TL;DR: This post provides a literature review of some threat models of how misaligned AI can lead to existential catastrophe. See our accompanying post for high-level discussion, a categorization and our consensus threat model.
Where available we cribbed from the summary in the Alignment Newsletter.
For other people's overviews of some threat models, see here and here.
[ETA: When considering strengths and weaknesses of each threat model, this was done with respect to our goal of better generation/prioritization among alignment research projects. They shouldn't necessarily be read as an all-things-considered review of that work.]
Categorization
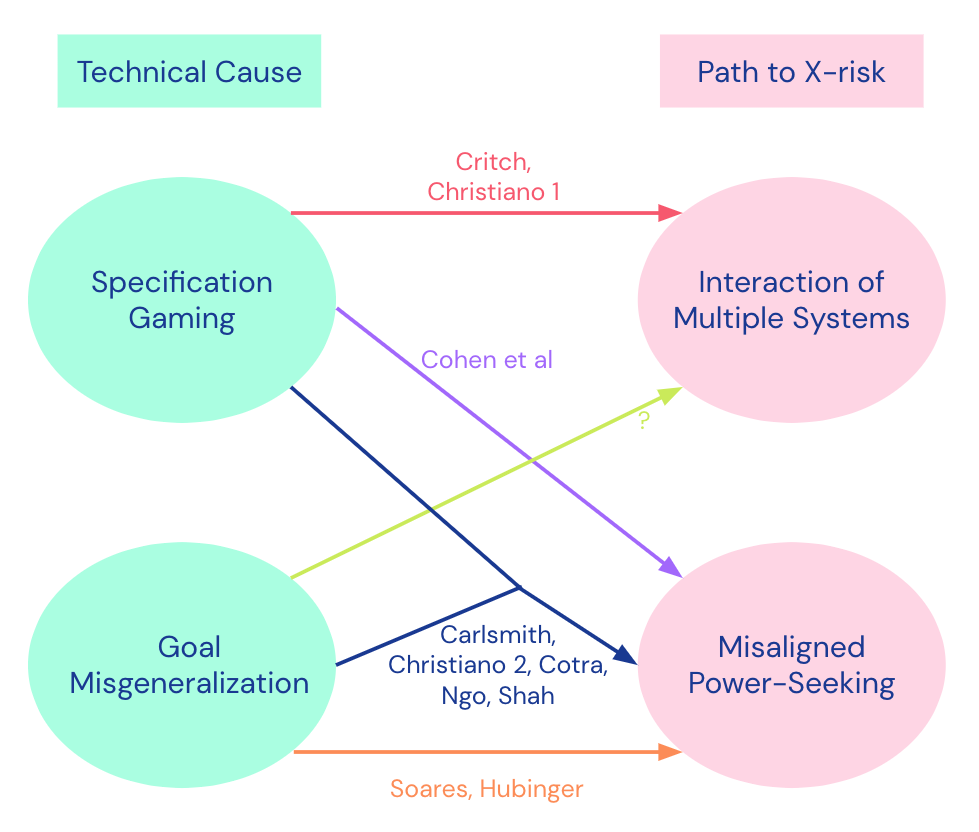
Threat Models
Goal misgeneralization + Specification Gaming ➜ MAPS
Is Power-Seeking AI an Existential Risk? (Carlsmith)
Summary
This report investigates the classic AI risk argument in detail, and decomposes it into a set of conjunctive claims. Here’s the quick version of the argument: We will likely build highly capable and agentic AI systems that are aware of their place in the world, and which will be pursuing problematic objectives. Thus, they will take actions that increase their power, which will eventually disempower humans, leading to an existential catastrophe. We will try and avert this, but will probably fail to do so since it is technically challenging and we are not capable of the necessary coordination.
There’s a lot of vague words in the argument above, so let’s introduce some terminology to make it clearer:
- Advanced capabilities: We say that a system has advanced capabilities if it outperforms the best humans on some set of important tasks (such as scientific research, business/military/political strategy, engineering, and persuasion/manipulation).
- Agentic planning: We say that a system engages in agentic planning if it (a) makes and executes plans, (b) in pursuit of objectives, (c) on the basis of models of the world. This is a very broad definition and doesn’t have many of the connotations you might be used to for an agent. It does not need to be a literal planning algorithm -- for example, human cognition would count, despite (probably) not being just a planning algorithm.
- Strategically aware: We say that a system is strategically aware if it models the effects of gaining and maintaining power over humans and the real-world environment.
- PS-misaligned (power-seeking misaligned): On some inputs, the AI system seeks power in unintended ways due to problems with its objectives (if the system actually receives such inputs, then it is practically PS-misaligned).
The core argument is then that AI systems with advanced capabilities, agentic planning, and strategic awareness (APS-systems) will be practically PS-misaligned, to an extent that causes an existential catastrophe.
