series, Post #1 set up my big picture motivation: what is “brain-like AGI safety” and why do we care? The subsequent six posts (#2–#7) delved into neuroscience. Of those, Posts #2–#3 presented a way of dividing the brain into a “Learning Subsystem” and a “Steering Subsystem”, differentiated by whether they have a property I call “learning from scratch”. Then Posts #4–#7 presented a big picture of how I think motivation and goals work in the brain, which winds up looking kinda like a weird variant on actor-critic model-based reinforcement learning.
Having established that neuroscience background, now we can finally switch in earnest to thinking more explicitly about brain-like AGI. As a starting point to keep in mind, here’s a diagram from Post #6, edited to describe brain-like AGI instead of actual brains:
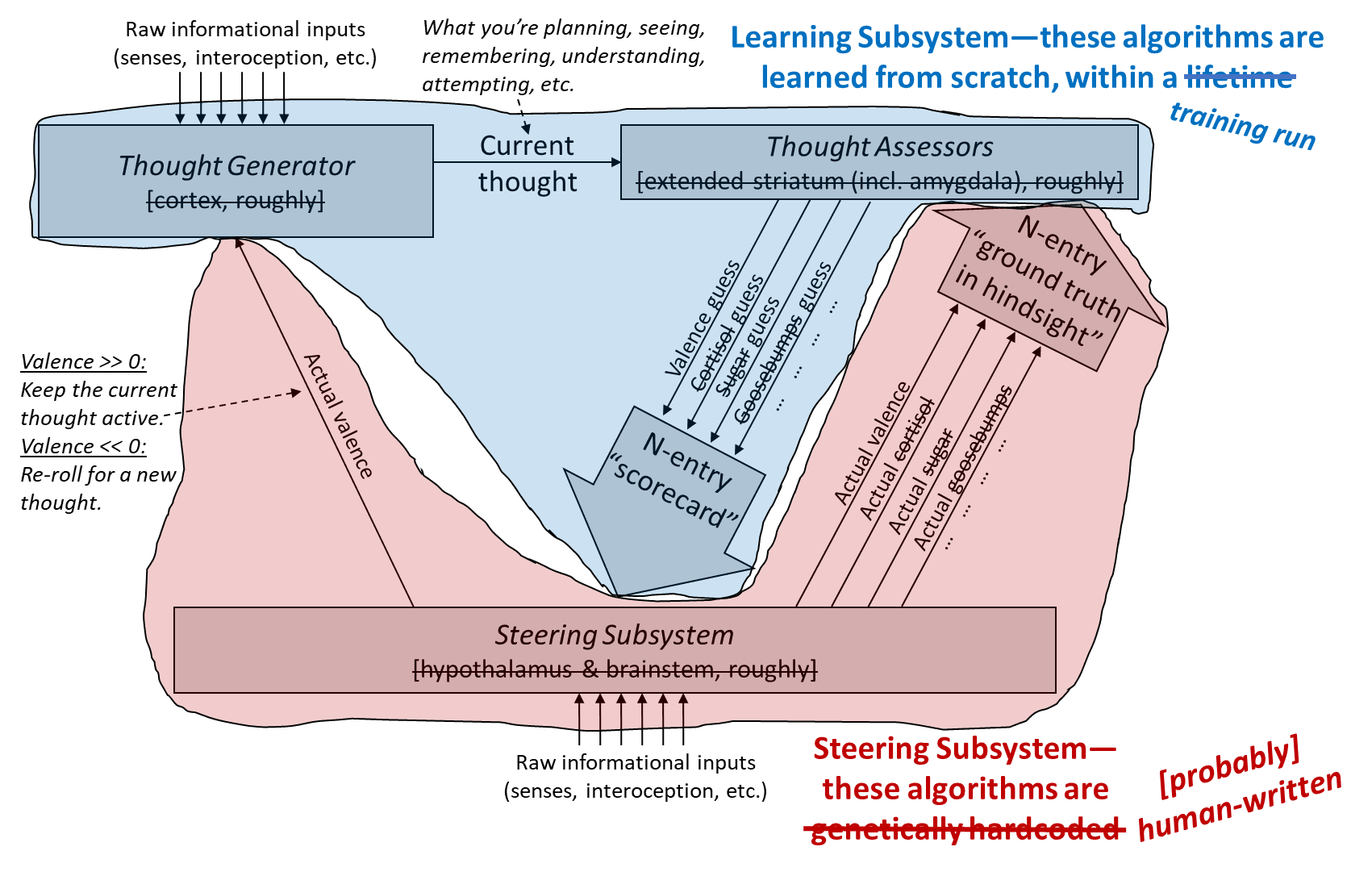
This and the next post will extract some lessons about brain-like AGI from the discussion thus far. This post will focus on how such an AGI might be developed, and the next post will discuss AGI motivations and goals. After that, Post #10 will discuss the famous “alignment problem” (finally!), and then there will be some posts on possible paths towards a solution. Finally, in Post #15 I’ll wrap up the series with open questions, avenues for future research, and how to get involved in the field.
