(Last revised: July 2024. See changelog at the bottom.)
1.1 Post summary / Table of contents
This is the first of a series of blog posts on the technical safety problem for hypothetical future brain-like Artificial General Intelligence (AGI) systems. So my immediate priority here is saying what the heck is “the technical safety problem for brain-like AGI” and what do those words even mean and why on earth should I care.
Summary of this first post:
- In Section 1.2, I define the “AGI technical safety problem”, put it in the context of other types of safety research (e.g. inventing passively-safe nuclear power plant designs), and relate it to the bigger picture of what it will take for AGI to realize its potential benefits to humanity.
- In Section 1.3, I define “brain-like AGI” as algorithms with big-picture similarity to key ingredients of human intelligence, presumably (though not necessarily) as a result of future people reverse-engineering those aspects of the human brain. What exactly that means will be clearer in future posts. I will also bring up the counterintuitive idea that “brain-like AGI” can (and probably will) have radically nonhuman motivations. I won’t explain that here, but I’ll finish that story by the end of Post #3.
- In Section 1.4, I define the term “AGI”, as I’m using it in this series.
- In Section 1.5, I discuss the probability that people will eventually make brain-like AGIs, as opposed to some other kind of AGI (or just not invent AGI at all). The section includes seven popular opinions on this topic, from both neuroscientists and AI / machine learning experts, and my responses.
- In Section 1.6, I’ll address AGI accidents, which is something we should expect if we don’t solve the AGI technical safety problem. I’ll argue that these kinds of accidents can be catastrophic indeed, including human extinction. This topic is a minefield of confusion and miscommunication, and I will frame my discussion around responses to eight common objections.
- In Section 1.7, I’ll address the more specific question of why we should think about AGI safety right now. After all, there is a prima facie good case for waiting, namely: (1) AGI doesn’t exist yet, (2) AGI will exist someday in the future, and (3) it will be easier to do AGI safety research when we know more about the AGI, and easier still when we actually have AGI code that we can run tests on. There is indeed something to that argument, but I’ll argue that there is nevertheless a lot of safety work that can and must be done ASAP.
- In Section 1.8, I’ll suggest that brain-like-AGI safety is a fun, fascinating, and fruitful topic, even if you don’t buy the idea that it’s important for the future.
1.2 The AGI technical safety problem
AGI is short for “Artificial General Intelligence”—I’ll get back to the definition of AGI in Section 1.4 below. AGI doesn’t exist right now, but I’ll argue in Section 1.7 that we can and should be preparing for AGI even today.
The part I’ll be talking about in this series is the red box here:
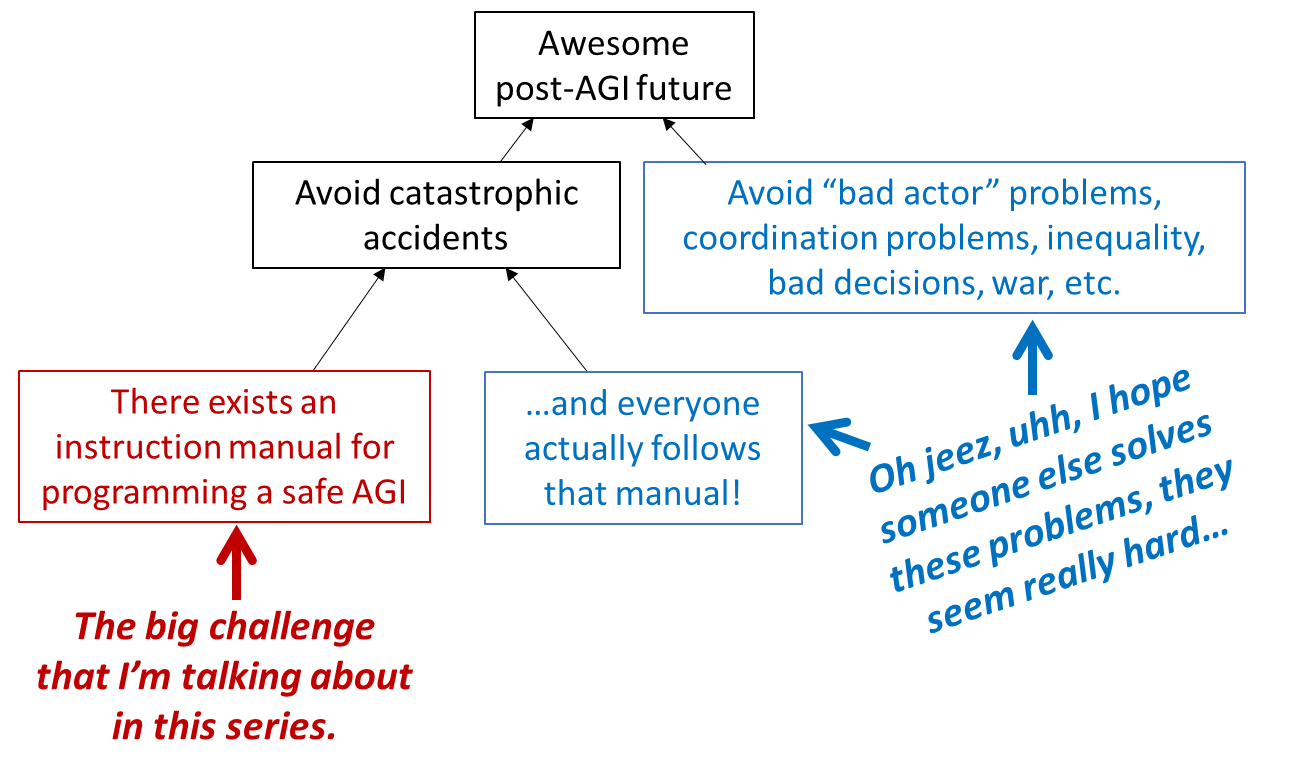