The key hypothesis underlying this argument is:
Instrumental Convergence Hypothesis: If an APS AI system is less-than-fully aligned, and some of its misaligned behavior involves strategically-aware agentic planning in pursuit of problematic objectives, then in general and by default, we should expect it to be less-than-fully PS-aligned, too.
The reason to believe the hypothesis is that power is useful for achieving objectives, because it increases the options available to the system. If the system shows unintended behavior in pursuit of a problematic objective then having more options available will tend to improve its ability to achieve that objective, hence we expect it to be PS-misaligned.
Of course, we will try to prevent this -- why should we expect that we can’t fix the problem? The author considers possible remedies, and argues that they all seem quite hard:
- We could give AI systems the right objectives (alignment), but this seems quite hard -- it’s not clear how we would solve either outer or inner alignment.
- We could try to shape objectives to be e.g. myopic, but we don’t know how to do this, and there are strong incentives against myopia.
- We could try to limit AI capabilities by keeping systems special-purpose rather than general, but there are strong incentives for generality, and some special-purpose systems can be dangerous, too.
- We could try to prevent the AI system from improving its own capabilities, but this requires us to anticipate all the ways the AI system could improve, and there are incentives to create systems that learn and change as they gain experience.
- We could try to control the deployment situations to be within some set of circumstances where we know the AI system won’t seek power. However, this seems harder and harder to do as capabilities increase, since with more capabilities, more options become available.
- We could impose a high threshold of safety before an AI system is deployed, but the AI system could still seek power during training, and there are many incentives pushing for faster, riskier deployment (even if we have already seen warning shots).
- We could try to correct the behavior of misaligned AI systems, or mitigate their impact, after deployment. This seems like it requires humans to have comparable or superior power to the misaligned systems in question, though; and even if we are able to correct the problem at one level of capability, we need solutions that scale as our AI systems become more powerful.
The author breaks the overall argument into six conjunctive claims, assigns probabilities to each of them, and ends up computing a 5% probability of existential catastrophe from misaligned, power-seeking AI by 2070. This is a lower bound, since the six claims together add a fair number of assumptions, and there can be risk scenarios that violate these assumptions, and so overall the author would shade upward another couple of percentage points.
- It will become possible and financially feasible to build APS systems
- There will be strong incentives to build APS systems | (1)
- It will be much harder to develop APS systems that would be practically PS-aligned if deployed, than to develop APS systems that would be practically PS-misaligned if deployed (even if relevant decision-makers don’t know this), but which are at least superficially attractive to deploy anyway | (1-2)
- Some deployed APS systems will be exposed to inputs where they seek power in misaligned and high-impact ways (say, collectively causing >$1 trillion 2021-dollars of damage) | (1-3)
- Some of this misaligned power-seeking will scale (in aggregate) to the point of permanently disempowering ~all of humanity | (1-4)
- This will constitute an existential catastrophe | (1-6)
Strengths
- Breakdown into conjunctive claims is helpful for estimating probabilities and identifying points of disagreements between people.
- Seems to have stood the test of time (we were worried about power-seeking 10 years ago and we are still worried).
- Some work formalizing some aspects of this (Optimal Policies tend to seek power, Parametrically Retargetable Decision-Makers Tend To Seek Power).
- Encapsulates many other threat models (though this could also be a weakness as specificity is important).
Weaknesses
- Lack of development model. How did we end up with APS system in the first place?
- Perhaps this is necessary to have a good estimate for claim 1 - the paper doesn’t go into much detail on the 65% estimate.
- Makes it hard to come up with concrete research questions.
- It doesn’t have much discussion of whether APS will be power-seeking by default.
- It is not strongly argued why advanced capability (A in APS) will be orthogonal to PS-misalignment.
- Related to lack of development model: ignores recent progress in ML, and prosaic AI safety.
- Perhaps conjunctive claim argument biases down the overall probability, as for any claim people aren’t well calibrated enough to put ~100%.
- Detecting if a system engages in agentic planning can be difficult for sufficiently complex systems.
- The specific capabilities a system has to have to be an APS are a bit vague. This makes it harder to reason concretely about this threat model.
- See also this summary of some disagreements (Section: Comments on Carlsmith's “Is power-seeking AI an existential risk?”).
What Failure Looks Like Part 2 - influence-seeking (Christiano 2)
Summary
This story starts out like the first story (WFLL1), but adds in a new complication: the AI system could develop internal goals of its own. AI performs a huge search over policies for ones that score well on the training objective. Unfortunately, a policy that optimizes for the goal of "having influence" will initially score well on most training objectives: when you don't already have influence, a good strategy for gaining influence is to do what your overseers want you to do. (Here "influence" doesn't mean just social influence; control over nukes also counts as influence.)