Back to this post. The topic is: given the discussion of neuroscience in the previous posts, how should we think about the software development process for brain-like AGI? In particular, what will be the roles of human-written source code, versus adjustable parameters (“weights”) discovered by learning algorithms?
Table of contents:
- Section 8.2 suggests that, in a brain-like AGI development process, “an animal’s lifetime” would be closely analogous to “a machine learning training run”. I discuss how long such training runs might take: notwithstanding the example of humans, who take years-to-decades to reach high levels of competence and intelligence, I claim that a brain-like AGI could plausibly have a training time as short as weeks-to-months. I also argue that brain-like AGI, like brains, will work by online learning rather than train-then-deploy, and I discuss some implications for economics and safety.
- Section 8.3 discusses the possibility of “outer-loop” automated searches analogous to evolution. I’ll argue that these are likely to play at most a minor role, perhaps for optimizing hyperparameter settings and so on, and not to play a major role wherein the outer-loop search is the “lead designer” that builds an algorithm from scratch, notwithstanding the fact that evolution did in fact build brains from scratch historically. I’ll discuss some implications for AGI safety.
- Section 8.4: While I expect the “Steering Subsystem” of a future AGI to primarily consist of human-written source code, there are some possible exceptions, and here I go through three of them: (1) There could be pre-trained image classifiers or other such modules, (2) there could be AGIs that “steer” other AGIs, and (3) there could be human feedback.
8.2 “One Lifetime” turns into “One training run”
The brain-like-AGI equivalent of “an animal’s lifetime” is “a training run”. Think of this as akin to the model training runs done by ML practitioners today.
8.2.1 How long does it take to train a model?
How long will the “training run” be for brain-like AGI?
As a point of comparison, in the human case, my humble opinion is that humans really hit their stride at age 37 years, 4 months, and 14 days. Everyone younger than that is a naïve baby, and everyone older than that is an inflexible old fogey. Oops, did I say “14 days”? I should have said “21 days”. You’ll have to forgive me for that error; I wrote that sentence last week, back when I was a naïve baby.
Well, whatever the number is for humans, we can ask: Will it be similar for brain-like AGIs? Not necessarily! See my post Brain-inspired AGI and the “lifetime anchor” (Sec. 6.2) for my argument that the wall-clock time required to train a brain-like AGI from scratch to a powerful general intelligence is very hard to anticipate, but could plausibly wind up being as short as weeks-to-months, rather than years-to-decades.
8.2.2 Online learning implies no fundamental training-versus-deployment distinction
The brain works by online learning: instead of having multiple “episodes” interspersed by “updates” (the more popular approach in ML today), the brain is continually learning as it goes through life. I think online learning is absolutely central to how the brain works, and that any system worthy of the name “brain-like AGI” will be an online learning algorithm.
To illustrate the difference between online and offline learning, consider these two scenarios:
- During training, the AGI comes across two contradictory expectations (e.g. “demand curves usually slope down” & “many studies find that minimum wage does not cause unemployment”). The AGI updates its internal models to a more nuanced and sophisticated understanding that can reconcile those two things. Going forward, it can build on that new knowledge.
- During deployment, the exact same thing happens, with the exact same result.
In the online-learning, brain-like-AGI case, there’s no distinction. Both of these are the same algorithm doing the same thing.