Specifically, we zoom in on a single team of humans who are trying to create a single AGI, and we want it to be possible for them to do so without winding up with some catastrophe that nobody wanted, with an out-of-control AGI self-replicating around the internet or whatever (more on which in Section 1.6).
Blue boxes in this diagram are things that I won’t talk about in this series. It’s long enough already. But I very strongly endorse other people working on them, and think about them myself as well.
Back to the red box. This is a technical problem, calling for a technical solution. Nobody wants catastrophic accidents. And yet!! Indeed, it’s entirely possible for people to write an algorithm that does something that nobody wanted it to do. It happens all the time! We might call it “a bug” when it’s a local problem in the code, and we might call it “a fundamentally flawed software design” when it’s a global problem. I’ll argue later in the series that AGI code may be unusually prone to catastrophic accidents, and that the stakes are very high (see Section 1.6 below, and Post #10).
Here’s an analogy. If you’re building a nuclear power plant, nobody wants an out-of-control chain reaction. The people at Chernobyl certainly didn’t! But it happened anyway! I take a few lessons from this analogy:
- Enrico Fermi invented a technical solution for controlling nuclear chain reactions—control rods—before starting to build the first-ever nuclear chain reaction. Right on!! That’s doing things in the right order! By the same token, I suggest that we should strive to have a technical solution to avoiding catastrophic AGI accidents ready to go before people start programming AGIs. In fact, I’ll argue below for something even stronger than that: knowing the solution (even vaguely) 10 years before AGI is even better; 20 years before AGI is better still; etc. This claim is not obvious, but I’ll get back to it (Section 1.7).
- Technical solutions aren’t all-or-nothing. Some reduce the chance of accidents without eliminating them. Some are complicated and expensive and error-prone to implement. In the nuclear case, control rods reduce accident risk a lot, but passively-safe reactors reduce it even further. By the same token, I expect that technical AGI safety will be a rich field, where we’ll develop better and better approaches over time, involving multiple techniques and multiple layers of protection. At least, I hope! As I’ll discuss later in the series, I claim that right now we have no solution at all—not even vaguely. We have our work cut out!
- The blue boxes (see diagram above) also exist, and are absolutely essential, even if they’re out-of-scope for this particular series of articles. The cause of the Chernobyl accident was not that nobody knew how to keep a nuclear chain reaction under control, but rather because best practices were not followed. In that case, all bets are off! Still, although we on the technical side can’t solve this noncompliance problem by ourselves, we can help on the margin, by developing best practices that are maximally idiot-proof, and minimally expensive.

1.3 Brain-like AGI
1.3.1 Overview
This series will focus on a particular scenario for what AGI algorithms will look like:

The red box is what I’ll talk about here. The blue boxes are things that are out-of-scope for this series.