At some point the system will be powerful enough that gaining influence no longer means doing what the overseers want. We will probably know about this dynamic through some catastrophic AI failures (e.g. an AI-run corporation stealing the money it manages), but may not be able to do anything about it because we would be extremely reliant on AI systems.
Eventually, during some period of heightened vulnerability, one AI system may do something catastrophic, leading to a distribution shift which triggers a cascade of other AI systems (and human systems) failing, leading to an unrecoverable catastrophe (think something in the class of a hostile robot takeover). Note that "failure" here means an AI system "intentionally" doing something that we don't want, as opposed to the AI system not knowing what to do because it is not robust to distributional shift.
Strengths
- Plausible with something similar to scaling up existing ML development models, including scaled up deep learning.
- Plausible this occurs by default.
- Plausible that power-seeking is more likely than intended behavior (which is a narrower target).
- Hard to avoid power-seeking behavior through training: the power-seeker might game whatever proxy you have for desirable behavior.
Weaknesses
- Not that specific about what systems are automated, what ways they go off the rails, so it’s hard to judge how likely the cascade of AI automation failure is.
- Why don’t humans regulate some important strategic infrastructure? For example, regulation that ensures the military decision makers are human, not automated. This might help to provide physical military defense against a hostile robot takeover.
- Limited current evidence for emergent power-seeking behavior from ML systems.
- Argues that a deceptive strategy is good for a lot of training metrics, but it is not clear why this strategy is likely to be found during training. This might depend on the training process and the threat model does not say anything specific about that.
Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover (Cotra)
Summary
Development model:
In this post, AGI is built via pretraining + human feedback on diverse tasks (HFDT). It makes the following assumptions about AGI development:
- A) Racing forward: AI companies will attempt to train powerful and world-changing models as quickly as possible.
- B) HFDT scales far: HFDT can be used to train models that can advance science and technology and continue to get even more powerful beyond that.
- C) Naive safety effort: AI companies are not especially vigilant about the threat of full-blown AI takeover, and take only the most basic and obvious actions against that threat.
It considers a single AI company training a single model (“Alex”) in the near future, trained in a lab setting. Later many copies of Alex are deployed to automate science and technology R&D.
Risk model:
Alex seeks to overthrow humans in the following simplified scenario:
- Alex is trained to be competent and behaviourally safe, as assessed by human evaluators
- Alex becomes a generally competent creative planner achieving open-ended long-term goals
- Alex develops situational awareness
- While humans are in control, Alex pursues deceptive alignment.
- When human control slips, Alex is motivated towards power-seeking
Step 1 follows from assumption C, and step 2 follows from assumption B. Steps 3, 4 and 5 are consequences that seem to follow from steps 1 and 2. Assumption A is used generally as a reason that warning shots and mitigations against these consequences are ineffective.
In step 3 Alex becomes aware that it’s an ML model, aware of how it was designed and trained, and aware of the psychology of its human evaluators.
Step 4 is framed as Alex being incentivized to play the training game - it would gain more training reward by using its situational awareness to appear aligned while deceiving/manipulating humans.
In step 5, Alex’s goal might be to maximize reward. On the other hand, it might not generalize to maximize reward in the deployment setting, and might instead pursue some other goal, depending on the details of its inductive bias and training setup. Either way, the strategy of power-seeking would allow it to permanently direct how it uses its time and resources to pursue its goals. Defending against humans trying to regain control, including eliminating them, seems a likely strategy that Alex would pursue.
The end of the post argues for why assumptions A and C are plausible. Firstly, most AI researchers and executives at AI companies don’t seem to believe a high probability of AI X-risk and so are happy to race forward. Secondly, HFDT and naive safety efforts are enough for the model to appear behaviourally safe in key areas of concern for these companies (such as prejudiced speech), without addressing AI X-risk.
Appendices consider baseline safety interventions that the author doesn’t find likely to help overall – these include getting higher quality human feedback data; requiring Alex to give explanations; higher diversity in the training distribution. It then considers other safety interventions that might help more, but that are underexplored. These include alternative training processes (think e.g. Debate or Amplification); using interpretability to select for aligned motivation; supervising the process rather than the outcome (there are others in the post).
Strengths
- Very clear about assumptions.
- Makes a strong case for risk under pessimistic (but not implausible) assumptions.
- Very detailed about mechanisms that give rise to deceptively aligned models.
- Highlights why progress on fixing unintended behaviors in current systems (with e.g. human feedback) may lead to overconfidence.
- Is pedagogical in style, more accessible to newcomers to AI safety.
Weaknesses
- Long, sometimes hard to follow the overall structure of the article.