By contrast, in offline-learning ML systems (e.g. Large Language Models (LLMs)), these two cases would be handled by two different algorithmic processes. Case #1 would involve changing the model weights, while Case #2 would not. Instead, Case #2 would solely involve changing the model activations.
To me, this is a huge point in favor of the plausibility of the online learning approach. It only requires solving the problem once, rather than solving it twice in two different ways. And this isn’t just any problem; it’s sorta the core problem of AGI!
I really want to reiterate what a central role online learning plays in brains (and brain-like AGIs). A human without online learning is a human with complete anterograde amnesia. If you introduce yourself to me as “Fred”, and then 60 seconds later I refer to you as “Fred”, then I can thank online learning for putting that bit of knowledge into my brain.
8.2.3 …Nevertheless, the conventional ML wisdom that “training is more expensive than deployment” still more-or-less applies
In current ML, it’s common knowledge that training is far more expensive than deployment. For example, OpenAI spent >$100 million to train GPT-4—i.e., to get the magical list of a trillion or so numbers that comprise GPT-4’s weights. But now that they have that list of a trillion numbers in hand, running GPT-4 is dirt cheap—perhaps a few cents per page of generated text.
Thanks to online learning, brain-like AGI would have no fundamental distinction between training and deployment, as discussed in the previous section. However, the economics wind up being similar.
Imagine spending decades raising a child from birth until they were a skilled and knowledgeable adult, perhaps with advanced training in math, science, engineering, programming, etc.
Then imagine you have a sci-fi duplication machine that could instantly create 1000 copies of that adult. You send them to do 1000 different jobs. Granted, each of the copies would probably need additional on-the-job training to get up to speed. But they wouldn’t need decades of additional training, the way it took decades of training to get them from birth to adulthood. (More discussion at Holden Karnofsky’s blog.)
So, just like normal ML, there is a big fixed cost to training, and this cost can in principle be amortized over multiple copies.
(However, interestingly, the ratio of training compute to deployment compute is large for human brains, but very much larger for LLMs—see discussion here.)
8.2.4 Online learning is bad for safety, but essential for capabilities
I claim that online learning creates nasty problems for AGI safety. Unfortunately, I also claim that if we’re going to build AGI at all, we need online learning, or something with similar effects. Let me elaborate on both these claims:
Online learning is bad for safety:
Let’s switch to humans. Suppose I’m just now being sworn in as president of a country, and I want to always keep my people’s best interests at heart, and not get drawn in by the siren song of corruption. What can I do right now, in order to control how my future self will behave? It’s not straightforward, right? Maybe it’s not even possible!
There just isn’t a natural and airtight way for current-me to dictate what future-me will want to do. The best I can do is lots of little hacks, where I anticipate particular problems and try to preempt them. I can tie my own hands by giving an honest accountant all my bank account passwords, and asking her to turn me in if she sees anything fishy. I can have regular meetings with a trustworthy and grounded friend. Things like that may help on the margin, but again, there’s no reliable solution.
In an analogous way, we can have an AGI that is right now trying in good faith to act ethically and helpfully. Then we keep it running for a while. It keeps thinking new thoughts, it keeps having new ideas, it keeps reading new books, and it keeps experiencing new experiences. Will it still be trying in good faith to act ethically and helpfully six months later? Maybe! Hopefully! But how can we be sure? This is one of many open questions in AGI safety.
(Maybe you’re thinking: We could periodically boot up a snapshot of AGI-now, and give it veto-power over aspects of AGI-later? I think that’s a reasonable idea, maybe even a good idea. But it’s not a panacea either. What if AGI-later figures out how to trick or manipulate AGI-now? Or what if AGI-later has changed for the better, and AGI-now winds up holding it back? I mean, my younger self was a naïve baby!)
Online learning (or something with similar safety issues) is essential for capabilities:
I expect AGIs to use online learning because I think it’s an effective method of making AGI—see the “solving the problem twice” discussion above (Section 8.2.2).
That said, I can imagine other possible setups that are not “online learning” per se, but which have similar effects, and which pose essentially the same challenges for safety, i.e. making it difficult to ensure that an initially-safe AGI continues to be safe.
