Introduction
So, we've found some new results about infradistributions, and accordingly, this post will be a miscellaneous grab-bag of results from many different areas. Again, this is a joint Vanessa/Diffractor effort. It requires having read "Basic Inframeasure Theory" as a mandatory prerequisite, and due to a bit less editing work this time around, it's advised to pester me for a walkthrough of this one, illusion of transparency is probably worse on this post than the previous two. Apart from the 8 proof sections (1, 2, 3, 4, 5, 6, 7, 8), included in this post is:
Section 1: We cover generalizations of the background mathematical setting of inframeasure theory to cover discontinuous functions, taking the expectation of functions outside of , and defining infradistributions over non-compact spaces. We'll also cover what "support" means for infradistributions, and why it becomes important when we go outside of compact spaces.
Section 2: We'll introduce various convenient properties that infradistributions might fulfill, from weakest to strongest, what they mean for the expectation functionals as well as the set of minimal points, and what they're used for.
Section 3: We present several operations to form new infradistributions from old ones, and talk about what they mean, both on the set side of LF-duality as well as the expectation functional side. We go more in-depth on things like semidirect product which were casually mentioned at the end of the last post, as well as some novel ones like pullback.
Section 4: We briefly introduce the basics of optimistic Knightian uncertainty, which we'll call ultradistributions, as opposed to pessimistic Knightian uncertainty/infradistributions. It's covered in only cursory depth, because they appear so closely parallel to our existing framework that if ultradistributions are ever required for something, it would be very easy to adapt the requisite results from the theory of infradistributions.
Section 5: We present our first major theorem, the analogue of the disintegration theorem from classical probability theory. It is a highly useful tool which gives the infra-version of conditional probability. Its use is more restricted than the probability theory analogue, but it lets you do things like derive the analogue of Bayes' rule when you have Knightian uncertainty as to the prior probability distribution over hypotheses. Also we have an analogue of Markov's inequality.
Section 6: This section addresses notions of distance between infradistributions. In particular, we have a notion of distance for infradistributions which, in the standard probabilistic case, reduces to the KR-metric we know and love. We characterize this metric and the space of infradistributions equipped with this metric in many different ways, including finding strongly equivalent versions of it for functionals and their associated sets (by LF-duality), locating necessary-and-sufficient conditions for a set of infradistributions to be compact according to this metric, showing that the topology it induces is a close cousin of the Vietoris topology, and using this topology to elegantly characterize infrakernels (plus one additional condition) as just bounded continuous functions.
Section 7: The basics of Infra-Markov processes. This is just giving a few definitions, and will mostly be followed up on in a future post about infra-POMDP's. However, we also have a far-reaching generalization of the classic result where Markov chains (fulfilling some conditions) have a stationary distribution which can be found by iterating. Infra-Markov chains (fulfilling some conditions) have a stationary infradistribution which can be found by iterating.
Section 8: When an infradistribution is over finitely many events, we can define entropy for it. We define the Renyi entropy for , use that to derive a few different formulations of the Shannon entropy, cover what entropy intuitively means for crisp infradistributions, and show a few basic properties of entropy.
Section 9: Teasers for additional work.
EDIT: In the comments, we work out what the analogue of KL-divergence is for crisp infradistributions, and show it has the basic properties you'd expect from KL-distance.
Section 0: Notation Glossary
: A Polish space.
: The space of continuous functions .
: the Banach space of continuous bounded functions , equipped with the sup-norm, .
: Functions. Typically of type signature .
: The restriction of a function f to some set .
: Constants. Generally, are in or , while and represents a probability you use to mix two things together.
: Various distance metrics. There are some others that we try to describe with subscripts, but if you're looking at distances between functions, we're using the sup-norm distance metric . If you're lookin at distances between measures, we're using the KR-metric, (ie, if you feed in a 1-Lipschitz function bounded to be near 0, what's the biggest difference in the expectation values you can muster), and if you're looking at distances between points , we're just equipping the space with some distance metric.
: The quantity , aka .
: If is a Lipschitz function, it's the Lipschitz constant of .
: The expectation of a function w.r.t. some probability distribution, or measure, or the measure on some set . Like, .
: An infradistribution functional, of type signature , fulfilling some properties like monotonicity and concavity.
: An infradistribution set, a closed convex upper-complete set of a-measures fulfilling a few other conditions.
: The space of infradistributions over the space .
: The space of probability distributions over the space .
: An a-measure. is a measure, is a number that's 0 or higher.
: The set of a-measures over the space .
: the upper completion of a set of a-measures , made by the set , where + is Minkowski sum.
: the minimal points of the infradistribution , those points where the value can't get any lower without the point traveling outside .
: An alternate representation of an a-measure, where we can break the measure down into a probability distribution and a scaling term . Talk of and for a-measures is referring to these quantities of "how much is the amount of measure present" and "how much of the utility is present".
: The expectation of a function according to an infradistribution set, defined as
: Used to denote the Lispchitz constant of some infradistribution or infrakernel. In other words, The subscript helps denote which infradistribution or infrakernel it came from, if there's ambiguity about that.
: In the context of updates, and is a likeliehood function saying how likely various points are to produce some observation, while is an "off-history utility function" used to define the update.
: An abbreviation for the sorts of functions we take the expectation of when we define the update, defined as:
Where and .
An infradistribution, updated on off-event utility and likelihood function , defined as:
: The quantity .
: A mixture of infradistributions according to some probability distribution , defined as
: Given some continuous function , and infradistribution , this is the pushforward infradistribution of type , defined by
: The infinimum of two infradistributions according to information ordering, defined by:
: The supremum of two infradistributions according to information ordering, defined by
: Usually used for an infrakernel, a function with the shared Lipschitz-constant property, pointwise convergence property, and compact-shared CAS property. Described in the post.
: is the type of infrakernels .
: Lambda notation for functions. This would be "the function that maps to (the function that maps to )".
: The semidirect product, , where and , is an infradistribution defined by:
: The direct product, , where , , is an infradistribution defined by:
: The projection map from some space to . The thing in the subscript tells you what you're projecting to.
: The coproduct, , where , , is an infradistribution defined by:
Where and are the injection maps.
: the infrakernel pushforward, , where and , is an infradistribution defined by:
is the same thing, except when your infrakernel is just a Feller-continuous function .
: the pullback. If is a continuous proper map , and is an infradistribution on supported on , then , and is defined by:
: The free product of infradistributions. Given two infradistributions and , then is the infradistribution given by:
This subscript notation generalizes to other things. When you've got a sequence of thingies (let's say points from spaces ), then refers to a point from . gets abbreviated as , and refers to a point from . In general, this notation applies to any time when you're composing or sticking together a bunch of things indexed by numbers and you need to keep track of where you start and where you end.
: The support of a function , the set .
: The closure of a set . The overline is closure of a set.
: The convex hull of a set .
: A compact -almost-support. Generally, the superscript tells you something about what space this is a subset of, and the subscript tells you what level of almost-support it is. Compact almost-supports are defined later.
: the space of nonempty compact subsets of the space , equipped with the Vietoris topology.
: The Gateux derivative of infradistribution at in the direction of the function , defined as .
: the -Renyi entropy of infradistribution .
: When no subscript is specified, this refers to the limit of , ie, the Shannon entropy of the infradistribution (reduces to standard Shannon entropy for probability distributions)
: The cross-entropy of two probability distributions, the quantity .
Section 1: Generalizations
There's three notable variants on the mathematical framework found so far. Our old mathematical framework was viewing an infradistribution as a set of sa-measures over a compact metric space , fulfilling some special properties. Or, by LF-duality, an infradistribution is a concave monotone functional of type signature (it intakes a continuous function and spits out an expectation value).
Our three directions of generalization are: Permitting the use of the expectations of non-continuous functions, permitting expectations to be taken of any bounded continuous function instead of having the restriction, and letting our space be something more general than a compact metric space. The first path won't be taken, but the latter two will. Going to bounded continuous functions in general makes the theory of distances between infradistributions much tidier than it would otherwise be, as well as making the supremum operation and free product behave quite nicely. And letting our space be something more general than a compact metric space lets us have infradistributions over spaces like the natural numbers and do updates properly, and leads to an improved understanding of which conditions are necessary for an infradistribution to be an infradistribution.
Generalization to Measurable Functions
So, it may seem odd that we can only take the expectation of continuous functions. Probability distributions can take expectations of measurable functions, right? Shouldn't we be able to do the same for infradistributions? Being able to take expectations of measurable functions instead of just continuous functions would let you do updates on arbitrary measurable sets, instead of having to stick to clopen sets or fuzzy sets with continuous indicator functions.
On the concave functional side of LF-duality, we can do this by swapping out , the space of continuous bounded functions , for , the space of bounded measurable functions , and equipping it with the metric of uniform convergence (ie, )
To preserve LF-duality, on the set side, we'd have to go to the space of finitely additive bounded measures on . Ie, if are all disjoint subsets of our space , instead of (countably additive), we can only do this for finitely many disjoint sets. Most of measure theory looks at countably additive measures instead of finitely additive ones, so my hunch is that it'd introduce several subtle measure-theoretic issues throughout, instead of just being able to cleanly apply basic textbook results, and make our space of measures "too big". But it can probably be done if we really need discontinuous functions for something, we'd just have to go through our proofs with a fine-toothed comb. Finitely additive measures instead of countably additive ones are fairly odd. For instance, a nonprincipal ultrafilter over (1 if the set is in the ultrafilter, 0 if it isn't) is a finitely additive measure that isn't countably additive. So we'd have to consider strange creatures like that.
Generalization to Functions Outside [0,1]
Having to deal with functions in works nicely for utility functions, but maybe we want more generality. So, instead of having our infradistributions be defined over , (continuous functions ) we could have them be defined over (bounded continuous functions that are ), or even (bounded continuous functions) in full generality.
In fact, to get the supremum and free product and metrics on the space of infradistributions, to behave nicely, we have to switch to our infradistributions having type signature . Infradistributions of type signature have a... more strained relationship with these concepts, so in the interests of mathematical tidiness, we'll be we working with infradistributions of type signature from here on out.
There are three advantages and three disadvantages to making this switch. The disadvantages are:
1: Infradistributions of type signature cut down on a bunch of extra data that an infradistribution of type specifies. If your utility function is in , for example, the ability to take expectations of functions outside of is rather pointless.
2: The particular form of normalization we use is most naturally tailored to infradistributions of type , because it's basically "send the worst-case function, the constant-0 function, to a value of 0, and the best-case function, the constant-1 function, to a value of 1", and the scale-and-shift of inframeasures (fulfill everything but normalization) to make an infradistribution is perfectly analogous to rescaling a bounded utility function to lie in [0,1]. However, when you've got type signature , this becomes more arbitrary. Obviously, 0 should be mapped to 0. But mapping 1 to 1? Why not scale-and-shift to map -1 to -1, or make it so the slope of the functional at 0 in the direction of increasing the constant is 1? We'll stick with the old "0 to 0, 1 to 1" normalization, but maybe another one will be developed that has better properties. I'll let you know if one shows up.
3: There's a concept called isotonic infradistributions, which are closely tied to proper scoring rules, and the concept only behaves well for infradistributions of type signature . However, these will not be discussed in this post.
What about the advantages?