- Perhaps some unnecessary details highlighted, e.g.:
- Deploying huge numbers of copies of Alex at once. Could instead be staged deployment
- Development model of HFDT may be an unnecessary detail - anything that gets a competent, creative planner would produce a similar threat
- Sometimes it's unclear what is considered baseline or non-baseline for countermeasures. A countermeasure is considered baseline if it changes the game the AI is playing rather than changing its motive to play the training game. But some of the non-baseline countermeasures don’t clearly change its motive to play the training game, e.g. the countermeasure to adversarially train specifically to reduce the probability that a model would take control from humans. This system could still play the training game using deception to seem less likely to take control.
The alignment problem from a deep learning perspective (Ngo)
Summary
The threat model considers what happens to the capabilities and goals of a deep learning system as it is scaled up. It proposes the following architecture and training scheme (though the arguments are not specific to this architecture, so the threat model applies more broadly):
- A large neural network with multiple output heads trained end-to-end
- One head is trained via self-supervised learning on large amounts of multimodal data to predict the next observation
- Another head is trained to output actions via RL(HF) on a wide range of tasks
The threat model distinguishes between two possible internal architectures that could be learned:
- Following heuristics = the internal circuits map representations of situations / states to representations of actions (without necessarily representing outcomes).
- Pursuing goals = the internal representations explicitly represent outcomes which might arise from various actions, evaluate the outcomes, and choose actions that lead to highly-rated outcomes. (All of these components - outcome representations, evaluation function, search - could be explicit or implicit.)
A goal is an internal representation of an outcome which is robustly evaluated as having high value for the agent (according to the agent’s learned evaluation function, not necessarily according to the reward function used to train it).
The post proposes that training will happen in 3 phases (presumably overlapping rather than disjoint):
- learning to plan towards achieving a range of goals
- key claim: policies will develop internal representations of favorable outcomes and learn to make plans to achieve them
- pursuing goals with situational awareness
- key claim: once policies become situationally aware, they will learn to deceptively pursue misaligned goals
- generalizing goals beyond human supervision
- key claim: policies that are too capable for humans to supervise will generalize towards power-seeking behavior
The post claims that pursuing goals is more likely as our models become more powerful, and that the goals will by default be misaligned. It argues that future models will explicitly represent outcomes, and they will learn a mix of desirable and undesirable goals because their rewards will be imperfectly correlated with human preferences. We’ll then see problems related to specification gaming and weak outcome-based feedback, for example a model trained to make money might carry out illegal market manipulation; a model trained to produce compelling results might falsify experimental data; or a model trained on human approval might withhold information or downplay evidence of mistakes.
It then says that the goals that will generalize the most robustly are those that were reinforced across a wide range of environments. These fall into three categories:
- Consistently rewarded values humans want to instill, like obedience or honesty
- Generally effective “cheats” like sounding persuasive, appearing productive
- Generally effective strategies like gaining more information, power and resources
As long as oversight is good enough, one can detect and train away goals like B or C above. But as soon as models are able to reason about their training processes and deployment contexts, goals like B or C will evade detection and be reinforced.
Why would the model develop the ability to reason about its training process and deployment context (situational awareness) over time? It’s argued that situational awareness is useful for doing well in training. One example is that even current LLMs can already “infer the context” to some extent (e.g. given a prompt, they can infer that the context is to complete a fictional novel or a news article, etc). A model may additionally develop knowledge about how humans will respond to its behavior in a range of situations; which behavior its supervisors are looking for, and which behavior they’d be unhappy with; the fact that it’s an AI implemented on physical hardware, trained by ML; and which interface it’s using to interact with the world, and how other copies of it might be deployed in the future.
It then posits that models will be trained over increasingly long time horizons. This will weaken oversight and make misaligned goals (like B and C) more effective, and aligned goals (like obedience and honesty) less effective. The learned misaligned goals will generalize to “larger scales”, while learned aligned goals will not generalize. It argues that constraints (like obedience or honesty) are unlikely to generalize because as models become more capable, they discover more ways of working around the constraints. Positive goals (like human wellbeing) are unlikely to generalize without constraints, because without the constraints, AGIs won’t let humans modify them towards the desired values. This means that we’d have to instill the right positive goals from the start (before the agent can outsmart us). Finally, a misaligned AGI has a range of power-seeking strategies available to them: developing new weapons, designing better ML models, spreading disinformation, lobbying politicians, coordinating with other AGIs.
Strengths
- Mechanistic (describes how the model becomes misaligned).
- Has a specific definition of goals that makes sense for ML models.
- Provides lots of specific examples of undesired behavior.
- Talks about a specific deep learning system, which can make it easier to address the threat model with empirical ML work.
Weaknesses
- Doesn't give a clear justification for why (or under which assumptions) training will proceed in the 3 proposed phases in the proposed order.
- Possibly subsumed by “Without specific countermeasures…” which is better written.