I have a much harder time imagining any way to avoid those safety issues altogether. Consider:
- If the AGI can think new thoughts and have new ideas and learn new knowledge “in deployment”, then we would seem to be facing this goal-instability problem I’m talking about. (See, for example, the problem of “ontological crises”; more on this in future posts.)
- If the AGI can’t do any of those things, then is it really an AGI? Will it really be capable of doing the things we want AGI to do, like coming up with new concepts and inventing new technology? I suspect not. More on this at “Why I want to move the goalposts on ‘AGI’”.
8.3 Evolution-like outer-loop automated searches: maybe involved, but not the “lead designer”
“Outer loop” is a programming term for the outer of two nested control-flow loops. Here, the “inner loop” might be code that simulates a virtual animal’s life, second by second, from birth to death. Then an “outer-loop search” would involve simulating lots of different animals, each with a different brain setup, in search of one that (in adulthood) displays maximum intelligence. Within-lifetime learning happens in the inner loop, whereas an outer-loop search would be analogous to evolution.
There’s an extreme version of outer-loop-centric design, where (one might suppose) humans will write code that runs an evolution-like outer-loop algorithm, and this algorithm will build an AGI from scratch.
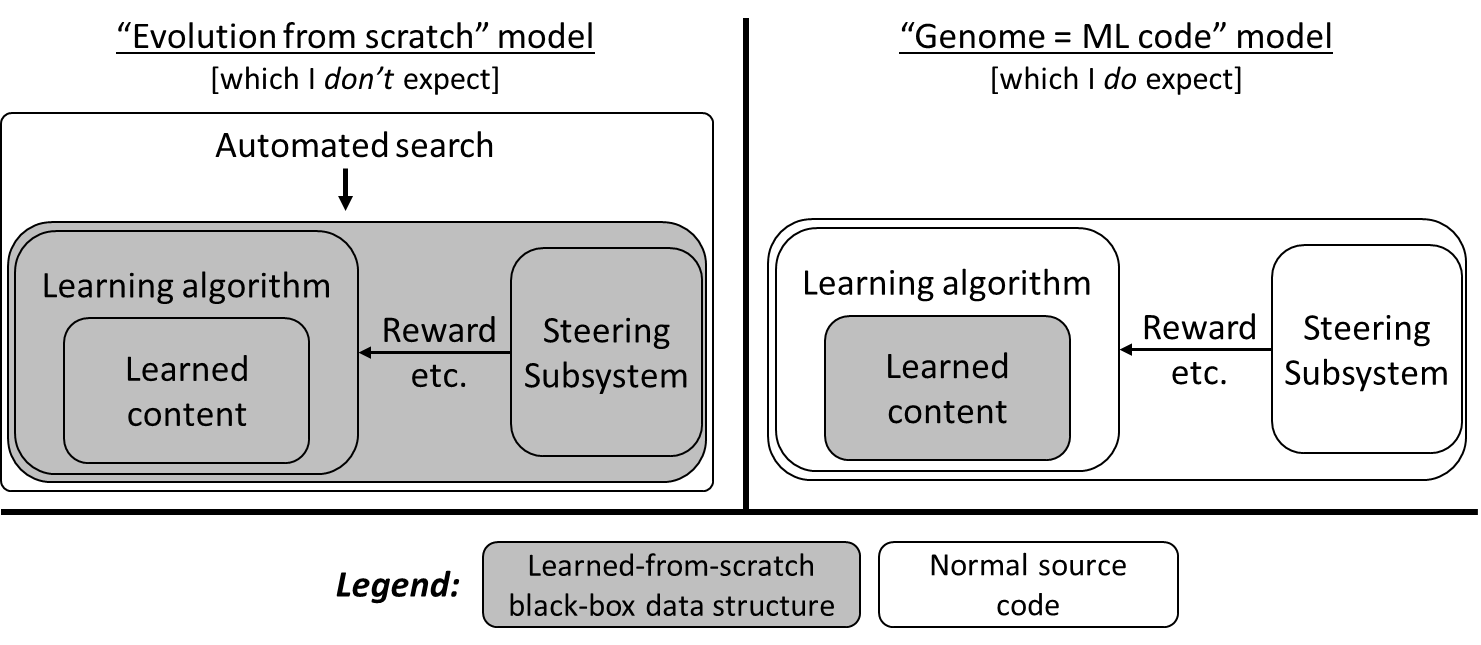
The evolution-from-scratch approach (left) is discussed with some regularity in the technical AGI safety literature—see Risks From Learned Optimization and dozens of other posts about so-called “mesa-optimizers”.