1: We can evaluate the expectation of any bounded function, instead of just functions bounded in . Although that restriction works nicely for utility functions, it's fairly restrictive in general. If infradistributions are to serve as a strictly superior generalization of probability theory... well, probability theory often involves expectations of functions not bounded in , so we should be able to accommodate such things.
2: As we'll see later, the set form of these sorts of infradistributions only involves a-measures (a pair of a measure and a nonnegative b term, without any mucking around with signed measures), which is very convenient for proving results. Also, the notion of "upper completion" for the set form of an infradistribution becomes much more manageable, and it's trivial to find minimal points. And finally, the KR-distance doesn't actually metrize the weak topology on signed measures, but it does metrize the weak topology on measures, so we don't have to worry about rigorously cleaning up any fiddly measure-theoretic issues regarding the use of signed measures.
3: But by far the most important reason to switch to infradistributions of type signature is that it just interacts much better with various operations. The supremum behaves much better, the free product behaves much better, the space of infradistributions can be made into a Polish space, the additional compactness condition we must add when we go to Polish spaces has a natural interpretation, you get a close match between infrakernels and bounded continuous functions... This type signature is unsurpassed at equipping infradistributions with nice properties, and I eventually gave up after a month of trying to make infradistributions behave nicely w.r.t. those things. This isn't a rushed decision to switch to this type signature, I was forced into it.
So, from now on, when we say "infradistribution", we're talking about the type signature , fulfilling some additional conditions, unless specifically noted otherwise.
Generalization to Polish Spaces
This is another generalization that we'll be adopting from this point onwards unless explicitly noted. Our old definition of what a permissible space to have infradistributions over was: is a compact metric space. But we can generalize this significantly, to Polish spaces (which have compact metric spaces as special cases)
Broadening our notion of what spaces are permissible to have infradistributions over does come at the cost of introducing some extra complexity in the proofs and results, but we'll specifically note when we're making extra assumptions on the relevant space.
The concept of Polish spaces is used throughout the rest of this post, so this section is very important to read so you have some degree of fluency in what a Polish space is.
Previously, we were limited to compact separable complete metric spaces to define infradistributions over. (this is redundant, because compact and metric imply the other two properties). Polish spaces are just separable complete metric spaces.
Technically, this is slightly wrong, because Polish spaces only have a topology specified, not a metric. So, you can think of them more accurately as being produced by starting with a separable complete metric space, and forgetting about the metric, just leaving the topology alone. But these details are inessential most of the time.
Some exposition of what these conditions mean is in order.
"Metric" just means it has a notion of distance. "Complete" means that all Cauchy sequences in the metric (sequences which ought to converge) have their limit point already present in the space. For example, isn't complete under the usual metric, but is. Taking limits shouldn't lead you outside the relevant space.
And finally, "separable" means that there's a countable dense subset. Ie, there's countably many points where, given any point in the space, you can find something from your countable list arbitrarily close to it. As a concrete example, shows that fulfills this property. There's countably many fractions, and, given any real number, you can find a fraction arbitrarily close to it. In particular, this implies that a Polish space can't be "too big". It must have the cardinality of the continuum or less, because everything can be written as a sequence of countably many points from a countable set. You can't necessarily express any point in it with finite data, but you can express arbitrarily close approximations to any point in it with finite data.
So, that's what a Polish space is. It's a space which can be equipped with a notion of distance where limits don't lead you outside of the space, and there's a countable dense subset. That last one is critical because, if it's missing, you can give up all hope of being able to work with such a space on a computer. You may not be able to deal with arbitrary real numbers on a computer, but the presence of a countable dense subset (rationals) means that you can round a real number off a tiny bit to a rational number, and do operations on those. But if a space isn't separable, then there must be points in it which can't be arbitrarily closely approximated with finite data you can work with on a computer.
Concrete examples of Polish spaces: All the previously mentioned spaces in the last post, , , any closed or open subset of a Polish space, or countable product of Polish spaces, the space of continuous functions when is compact (more generally, any separable Banach space is Polish), and the space of probability distributions over when is Polish (equipped with the weak topology). So, if you want infradistributions over the natural numbers, or over the real line, or over probability distributions on a Polish space, or continuous functions on a compact set, you can have them. This is a fairly large leap in generality.
So... how do we accommodate Polish spaces in our framework? We've just talked about what they are. Well, because isn't compact any more, our function space for the functional side of LF-duality has to shift from (the space of continuous functions , because continuous functions on a compact space are bounded automatically) to (the space of bounded continuous functions ).
There's two problems we run into when we make this shift. Compactness is an incredibly handy property, and we're no longer able to exploit our old compactness lemma, which showed up in a bunch of proofs in "Basic Inframeasure Theory". Second, due to not being in a compact space, we lose the ability to casually identify continuous functions and uniformly continuous functions, they can be different now, which was also used a lot in proofs.
To get around these, we'll have to eventually impose a condition on infradistributions which lets us work in the compact setting, modulo a little bit of error (the compact almost-support property)
Updating the Right Way:
An extremely convenient feature we have is that open subsets of a Polish metric space are Polish, such as the open interval (though you do need to change your metric, the standard metric inherited from says that space isn't complete, it's missing the points 0 and 1.) This lets us deal with updating in full generality, which we'll now go into.
As a recap, the way we dealt with updating on a likelihood function (with as the likelihood function, as the function giving you your off-event utility, and the starting infradistribution is ) was defining the updated infradistribution by:
Where is defined by:
Ie, you blend the functions together with . When is near 1, we're in the region which plausibly could have occurred, and we use . When is near 0, we're in the region which has been ruled out, and we use , as that's our off-event utility function. For infradistributions, all the functions you're evaluating have to be continuous, so in particular, must be continuous to look at what its expectation is.
Now, originally, from the last post, was an infradistribution over the space (the region where , but take the closure), and f was a continuous bounded function from that space to . Our post-update space had to be closed because we could only have infradistributions over compact spaces back then, and closed subsets of compact sets are compact, which is why we had to take the closure. But, actually, the support is an open set! And if we're working over Polish spaces, that's a-ok, we don't need to add anything special or clean it up, because an open subset of a Polish space is Polish.
As further evidence for not actually needing to take the closure in updating, we technically only need to be continuous on the support of for to be continuous. Like, could be continuous on the open set "support of ", but start having discontinuities at the "edges" of the set where is 0. But then the bad behavior of on the zero-likelihood edges would get crunched down when you multiply the function by , so then would still be continuous, and thus would be continuous and bounded and you could evaluate its value as usual with no issues.
To metrize the support of a likelihood function, just restrict the original distance metric on to be at most 1 and define your new metric as:
Proposition 1: For a continuous function , the metric completely metrizes the set equipped with the subspace topology.
Why do we care about such fiddly technicalities? Does it affect anything? Well, one of our upcoming results, the Infra-Disintegration Theorem, naturally produces some of those functions that can be discontinuous on the zero-probability "edges" of the fuzzy set you're updating on, because conditional probability can vary wildly on low or zero-probability events. So now that we're no longer restricted to compact spaces, we can properly address updates like that.
Supports and Almost Supports
The largest change we make when we go to Polish spaces is that there's a prominent extra condition we must add to fairly call something an "infradistribution", because things get extremely messy if we don't. First, some exposition on the analogous property for ordinary probability distributions. If you have a probability distribution on , it can't be a uniform distribution. It must tail off as you head towards infinity in either direction. In a more general form, any probability distribution on a Polish space has the property that there's a sequence of compact sets that more and more of the probability mass lies within, limiting to all of it. We'd want an analogous property for our infradistributions, as "compact set that accounts for arbitrarily-much-but-not-all of the infradistribution" would be perfect for replacing the compactness arguments that we used to use all over the place.
To properly formulate this, we must define a support. The notation is the restriction of a function to a set .
Definition 1: Support
A closed set is a support for a functional iff
So, a support is just "if functions disagree outside of it, it doesn't matter for assessing their value". Note that we're speaking of a support instead of the support, but as we'll see a bit later, we just need to assume one additional condition to get that infradistributions have a unique closed set which could be fairly called the support.
Now, the compactness condition on probability distributions we discussed earlier required that arbitrarily large fractions of the probability mass can be accounted for a compact set, not that all of the probability mass be accounted for by a compact set. Accordingly, we define:
Definition 2: -Almost Support
A closed set is an -almost support for a functional iff
For this, our distance is using the sup-norm on functions.
What's going on with this definition is that it matches up with how, if a probability distribution over has all but of its measure on the interval , then if you take any two bounded functions and and have them agree on said interval, the difference in their expectation values can be at most times the difference in the functions outside of said interval.
Anyways, armed with this notion of almost-support, the natural analogue of "you can find compact sets that account for as much of the measure as you want" for probability distributions becomes:
Definition 3: Compact Almost-Support
A functional is said to have compact almost-support if, for all , there is a compact set that is an -almost support for .
This condition essentially rules out having too much Knightian uncertainty, lets you apply compactness arguments, and has a very nice interpretation on the set side of LF-duality.
So, we will mandate another condition to call something an infradistribution: Compact almost-support, or CAS for short. And now, we will define infradistributions afresh:
Definition 4: Infradistribution (set form)
An infradistribution over is a subset of the cone of a-measures over , fulfilling the following properties:
1: Convexity:
2: Closure:
3: Upper-completeness:
4: Projected-compactness: is relatively compact in (contained in a compact set)
5: Normalization: There exists an a-measure in where , and there exists an a-measure in where , and all a-measures have .
The main thing to note in this definition that we've swapped out our notion of upper-completion. Instead of our notion of upper-completion being "add the cone of all sa-measures", our notion of upper-completion is now just "add the cone of increasing the b term". And the notion of minimal point is altered accordingly, so now it's really easy to find a minimal point below something in an infradistribution set. Just decrease the b term until you can't decrease it anymore. Roughly, the reason for this is that the sa-measures were exactly the signed measures with the special property "no matter which function we use, ".However, the only points that fulfill the property "no matter which function we use, " are those where the measure component is just 0, and , so that's the cone we use for upper completion instead.
There's also this projected-compactness property which means that if you ignore the b terms, the set of measure components is contained in a compact set. This is an important assumption to make for being able to apply our usual compactness arguments, but it's not obviously equivalent to anything we've already discussed so far. Nonobviously, however, it's actually equivalent to the conjunction of our CAS (compact almost-support) property, and Lipschitzness. We'll be using for the space of compact subsets of .
And, on the concave functional side of things, our conditions are:
Definition 5: Infradistribution (functional form)
An infradistribution is a functional of type fulfilling the following properties:
1: Monotonicity:
2: Concavity:
3: Normalization:
4: Lipschitzness:
5: Compact almost-support:
For monotonicity, the ordering on functions is iff . For concavity, . For normalization, we abuse notation a bit and use constants (like 0) as abbreviations for constant functions (like the function that maps all of to the value 0). For Lipschitzness, our notion of distance that we have is . And for compact almost-support/CAS, must be a compact set.
These two different definitions are secretly isomorphic to each other. is used for the set form of an infradistribution, and is used for the expectation functional form.
Theorem 1: The set of infradistributions (set form) is isomorphic to the set of infradistributions (functional form). The part of the isomorphism is given by , and the part of the isomorphism is given by , where and is the convex conjugate of .