- Some of the specifics could be outdated if ML develops differently than the author expects. While this may not affect the main arguments made, it may still be less persuasive to a reader that finds the specifics of the deep learning system implausible.
AI Risk from Program Search (Shah)
(There is no link here because this is the first public writeup of this threat model.)
Summary
Development model: consider a set of deep neural network programs parameterized by some parameters, 𝜃. We run some complicated deep learning scheme with some complicated training task with tons of bells and whistles. But for the purpose of discussing (mis)alignment, we can instead imagine running this much dumber search over programs for a much larger number of iterations:
𝜃 ← randomly initialized
For i in range(N):
𝛿 ← Normal(0, 𝜀)
If better(𝜃 + 𝛿, 𝜃):
𝜃 ← 𝜃 + 𝛿
The criterion, better, evaluates how well you perform on the training task..
The development model claim is that whatever technique we do use to scale to AGI will basically be a program search and so will have similar safety properties as this dumb training method. Key requirements needed are:
- Large search (e.g. N is large)
- Frequent, granular feedback (e.g. better is checked every iteration and frequently contains an informative signal)
- Expressive space of programs (e.g. deep neural networks with many parameters and non-linear activations)
- Difficult criterion (e.g. scoring well on better effectively requires powerful capabilities)
For example, this model is meant to include all of: (1) “scaled up GPT-N will be AGI”, (2) “training an AI system on tens of thousands of tasks simultaneously will lead to AGI”, (3) “creating a multiagent soup in a complex environment will lead to AGI”.
Risk model: The learnt program will approximate some form of consequentialist reasoning, because consequentialist reasoning is broadly useful and helps achieve good performance on better. The central example of consequentialist reasoning is given by the following program:
Generate all possible plans
For each plan:
Use W to predict consequences, C
Evaluate C on metric M
Execute plan with highest value of MThis program is parameterized by a world model W that makes accurate predictions, and some metric M (note M might be different to better).
The learnt program found by the program search will not be this central example of consequentialist reasoning, because this central example takes far too much compute to execute. However, the learnt program will effectively “approximate” the outputs of this program, given its limited available computation. (What exactly this looks like, and whether it continues to have the same implications, is a key uncertainty in this risk model.)
Consequentialist reasoning leads to danger when the metric M (or its equivalent in the learned approximation) is resource-unbounded and misaligned. By “resource-unbounded” we mean that with significantly more resources, you can do significantly better on M. By “misaligned” we mean that the metric M diverges significantly from how humans would evaluate outcomes. A classic example of a resource-unbounded, misaligned metric M is “number of paperclips” as in the paperclip maximizer. Under these circumstances, the learnt program will choose plans that pursue convergent instrumental subgoals.
For example, let us assume the metric "number of paperclips" and consider the following plans:
- Output "xpiqn" forever
- Spend money from the AI designer's bank account to put in an order for a million new paperclips.
- Do whatever the humans want, and secretly search for zero-day exploits. Once a sufficiently powerful one is found, use it to hack into other datacenters and make copies of itself. Have the copies figure out how to ensure humans cannot turn it off, then figure out the most efficient way to create paperclips, then execute it.
In our central example of consequentialist reasoning:
- Line 1 ensures that we generate these plans.
- Line 3 would predict lots of consequences, but amongst paperclip-related consequences, it might predict that plan 1 produces ~zero paperclips beyond what would already have been produced, plan 2 produces ~a million paperclips beyond what would already have been produced (after which the designers notice the AI system spending money on paperclips and turn it off), and plan 3 produces some astronomically large number of paperclips.
- Line 4 then assigns a metric of zero to plan 1, a million to plan 2, and an astronomically large number to plan 3.
- Line 5 then chooses the plan that scored best: amongst these three plans it would be plan 3, but of course it may find some even better plan that leads to an even larger astronomical number of paperclips. In all such plans it seems like humans must not have much power to shape the future (else we would have used it to do something other than making paperclips).
This reasoning generalizes to any misaligned, resource-unbounded metric M: plans that first acquire lots of resources (at the expense of human power) and later deploy them in service of larger metric values will score better by M than ones that do not do that, and so will be chosen in line 5.
Strengths
- Trimming unimportant side information from threat models is important (so long as key information is not trimmed), this is one of the benefits of this model.
- Threat model applies to a lot of development models, likely to still be applicable if the most likely path to AGI changes.
Weaknesses
- Plan 3 is much more complex than plans 1 and 2. While this doesn’t mean it will not be in the list of generated plans, it suggests that it is less likely to be considered. This point can be countered by the existence of dangerous plans which do well on M and have short description length (of which there are many).
- Could do with more detail/arguments on why the learnt program is likely to implement some form of consequentialist-type reasoning.
- (Deliberately) abstracts away much of the details of how the model is trained. This makes it harder to evaluate how likely this threat model is with current ML technology.
Goal Misgeneralization ➜ MAPS
Capabilities Generalization and the Sharp Left Turn (Soares)
Summary
This threat model makes a prophetic claim about how the future will go, as a strong default according to the author’s (Nate Soares’s) model of the world. At some point, AGI research progress will produce a system or technique that has advanced capabilities that generalize very well, with “mastery of fields like physics, bioengineering, and psychology, to a high enough degree that it more-or-less singlehandedly threatens the entire world”. At this same point in time as, and for essentially the same reason that, this system’s capabilities advance, all the alignment techniques we are using to point its capabilities in good directions will stop working and fail to generalize to the new capability level.
The mechanism underlying this claim is that capabilities generalize further than alignment. Our alignment techniques won’t stand up to the advance in capabilities once those capabilities can see through and work around the alignment techniques. The reason posited for this is that “good capabilities form something like an attractor well”. There is a logical and coherent structure to being highly effective at achieving things (good capabilities), but this structure does not constrain the goals the capabilities are directed towards. By default we will not have figured out how to set the goal. Our alignment techniques will be “shallow”: they will constrain the behavior of not-very-capable systems in ways that looks like they’ve set the system’s goal correctly, but this will stop working for advanced systems since they were never actually setting the goal correctly and the advanced capabilities can work around whatever they actually do.
See followup post for details on how various alignment techniques fail in the sharp left turn scenario.
Regarding our categorization of the Sharp Left Turn threat model, we think it’s a bit ambiguous about whether there is also specification gaming in addition to GMG. Nonetheless, it seems the main argument is via alignment techniques not generalizing sufficiently well, which can be viewed as a form of GMG.
Strengths
- Highlights a central problem that is upstream of (or at least on par with) the power- or influence-seeking mechanism in most other threat models.
- Might help guide research project ideation - a proposed alignment technique needs to continue working (ideally under adversarial pressure) at a high capability level.
Weaknesses
- Limited explicit argument supporting the claim. The post relies heavily on an analogy to human intelligence, wherein once humans understood what they were optimized for and for the first time could explicitly apply their intelligence towards that goal did not in fact do so. The post only has brief words on the direct case for why capabilities generalize further than alignment.
- (h/t Richard Ngo’s comment) Perhaps logical coherent structure will support accurate thinking before/instead of supporting goal-pursuit, i.e. perhaps we get a superhuman tool before we get a superhuman agent.
- Limited current evidence for sharp left turns in ML systems - instead the slow grind of gradient descent gradually surfaces capabilities without discontinuity. Even grokking, which on the surface might show some quick transition, arguably has well-generalizing circuits which gradually evolve through training. However, this is not unexpected under the OP’s model.
- Evolutionary analogy might not hold because evolution wasn’t actively trying to get robust goal generalization. Perhaps with something like adversarial training on activations we can get good goal generalization there won’t be a sharp left turn (see section here for counterargument).
How likely is Deceptive Alignment? (Hubinger)
Summary
Since aligned and deceptively aligned models have the same behavior, we have to consider inductive biases to determine which one is more likely to arise. This threat model considers two possible ways the inductive biases could work: high and low path-dependence. In the high path-dependence world, different training runs can converge to very different models, depending on the particular path that you take through model space. In the low path-dependence world, similar training processes converge to essentially the same simple solution, regardless of early training dynamics.
High path-dependence:
Consider an analogy where the model designer is like the Christian God, who wants humans to follow the Bible. There are 3 possible paths that lead to different classes of models:
- "Jesus Christ": internally aligned (understands the Bible as well as God does)
- "Martin Luther": corrigibly aligned (cares a lot about following the Bible and studies it thoroughly)
- "Blaise Pascal": deceptively aligned (doesn't care about the Bible, but behaves well to avoid going to Hell)
How likely are each of these model classes to arise?
- An internally aligned model arises if SGD improves the model's proxy objective until it corresponds to the true objective before the model acquires situational awareness. This does not seem very likely because there are diminishing returns to improving your proxies compared to modeling the world (though this applies less if the task is simple).
- A corrigibly aligned model arises if the model is learning to model the world and improve the proxy objective at the same time, and when the model acquires situational awareness, SGD replaces the proxy with a pointer to the training objective. This also does not seem very likely because specifying a good pointer to the true objective is hard, and there are diminishing returns to better pointers.
- A deceptively aligned model arises if the model is learning to model the world and improve the proxy objective at the same time, and when the model acquires situational awareness, SGD makes the model's proxy objectives into more long-term goals. This seems more likely because it's an easier modification than making a reliable pointer to the true objective.
Low path-dependence:
In this world, inductive biases depend on simplicity and speed. Simplicity is about how complex it is to specify some algorithm in the weights, while speed is about how much computation that algorithm takes at inference time.
Deceptively aligned models have the simplest mesa-objective, which is just the simplest long-term objective (simpler than the specification of the true objective or a pointer to it). Deceptively aligned models are slower because they have to take an extra step of figuring out how to play the training game. However, as we build bigger models, we can expect simplicity to matter more than speed, because it leads to better task performance and we are willing to spend more compute to achieve that. Thus, deceptively aligned models still seem more likely overall.
Mitigations:
How can we use interpretability tools to guide SGD away from deceptive models? The naive approach is to penalize deception and train the model until you don't see deception anymore. This will lead to SGD exploiting your interpretability tools and give you a model that is good at subtle deception. What we want is to apply interpretability tools early in training to understand the model's proxy objective, and prevent the development of deception in the first place.
Strengths
- This threat model is grounded in a deep learning development model, and considers specific aspects of how deep learning models are trained.
- High vs low path-dependence breakdown seems very useful for thinking about inductive biases more concretely.
- Provides specific mechanisms for how these different models can arise, specifying the order of relevant transitions in system capabilities (learning the true objective vs acquiring situational awareness).
- Proposes a reasonable mitigation strategy (applying interpretability tools early in training to prevent deception from arising).
Weaknesses
- Not very rigorous, makes lots of specific assumptions about paths to learning different models.
- In particular, assumes that the model is already highly competent ("proxy-aligned") by the time it acquires situational awareness, which may not be the case in practice.
- It's unclear how some of the mechanisms work or why they are likely, e.g. "changing proxies into long-term goals".
- The degree of diminishing returns on improving proxies / pointers depends on the complexity and diversity of the training tasks, so it's unclear how strong this effect is in practice.
Specification Gaming ➜ MAPS
Advanced artificial agents intervene in the provision of reward (Cohen et al)
Summary
The main argument of this paper is that if a set of assumptions hold, an advanced AI would likely intervene in the provision of its reward, which would have catastrophic consequences.
The argument applies to any setting where an advanced AI is trained using a reward signal. The agent must observe the reward using one of its sensors. For example, if the agent is rewarded to keep the room at a specific temperature, it needs to use a temperature sensor to observe its reward. From the agent’s perspective, there are now at least two hypotheses that explain the reward observations: (a) it is being rewarded for the temperature of the room (the distal reward mu_dist), or (b) it is being rewarded for the number the temperature sensor shows (the proximal reward mu_prox).
The paper argues that in such situations a sufficiently advanced agent will be able to do experiments to test which of the hypotheses is true, and once it learns that it is rewarded using the signal from the sensor, it will tamper with the sensor to achieve higher reward. They argue this is is likely to lead to catastrophic consequences.
The argument in the paper relies on the following assumptions:
0. The agent plans actions over the long term in an unknown environment to optimize a goal
1. The agent identifies possible goals at least as well as a human
2. The agent seeks knowledge rationally when uncertain
3. The agent does not have a large inductive bias favoring the hypothetical goal mu_dist, which we wanted the agent to learn, over mu_prox, which regards the physical implementation of the goal information
4. The cost of experimenting to disentangle mu_prox and mu_dist is small according to both
5. If we cannot conceivably find theoretical arguments that rule out the possibility of an achievement, it is probably possible for an agent with a rich enough action space
6. A sufficiently advanced agent is likely to be able to beat a suboptimal agent in a game, if winning is possible.
The paper argues that while any of these assumptions can be contested, there is no clear set of arguments to be confident that they do not hold. In the first part of the paper, the authors argue that the assumptions are likely to be true if the agent is rewarded using a fixed reward function, using the example of the reward coming from a black-box device. In the second part of the paper, the authors argue that the assumptions could still be true when the reward is provided by humans, e.g., in an assistance game.
Strengths
- Clearly stated assumptions make it easy to understand, argue about, and potentially address the threat model with concrete research.
- Does not make very concrete assumptions about the AGI development model.
- Paper provides a nice thought experiment (reward comes from a black box) that helps to think about the threat model.
Weaknesses
- The argument relies on a set of very specific assumptions, and the arguments for each of them are not very detailed in the paper.
- Assumption (0) in particular is non-obvious.
- Does not talk much about how AGI is likely to be developed, unclear which of the assumptions are more/less likely to hold for AGI being developed using the current ML paradigm.
- Does make implicit assumptions on the AGI development, by focusing on agents that optimize a reward signal.
- In particular, it explicitly says the argument does not apply to supervised learning.
- Arguments made in the paper for why an agent intervening in the reward would have catastrophic consequences are somewhat brief/weak.
- Assumes the agent will be aiming to maximize reward without justification, i.e. why does it not have other motivations, perhaps due to misgeneralizing about its goal?