However, as noted in the diagram, this evolution-from-scratch approach is not how I expect people to build AGI, for reasons explained shortly.
That said, I’m not totally opposed to the idea of outer-loop searches; I expect them to be present with a more constrained role. In particular, when future programmers write a brain-like AGI algorithm, the source code will have a number of adjustable parameters for which it won’t be obvious a priori what settings are optimal. These might include, for example, learning algorithm hyperparameters (such as learning rates), various aspects of neural architecture, and coefficients adjusting the relative strengths of various innate drives.
I think it’s quite plausible that future AGI programmers will use an automated outer-loop search to set many or all of these adjustable parameters.
(Or not! For example, as I understand it, the initial GPT-3 training run was so expensive that it was only done once, with no hyperparameter tuning. Instead, the hyperparameters were all studied systematically in smaller models, and the researchers found trends that allowed them to extrapolate to the full model size.)
(None of this is meant to imply that learning-from-scratch algorithms don’t matter for brain-like AGI. Quite the contrary, they will play a huge role! But that huge role will be in the inner loop—i.e., within-lifetime learning. See Post #2.)
8.3.1 The “Genome = ML code” analogy
In the above diagram, I used the term “genome = ML code”. That refers to an analogy between brain-like AGI and modern machine learning, as spelled out in this table:
| “Genome = ML code” analogy | |
| Human intelligence | Today’s machine learning systems |
| Human genome | GitHub repository with all the PyTorch code for training and running the Pac-Man-playing agent |
| Within-lifetime learning | Training the Pac-Man-playing agent |
| How an adult human thinks and acts | Trained Pac-Man-playing agent |
| Evolution | Maybe the ML researchers did an outer-loop search for a handful of human-legible adjustable parameters—e.g., automated hyperparameter tuning, or neural architecture search. |
8.3.2 Why I think “evolution from scratch” is less likely (as an AGI development method) than “genome = ML code”
(See also my post from March 2021: Against evolution as an analogy for how humans will create AGI.)
I think the best argument against the evolution-from-scratch model is continuity: “genome = ML code” is how machine learning works today. Open a random reinforcement learning paper and look at the learning algorithm. You’ll see that it is human-legible, and primarily or entirely human-designed—perhaps involving things like gradient descent, TD-learning, and so on. Ditto for the inference algorithm, the reward function, etc. At most, the learning algorithm source code will have a few dozens or hundreds of bits of information that came from outer-loop search, such as the particular values of some hyperparameters, comprising a tiny share of the “design work” that went into the learning algorithm.[1]
Also, if extreme outer-loop search were really the future, I would expect that we would see today that the ML projects that rely most heavily on outer-loop search would be overrepresented among the most impressive, headline-grabbing, transformative results. That doesn’t seem to be the case at all, as far as I can tell.
I’m merely suggesting that this pattern will continue—and for the same reason it’s true today: humans are pretty good at designing learning algorithms, and meanwhile, it’s extraordinarily slow and expensive to do outer-loop searches over learning algorithms.
(Granted, things that are “extraordinarily slow and expensive” today will be less so in the future. However, as time passes and future ML researchers can afford more compute, I expect that they, like researchers today, will typically “spend” that windfall on bigger models, better training procedures, and so on, rather than “spending” it on a larger outer-loop search space.)
Given all that, why do some people put a lot of stock in the “evolution-from-scratch” model? I think it comes down to the question: Just how hard would it be to write the source code involved in the “genome = ML code” model?
If your answer is “it’s impossible”, or “it would take hundreds of years”, then evolution-from-scratch wins by default! On this view, even if the outer-loop search takes trillions of dollars and decades of wall-clock time and gigawatts of electricity, well, that’s still the shortest path to AGI, and sooner or later some government or company will cough up the money and spend the time to make it happen.[2]
However, I don’t think that writing the source code of the “genome = ML code” model is a hundreds-of-years endeavor. Quite the contrary, I think it’s very doable, and that researchers in neuroscience & AI are making healthy progress in that direction, and that they may well succeed in the coming decades. For an explanation of why I think that, see my “timelines to brain-like AGI” discussion earlier in this series—Sections 2.8, 3.7, and 3.8.