This is just our old LF-duality result from "Basic Inframeasure Theory", but we have to reprove it anew because we switched around the type signature on the functional side, notion of upper completion on the set side, added the compact-projection requirement on the sets, and added the Lipschitz/CAS conditions on the functionals.
Now, we can now return and define the support of an infradistribution uniquely, as just the intersection of all supports.
Proposition 2: For any infradistribution there is a unique closed set which is the intersection of all supports for , and is a support itself.
This looks easy to prove. It's really not. Although it technically hasn't been proven yet, we're fairly sure that the support of an infradistribution is the closure of the union of the supports of all the measure components present in the infradistribution set. And similarly, an -almost-support should be a set where all measure components in the infradistribution agree that there's only measure assigned outside the set. So, the notion of a support and an almost-support on the functional side of LF-duality matches up with the standard notion of a support for measures.
To recap this section, we generalize in two directions. Our first direction of generalization is going from the type signature to , because it makes infradistributions behave so much more nicely, and our second direction of generalization is letting our space be Polish instead of just a compact metric space.
Polish spaces, are spaces where you can stick a metric on them, have the space be closed under limits in that metric, and have a countable dense subset, this accounts for and and other more exotic spaces. This also allows us to properly handle weird edge discontinuities in updating. To compensate for the loss of compactness, we must add an extra condition that's like "all but of the behavior of the expectation functional is explained by what functions do on a compact set, for any ".
Section 2: Types of Infradistributions
Here's our fancy diagram of implications between the various additional properties an infradistribution may have.
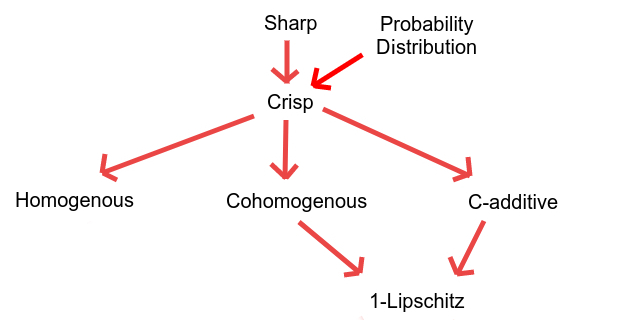
We should mention that a-measures can be written in the form . You can decompose a measure into a scale term and a probability distribution . So, if we talk about the value or the value of minimal points in a set, this is what it's referring to.
Definition 6: Homogenous
An infradistribution is homogenous iff for or, equivalently, all minimal points in have .
I haven't had much occasion to use this so far, despite it looking like a very natural condition. One notable property is that it's one of the only nice properties preserved by updating, which is an operation that's very badly behaved when it comes to preserving nice properties. Sadly, updating only preserves homogenity when (your off-event utility), and as we'll see later when we get to cohomogenous infradistributions, that sort of update is actually not a very good way to represent "updating when you don't care about what happens off-history". The second notable property is that, since it's equivalent to all minimal points having , homogenous infradistributions could be thought of as corresponding to sets of actual measures. So, it's what you'd naturally get if you were fine with dealing with sets of measures instead of probability distributions, but had philosophical issues with +b offset/guaranteed utility.
Proposition 3: for all iff all minimal points in have .
In the other direction, we have 1-Lipschitzness. This is as simple as it says, it's just that the infradistribution has a Lipschitz constant of 1. Or, if you prefer to think in terms of minimal points, all minimal points have . Their measure component is an actual probability distribution or has even less measure present than that.
The primary nice application this property has is that, intuitively, when you compose a bunch of operations, the Lipschitz constants tend to blow up over time, like how adding or multiplying Lipschitz functions often leads to the Lipschitz constant of the result increasing. So, if you want to infinitely iterate a process, this condition shows up as a prerequisite for doing that.
However, for technical reasons, 1-Lipschitzness doesn't behave as nicely for infradistributions of type as it does for infradistributions of type , so in practice, we use the stronger condition of C-additivity instead.
Also, for minimal points, 1-Lipschitzness corresponds to "all minimal points have their measure component being a probability distribution or having lower measure than that". So it's what you'd naturally get if you were fine with +b offsets, but had philosophical issues with the amount of measure being more than 1. After all, you can interpret measures of less than 1 as "there's some probability of not getting to select from this probability distribution in the first place", but how do you interpret measures of more than 1?
Proposition 4: iff all minimal points in have .
There are two strengthenings of that property. Our first one will be cohomogenity, which, oddly enough, is a little nicer than homogenity to have as a property, despite being more complicated to state.
Definition 7: Cohomogenous
An infradistribution is cohomogenous iff for all or, equivalently, if all minimal points have .
Why is this called cohomogenous? Well, for homogenity, if you drew a line from 0 to , and plotted what does over that line, it'd be linear. For cohomogenity, if you drew a line from 1 to , and plotted what h does over that line, it'd be linear. The half of normalization where enforces that there's a minimal point with , and we can compare with homogenity being "all minimal points have ". The half of normalization where enforces that there's a minimal point with , and we can compare that with cohomogenity being "all minimal points have ". Homogenity is "the whole function is determined by the differentials at 0" and cohomogenity is "the whole function is determined by the differentials at 1".
Also, "all minimal points have " is what you'd naturally get if you adopted the 1-Lipschitz viewpoint of not being ok with the measure components of a-measures summing to more than 1, and adopted a view of the b component that's something like "you have probability 1 of either proceeding with the probability distribution of interest, or the experiment not starting in the first place and you go to Nirvana (1 reward Nirvana, not infinite reward)".
This property is preserved by updates but only for , like how homogenity is preserved by updates where . And in fact, it makes somewhat more sense to use this for updating when you don't care about what happens off-history than the update. Here's why. If you observe an observation, an update where is like "ok, we do as badly as possible if the observation doesn't happen". Thus, your expectations will tend to be determined by the probability distributions with the lowest probability of observing the event, because you're trying to salvage the worst-case.
However, an update when is like "we do well if the observation doesn't happen". Thus, your expectations will tend to be determined by the probability distributions with the highest probability of observing the event, which is clearly more sensible behavior. Cohomogenity is preserved under these sorts of updates.
There's also an important thing we become able to do at this stage. As we'll see at the end of this post, we can define entropy for infradistributions in general. However, it only depends on the differentials of an infradistribution around 1/the minimal points with . And cohomogenity is "those differentials/minimal points pin down the whole infradistribution". So, my inclination is to view the concept of entropy for infradistributions in general as a case of extending a definition further than it's meant to go, and I suspect entropy will only end up being relevant for cohomogenous infradistributions.
Proposition 5: iff all minimal points in have .
Time for the next one, C-additivity, which is an incredibly useful one.
Definition 8: C-additive
An infradistribution is C-additive iff for all , or, equivalently, if all minimal points have , or, equivalently, if for all
This lets you pull constants out of functions, a very handy thing to do. For sets, it says that every minimal point can be represented as a probability distribution paired with a b term. You'd get this if, philosophically, you were fine with +b guaranteed utility, but were a real stickler for everything being a probability distribution. Further, you need to assume this property to get obvious-looking properties of products to work, like "projecting a semidirect product on back to makes your original infradistribution" or "projecting a direct product to either coordinate makes the relevant infradistribution" or "projecting the free product to either coordinate makes the relevant infradistribution". So, this could be thought of as the property that makes products work sensibly, which explains why it shows up so often. In particular, though we don't know whether it's necessary to make things like the infinite semidirect product work out, it's certainly sufficient to do so.
Proposition 6: iff all minimal points in have iff .
And now we get to the single most important and nicely behaved property of all of these, crispness.
Definition 9: Crisp
An infradistribution is crisp iff for , , or, equivalently, if all minimal points have and .
So, this is really dang important, mostly because of that property where all minimal points have and . It means all crisp infradistributions can be viewed as a compact convex set of probability distributions! These are already studied quite extensively in the area of imprecise probability. Shige Peng's nonlinear expectation functionals correspond to these, as do the "lower previsions" from the textbook "Statistical Reasoning with Imprecise Probabilities".
Any two out of three from "homogenity", "cohomogenity" and "C-additivity" imply this property, and it implies all three. Homogenity and 1-Lipschitzness also suffice to guarantee this condition.
Now, the ability to identify these with conventional sets of probability distributions lets you simplify things considerably. They have a natural interpretation of entropy, they make very nice choices for infrakernels in MDP's and POMDP's, and (we won't cover this in this post), they let you break down time-discounted utility functions in a very handy way, because the reward that has occured so far is a constant and you can pull that out, and you can factor a time-discount out of everything else to pull the time-discount scaling factor out of the expectation as well. So these are very nice.
Proposition 7: iff all minimal points in have and .
Time for one last property, which is the analogue for infradistributions of dirac-delta distributions in standard probability theory.
Definition 10: Sharp
An infradistribution is sharp iff for some compact set , or, equivalently, if the set of minimal points in is all probability distributions supported on .
Notice that doesn't have to be a convex set, just compact. is a subset of , not a subset of the space of a-measures. These are infradistributions which correspond to "Murphy can pick the worst possible point from this set right here and that's all they can do". They're like the infradistribution analogue of probability distributions that put all their probability on a single point. This analogy is furthered by probability distributions supported on a single point (the dirac-delta distributions) being extreme points in the space of probability distributions, and we have a similar result here. An extreme point is a point in a set that cannot be made by taking probabilistic mixtures of any distinct points in the set.
Proposition 8: iff the set of minimal points of corresponds to the set of probability distributions supported on .
Proposition 9: All sharp infradistributions are extreme points in the space of crisp infradistributions.
These are almost certainly not the only extreme points in the space of crisp infradistributions, but they are extreme points nonetheless.
And that should be about all of it. Now for further things we can do with infradistributions!
Section 3: Operations on Infradistributions
We start by giving a big chart for which operations preserve which properties.
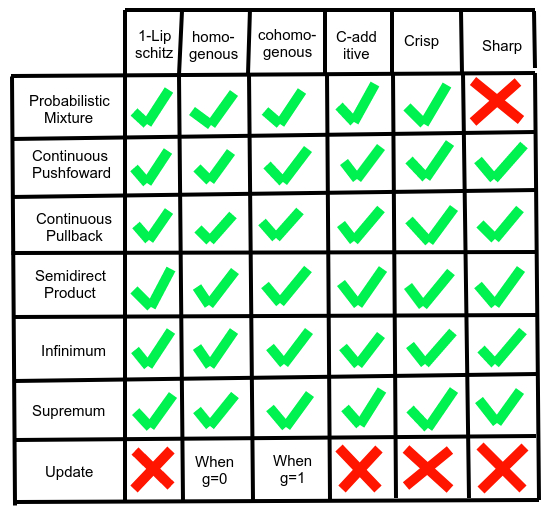
This diagram doesn't show everything in this section, it's missing infrakernel pushforward, Markov kernel pushforward, direct product, coproduct, free product, and probably more. However, all of those can be generated via composing continuous pushforward, inf, sup, continuous pullback, and semidirect product accordingly, so they automatically preserve the nice properties because their building blocks do. Since we won't be addressing continuous pushforward, mixture, and updating in this section (we already did it in the last post), we'll just get them out of the way right now.
Proposition 10: Mixture, updating, and continuous pushforward preserve the properties indicated by the diagram, and always produce an infradistribution.