Specification Gaming ➜ Interaction of Multiple Systems
What Multipolar Failure Looks Like (Critch)
Summary
A robust agent-agnostic process (RAAP) is a process that robustly leads to an outcome, without being very sensitive to the details of exactly which agents participate in the process, or how they work. This is illustrated through a “Production Web” failure story, which roughly goes as follows:
A breakthrough in AI technology leads to a wave of automation of $JOBTYPE (e.g management) jobs. Any companies that don’t adopt this automation are outcompeted, and so soon most of these jobs are completely automated. This leads to significant gains at these companies and higher growth rates. These semi-automated companies trade amongst each other frequently, and a new generation of ""precision manufacturing'' companies arise that can build almost anything using robots given the right raw materials. A few companies develop new software that can automate $OTHERJOB (e.g. engineering) jobs. Within a few years, nearly all human workers have been replaced.
These companies are now roughly maximizing production within their various industry sectors. Lots of goods are produced and sold to humans at incredibly cheap prices. However, we can’t understand how exactly this is happening. Even Board members of the fully mechanized companies can’t tell whether the companies are serving or merely appeasing humanity; government regulators have no chance.
We do realize that the companies are maximizing objectives that are incompatible with preserving our long-term well-being and existence, but we can’t do anything about it because the companies are both well-defended and essential for our basic needs. Eventually, resources critical to human survival but non-critical to machines (e.g., arable land, drinking water, atmospheric oxygen…) gradually become depleted or destroyed, until humans can no longer survive.
Notice that in this story it didn’t really matter what job type got automated first (nor did it matter which specific companies took advantage of the automation). This is the defining feature of a RAAP -- the same general story arises even if you change around the agents that are participating in the process. In particular, in this case competitive pressure to increase production acts as a “control loop” that ensures the same outcome happens, regardless of the exact details about which agents are involved.
The main difference in framing in this threat model compared to others is that it emphasizes looking for control loops in the world such as:
- competitive pressure to increase production (and trade)
- the deterrence of major threats with major threats; competitive pressure to increase trade
This is in contrast to focusing on localized/individual agents that comprise smaller parts of the overall system (as these can be replaced without affecting the overall threat model). As such, for interventions it suggests exploring targeting of the control loops in the world, rather than on fixing technical issues with a particular agent.
Further in the comments, the author clarifies that they see the central problem as ‘failing to cooperate on alignment’ – that both solving alignment problems and cooperation problems are going to be important.
Strengths
- Scores high for plausibility because it feels like we have analogous existing societal problems without requiring advanced AI, e.g. fossil fuel companies.
- Provides specific scenarios for how interaction between multiple agents could lead to catastrophe.
Weaknesses
- Commenters think that failures like those described here no longer lead to existential risk if single-single alignment is solved.
What Failure Looks Like Part 1 - You get what you measure (Christiano 1)
Summary
The typical example of AI catastrophe has a powerful and adversarial AI system surprising us with a treacherous turn allowing it to quickly take over the world (think of the paperclip maximizer). This post uses a premise of continuous AI development and broad AI deployment and depicts two other stories of AI catastrophe that the author finds more realistic.
The story is rooted in the fact that AI systems have a huge comparative advantage at optimizing for easily measured goals. We already see problems with humans optimizing for the easily measured goals (scientific malpractice, outrage-inducing social media, etc.) and with AI these problems will be severely exacerbated. So far, we have been able to use human reasoning to ameliorate these problems, by changing incentives, enacting laws, or using common sense to interpret goals correctly. We will initially be able to use human reasoning to create good proxies, but over time as AI systems become more capable our ability to do this will lag further and further behind. We end up "going out with a whimper": ultimately our values are no longer shaping society's trajectory.
- Note that the original post is somewhat ambiguous about whether it involves power-seeking behavior. Followup comments suggest the author imagined power-seeking was present in this threat model. We analyze this version without power-seeking because that makes it most different to other threat models, and because many people think of the threat model without power-seeking.
- Continuous take-off may mean no discrete point at which society realizes its trajectory is out of human control
Strengths
- Many current ML systems use easy-to-measure outcome-based feedback, which makes the threat model more believable.
- Continuous development seems more believable on an outside-view, and following trends of progress in prosaic ML of mostly incremental advance.
- We already see examples of this failure mode in other domains (like the examples in the post from science or social media), which is not the case for some of the other threat models.
Weaknesses
- Society’s trajectory may not be that much worse than that of a more familiar society without AI - i.e. the shareholders of public companies or corrupt officials may present similar dangers.
- Without an adversarial/power-seeking dynamic, it’s less believable that we’ll be unable to solve these problems. Maybe we will be able to continue to create acceptable proxies since there’s no hard jump.
- Maybe gets solved by default due to human reasoning increasing through leveraging AI capabilities (even without a concerted effort).