8.3.3 Why “evolution from scratch” is worse than “genome = ML code” (from a safety perspective)
This is one of those rare cases where “what I expect to happen by default” is the same as “what I hope will happen”! Indeed, the “genome = ML code” model that I’m assuming in this series seems much more promising for AGI safety than the “evolution from scratch” model. Two reasons.
The first reason is human-legibility. In the “genome = ML code” model, the human-legibility is bad. But in the “evolution from scratch” model, the human-legibility is even worse!
In the former, the world-model is a big learned-from-scratch black-box data structure, as is the value function, etc., and we’ll have our work cut out understanding their contents. In the latter, there’s just one, even bigger, black box. We’ll be lucky if we can even find the world-model, value function, and so on, let alone understand their contents!
The second reason, as elaborated in later posts, is that careful design of the Steering Subsystem is one of our most powerful levers for controlling the goals and motivations of a brain-like AGI, such that we wind up with safe and beneficial behavior. If we write the Steering Subsystem code ourselves, we get complete control over how the Steering Subsystem works, and visibility into what it’s doing as it runs. Whereas if we use the evolution-from-scratch model, we’ll have dramatically less control and understanding.
To be clear, AGI safety is an unsolved problem even in the “genome = ML code” case. I’m saying that the evolution-from-scratch AGI development approach would seemingly make it even worse.
(Note for clarity: this discussion is assuming that we wind up with “brain-like AGI” in either case. I’m not making any claims about brain-like AGI being more or less safe than non-brain-like AGI, assuming the latter exists.)
8.3.3.1 Is it a good idea to build human-like social instincts by evolving agents in a social environment?
A possible objection I sometimes hear is something like: “Humans aren’t so bad, and evolution designed our Steering Subsystems, right? Maybe if we do an evolution-like outer-loop search process in an environment where multiple AGIs need to cooperate, they’ll wind up with altruism and other such nice social instincts!” (I think this kind of intuition is the motivation behind projects like DeepMind Melting Pot.)
I have three responses to that.
- First, my impression (mainly from reading Richard Wrangham’s The Goodness Paradox) is that there are huge differences between human social instincts, and chimpanzee social instincts, and bonobo social instincts, and wolf social instincts, and so on. For example, chimpanzees and wolves have dramatically higher “reactive aggression” than humans and bonobos, though all four are intensely social. The evolutionary pressures driving social instincts are a sensitive function of the power dynamics and other aspects of social groups, possibly with multiple stable equilibria, in a way that seems like it would be hard to control by tweaking the knobs in a virtual environment.
- Second, if we set up a virtual environment where AGIs are incentivized to cooperate with AGIs, we’ll get AGIs that have cooperative social instincts towards other AGIs in their virtual environment. But what we want is AGIs that have cooperative social instincts towards humans in the real world. A Steering Subsystem that builds the former might or might not build it in a way that generalizes to the latter. Humans, I note, are often compassionate toward their friends, but rarely compassionate towards members of an enemy tribe, or towards factory-farmed animals, or towards large hairy spiders.
- Third, human social instincts leave something to be desired! For example, it has been argued (plausibly in my opinion) that a low but nonzero prevalence of psychopathy in humans is not a random fluke, but rather an advantageous strategy from the perspective of selfish genes as studied by evolutionary game theory. Likewise, evolution seems to have designed humans to have jealousy, spite, teenage rebellion, bloodlust, and so on. And that’s how we want to design our AGIs?? Yikes.
8.4 Other non-hand-coded things that might go in a future brain-like-AGI Steering Subsystem
As discussed in Post #3, I claim that the Steering Subsystem in mammal brains (i.e., hypothalamus and brainstem) consists of genetically-hardcoded algorithms. (For discussion and caveats, see Post #2, Section 2.3.3.)
When we switch to AGI, my corresponding expectation is that future AGIs’ Steering Subsystems will consist of primarily human-written code—just as today’s RL agents typically have human-written reward functions.
However, it may not be completely human-written. For one thing, as discussed in the previous section, there may be a handful of adjustable parameters set by outer-loop search, e.g. coefficients controlling the relative strengths of different innate drives. Here are three other possible exceptions to my general expectation that AGI Steering Subsystems will consist of human-written code.
8.4.1 Pre-trained image classifiers, etc.
Plausibly, an ingredient in AGI Steering Subsystem code could be something like a trained ConvNet image classifier. This would be analogous to how the human superior colliculus has something-like-an-image-classifier for recognizing a prescribed set of innately-significant categories, like snakes and spiders and faces (see Post #3, Section 3.2.1). Likewise, there could be trained classifiers for audio or other sensory modalities.
8.4.2 A tower of AGIs steering AGIs?
In principle, in place of the normal Steering Subsystem, we could have a whole separate AGI that is watching the thoughts of the Learning Subsystem and sending appropriate rewards.
Heck, we could have a whole tower of AGIs-steering-AGIs! Presumably the AGIs would get more and more complex and powerful going up the tower, gradually enough that each AGI is up to the task of steering the one above it. (It could also be a pyramid rather than a tower, with multiple dumber AGIs collaborating to comprise the Steering Subsystem of a smarter AGI.)
I don’t think this approach is necessarily useless. But it seems to me that I still haven’t even gotten past the first step, where we make any safe AGI. Building a tower of AGIs-steering-AGIs does not avert the need to make a safe AGI in a different way. After all, the tower needs a base!
Once we solve that first big problem, then we can think about whether to use that new AGI directly to solve human problems, or to use it indirectly, by having it steer even-more-powerful AGIs, analogously to how we humans are trying to steer the first AGI.
Of those two possibilities, I lean towards “use that first AGI directly” being a more promising research direction than “use that first AGI to steer a second, more powerful, AGI”. But I could be wrong. Anyway, we can cross that bridge when we get to it.
8.4.3 Humans steering AGIs?
If an AGI’s Steering Subsystem can (maybe) be another AGI, then why can’t it be a human?
Answer: if the AGI is running at human brain speed, maybe it would be thinking 10 thoughts per second (or something). Each “thought” would need a corresponding reward and maybe dozens of other ground-truth signals. A human would never be able to keep up!
What we can do is have human feedback be an input into the Steering Subsystem. For example, we could give the humans a big red button that says “REWARD”. (We probably shouldn’t, but we could.) We can also have other forms of human involvement, including ones with no biological analog—we should keep an open mind.
Changelog
July 2024: Since the initial version, there are no interesting changes to speak of. I’ve just updated links, fixed wording, etc. I have also updated the diagrams in line with changes to the similar diagrams in previous posts.
- ^
For example, here’s a random neural architecture search (NAS) paper: “The evolved transformer”. The authors brag about their “large search space”, and it is a large search space by the standards of NAS. But searching through that space still yields only 385 bits of information, and the end result fits in one easily-human-legible diagram in the paper. By contrast, the weights of an ML trained model may easily comprise millions or billions of bits of information, and the end result requires heroic effort to understand. We can also compare those 385 bits to the number of bits of information in the human-created parts of the learning algorithm source code, such as the code for matrix multiplication, softmax, autograd, shuttling data between the GPU and the CPU, and so on. The latter parts comprise orders of magnitude more than 385 bits of information. This is what I mean when I say that things like hyperparameter tuning and NAS contribute a tiny proportion of the total “design work” in a learning algorithm.
(The most outer-loop-search-reliant paper that I know of is AutoML-Zero, and even there, the outer-loop search contributed effectively 16 lines of code, which the authors had no trouble understanding.)
- ^
If you’re curious for some ballpark estimates of how much time and money would it take to perform an amount of computation equivalent to the entire history of animal evolution on Earth, see the “Evolution anchor” discussion in Ajeya Cotra’s 2020 draft report on biological anchors. Obviously, this is not exactly the same as the amount of computation required for evolution-from-scratch AGI development, but it’s not entirely irrelevant either. I won’t talk about this topic more; I don’t think it’s important, because I don’t think evolution-from-scratch AGI development will happen anyway.