UPDATE MARCH 2022: I later revised and improved this post—see [Intro to brain-like-AGI safety] 7. From hardcoded drives to foresighted plans: A worked example. I’m leaving this old version here, but I strongly suggest you click over to the later version instead. Goodbye!
We start out as infants knowing nothing of the world. Then many years later, we have various complex conscious explicit goals, like “I want to get out of debt”, and we take foresighted action in pursuit of those goals. What algorithms can get us from here to there? In this post I’m going to work through an example. To summarize and simplify a bit, the steps will be:
- We gradually develop a probabilistic generative model of the world and ourselves;
- There’s a “credit assignment” process, where something in the world-model gets flagged as “good”;
- There’s a reward prediction error signal roughly related to the time-derivative of the expected probability of the “good” thing. This signal drives us to “try” to make the “good” thing happen, including via foresighted planning.
To make things a bit simpler, I won’t talk about “I want to get out of debt” here. I’ll do a simpler example instead. Let’s say (purely hypothetically… 👀) that I ate a slice of prinsesstårta cake a couple years ago, and it was really yummy, and ever since then I’ve wanted to eat one again.
So my running example of an explicit goal in this post will be “I want a slice of prinsesstårta”.
It’s not my only goal in life, or even a particularly important one—so it has to trade off against my other goals and desires—but it is nevertheless a goal of mine (at least when I’m thinking about it), and I would indeed make complicated foresighted plans to try bring about that goal, like dropping subtle hints to my family … in blog posts … when my birthday is coming up. Purely hypothetically!!
Big-picture context: As in most of my posts, the subtext is that researchers may someday make AGI algorithms that resemble human brain algorithms—after all, loads of people in neuroscience and AI are trying to do exactly that as we speak. And if those researchers successfully do that, then we’ll want to have a good understanding of how (and indeed whether) we can sculpt those AGIs’ motivations such that the AGIs are robustly trying to do the things we want them to be trying to do. I don't know the answer to that question, and nobody else does either. But one relevant data-point towards answering that question is "how does the analogous thing work in human brains?". To be clear, I'm talking here about within-lifetime learning, not evolution-as-a-learning-algorithm, for reasons discussed here.
Also as usual, this is all based on my personal best current understanding of aspects of the human brain, and I could well be wrong, or missing important things.
Background on motivation and brainstem-supervised learning
As required background, here’s my diagram of decision-making, motivation, and reinforcement learning in the brain:
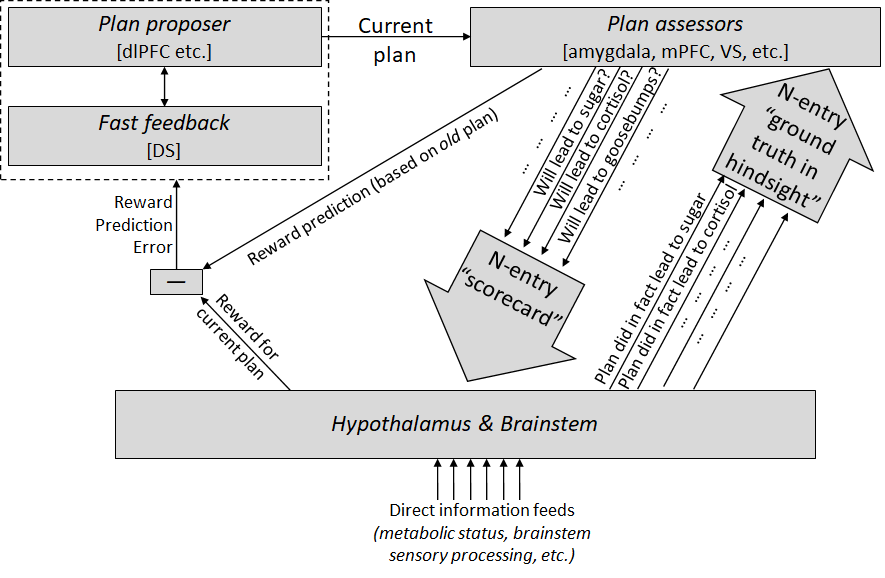
An important aspect of this for this post is that I’m suggesting that some parts (the hypothalamus and brainstem) are (to a first approximation) entirely genetically-hardcoded, while other parts (the “plan proposer” and “plan assessors”) are AFAICT “trained models” in ML terminology—they’re initialized from random weights (or something equivalent) at birth, and learned within a lifetime. (See discussion of “learning-from-scratch-ism” here.) Here’s an illustration:

(The reward prediction error on the left comes from subtracting a trained model output from a genetically-hardcoded algorithm output, so I left it uncolored.)
1. Building a probabilistic generative world-model in the cortex
The first step is that, over my lifetime, my cortex builds up a probabilistic generative model, mostly by self-supervised (a.k.a. predictive) learning.
Basically, we learn patterns in our sensory input, and patterns in the patterns, etc., until we have a nice predictive model of the world (and of ourselves)—a giant web of interconnected entries like “grass” and “standing up” and “slices of prinsesstårta cake” and so on.
Note that I left predictive learning off of the diagram above. Sorry! I didn't want it to be too busy. Anyway, predictive learning lives inside the “plan proposer”. A plan is just a special case of a “thought”, and a “thought” is some configuration of this generative world-model.
Every thought I can possibly think, and every plan I can possibly plan, can be represented as some configuration of this world-model data structure. The data structure is also continually getting edited, as I learn and experience new things.
When you think of this data structure, imagine many gigabytes or terabytes of inscrutable entries like "PATTERN 8472836 is defined as the sequence PATTERN 278561 followed by PATTERN 6578362 followed by...", or whatever. Some entries have references to sensory inputs or motor outputs. And that giant inscrutable mess comprises my entire understanding of the world and myself.
2. Credit assignment when I first bite into the cake
As I mentioned, two years ago I ate a slice of prinsesstårta cake, and it was really good.
Step back to a couple seconds earlier, as I was bringing the cake towards my mouth to take my first-ever bite. At that moment, I didn’t yet have any particularly strong expectation of what it would taste like, or how it would make me feel. But once it was in my mouth, mmmmmmm, yummy.

So, as I took that bite, my body had a suite of autonomic reactions—releasing certain hormones, salivating, changing my heart rate and blood pressure, etc. etc. Why? The key is that, as a rule, all sensory inputs split:
- One copy of any given sensory signal goes to the learning-from-scratch subsystem, to be integrated into the predictive world-model. (I omitted that from the diagram above.)
- A second copy of the same signal goes to the hypothalamus & brainstem system, where it serves as an input to genetically-hardwired circuitry. (That’s the “Direct information feeds” at the bottom of the diagram above.)
Taste bud inputs are no exception: the former signal winds up at the insula (part of the neocortex), the latter at the medulla (part of the brainstem). The latter feeds into hardcoded brainstem circuits, which, when prompted with the taste and mouth-feel of the cake, and also accounting for my current physiological state and so on, executed all those autonomic reactions I mentioned.
As I mentioned, before I first bit into the cake, I didn’t expect it to be that good. Well, maybe intellectually I expected it—like if you had asked me, I would have said and believed that the cake would be really good. But I didn’t viscerally expect it. What do I mean by that? What’s the difference? The things I viscerally expect are over on the “plan assessor” side. People don’t have conscious control over their plan assessors—the latter are trained exclusively by the “ground truth in hindsight signals” from the brainstem. I can manipulate the assessors a bit on the margin, e.g. by re-framing the way I think about things (see here), but by and large they’re doing their own thing, independent of what I want them to be doing. (From an evolutionary perspective, this design makes good sense as a defense against wireheading—see here.)
So when I bit into the cake, my “plan assessors” were wrong! They expected the cake to cause mild “yummy”-related autonomic reactions, but in fact it caused intense “yummy”-related autonomic reactions. And the brainstem knows that the plan assessors were wrong. So it sends correction signals up to the “plan assessor” algorithms, as shown in the diagram above. Those algorithms thus edit themselves so that next time I bring a fork-full of prinsesstårta towards my mouth, they will be more liable to predict intense hormones, goosebumps, and all the other reactions that I did in fact get.
A cool thing just happened here. We started with a simple-ish hardwired algorithm: brainstem / hypothalamus circuits turning certain types of taste inputs into certain hormones and autonomic reactions. But then we transferred that information into functions on the learned world-model—recall that giant inscrutable database I was talking about in the previous section. This step, which we might call “credit assignment”, is a bit fraught; it’s some hardcoded model-updating algorithm (akin to backprop, although probably not literally that), and it’s based on heuristics, and it might sometimes assign credit to the wrong thing—cf. superstitions!
But in this case, the credit-assignment (a.k.a. plan-assessment model update) process went smoothly: I already had some world-model concept that we might describe as “myself eating prinsesstårta”, and probably the main change was: from that point on, the plan assessors will know that whenever the “myself eating prinsesstårta” concept “lights up” in the world-model, they should issue predictions of the corresponding hormones and other reactions.
3. Planning towards goals via reward-shaping
I don’t have a particularly rigorous model for this step, but I think I can lean on intuitions a bit, in order to fill in the rest of the story:

Remember, ever since my first bite of prinsesstårta two years ago in Step 2, the “plan assessors” in my brain have been looking at each thought I think, pattern-matching that thought to the “myself eating prinsesstårta” world-model concept, and to the extent that it’s a match, issuing a suggestion to prepare for delightful hormones, salivation, goosebumps, and so on.
The diagram above suggests a series of thoughts that I think would “pattern-match” better and better, from top to bottom.
To get the intuition here, maybe try replacing “prinsesstårta” with “super-salty cracker”. Then go down the list, and try to feel how each thought would make you salivate more and more. Or better yet, replace “eating prinsesstårta” with “asking my crush out on a date”, go down the list, and try to feel how each thought makes your heart rate jump up higher and higher.
Here's another way to think about it: If you imagine the world-model being vaguely like a PGM, you can imagine that the "degree of pattern-matching" corresponds roughly to the probability assigned to the “eating prinsesstårta” node in the PGM. For example, if you’re confident in X, and X weakly implies Y, and Y weakly implies Z, and Z weakly implies “eating prinsesstårta”, then “eating prinsesstårta” gets a very low but nonzero probability, a.k.a. weak activation, and this is kinda like having a far-fetched but not completely impossible plan to eat prinsesstårta. (Don’t take this paragraph too literally, I’m just trying to summon intuitions here.)
OK, if you’re still with me, let’s go back to my decision-making model, now with different parts highlighted:

Again, every time I think a thought, the hypothalamus & brainstem look at the corresponding “scorecard”, and issue a corresponding reward. Recall also (see here) that the active thought / plan gets thrown out when its reward prediction error (RPE) is negative, and it gets kept and strengthened when its RPE is positive.
Let’s oversimplify for a second, and say that the relevant prinsesstårta-related "assessments" comprise just one entry on the scorecard: “Will lead to feel-good hormones”. And let’s also assume the brainstem follows the simple rule: “The higher that a plan / thought scores on the ‘Will lead to feel-good hormones’ assessment, the higher the reward I’m gonna give it”. Well in that case, each time our thoughts move down the ranked list above—from idle musing about prinsesstårta, to a far-fetched plan to get prinsesstårta, to a plausible plan to get prinsesstårta, etc.—there’s an immediate positive RPE, so that the new thought gets strengthened, and gets to establish itself. And conversely each time we move back up the list—from plausible plan to far-fetched plan to idle musing—there’s an immediate negative RPE, so that thought gets thrown out and we go back to whatever we were thinking before. It's a ratchet! The system naturally pushes its way down the list, making and executing a good plan to eat cake.
(By the way, the plan-proposing algorithm on the top-left is NOT trying to maximize the sum of future rewards—see here, specifically the discussion of TD learning. Instead, its job is more like “maximize RPE right now”.)
So there you have it! From this kind of setup, I think we're well on the way to explaining the full suite of behaviors associated with humans doing foresighted planning towards explicit goals—including knowing that you have the goal, making a plan, pursuing instrumental strategies as part of the plan, replacing good plans with even better plans, updating plans as the situation changes, pining in vain for unattainable goals, and so on.
By the way, I oversimplified above by reducing the actual suite of prinsesstårta-related assessments with “will lead to feel-good hormones”. In reality, it’s more specific than that—probably some assessment related to salivating, and some other assessment related to releasing certain digestive enzymes, and various hormones, and goosebumps, and who knows what else.
Why does that matter? Well, imagine you’re feeling nauseous. Of course your hypothalamus & brainstem know that you’re feeling nauseous. And meanwhile the assessment functions are telling the hypothalamus & brainstem that this plan will lead to eating food. Some hardwired circuit says: “That’s bad! Whatever thought you’re thinking, I’m gonna dock some reward points for its possibly leading to eating, in my current state of nausea.”
...And indeed, I think you’ll find that you’re much less intrinsically motivated to make plans to get prinsesstårta, when you’re currently feeling nauseous. Maybe you’ll do it anyway, because thoughts can be quite complicated, and you have other motivations in life, and those motivations also feed into these assessment functions and get weighed by the brainstem. So maybe you'll proceed with the plan, driven by the motivation of “trying to avoid later regret, if I miss the deadline to order prinsesstårta in time for the party next week”. So you’ll order the cake anyway, despite it feeling kinda gross right now.