This seems like routine verification, but why do we need to specify that they always produce an infradistribution? Didn't we know that already from the last post? Well, because we're dealing with Polish spaces now, and also altered the type signature of our infradistributions, we do need to double check that our various conditions still work out. Fortunately, they do.
Our first two that we'll be looking at are inf and sup.
IMPORTANT EDIT RE: ORDERING
We've got a call to make on ordering infradistributions and would appreciate feedback in the comments.
One possible way to do it is to have the ordering on infradistributions be the same as the ordering on functionals, like iff . This is the information ordering from Domain theory, where the least informative (most uncertainty about what Murphy does/biggest sets) go at the bottom, and the most informative (smallest sets/least uncertainty about what Murphy does) go near the top, with a missing top element representing inconsistency. Further support for this view comes from the supremum in the information ordering on infradistributions perfectly lining up with how the supremum from domain theory behaves. The problem is, the "or" operation in infradistribution logic is infinimum in the information ordering, and the way that lattice theory writes inf is . The bullet bitten in this approach is using the symbol to mean infinimum, in contravention of the rest of lattice theory, confusing many people. But, I mean, points down, it looks like it means inf if you don't have lattice theory familiarity.
Or, there's Vanessa's preferred view where we use the set ordering, where the smallest sets go on the bottom, and the biggest sets go on the top. This is in perfect compliance with lattice theory, there's no notation mismatches.
"It's extremely standard in lattice theory to denote join by and meet by . I can't imagine submitting a paper which would have it the reverse."
But it means that the ordering is backwards from domain theory (inf in the set ordering behaves like sup does in domain theory), and supremum in this ordering is the inf of two functions.
Oh, there's a third way: Use the domain theory information ordering, but use for supremum aka intersection aka logical and, and for infinimum aka union aka logical or. This notation is standard in domain theory, because there are often orderings or logical operations on the domains that don't match up with the order a domain is equipped with, and the lattice theorists would understand it. This would look a little strange because we'd have and , but that's the only drawback.
The infinimum (information ordering) is easy to define.
Definition 11: Infinimum
The infinimum of two infradistributions is defined as:
Proposition 11: The inf of two infradistributions is always an infradistribution, and inf preserves the infradistribution properties indicated by the diagram at the start of this section.
Now, when we say what a construction is on the set side of LF-duality, we should remember that taking the convex hull, closure, and upper completion always gets a set into its canonical infradistribution form, without changing any of the expectations at all. It gets pretty hard to show whether the set form for the more complicated constructions preserves convex hull, closure, and upper completion, and it affects nothing whether or not it does. So, from now on, when we give a set form for something you can do with infradistributions, it should be understood to be modulo convex hull, closure, and upper completion.
Anyways, our definition of inf on the set level is
And we can show that this is the right definition (modulo closed convex hull and upper completion)
Proposition 12:
Excellent, it matches up with the concave functional definition.
One last result. Can we take the infinimum of infinitely many infradistributions and have it be an infradistribution? Well, yes, as long as you have certain conditions in place.
Proposition 13: If a family of infradistributions has a shared upper bound on the Lipschitz constant, and for all , there is a compact set that is an -almost support for all , then , defined as , is an infradistribution. Further, for all conditions listed in the table, if all the fulfill them, then fulfills the same property.
The supremum is a bit more finicky, because it might not exist. We haven't shown it yet, but if infinimum is union of infradistribution sets, then supremum should probably be intersection of infradistribution sets. So, the supremum of the infradistributions corresponding to two dirac-delta distributions on different points has no intersection, and doesn't exist. However, it's reasonable to ask what suprema are like if they do exist.
The upcoming definition may not produce an infradistribution, but fortunately we'll see we only need to check normalization to ensure that it's an infradistribution.
Definition 12: Supremum
The supremum of two infradistributions is defined as:
Alternately, it is the least infradistribution greater than in the information ordering, or the concave monotone hull of .
Proposition 14: If and , then the supremum is an infradistribution.
Proposition 15: All three characterizations of the supremum given in Definition 12 are identical.
What's the supremum on the set level? Well, it's:
Just take intersection. This makes it clearer why the supremum may fail to exist. Maybe the two sets have empty intersection. Or, since normalization is "there exists an a-measure with , and all a-measures have and there's an a-measure with ", you need the intersection to contain a point with and a point with as a necessary and sufficient condition for the supremum to be an infradistribution.
Proposition 16:
Ah good, we've got the right set form. Infinimum is union, supremum is intersection. Pleasing. This view of supremum as intersection is also the easiest way to show that:
Proposition 17: For any property in the table at the start of this section, will fulfill the property if both components fulfill the property.
And what about infinite supremum? Well... Let's take a bit of a detour to Domain Theory. Domain Theory studies partially ordered sets with particular properties in order to give a semantics to types in computer programming, where the ordering on the set can be interpreted as an "information ordering". Lower things in the ordering are less-defined pieces of data or stages of a computation. Let's look to it for inspiration, because "partially specified information" looks very similar to the sort of stuff we're doing where we've got a set of possible a-measures that can be large (much ignorance) or small (much knowledge)
The pairwise supremum rarely exists in full generality for a domain, for it usually happens that it is possible for there to exist two pieces of inconsistent information that cannot be combined. However, one of the requirements for a domain to be a domain is that directed sets have a supremum. A directed set is a set of points where, for any two points , there is some third point where and . Ie, "any two pieces of information can be consistently combined". Or you could think of it as analogous to compact sets. If there's no finite collection of compact sets with nonempty intersection, then the intersection of all of them has nonempty intersection. If there's no finite collection of data that is inconsistent, then it should be possible to aggregate all the data together.
There's also a particularly nicely behaved subclass of domains called bc-domains where the only possible obstruction to the pairwise supremum existing is the lack of any upper bounds to both points, and you have a guarantee that if there's some that's an upper bound to and , the the supremum of and exists. In other words, if it's possible to combine the information together at all, there's some minimal way to combine the information together.
Finally, if you have "supremum exists for any finite collection of points in this set " and "supremum exists for any directed set ", then you can show that there's a supremum for your arbitrary set by "directifying" it. You take all possible collections of finitely many points from , take the supremum of each of those, add all those points to your set , and now you have created a directed set, and can take the supremum of that, and it's the least upper bound on your original set .
As it turns out, we have a perfectly analogous situation for all of these concepts for infradistributions. Call a set of infradistributions "directifiable" if any finite collection of infradistributions from that set has the supremum exist. Then, we get:
Proposition 18: If a family of infradistributions is directifiable, then (defined as the functional corresponding to the set ) exists and is an infradistribution. Further, for all conditions listed in the table, if all the fulfill them, then fulfills the same property.
One last note of relevance. For infradistributions of type , it is possible to associate them with a canonical infradistribution of type by taking the maximal extension of the function to all of that still fulfills all the infradistribution properties.
However, sadly, this way of embedding infradistributions of type into the poset of infradistributions of type doesn't make a sublattice. The inf of two maximal extensions may not be a maximal extension. Infradistributions of type are just much better-behaved when it comes to inf and sup.
Let's move forward. As a brief recap of "Basic Inframeasure Theory", pushforward w.r.t a a continuous function is the function given by: . Ie, if you have a continuous function , and Murphy is adversarially choosing things to minimize functions , then given a function , you can just precompose it with to turn it into a function , and look at the worst-case expected value of it.
Interestingly enough, a bunch of other concepts we're going to be covering can be thought of as generated by semidirect product and pushforward w.r.t a continuous function.
Next up on the list is semidirect product, which is a very important construction, and this requires rigorously defining infrakernels. Just as a Markov kernel is a function , a probabilistic function from to , an infrakernel is a function fulfilling some special properties. Ie, Murphy has their choice of how to minimize things depend on the initial point selected. We're in Polish spaces, so we'll need to add one extra condition to ensure that infrakernels behave nicely.
Definition 13: Infrakernels
An infrakernel is a function that fulfills the following three properties. From now on, will denote the type of infrakernels from to . and denote compact subsets of and respectively.
Condition 1: Boundedness.
Condition 2: Pointwise convergence.
Condition 3: Compact-shared CAS.
The first condition says that there's an upper bound on the Lipschitz constant of all the .
The second condition says that if the input to the kernel converges, that had better lead to convergence in what the corresponding infradistributions think about the expectation of a particular function.
The third condition says that, given any compact subset of , there needs to be a sequence of compact subsets of that act as compact almost-supports for any of the infradistributions from the family produced by feeding a point from into the kernel.
Roughly, these three conditions are how the infrakernel is glued together to behave nicely without the Lipschitz constant getting unmanageable, or having any discontinuities in functions, and while preserving the compactness properties we need.
Amazingly enough, once we define a notion of distance for infradistributions later, we'll see that we can almost replace this by one single condition: "the function is bounded and continuous". So you could just consider an infrakernel to be the analogue of a Feller-continuous Markov kernel. These conditions are almost all of the way towards being continuity in disguise, despite the concept of infrakernels coming well before we started to think about distance metrics on infradistributions. But that's for later.
Now that we see what the conditions for an infrakernel mean, we can look at the semidirect product.
Definition 14: Semidirect Product
The semidirect product , of type , is defined as
Intuitively, the semidirect product definition is, if is locked in and known, then Murphy gets to use to adversarially pick the to minimize . But, backing up, Murphy actually has adversarial choice of the . It knows that picking leads to an expected payoff of , so, Murphy actually minimizes the function to set itself up for success when the is revealed.
Semidirect products are important for two reasons. The first reason is that they let us define the direct product and infrakernel pushforwards. In fact, even mixture of infradistributions to make a prior can be viewed as special case of this. We'll get more into how that works later in the "infrakernel pushforward" section, but if you want an "infraprior" where Murphy has some adversarial choice over which hypothesis is selected, semidirect product is the key tool to let you figure out exactly how it should behave! Thinking about semidirect products lets you figure out the update rule when you have Knightian uncertainty about the prior probability distribution! Anything involving stacking adversarial choice over multiple stages involves semidirect product, it's an absolutely indispensable tool. Like going from Markov Decision Processes to infradistributions over histories... Yeah, that involves repeated semidirect product to build up the history.
The second reason the semidirect product is important that it gives you conditional probability. Given an input, the kernel gives you an infradistribution over what happens next, a sort of "conditional infradistribution" given a particular input. This reaches its full potential in the Infra-Disintegration Theorem, coming up in a while.
Time for results.
Proposition 19: is an infradistribution, and preserves all properties indicated in the diagram at the start of this section if h and all the have said property.
This is nice to know. There's also a really basic property you'd want, though. Projecting the semidirect product back to the starting coordinate should recover your original infradistribution. However, we need C-additivity for all the in order for this to work. Ie, for all , .
Proposition 20: If all the are C-additive, then .
A useful thing you can do when iterating a semidirect product is that you can fold a bunch of infrakernels into one big one. When referring to points from a series of spaces, we'll use to refer to a point from the space , and to refer to a point from the space . is an abbreviation for . With that notation out of the way, we have,
Proposition 21: If are a sequence of infrakernels of type , and is an infradistribution over , then can be rewritten as where is an infrakernel of type , recursively defined as and
In fact, we can even do an infinite semidirect product! Again, we have a sequence of spaces , and a sequence of infrakernels . And we keep doing semidirect product over and over again to build up infradistributions over products of increasingly many . Can we do the same thing as before, lumping all our infrakernels into one big infrakernel of type ? Well... kinda. We need that all our kernels are C-additive. Interestingly enough, when the type signature of an infradistribution only looks at functions bounded in , you need something only slightly weaker than 1-Lipschitzness to make it work out. The general issue with why we need to assume C-additivity in this case is that, for infradistributions with type , the property becomes far weaker of an assumption than , and you need for the proof to work out well.
Again, for notation, we'll be using for a sequence of points from the first spaces, and for an infinite sequence of points from and all further spaces. Similarly, will denote the infrakernel of type produced by composing the first n infrakernels. Fix an arbitrary sequence of nonempty compact sets , and let the infinite infrakernel be defined as:
Ie, take your and truncate it to a function that only needs the first inputs, by assuming worst-case inputs for everything in the tail. You can evaluate this by building up your semidirect product only up to level . Then just take the limit as n goes to infinity.
Wait, isn't there a dependence on which sequence of compact sets you pick to make worst-case inputs for everything in the tail? Well, no! You get exactly the same infrakernel no matter which compact sets you pick! You could even pick some arbitrary sequence of points as your compact set if you wanted. But we do need that sequence of compact sets to help in defining it for technical reasons, just taking the inf over the product of the would fail.
Proposition 22: is an infrakernel (C-additive, specifically) if all the are C-additive infrakernels. It is unchanged by altering the sequence of compact sets. In addition, if all the are homogenous/cohomogenous/crisp/sharp, then will be so as well.
Lovely. In particular, if the environment is a POMDP with a crisp transition kernel, this tool can let us make an infradistribution over histories of states. But, uh... how do we know this is the right way to do the infinite semidirect product? Well, we have this result.
Proposition 23: If all the are C-additive, then
So, projecting back the infinite semidirect product to any finite stage just makes the partially built finite semidirect product. Excellent!
There's another thing we can ask: What's the analogue of the semidirect product on the set side of LF-duality? Well, that... takes a fair amount of work. Let's say is a selection function. It's a measurable function (with treated as a set) with the property that regardless of , picks a point where the and are upper-bounded by some constant. It gives Murphy's choice of a-measure for each it could start with.
Now, there's some implicit type conversion going on where we can take points in (a measure over and a term), and they're isomorphic to measures over (the space with one extra disjoint point added, the measure on this point tracks what the term is). This now lets us do the ordinary measure-theoretic semidirect product. Given a measure over , we can look at , and we'd have a measure over . This is isomorphic to , and then you just collapse that second part into a single point to get a measure over , which is then isomorphic to a pair of measure on and a term. Thus, glossing over all these implicit type conversions, we will badly abuse notation for readability and view as an a-measure over .
With s being implicitly assumed to be a selection function of that form (measurable, bounded, picks a point in for each ), and having refer to the a-measure made by viewing all a-measures on as measures on , doing the semidirect product, and collapsing into a single point and then back into a term, we can now define the semidirect product on the set level. It's:
Ie, Murphy picks out a starting a-measure, and a selection function which can be looked at as a Markov kernel, kind of. The semidirect product of the measure component with the selection function is done and then type-converts to a measure over and a term, and the original b term from the start is added back on.
Proposition 24:
And thus, this is the proper set analogue of the semidirect product.
Next one! The direct product, .
Definition 15: Direct Product
The direct product , of type , is defined as
This is called the direct product because we've got another sort of product, and if you look at the definition, it's just the special case of semidirect product where the kernel has regardless of . This is "Murphy gets a choice over what happens next, but the available choices it can pick from don't depend on the "
This recovers the ordinary product of probability distributions as a special case. It's associative (parentheses don't matter), but it's not commutative (commutativity=order doesn't matter). in general. Intuitively, the reason for why it's not commutative is that Murphy can have its choice of distribution over depend on the starting point , so we still get Murphy paying attention to what it did in the past. It's just that the set of Murphy's available choices doesn't depend on .
Due to being a special case of the semidirect product, pretty much everything carries over, from the set definition to the preservation of nice properties to the ability to do infinite products, and we don't bother reproving these things. There are two notable properties, though.
Proposition 25: The direct product is associative.
Also, if and are C-additive, we get both projections working out well.
Proposition 26: If and are C-additive, then and
We've also got a sort of coproduct. is the usual injection mapping.
Definition 16: Coproduct
The coproduct , of type , is defined as
There's not really much to say about this. You just pushforward the starting infradistributions to via the standard injection mappings, and take inf. We showed that inf preserves the nice properties as well as pushforward, so coproduct inherits those same nice properties.
It corresponds to Murphy getting free choice over whether to pick or to be in, and then using one of those two available infradistributions to make a worst-case distribution for your function . Equivalently, it corresponds to your beliefs if you have no idea whether you're in or but you have beliefs about what happens conditional on being in or . We haven't really found any surprising things to say about it, but interestingly enough, it seems to connect up better to the free product. We haven't gotten to what the free product is yet, but the free product is intuitively "what's the least informative infradistribution on that projects to be above both of these infradistributions" and the coproduct is "what's the most informative infradistribution on that both of these infradistributions inject to be above"
Time for the next one, infrakernel pushforwards.
Definition 17: Infrakernel Pushforward
The infrakernel pushforward, , where and , is the infradistribution in given by:
If you look carefully at this, you'll see that it's just the semidirect product projected down to the coordinate. A Markov kernel pushforward is starting with a probability distribution over and pushing it through a Markov kernel to get a probability distribution over . This is a very similar sort of thing.
Since this is built from semidirect product and continuous pushforward (the projection), it inherits the nice properties from those, and we don't need to reprove everything. Pushforward of a crisp infradistribution w.r.t. a crisp infrakernel is crisp, etc.
A neat feature of this is that it perfectly recovers mixture of infradistributions to make a prior! If is an ordinary probability distribution over , and is the n'th infradistribution in your list you're mixing together to make a prior, then:
And we've recovered ordinary mixture of sets, if you remember that from the last post.
This obviously suggests how to generalize to have an infraprior where you're uncertain about the probability distribution over hypotheses to have. Just make your h a crisp infradistribution over (uncertainty about the prior probability distribution over hypotheses), and do infrakernel pushforward. Bam, done.
As for the set form of this concept, it could be written via the set form for the semidirect product and the set form for pushforward... but there's a particularly pleasing way to rewrite it.
Basically, just like how we could mix sets together according to a probability distribution, it's possible to mix uncountably many sets together according to a measure to make a new set. Just shift the mixture set a bit to account for the b term, union all of them together, clean it up with closure, convex hull, and upper completion, and we're done. It's basically the set mixture we used to make a prior, but generalized, and we do it for each choice of a-measure Murphy could have picked (starting infradistribution).
Proposition 27:
So, we did get the appropriate set form. Also, on the category-theory side of things, is that you can make a category where the objects are Polish spaces and the morphisms are infrakernels. Infradistributions would just be the morphisms from a single point to your space of interest, so the space of infradistributions over would just be . We're still working on this sort of stuff, though, and there are other categories you can make with infradistributions that behave differently.
We can further specialize to the case where the infrakernel is a Markov kernel, .
Definition 18: Markov Kernel Pushforward
The Markov kernel pushforward, , where and , is the infradistribution over given by:
Again, this is pretty basic, just being a special case of infrakernel pushforward, and obviously preserves the various nice properties (except sharpness, because is mapping points to probability distributions that may not be dirac-deltas)
An interesting question about these is "what happens to the three conditions on an infrakernel?". Well, the Lipschitz bound criterion is fulfilled for free, because all the are probability distributions, and so are 1-Lipschitz. The pointwise convergence condition turns into " must be continuous w.r.t. the KR-metric". Finally, the compactness condition (although this is non-obvious) gets fulfilled for free.
So, our only restriction on Markov kernels is that they're continuous. Nice! This is actually called "Feller continuity", it's a property you can have on Markov kernels, and our infrakernels can be thought of as the infra-analogue of Feller-continuous Markov kernels.
On the set side of LF-duality, we have an even nicer representation, abusing to also stand for the pushforward of through the Markov kernel.
Proposition 28:
And again, we have the right set form. Restricting this even further to deterministic Markov kernels which map every input to a dirac-delta output just recovers our continuous pushforward exactly.
Now it's time for some fairly novel operations. We're about to try to go in the reverse direction from a pushforward, to define a pullback. If there's a continuous function , and an infradistribution , we'll be looking for a infradistribution on that's the "most general" or "least informative" infradistribution on that projects down to make . This is basically going "if you know how inputs map to outputs, and you have uncertainty over outputs, what's the maximally uncertain belief you could have over the inputs that's consistent with your belief about the output?"
It can be done, but we'll need some nice conditions in order to show it exists. It's also probably possible to generalize it to pullbacks of Markov kernels and infrakernels, but it gets harder. But continuous pullback should work for now.
There must be two important starting conditions in place in order to be able to even make the pullback in the first place. Our first requirement is that if and are identical on the set , then . Put another way, if you know how inputs map to outputs (your function ), your expectations of functions shouldn't have any dependence on what the function is on impossible outputs. If they did, there would be no infradistribution over inputs that would be capable of producing your infradistribution over outputs.
The next condition is that be a proper map. A proper map is a function where the preimage of a compact set is compact. Roughly, this is because we have a condition on infradistributions where behavior on a compact set should mostly pin down what the expectations are. As a toy example, let's say that maps a non-compact closed set to a single point , and the infradistribution is actually just the dirac-delta point distribution on . Now, if you're trying to invert and have the most ignorance possible about what options Murphy has over , you'd have to conclude "dang, pretty much any probability distribution over the preimage of is an option Murphy has, Murphy has a lot of options". And if Murphy can pick any probability distribution in the preimage of , then the worst-case expectation values don't just depend on a compact set. The proper map condition is what you need to have maximal ignorance over without the pullback infradistribution being "too big" (not determined by compact sets, and thus not actually an infradistribution).
Now, let's define the pullback.
Definition 19: Continuous Pullback
If g is a continuous proper function , and and is a support of , then the pullback of along is the infradistribution on defined by:
A word about what's going on. You've got your function of type , and you're looking for some other function of type such that gets a good score, and going via and undershoots .
Proposition 29: The pullback of an infradistribution is an infradistribution, and it preserves all properties indicated in the table for this section.
Proposition 30: Pullback then pushforward is identity, , and pushforward then pullback is below identity,
Ok, so going back and then forward is identity, that's good. And, in accordance with the motivation of this as "maximum ignorance about the inputs if you know the infradistribution over the outputs", pushing forward then pulling back makes something less informative.
Interestingly enough, there's actually a whole bunch of equivalent characterizations of the pullback, hopefully some of these will make it clearer why the fairly opaque definition deserves to be called the pullback.
1: On the set side of LF-duality, (pushforward) acts as a linear operator from to , and is a subset of . For pullback, just take the preimage .
2: On the set side of LF-duality, take the union of all infradistribution sets which project down via to make .
3: Take the infinimum of all infradistributions that pushforward to make .
4: If , then should equal . Complete this to make a full infradistribution via concave monotone hull.
5: Same as 4, but we just take the monotone hull (this is the definition of pullback given at the start)
Proposition 31: All five characterizations of the pullback define the same infradistribution.
So, pullback is pretty much preimage.