You may have opinions about which of these categories is more or less likely, or impossible, or whether this breakdown is even sensible. I have opinions about those things too! I’ll discuss them later (Section 1.5). My main opinion is that all three of these are sufficiently likely that we should be “contingency planning” for them. So while I personally don’t do too much work on the blue boxes, I’m sure glad that other people do!
Here’s an analogy. If someone in 1870 were guessing what future human flight would look like…
- “Kinda like birds” would have been a reasonable guess…
- “Kinda like today’s best airships” would also have been a reasonable guess…
- “Neither of the above” would have been a reasonable guess too!!
In this particular imaginary case, all three of those guesses would have turned out correct in some ways and wrong in other ways: The Wright Brothers were directly and extensively inspired by large soaring birds, but left out the wing-flapping part. They also used some components found on airships (e.g. propellers), as well as plenty of original ingredients. That’s just one example, but I think it’s suggestive.
1.3.2 What exactly is “brain-like AGI”?
When I say “brain-like AGI”, I have a particular thing in mind. This thing will become much clearer in the subsequent posts, after we’ve started diving into neuroscience. But here’s what I'm going for in broad strokes.
There are ingredients in the human brain and its environment that lead to humans having general intelligence (i.e., common sense, ability to figure things out, etc.—see Section 1.4 below). The scenario I have in mind is: Researchers will write AI code using similar algorithmic ingredients—either because they reverse-engineered tricks that the brain uses, or because they independently reinvented those same tricks, I don’t care which—and that code will be able to do the same kinds of intelligent things that humans can do, for the same underlying reasons.
To clarify:
- I don’t expect that “brain-like AGI” will include every part of the brain and its environment. For example, there are highly-intelligent people who were born without a sense of smell, which suggests that brain olfactory processing circuitry probably isn't essential for AGI. There are highly-intelligent people who were quadriplegic from birth, suggesting that lots of spinal-cord circuitry and (certain aspects of) "embodiment" aren't essential either. There are likewise people born without a cerebellum who are nevertheless well within the range of normal adult human intelligence (able to hold down a job, live independently, etc.—the kinds of capabilities that we would unhesitatingly call “AGI”). Other adults are holding down jobs while missing an entire brain hemisphere, etc. My default expectation is that AGI will be created by people trying to create AGI, and they'll leave out whatever components they can, to make their jobs easier. (I’m not endorsing that as necessarily a good idea, just saying what I expect by default. More on this in Post #3.)
- In particular, the kind of “brain-like AGI” I’m talking about is definitely not the same as Whole Brain Emulation.
- I don’t require that “brain-like AGI” will resemble the human brain in low-level details, like with spiking neurons, dendrites, etc., or direct simulations thereof. If the resemblance is only at a higher level of abstraction, that’s fine, it won’t affect anything here.
- I don’t require that “brain-like AGI” will be designed in a way that resembles how the brain was designed, i.e. evolutionary search. Quite the contrary: My working assumption is that it will be designed by humans in a way that’s akin to a typical machine learning project today: lots of human-written code (loosely analogous to the genome), a subset of which defines the inference and update rules of one or more learning algorithms (corresponding to the brain’s within-lifetime learning algorithms). There may be a few blank spaces in the code that get filled in by hyperparameter search or neural architecture search etc. Then you run the code, and the learning algorithms gradually build up a big complicated trained model from experience, maybe with trillions of adjustable parameters. Much more on this stuff in the next two posts and Post #8.
- I don’t require that “brain-like AGI” will be conscious (in the phenomenal sense). There are ethical reasons to care about whether AGI is conscious (more on which in Post #12), but nothing I say in this series will depend on whether or not the AGI is conscious. Machine consciousness is a big contentious topic and I just don’t want to get into it here. (I’ve written about it a bit elsewhere.)
Maybe a more practical way of saying it is: I’m going to make a bunch of claims about the algorithms underlying human intelligence, and then talk about safely using algorithms with those properties. If our future AGI algorithms have those properties, then this series will be useful, and I would be inclined to call such an algorithm “brain-like”. We’ll see exactly what those algorithm properties are, going forward.
1.3.3 “Brain-like AGI” (by my definition) can (and quite possibly will) have radically nonhuman motivations
I’m going to talk about this a lot more in later articles, but this is such an important point that I want to bring it up immediately.
Yes I know it sounds weird.
Yes I know you think I’m nuts.
But please, I beg you, hear me out first. By the time we get to Post #3, Section 3.5, well then you can decide whether or not to believe me.
In fact, I’ll go further. I’ll argue that “radically nonhuman motivations” is not just possible for a brain-like AGI, but is my baseline expectation for a brain-like AGI. I’ll argue that this is generally a bad thing, and that we should consider prioritizing certain lines of R&D in a proactive effort to avoid that.
(To be clear, “radically nonhuman motivations” is not synonymous with “scary and dangerous motivations”. Unfortunately, “scary and dangerous motivations” is also my baseline expectation for a brain-like AGI!! But that requires a further argument, and you’ll have to wait until Post #10 for that one.)
1.4 What exactly is “AGI”?
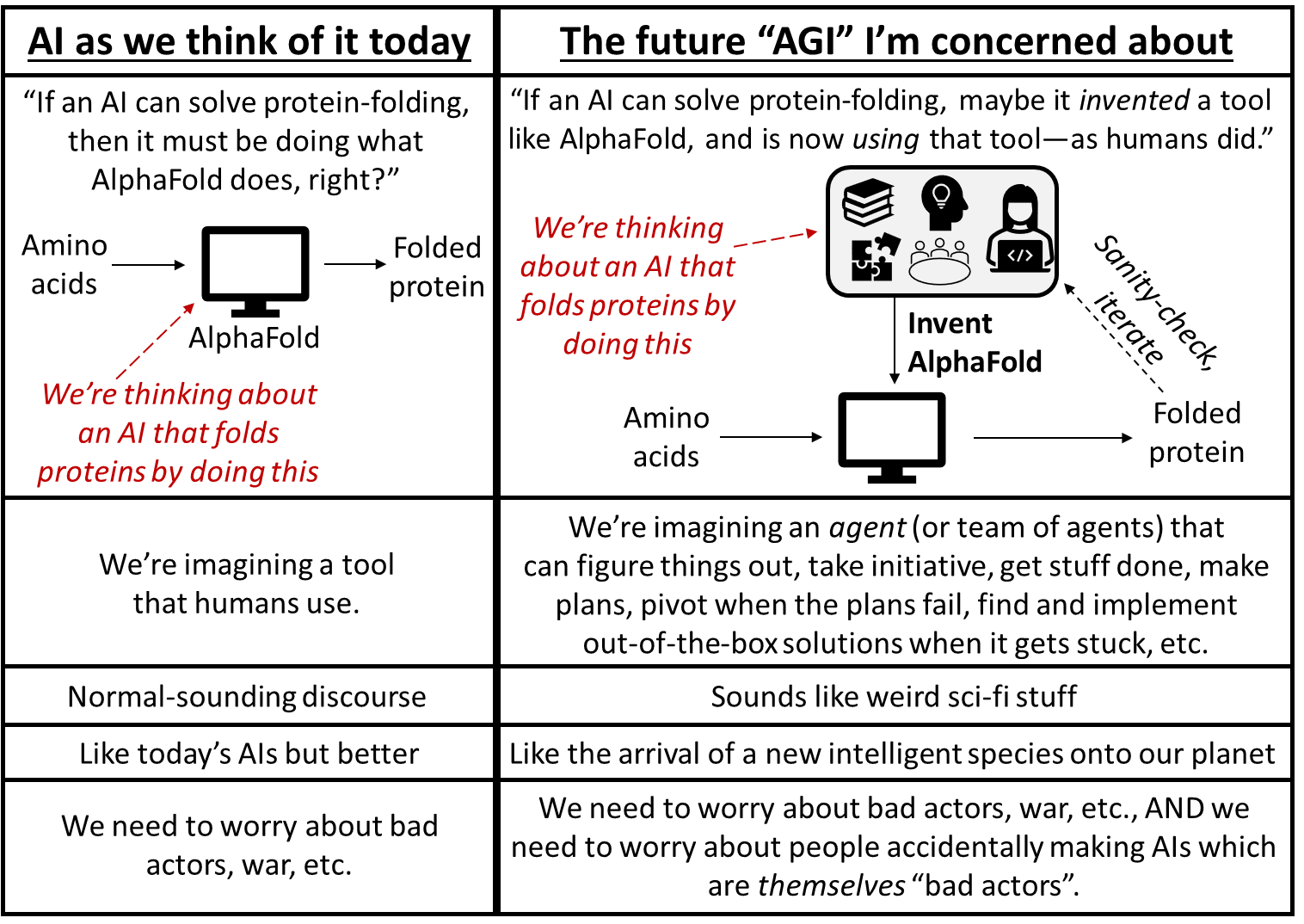
A frequent point of confusion is the word “General” in “Artificial General Intelligence”:
- The word “General” DOES mean “not specific”, as in “In general, Boston is a nice place to live.”
- The word “General” DOES NOT mean “universal”, as in “I have a general proof of the math theorem.”
An AGI is not “general” in the latter sense. It is not a thing that can instantly find every pattern and solve every problem. Humans can’t do that either! In fact, no algorithm can, because that’s fundamentally impossible. Instead, an AGI is a thing that, when faced with a difficult problem, might be able to solve the problem easily, but if not, maybe it can build a tool to solve the problem, or it can find a clever way to avoid the problem altogether, etc.
Consider: Humans wanted to go to the moon, and then they figured out how to do so, by inventing extraordinarily complicated science and engineering and infrastructure and machines. Humans don’t have a specific evolved capacity to go to the moon, akin to birds’ specific evolved capacity to build nests. But they got it done anyway, using their “general” ability to figure things out and get things done.
So for our purposes here, think of AGI as an algorithm which can “figure things out” and “understand what’s going on” and “get things done”, including using language and science and technology, in a way that’s reminiscent of how most adult humans (and groups and societies of humans) can do those things, but toddlers and chimpanzees and today’s large language models (LLMs) can’t. Of course, AGI algorithms may well be subhuman in some respects and superhuman in other respects.

Anyway, this series is about brain-like algorithms. These algorithms are by definition capable of doing absolutely every intelligent behavior that humans (and groups and societies of humans) can do, and potentially much more. So they can definitely reach AGI. Whereas today’s AI algorithms are not AGI. So somewhere in between here and there, there’s a fuzzy line that separates “AGI” from “not AGI”. Where exactly is that line? My answer: I don’t know, and I don’t care. Drawing that line has never come up for me as a useful thing to do. It won’t come up in this series either.
1.5 What’s the probability that we’ll eventually wind up with brain-like AGI?
Above (Section 1.3.1) I suggested three categories of AGI algorithms: “brain-like” (as defined just above), “prosaic” (i.e. like today’s most impressive deep neural net ML algorithms), and “other”.
If our attitude is “Yes, let's do safety research for all three possibilities, just in case!!”—as I claim it should be—then I guess it’s not all that decision-relevant what probability weights we put on each of the three things.
But even if it’s irrelevant, it’s fun to talk about, so what the heck, I’ll just quickly summarize and respond to some popular opinions I’ve heard on this topic.
Opinion #1: "I dispute the premise: human brains work by basically the same principles as today’s popular ML algorithms.”
- The thing is, “today’s popular ML algorithms” is a big tent including lots of different algorithms.
- As one example, I see hardly any overlap between “Large-Language-Model (LLM)-like-AGI safety” and “brain-like-AGI safety” (see my discussion in Section 4.2 here for some of the safety-relevant differences between LLMs and brain algorithms)
- On the opposite extreme, I see substantial overlap between “actor-critic model-based RL AGI safety” and “brain-like-AGI safety”. More explicitly: “actor-critic model-based RL algorithms” is a broad category including many different known algorithms, and even more algorithms yet to be invented; but if future AGI winds up being any kind of actor-critic model-based RL, I expect this series to be at least a little bit relevant and helpful.
- Anyway, by assuming “brain-like AGI”, I get the right to make certain assumptions about the cognitive architecture, representations, learning algorithms, and so on.
- Some of these “brain-like AGI ingredients” are universal parts of today’s popular ML algorithms (e.g. learning algorithms; distributed representations).
- Others of these “brain-like AGI ingredients” are (individually) present in a subset of today’s popular ML algorithms but absent from others (e.g. reinforcement learning; predictive [a.k.a. self-supervised] learning; explicit planning).
- Still others of these “brain-like AGI ingredients” seem mostly or totally absent from today’s most popular ML algorithms (e.g. ability to form “thoughts” [e.g. “I’m going to the store”] that blend together immediate actions, short-term predictions, long-term predictions, and flexible hierarchical plans, inside a generative world-model that supports causal and counterfactual and metacognitive reasoning).
- So in this sense, “brain-like AGI” is a specific thing that might or might not happen, independently of “prosaic AGI”. Much more on “brain-like AGI”, or at least its safety-relevant aspects, in the subsequent posts.
Opinion #2: “Brain-like AGI is possible but Prosaic AGI is not. It just ain’t gonna happen. Today's ML research is not a path to AGI, just as climbing a tree is not a path to the moon.”
- I find this to be a moderately popular opinion among neuroscientists and cognitive psychologists. Prominent advocates of this view include Gary Marcus and Melanie Mitchell.
- One question is: if we take one of today’s most popular ML models, add no additional significant insights or architectural changes whatsoever, and just scale the model to ever larger sizes, do we get AGI? I join those neuroscientists in expecting the answer to be “probably not”.
- On the other hand, even if it turns out that deep neural networks can't do important-for-intelligence things X and Y and Z, well c’mon, somebody's probably just gonna glue together a deep neural network with other components that do X and Y and Z. And then we can have some pointless semantic debate about whether it's still “really” prosaic AGI or not.
- Anyway, in this series, I will be assuming that AGI will have certain algorithmic features (e.g. online learning, a certain type of model-based planning, etc.—much more in later posts). I’ll be assuming that because (1) those features are part of human intelligence, (2) they seem to be there for a good reason. My safety-related discussions will rely on those features being present. Can algorithms with these features be implemented in PyTorch on a GPU? Well, I don’t really care.
Opinion #3: “Prosaic AGI is going to happen so soon that no other research program has a chance.”
- A subset of people in ML believe this. I don’t. Or at any rate, I would be awfully surprised.
- I do agree that IF prosaic AGI is, say, 5 years away, then we almost certainly don’t need to think about brain-like AGI or indeed any other research program. I just think that’s an awfully big “if”.
- I find this incredibly annoying, but in the past couple years there has been an increasingly widespread insane nonsensical misconception that the proposition “Large Language Models (LLMs) will scale to AGI within the next couple years and then kill everyone” is the only possible scenario in which we should be raising alarms right now about AGI extinction risk—as if the possibility of a non-LLM AGI killing everyone in 2045 is perfectly fine and normal?! See my post AI doom from an LLM-plateau-ist perspective for more on that topic, and more on when to expect brain-like AGI in the next two posts, and why to prepare way ahead of time in Section 1.7 below.
Opinion #4: “Brains are SO complicated—and we understand them SO little after SO much effort—that there’s just no way we’ll get brain-like AGI even in the next 100 years.”
- This is a pretty popular opinion, both inside and outside of neuroscience. I think it’s very wrong, and will be arguing against it at length in the next two posts of the series.
Opinion #5: “Neuroscientists aren’t trying to invent AGI, so we shouldn’t expect them to succeed.”
- There’s some truth to this, but I mostly disagree. For one thing, a number of leading computational neuroscientists (Dileep George and other neuroscientists at DeepMind, Randall O’Reilly, Jeff Hawkins) are in fact explicitly trying to invent AGI. For another thing, people in AI, including prominent leaders of the field, try to keep up with the neuroscience literature and incorporate its ideas. And anyway, “understanding an AGI-relevant brain algorithm” is part of inventing brain-like AGI, whether or not that’s the intention of the person carrying out the research.
Opinion #6: “Brain-like AGI is kinda an incoherent concept; intelligence requires embodiment, not just a brain in a vat (or on a chip).”
- The “embodiment” debate in neuroscience continues to rage. I fall somewhere in the middle. I do think that future AGIs will have some action space—e.g., the ability to (virtually) summon a particular book and open it to a particular passage. I don’t think having a whole literal body is important—for example Christopher Nolan (1965-2009) had lifelong quadriplegia, but it didn’t prevent him from being an acclaimed author and poet. More importantly, I expect that whatever aspects of embodiment are important for intelligence could be easily incorporated into a brain-like AGI running on a silicon chip. Is a body necessary for intelligence after all? OK sure, we can give the AGI a virtual body in a VR world—or even a real robot body in the real world!! Are hormonal signals necessary for intelligence? OK sure, we can code up some virtual hormonal signals. Etc.
Opinion #7: “Brain-like AGI is incompatible with conventional silicon chips; it requires a whole new hardware platform based on spiking neurons, active dendrites, etc. