Tl;dr
In this post, I will introduce two conceptual tools I found useful when thinking about (or introducing people to) AI alignment. Namely, I introduce the distinction between Maps and Blueprints (part 1), describe (what I call) the Two Sides of the “Alignment Equation” (part 2), and discuss how all these things relate to each other (part 3).
Part 1: Map and Blueprint
Most people reading this will already be familiar with the Map–Territory distinction. In this metaphor, the territory represents reality and the map represents your current best understanding of reality. The corollaries: “the map is not the territory”; “maps are never true, but they can be more or less useful”, etc.
I want to introduce one more idea into this picture: the blueprint. If the map is what we construct from investigating the word, a blueprint is what allows us to render a (new) bit of territory (e.g., building some artefact). Roughly speaking, map-making is closer to what science is trying to do, while blueprint-making is closer to what engineering is about.
While maps are causally posterior to the territory (they are drawn based on what we know about existing territory by looking at it), blueprints are causally prior (they are used to create new bits of territory). In other words, the red arrows in the diagram below depict the authorial relationship between these concepts.
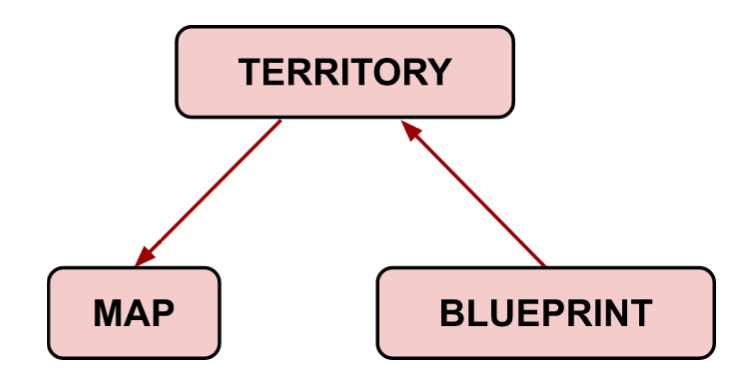
Figure 1: The relationship between territory, maps, and blueprints; arrows represent an authorial relationship.
(There is an interesting question as to what sort of epistemic object blueprints are (e.g., compared to maps). For those curious, I can recommend Herbert Simon’s "The Sciences of the Artificial" which discusses how (if at all) we can make "the artificial"/design/blueprints our subject of study.
Part 2: Two sides of the “Alignment Equation”
Here is a simple model that intends to capture the basic structure of the AI alignment problem. I will call it the “Alignment Equation”:
Let us assume there are two (intelligent) agents that stand in relationship R to one another. Ri can take different shapes, among which is Raligned, which is a relationship that guarantees alignment between the two agents. Let us name our two agents O and S, referring to the object and subject of this alignment endeavour, respectively. Specifically, we're trying to align O with S, i.e., Raligned, O→S.

Figure 2: The “alignment equation”, with the object of alignment on one side and the subject of alignment on the other.
In other words, when we talk about AI alignment, we talk about how we want one agent—in this case, the AI system(s), i.e., the object of alignment—to stand in a particular relationship to the subject of alignment (e.g., human intents, human values, etc.)—namely, an aligned relationship.
Of course, this wee toy model fails to capture a lot of relevant nuance. And yet, it lets us point at and talk about some critical subparts of the problem in fairly simple terms. For example:
1. Finding the right specification for O and S
In the toy model, O and S are placeholders. For example, O might represent a single centralised AI system, or multiple centralised AI systems, or a distributed network of AI services, etc. S might represent the intents or preferences of an individual human, or the (~aggregate) values of a collective of humans, or of sentient beings more generally, or something else yet. Finding the right ways to fill in the placeholders matters, and is itself subject to disagreement and study.
2. Finding mechanisms that can shape R
Different mechanisms can define or shape the relationship R. We can understand work on AI alignment as exploring what different mechanisms we have at hand and how to apply them to shape R into Raligned.
Following Simon Herbert in “The Sciences of the Artificial”, it might be most relevant to think of R as downstream of or contingent on the design of O. I.e. the nature of R is not (necessarily) a separately-existing thing in the world that we can manipulate directly, but a consequence of design choices for O. Depending on how broad or narrow one wants to understand the tasks of “designing O”, this may or may not capture the entirety of the option space. For example, in so far as one expects governance interventions located “outside of” O to help with alignment, one would want to say that there are mechanisms available for shaping that are separate from the design of O. Since, however, such governance interventions would have to be finely tuned to the functioning of O, it may as well seem conceptually appropriate to consider it as part of the design space of O.
3. What do we mean by "aligned"?
So far when discussing the toy model, I have been liberally talking about alignment as if there was no question to what it means for a thing to be "aligned" to another. That is, of course, not the case.