And we've just got one more operation to define! The free product, . Given an infradistribution on and another one on , it's the most uninformative infradistribution on that projects down to be more informative than and , or like combining beliefs about unrelated things. If you took two probability distributions and , would be the product of the probability distributions. However, would be the set of all probability distributions that project down to have both and as marginals.
Definition 20: Free Product
If and , then the free product is defined as:
Ie, you take both pullbacks along the projection mappings, and take the supremum.
Now, there's two possible complications here. The first potential complication is that the supremum doesn't always exist. The second potential complication is that we could only define the pullback when the map was proper, and unless and are compact, the projection maps aren't proper maps.
The second complication isn't an issue at all, it magically works out that you've still got compact almost-support as a property, much like how the preimage of a compact set under a projection mapping isn't compact, but intersecting two preimages like that for the and coordinates gives you a product of compact sets, which is compact.
As for the first one, we have the following result:
Proposition 32: The free product of two infradistributions exists and is an infradistribution iff:
1: There are points and where
2: There are points and where , and , and .
To see how weak this is, we have:
Proposition 33: Having (homogenity or 1-Lipschitzness) present on both of the component infradistributions is a sufficient condition to guarantee the existence of the free product.
Also, because pullback and supremum preserve all nice properties, the free product does as well, so we won't necessarily cover that.
Proposition 34: and , with equality when and are C-additive.
Again, C-additivity is what you need for the free product to project down appropriately, like how C-additivity is needed for the direct product and the semidirect product to project down appropriately. Also, we have:
Proposition 35: Free product is commutative and associative.
Woo, order and parentheses placement doesn't matter!
One last thing: We'd like to know what a sufficient condition for the existence of an infinite free product. Again, for this one, we have:
Proposition 36: The free product of countably many infradistributions exists and is an infradistribution iff:
1: There are points where,
2: There are points where
Proposition 37: , with equality when all the are C-additive.
Again, if every component infradistribution has some nice property, preservation of nice properties through pullback and supremum preserves it for the infinite free product, and if they're all C-additive, then the infinite free product projects down accordingly, so it's well-behaved.
And that's about enough for now.
Section 4: Ultradistributions
Ok, so infradistributions are pessimistic selection. But let's say that for some (currently unknown) purpose, we want to do optimistic selection. Ie, things are magically the best they can be. Do we get an analogous theory? Yes, let's call them ultradistributions, to parallel infradistributions, and work out what they look like in the set form. Instead of our a-measure condition of , we'll impose the condition . After all, we're doing optimistic selection here. For pessimistic selection, you can always freely increase the guaranteed utility, because Murphy never picks it, resulting in upper-completion of your set of points. But for optimistic selection, you can always freely decrease the guaranteed utility in the term, because optimistic selection will never pick it, resulting in lower-completion and maximal points instead of upper-completion and minimal points for pessimistic selection.
Expectation would be , we're taking the best result and using sup instead of the worst result and using inf. Instead of minimal points, we have maximal points. And instead of the upper completion, we have the lower completion.
The relevant conditions on the set side of LF-duality are pretty much the same as the conditions we'd normally have, except that instead of upper completion we have lower completion where we subtract arbitrary amounts from the b term, and instead of being a set of a-measures, it's a set of (measure, nonpositive number) pairs.
Proposition 38: Ultradistributions H are isomorphic to convex, monotone, normalized, Lipschitz, CAS, functions .
This is just LF-duality for ultradistributions instead of infradistributions. The only difference is convexity instead of concavity.
We can presumably work out analogues of pretty much all results for infradistributions, just with optimistic selection, but that'd take too long. Just remember that these things exist if we ever have to use them for something.
One other note: For crisp infradistributions, there's always a dual ultradistribution defined as that corresponds to the same set of probability distributions, but with optimistic selection instead of pessimistic selection. This result was taken from the book "Statistical Reasoning with Imprecise Probabilities" (worth reading) where they called the dual crisp ultradistribution an "upper prevision" as opposed to the "lower prevision" which corresponds to our crisp infradistributions. Most results about how they behave can be found in the aforementioned book, but only for the case which we'd call a crisp infradistribution. Previous work on imprecise probability doesn't seem to have generalized further beyond crisp infradistributions, and you need to generalize beyond that to address updating in a dynamically consistent way.
Section 5: Conditional Probability/Updates
Updating is a bit odd, because it preserves almost none of the nice properties we'd want. The only notable one that's preserved is homogenity/cohomogenity when or respectively. However, there's one very important theorem we can get about how updating works, and linking it to the semidirect product.
First, we'll cover the disintegration theorem in the conventional probabilistic case.
So, the disintegration theorem in ordinary probability theory says that given any probability distribution , it can be written as where , . Ie, if you have a probability distribution over , you can express it as a probability distribution over , and a conditional probability distribution over for each . And this conditional probability distribution is uniquely determined for -almost-all . This is because, when an has nonnegligible probability, the conditional probabilities are well-defined, but when is out of the support of , you're conditioning on a probability-0 event so there's freedom in what the conditional probabilities could be. Roughly, the classical disintegration theorem makes the notion of conditional probability rigorous.
For our version of the disintegration theorem, we sadly won't have the ability to decompose an arbitrary infradistribution over into an infradistribution over and an infrakernel . Vanessa says she has conditions to guarantee that this can be done, more on that in a later post.
What we did prove, however, is the ability to disintegrate an update of an infradistribution that was already disintegrable. Ie, if you start out with , then ( updated by likelihood function and off-event utility ) can also be written as where the definition of and will be given later. Updating an infradistribution with a notion of conditional probability makes another infradistribution with a notion of conditional probability. Since so many things can be viewed as semidirect products, this theorem lets you solve problems like "I have an infradistribution over states, each state induces an infradistribution over observations, and I observed something, what's my new infradistribution over states?". Or, as a special case of that, furnishing a variant of InfraBayes suitable for updating when you don't have a prior over hypotheses, you have an infraprior. What's your infraposterior going to be? And what update happens to each individual component in your set of hypotheses?
We'll present the theorem, and then go into what it means.
Theorem 2: Infra-Disintegration Theorem: Let be some arbitrary infradistribution over , and be some arbitrary infrakernel . Then , where:
So, and are the off-event utility and likelihood functions of type and , which have been restricted to a function or by plugging in a particular value. and are auxiliary functions , and and will be explained shortly.
What's going on is that each new conditional probability distribution is just the old conditional probability distribution , updated on its own particular fragment of the likelihood function and off-event utility function. You take your old conditional probability distribution, and go "hm, knowing our , the likelihood function is thus-and-such and the off-event utility is thus-and-such, let's just do a standard update"
is much less clear. If we ignore all the terms about, because they're just doing a shift and rescale to make things an actual infradistribution, then what it's doing is roughly attempting to "undo" the update that does. What it's basically doing is assuming that the you're feeding in is what the kernel is reporting to you about a mystery function . It's pretending your is the function given by
And the and functions are trying to undo the updates done by all the to figure out what the original kernel would say about , it's trying to go back to
Pretty much, it's going "ok, is the reports the updated kernel is giving about a mystery function . I need to scale these reports down for the (the function) that are improbable under the update, and add on the guaranteed baseline utility for a given (the function) to undo the updates that happened to the kernel and find out what the original kernel thinks about this mystery function"
If the actually was the reports from about a mystery function , then things cancel out to make
Also, some subleties about . It's (kind of) an infrakernel of type , we don't necessarily have the ability to make up an arbitrary extension like for the classical disintegration theorem, because of our Feller continuity/pointwise convergence constraint on infrakernels. If we weren't dealing with Polish spaces in full generality, this would be a bit of a mess because we could have discontinuities in the kernel on the edges where , but since we're working in Polish spaces and any open subset of a Polish space is Polish, it just straightforwardly works out. Also, if your space is discrete, you can just make up an arbitrary extension of the infrakernel if you want.
There is a way in which it isn't an infrakernel, though. It doesn't have a uniform bound on its Lipschitz constants. What's up with that? Well, the analogous phenomenon elsewhere in math is having a function that isn't upper bounded, but there's a finite measure where . You can have the thing you're integrating/taking the expectation of "run off to infinity", as long as it does so in sufficiently low-probability areas. And we get exactly this phenomenon, the conditional probabilities can get wilder as they become lower-probability. This is also why the condition for mixing together infradistributions is "expected value of the Lipschitz constant is finite" instead of "Lipschitz constant has a uniform upper bound" which is what you need for infrakernels.
Mixtures and this sort of "infrakernel" can have their Lipschitz constant run off to infinity, but it happens in "low-probability" areas so on net it makes a reasonable result. Actual infrakernels are like bounded functions, because if is bounded, then any finite measure has being finite. So that's what's going on with why the concept of infrakernel seems to behave a little strangely with mixtures and the infra-disintegration theorem.
This result has some applications. For example, if you've got a state, and an infrakernel from states to observations, and you update on the observation, what result do we get? You can just use the Infra-Disintegration theorem.
Another interesting application of this is that it lets you derive the update rule
for continuous likelihood functions , if you started out only believing in that update rule for 0-1 indicator functions on clopen sets. It derives continuous updates from "the observation either happened or it didn't" updates.
Basically, let's say your likelihood function is a Markov kernel giving your odds of seeing the observation or not, and you have some utility function of "what happens when I don't see ". And if you update your semidirect product on (a clopen set), with g as your off-event utility function, and project it back to the coordinate, it makes the update rule for continuous indicator functions! If you want, you can even work out the update rule for having Knightian uncertainty about how inputs translate to odds of seeing the observation, this could let you do that too.
Further, if you're trying to get an analogue of Bayes for infrapriors... well, it has an uglier form than standard Bayes (given in the last post), but it can be done with this theorem.
Proposition 39: Given a crisp infradistribution over , an infrakernel and suggestively abbreviating as (hypothesis ) and as (your infraprior where you have Knightian uncertainty over how to mix the hypotheses), then
This recovers our original reformulation of infra-Bayes as a special case. Roughly, the reason it looks more complicated is there's weird blending between how well you do in different hypotheses and the starting probability distribution over hypotheses that Murphy picked. However, if our is an actual probability distribution over , then this turns into:
Ie, update each hypothesis individually (in our general disintegration thing, we updated each fiber individually), weight them by the "probability" they assigned to the observation, mix them back together, and rescale, which is exactly our original formulation of how Infra-Bayes worked. But when the probability distribution over hypotheses can vary, then you can't necessarily pull off these sorts of cancellations.
Also, because I couldn't figure out where to put it, here's an analogue of Markov's Inequality.
Proposition 40: If a likelihood function is 0 when , and and , then
Note that when is homogenous, this turns into . And, if we ignore continuity issues for the moment and let be the indicator function for "", then it turns into "the infraprobability that is less than the expectation of divided by ", which reduces to just the standard Markov inequality for probability distributions.
Section 6: IKR-distance
So, the obvious choice for a distance metric between infradistributions,
is actually the total variation distance for infradistributions (it reduces to the total variation distance for standard probability distributions). But does our KR distance metric for measures generalize to infradistributions somehow? Well... yes. Our analogue of the KR-metric is:
Definition 21: Infra-KR metric
The IKR distance between two infradistributions is:
is the space of bounded Lipschitz functions , and is the Lipschitz constant of . Notice that having a notion of "Lipschitz function" requires a metric on . So, this metric should be thought of as being induced by a metric on .
Pretty much, here's why it works. For standard probability distributions, is:
However, for any bounded Lipschitz function , is a 1-Lipschitz function bounded in , and we can pull the constant out of the expectations, so we can also write the KR-distance as:
And this form of the KR-metric generalizes perfectly to infradistributions.
In fact, we could probably just call this the KR metric for infradistributions, because it lines up perfectly with the original KR metric on probability distributions. However, in the proofs associated with this section, we often toggle between looking at the distance between measures, as well as the distance between infradistributions, and so it's useful to have our terminology keep track of what sorts of things we're assessing the distance between.
This notion of distance between infradistributions doesn't look like much, but it's actually quite special. First, we should verify basic properties.
Proposition 41: The IKR-metric is a metric.
Ok, that's nice to know.
Proposition 42: The IKR-metric for infradistributions is strongly equivalent to the Hausdorff distance (w.r.t. the KR-metric) between their corresponding infradistribution sets.
If you haven't seen it before, strongly equivalent metrics are within a constant factor of each other. So, this metric is equivalent to "how far away are the two sets of a-measures from each other in Hausdorff-distance, where we're using the KR-metric on measures to induce a Hausdorff-metric between sets"
This is an extremely important result, because it lets us think of convergence of infradistributions either on the functional level, or on the set level, and the latter is honestly much more useful for proving results. To be more precise about what this result is saying, if you equip with a metric, this lets you know which functions are Lipschitz. This gives you the IKR-metric, but it also gives you a KR-metric on measures, which can be extended in a canonical way to a KR-metric on a-measures, which gives you a Hausdorff distance metric between sets of a-measures. If you go in these two directions from a single metric on , you get metrics that are within a constant factor of each other, given our LF-duality where you can think of infradistributions as either sets of a-measures or as concave monotone functionals on .
So, the IKR-distance is equivalent to "how close are these two sets of a-measures to each other". And it makes sense of why we had a Hausdorff-continuity condition back when we were talking about belief functions, before we realized how natural that sort of continuity is.
Proposition 43: A Cauchy sequence of infradistributions converges to an infradistribution, ie, the space is complete under .
Alright, cool! This limit keeps us within our ordinary comfortable space of inframeasures and produces no additional strange mathematical creatures when we take the Cauchy completion.
Now, there's one thing to note. From our discussion above, the IKR distance and the strongly equivalent KR-Hausdorff distance both critically depend on what metric our starting space is equipped with. This metric-dependence is worrying. If we swapped out the metric on our starting space, would it make the topology on the space of infradistributions different?
Proposition 44: If a sequence of infradistributions converges in the IKR distance for one complete metric that is equipped with, it will converge in the IKR distance for all complete metrics that could be equipped with.
This is a really important one. The topology on isn't affected by which metric on we picked. (After all, picking out a different metric on makes different functions Lipschitz, you'd naively think it could mess with distance). Any old metric that induces the requisite topology on your Polish space that's complete will produce the exact same notion of "convergence" for infradistributions. So it's a fairly natural sort of convergence that we've identified.
Proposition 45: If a sequence of infradistributions converges to in the infra-KR distance, then for all bounded continuous functions , .
A very similar thing applies for probability distributions over a Polish space, and that was the inspiration for this result. If probability distributions weakly converge, then you get pointwise convergence for all function expectations. The exact same result generalizes here.
However, there's one important difference from the Bayesian case that we should note. The converse doesn't hold! It's possible to have a sequence of infradistributions , where, for all bounded continuous functions , , without being a limit of the sequence. So keep that in mind.
Our next result that we'll tackle is getting necessary-and-sufficient conditions for (pre)-compactness of a space of infradistributions. If you haven't seen it before, precompactness aka relative compactness is "any sequence of points from this set has a convergent subsequence" ie "this set is a subset of a compact set"
But in order to do this, we'll have to define something called the b-uniformity condition.
Definition 22: b-Uniform
A collection of infradistributions is b-uniform if:
Where is the expectation functional associated with the set
This condition may seem a bit mysterious. To begin, is where you take the infradistribution set , delete every point with a value more than , and rebuild an infradistribution set back up again. Fundamentally, it's a sort of approximation property. You can view an infradistribution as being specified by its set of minimal points, and if the set of minimal points has some upper bound on its values, then that's good. However, it's possible to have infradistributions with minimal points having unboundedly high b values, which... isn't good from our point of view where we want compactness or something like it on everything we can. However, any infradistribution like this can be arbitrarily-closely approximated in Infra-KR distance by chopping off the parts of the set with ultra-high values, and rebuilding an infradistribution. You could think of it as something vaguely analogous to trying to approximate a uniformly continuous function with Lipschitz functions.
Anyways, ramping up your cutoff for the minimal points gets you better and better approximations for what the true infradistribution is actually like. So, a collection of infradistributions being b-uniform means that if you want to approximate an infradistribution in the collection to within a certain accuracy, you have a guarantee on how high your cutoff has to be to get an approximation with that level of accuracy.
Anyways, we can now return to giving necessary-and-sufficient conditions for (pre)-compactness of a set of infradistributions with the IKR-topology.
Proposition 46: A set of infradistributions is precompact in the topology induced by the IKR distance iff:
1:There's an upper bound on the Lipschitz constant of all the infradistributions in the set.
2: There's a sequence of compact sets , one for each , that are compact -almost-supports for all infradistributions in the set.
3: The set of infradistributions is b-uniform.
These three necessary-and-sufficient conditions correspond to the three possible ways that a set of a-measures can fail to be compact. They can have unboundedly large value (roughly analogous to condition 3 failing), they can have unboundedly large amounts of measure present (perfectly analogous to condition 1 failing), or the collection of measures may be "too big" when the space isn't compact (you can't find a sequence of compact sets that engulfs more and more of the available measure present), which is closely analogous to condition 2 failing.
Proposition 47: When is a compact Polish space, the spaces of cohomogenous, crisp, and sharp infradistributions are all compact in equipped with the infra-KR metric.
This is a pretty easy corollary of more meaty results. Specifying that is a compact set takes care of the second compactness condition automatically because is an -almost-support for all infradistributions and all , so it works. Then, you just need a bound on the amount of measure present (which homogenous infradistributions fail), and a bound on the b term present (which 1-Lipschitz and C-additive infradistributions fail), leaving cohomogenous, crisp, and sharp infradistributions left over. All that remains is just showing that an infradistribution having these properties is preserved under IKR-limits, which is fairly easy to show from Proposition 45.
Looking at the conditions for compactness, "bounded Lipschitz constant" and "shared compact sets" should look suspiciously similar to the defining conditions for an infrakernel. Also, Proposition 45 seems closely linked to the "pointwise convergence" property of an infrakernel? Could infrakernels just be continuous functions? Well... kinda, yeah.
Proposition 48: A function is an infrakernel and fulfills the property:
iff the function is bounded and continuous when is equipped with the IKR metric.
We do need to make this a bit clearer. This is basically saying that if we were to add a "the sets of infradistributions associated with feeding compact sets into the function are b-uniform" condition to infrakernels, we could perfectly identify them with just IKR-continuous functions where (bounded).
Now, I have suspicions on how to rework the metric/topology a bit so this additional condition isn't needed, but it'd come at the cost of making several other conditions much more complicated. So, my current view of things is that we might as well throw this condition into the definition of an infrakernel, even though it's not strictly necessary. It's not particularly restrictive to stick to infrakernels like this. Any infrakernel where all the have the value of all their minimal points being less than 1 zillion fulfills this property. And then, once that condition is added, we would be able to just go "an infrakernel is a bounded continuous function where has the IKR-topology" and everything would be perfect.
Also, we have:
Proposition 49: The space equipped with the IKR-topology is a Polish space if is too.
So, the space of infradistributions is the sort of space you can define infradistributions over!
And there's one last way to characterize the topology. Generally, a topology is specified by giving a base. A base for a topology is a collection of open sets where every open set of the topology can be made by unioning together open sets from this collection. If you've got a distance metric, you can make a base consisting of all the open balls (radius varying) centered at all the different possible points. But it seems somewhat coincidental that every possible choice of IKR-metric (you stick with a metric, that tells you what the Lipschitz functions are, you get an IKR-metric from that) induces the same topology on the space of infradistributions, doesn't it? We'd ideally want a base for the topology that doesn't talk about metrics in any way.
To lift analogous results from other areas of math, the IKR-metric is strongly equivalent to Hausdorff-distance, so let's look at some of how Hausdorff-distance behaves.
Let's say is a Polish space. Then (the compact subsets of ) is a Polish space too. And interestingly enough, no matter which metric you equip with, it makes a Hausdorff-distance metric on , and they all end up inducing the same topology, so we should look at that. The topology is the Vietoris topology, so maybe we can adapt the Vietoris topology somehow.
As it turns out, yes. We need to explain what the Vietoris topology first, though. Remember, it's a topology on the space of nonempty compact subsets of a space . So, an open set is going to consist of a set of nonempty compact subsets of .
The basis open sets for the Vietoris Topology are all generated as follows: First, you specify finitely many open sets in the original space. Then, the set
Is your open set of compact sets. It's every compact set that's a subset of the union of opens, and has nonempty intersection with each open. So, every finite collection of open sets in the original space induces a basis open set for the Vietoris topology.
Because of the strong equivalence between the IKR-metrics and the Hausdorff-metrics on , and Hausdorff metrics being connected to the Vietoris topology, we could probably characterize sets of infradistributions in some Vietoris-like way. The problem is, the Vietoris topology and its close link to Hausdorff-distance between sets only works well for compact sets. Infradistribution sets aren't compact, because they've got the upper-completion thing going on. But, amazingly enough, we can make something Vietoris-like work.
Our variant of it is, instead of specifying finitely many open subsets of in full generality, we specify finitely many bounded-b open sets . They're open sets of a-measures with a maximum value. Then, we make the set:
Where is the projection of a set of a-measures to a set of measures.
And this is a basis open set for our analogue of the Vietoris topology. All the open sets like this, induced by finitely many bounded-b open sets. The three major differences from the Vietoris topology are: we're not using arbitrary open sets, we're restricting the value. Also, when we take the union of the , we upper-complete all of them first (add the cone of to them), in order to check whether is a subset of them. Finally, we need that, when we project down to its measure components and take the closure, that it lies within the projection of our opens.
Er... why is the infra-Vietoris topology so much more complicated than the standard Vietoris topology? Well, the reason the Vietoris topology works so well for compact sets and so poorly otherwise, is when you've got a compact set inside an open set, the distance to go from the compact set to the region outside the open set is always lower-bounded by a nonzero constant. You can wiggle your compact set around a tiny little bit and it'll remain within the same union of opens.
However, with an arbitrary closed set, if it "runs off to infinity", it's possible that it gets arbitrarily close to the boundary of the open set as it "runs off to infinity", so any tiny wiggle in the closed set means the new set goes outside the union of opens.
Now, our infradistribution sets do "run off to infinity", in the form of upper-completion, but they do so only in a well-controlled and understood way, and if they weren't doing that, they'd act like compact sets. So, the new "projecting down your infradistribution set and taking the closure of it lies in the projection of the union of opens" condition is enforcing that little bit of wiggle room, that you can't have your infradistribution set getting arbitrarily close to the exterior of the union of opens. And the "upper-complete the opens" and "bound the values of the opens" conditions are also shutting down another way where you could get into a situation where wiggling your infradistribution a little bit goes outside your open set of interest. So the extra complexity is taming the only way in which infradistribution sets aren't compact.
