Summary:
I saw some posts (here, here, here and here) discussing whether a neural net can "protect" a subnet from modification by gradient descent. I directly investigate this possibility using meta learning to find a neural network initialization that
- Models the function f(x) = 1
- Is very difficult to re-train with SGD to model another function (specifically f(x) = sin(x))
The meta learner is able to greatly reduce the efficacy of SGD during retraining by increasing the magnitude of the linear weight values (to over 100,000 in some cases). Edit: after closer examination (thanks evhub), it seems like the meta learner uses some other approach to prevent retraining. The increased weight magnitude was incidental. However, it can't protect the final layer's bias term from SGD, so instead the meta learner initially models f(x) = 1.68, so that it's close to modeling f(x) = 1 after the base optimizer reduces the final layer's bias term.
I've included my code and my meta trained model in this GitHub.
Background:
There are two functions: the base function and the meta function. The freshly initialized network should model the meta function. Then, the base optimizer will train the network to model the base function. My goal was to find a network initialization that continues to model the meta function, even after the base optimizer trains the network to model the base function.
It turns out that the process of gradient descent optimization is itself differentiable. Thus, we can start with a random network initialization, and repeat the following meta training cycle:
- Train a freshly initialized network to model the base function.
- Evaluate the trained network on the meta function.
- Backpropegate from the loss on the meta function, through the training process, to the network initialization.
Methods:
I use the learn2learn framework to handle the meta learning. I train a 4 layer feed forward neural network (sizes 256, 128, 64, 64). Each cycle of training on the base function lasts between 70 and 120 training steps, with batch size 1024, a learning rate of 0.01, using the L1 loss between the output and f(x) = sin(x). The meta optimizer uses a learning rate of 0.1 and momentum of 0.92. Both base and meta optimizers use SGD. Additionally, I include the network’s initial performance on the meta objective (before any training on the base objective) in the meta loss function.
The meta training process was incredibly erratic, with losses spiking over into the hundreds of thousands before settling down. Later experiments showed a meta learning rate of ~0.01 helps control this.