In this toy model proper, "alignment" merely refers to a specific way the behaviour of one element relates to the behaviour of the other. This degree of abstraction is of course insufficient when aiming to make progress on AI alignment proper. Yet, the purpose of the toy model is not to answer the question, but to draw attention to and allow us to talk about (uncover disagreements about, etc.) the elements of the toy model. For example, some might argue Raligned means that S controls O, or that O holds an intention of truthfulness or assistance/sevitude towards S, etc.
Part 3: Putting things together
Now, what do maps, territories, and the alignment equation have to do with each other?
In short, we use blueprints for the part of the alignment problem that is about designing the artefacts (i.e., AI systems) in a certain way (i.e., in a way that guarantees they are safe and aligned). And we require maps in order to be able to correctly characterise the subject of alignment, i.e., the target behaviour of the alignment problem. This initial take is of course too simplistic; for example, creating blueprints that robustly lead to a faithful rendering of the desired artefact require good maps (see dotted arrow).
In terms of the four different epistemic artefacts introduced in this post, artefacts 1–3 (de-confusion and gears-level models of key phenomena, characterising target behaviour, and characterising risk scenarios) mainly involve making maps, while artefact 4 (alignment proposals) is equivalent to drawing reliable blueprints.
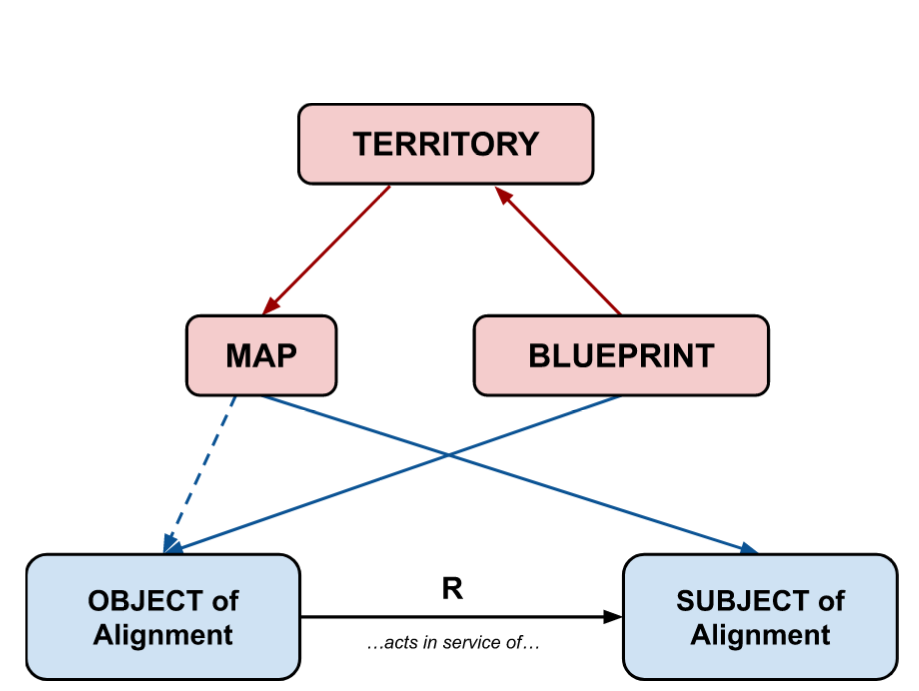
Figure 3: Using maps and/or blueprints for specifying the object and subject of alignment.
Despite its simplicity, and without wanting to claim it can do more than it actually does, I find this simple toy model surprisingly useful. For example, I have found it quite useful when first introducing the basic structure of the alignment problem to people who are fairly new to the problem (and then problematise this simple picture over time). It makes it easier to be clear about why we are interested in understanding agency, both in terms of real-world agents as well as idealised agents. When thinking about advanced AI systems (i.e., “objects of alignment”), it is plausible that we should treat them as (fairly) idealised agents. However, when thinking about the subject of alignment (i.e., when trying to characterise target behaviour), assumptions of idealised agency or rationality fall short, and we instead need more realistic map-making.
Summary
- “Maps” represent our current best understanding of the territory (aka., reality); “blueprints” are what we use to design new artefacts (that then become part of the territory).
- The “Alignment Equation” is a toy model of the alignment problem, cashing it out in terms of an object of alignment (O) and a subject of alignment (S), which we want to bring into relationship Raligned to each other.
- Solving the alignment problem requires both map-making and blueprint drawing. To simplify a bit, map-making is required for characterising the S as well as the environment in which O operates (thereby defining the observed behaviour of O’s functioning). Blueprint making, on the other hand, is required for designing O, and by extension, for shaping R.
Thanks to TJ/particlemania for sharing the notion of "blueprints" with me; and to Refine fellows for giving feedback on an early iteration of this toy model.