Proposition 50: The infra-Vietoris topology and the topology induced by the IKR metrics are the same.
The theory of this notion of distance is thus about as nice as we could hope for. The reason why we mandated infradistributions of type signature instead of , is that almost all of these proofs critically hinge on compactness arguments that you can only pull off when the upper completion is "small" (just add stuff to the term), not when the upper completion is "large" (adding any a-measure or any sa-measure). I beat my head against the problem for a month or so trying to get the type signature to work, it just doesn't. I guess if you wanted you could take a quotient space of and get a topology on that, but I don't whether it would behave well. The resulting space would at least be a Suslin space, for what it's worth.
Let's move on to Markov processes.
Section 7: Markov Processes
So, Markov stuff tend to work much better with crisp infrakernels. Ie, you don't have the stuff going on or any weird measures, all the sets are just generated by a set of probability distributions.
For work on environments, useful concepts are infra-MDP's and infra-POMDP's. An infra-MDP is a tuple of: A Polish space (states), a Polish space (actions), a starting infradistribution in , and a crisp infrakernel . An infra-POMDP is the same, except instead of the state being the same as the observation, we have a space of observations and a crisp infrakernel .
Results on these are deferred to the next post. However, we do have one interesting result about Markov chains. In the standard probabilistic case, for a fairly broad range of conditions, a Markov chain has a unique stationary probability distribution that you can find by iterating. However, is usually taken to be a finite space.
In our case, there's conditions for a crisp infraMarkov chain (when initialized with a crisp infradistribution) to have a unique stationary crisp infradistribution. We do have to make assumptions moderately stronger than the usual Markov chain fixpoint proof. But in return, we get a much stronger result that applies to all Polish spaces. Have you ever wanted fixpoints of Markov chains over the natural numbers? Well, this gives you a condition to check to ensure they exist. The upcoming theorem also proves the Banach Fixpoint Theorem as a special case, though it's really a circular proof because the Banach Fixpoint Theorem is used in the background.
The conditions are:
1: Your space is equipped with a metric where the distance between two points is always at most 1 (this can always be done without changing the topology)
2: is a crisp infrakernel .
3: There's a where, regardless of the and selected from ,
is Hausdorff distance w.r.t the KR-metric on probability distributions, btw. Since we assumed was a crisp infrakernel, and crisp infradistributions always have their set of minimal points being a set of probability distributions, this is evaluating Hausdorff distance between the sets of probability distributions that the are associated with.
The final condition is the really important one, and it says that two points close together must have the Hausdorff distance between their sets of probability distributions get a little bit closer when you apply the kernel. (if you only have a guarantee that they get closer after iterations of the kernel, you can just compose the kernels and project to the last coordinate to lump them into one big kernel with this property).
This may seem a bit mysterious. Roughly, if you're dealing with dirac-delta distributions, and your is actually a continuous function (points in correspond to dirac-delta measures in which all make crisp infradistributions in ), then you're in the setting of the classical Banach fixed point theorem, and your points had better get closer when you apply .
If you're in a setting where you have finitely many states, and are dealing with probability distributions, like the setting of the standard Markov fixpoint theorem, then this condition is saying something like "given any two states, there must exist some third state that both states have some positive probability of entering on the next timestep". A state going around in a loop doesn't fulfill this property.
And for sets of probability distributions induced by feeding one of finitely many states x into an infrakernel, this condition is saying "Given any two states and and any distribution , there's a where and don't have disjoint support". So this condition is actually quite weak.
Sticking in the standard Markov setting with conventional boring probability distributions, here's how this can, say, get you a stationary probability distribution over the natural numbers, which isn't a usual sort of setting for stationary distributions. Given two distributions over the numbers, we can split them into a chunk of probability measure that they agree on, and two disjoint chunks of probability measure that are unique to and and don't overlap. Each time we iterate the Markov kernel, that "any two different numbers must have some third common number they both have a shot at transitioning to" condition means that a little slice of probability measure is added to the "overlap of measure" pile. The same condition also prevents the distribution from running off to infinity. Anyways, with those conditions, we get:
Theorem 3: Given a crisp infrakernel then if there's a where, regardless of and , , there's a unique crisp infradistribution where , and can be found by starting with any crisp infradistribution on , and repeatedly applying .
Section 8: Entropy
For this, we'll be restricting to the case where is a space consisting of finitely many points, and try to figure out what the entropy of an infradistribution is. We'll start with the definition of Renyi entropy for infradistributions in general, and keep working on it until we end up at an intuitive meaning of what Shannon entropy is for crisp and cohomogenous infradistributions.
Also, notation warning: Since is already taken for infradistribution sets, will be used to denote the entropy of an infradistribution. We'll also be using , and nats, instead of and bits, but you can just change the logarithm base accordingly to convert, it causes no issues.
So, as a recap, Renyi entropy is a family of entropy functions for any number (extended real line). The classic Shannon entropy we know and love is when . Sadly, the equation for Renyi entropy has a divide-by-zero error when that happens, and also crashes when or but you can take a limit in those three cases. For probability distributions, it is defined as:
All the Renyi entropies get bigger as the probability distribution gets more spread out. For , it's the logarithm of the size of the support of (how many options are possible), for , it's the good old "what's the expected amount of information needed to communicate what result happened from this probability distribution", and for , it's the negative logarithm of the upper bound on the probability for any event, the entropy would be high if no event has a particularly high probability.
For infradistributions, it's a more complicated definition, and we can only define it for numbers in , the endpoints by taking limits. Fortunately, the most commonly used entropy by far is Shannon entropy, and that's for . But whoo boy the proof that the limit exists was not fun. Thankfully, we'll be able to reexpress the Shannon entropy for cohomogenous infradistributions in a tidier form. Here's Renyi entropy for infradistributions:
Definition 23: Renyi Entropy
The Renyi entropy for of an infradistribution over finitely many states is defined as (where is taken over all functions where )
Note that is the function .
It is not at all obvious that this is the same thing as Renyi Entropy for probability distributions. However,
Proposition 51: If is the infradistribution corresponding to a probability distribution , then if , , where the latter is the conventional definition of Renyi entropy for probability distributions, and the former is the definition of Renyi Entropy for infradistributions.
So, this recovers the standard definition and matches up with Renyi entropy for probability distributions, it's just shuffled around somewhat to compensate for the limitations of infradistributions not being probability distributions and being restricted to functions in .
Now, the obvious next question is whether the and limits exist for infradistributions. Especially the second one, since that's Shannon entropy. Well, the first one is easy.
Proposition 52: exists for all infradistributions , and equals
Ok, that's a pretty obvious limit. But what about the limit of
That seems harder, because the fraction in front limits to . And if you briefly assume that the suitable is supported over all possible outcomes, then that function inside would be raised to a power of nearly 0, so it'd be really close to the constant function that outputs 1, and h would assign it a value near 1 by normalization. So would be near 1, and of that would limit to 0. , that's definitely an indeterminate form. But L'hopital's rule doesn't help figure out this limit, because we've got a supremum over all the , and isn't even differentiable! So it's quite difficult to prove that the limit exists, requiring more Taylor expansions than a physics paper. But it can be proven, leading to:
Theorem 4: exists for all infradistributions over a finite set , and equals
In this case, is any function where , and is the directional derivative of at 1 in the direction of , ie
Pretty much, is negative, and you ask what the slope of is at 1 if you were to go a tiny bit in the direction of that function. Of course, you're starting at the maximal value of , and going a little tiny bit in a direction which slopes down, so all these derivatives will be negative. You take the one which is closest to 0, flip it around to a positive number, and you're done.
Now, since the Shannon entropy depends only on the differentials of your infradistribution around 1 (which are pinned down by tangent hyperplanes around 1 ie minimal points with ) this implies that even though this quantity is technically defined for all infradistributions, it'd be throwing away a whole lot of infradistribution behavior, unless your infradistribution was entirely pinned down by the differentials around 1/had all minimal points have .
And that's just cohomogenous infradistributions (with crisp infradistributions as a special case). So, it's for those infradistributions that we should be looking for an interpretation of this mysterious quantity. And indeed, we do get such an interpretation.
Proposition 53: For infradistributions,
is the cross-entropy. It's "what's the expected amount of information to communicate what just happened, when we're using an encoding scheme optimized for the distribution , and the events are actually being selected according to ." So, this is basically saying that the Shannon entropy of an infradistribution is: determined by the differentials around 1, can be interpreted as "what's the expected amount of nats needed to send a message when I'm picking the best encoding I can and Murphy is trying to maximize the expected number of nats I send in my message", and can also be interpreted as merely "what's the highest entropy of one of these infradistributions"
We can clearly see that the restriction on the minimal points we're using means that this entropy quantity is fairly nonsensical for infradistributions in general. But cohomogenous infradistributions have all minimal points have , so for them, the entropy turns into:
And for crisp infradistributions, we get an even nicer picture, because all their minimal points have . For them, entropy becomes
Moving on with the intuition, the entropy of a probability distribution is the expected amount of information it takes to communicate what just happened using a code that's optimized for that probability distribution.
So for this, the entropy of a set of probability distributions is "what's the expected amount of information it takes to communicate what just happened, given that the probability distribution is being adversarially selected to maximize my expected message length, and my encoding of outcomes as bitstrings is optimized accordingly to deal with this." A very nice interpretation of what entropy means for infradistributions! Also, it can be thought of as just "what's the maximum possible entropy that my foe could select from their available options".
Now, let's get into properties of Shannon entropy.
Proposition 54: For all infradistributions, , entropy is upper bounded by the logarithm of the number of states.
Roughly, this occurs because you can always let your be the uniform distribution, which, as a code, is "I'll use the same message length for everything that happens". This is clearly immune to adversarial choice of probability distribution, and gets you an expected message length of .
Proposition 55: For all infradistributions, entropy is concave.
This is just a basic property of entropy, nothing fancy.
Proposition 56: For all infradistributions, entropy doesn't increase after deterministic pushforward.
Ie, it's as hard or easier to communicate what happened after a deterministic process occurred, as opposed to before a process occurred. The worst-case is an injective function , but if you're not in that case, then maybe maps several inputs to the same output, and you can economize on your message length as a result.
Proposition 57: For cohomogenous infradistributions,
This roughly says that the entropy of a semidirect product can be decomposed into two components. There's the entropy of the starting coordinate, and there's the worst-case expected entropy of the resulting coordinate.
Proposition 58: For cohomogenous infradistributions, , with equality when the infradistributions are crisp.
For the equality case, this says that the entropy of a product is the sum of the entropy of the components. There's the entropy of the starting coordinate, and there's the entropy of the coordinate, which are independent. Surprisingly enough, this holds anyways even though our notion of direct product varies depending on order and there isn't the sort of intuitive independence we have for products of probability distributions.
Section 9: Future directions
We've got more stuff on hybridizing infra-Bayes and Cartesian Frames, the analogue of KL-divergence in this setting (since we have entropy), the internal logic of infradistributions, reinforcement learning regret bounds, how to properly handle Nirvana, proper scoring rules for infradistributions, the category theory of infradistributions, and more, but that's for another time.