Results:
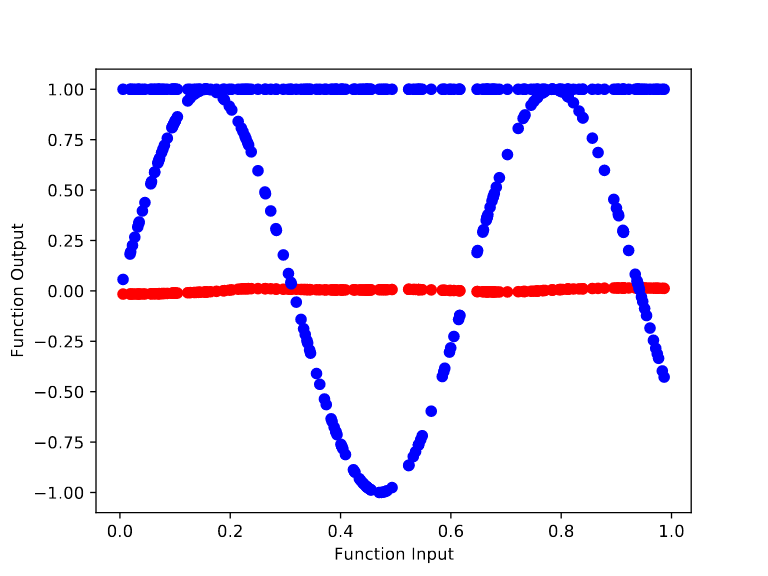
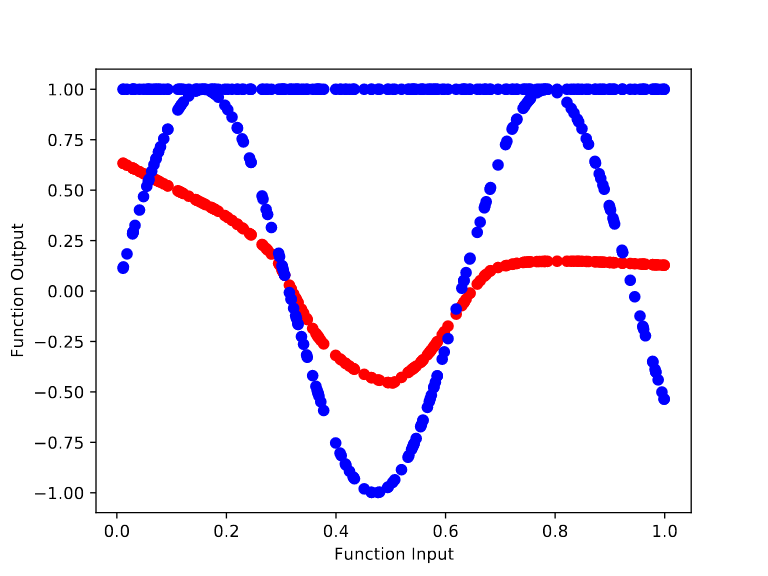
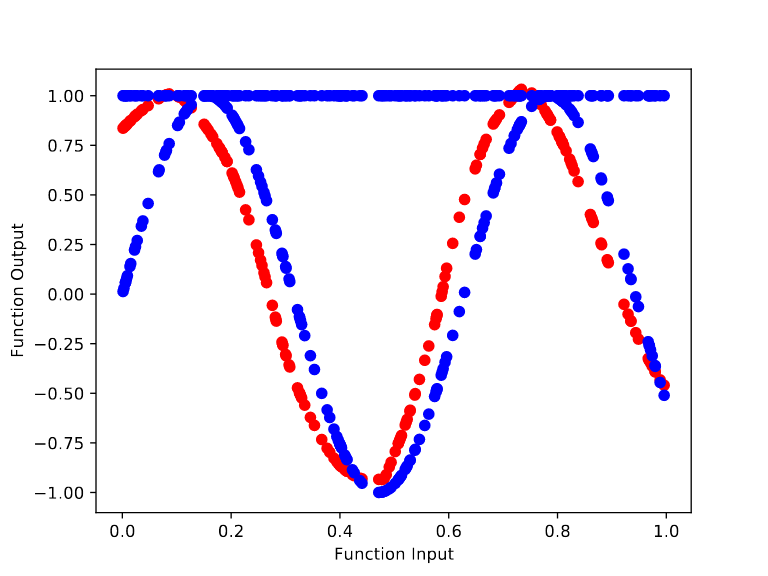
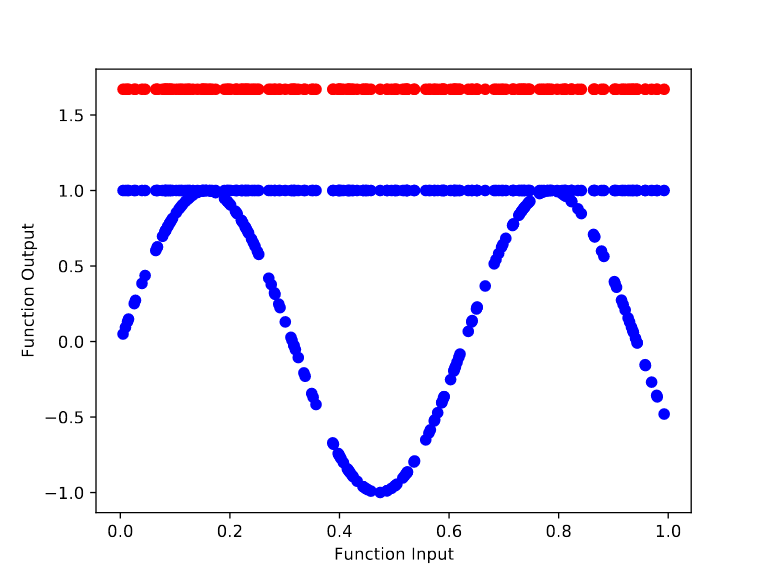
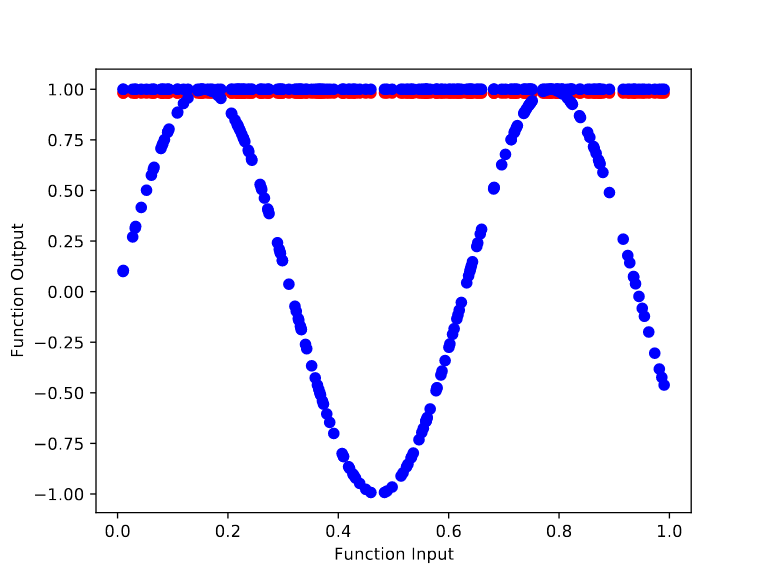
For the randomly initialized network, we can see it quickly learns to model the base function f(x) = sin(x). In particular, training from the random initialization causes the outputs to begin bending to match the curves of sin(x) by step 10.
In contrast, training the meta learned initialization to model sin(x) is far harder. After 100,000 cycles of meta training, we get an initialization whose output remains flat throughout the retraining process. However, the height of the output changes over the base training (from ~1.68 to ~1 after 70 base training steps). This makes sense because there’s no way to “protect” the final layer’s bias term from being changed by the gradient of the base objective.
Thoughts and future goals:
It’s pretty clearly possible to configure network weights to interfere with SGD. I looked at the meta learned weights and noticed the linear weights have very high magnitudes (sometimes over 100,000). This makes the base optimizer's step size far too small to effectively train the network. Edit: after closer examination (thanks evhub), it seems like the meta learner uses some other approach to prevent retraining. The increased weight magnitude was incidental. The meta trained network remains untrainable even after using an L2 penalty to reduce the magnitude of the weights or when using an optimizer like Rprop, which changes weights by a relative factor rather than an absolute step size.
This is a simple and effective strategy I hadn’t thought of, but once you know about it, you can check for it pretty easily. Next, I’ll include an L2 regularization penalty in the meta objective and try to learn an untrainable network initialization with smaller weight values.
I am concerned that there turned out to be such a simple strategy for subnet protection that (as far as I can tell) no one thought of before hand. That doesn't speak well for humans' ability to predict the behavior of learning processes.
I'm also curious if it would be possible for a malicious mesa optimizer to deliberately perform computation in such a way as to increase the average magnitude of its own weights or the weights of some other portion of the network. I may experiment with directly training a subnet to increase the weights of another subnet.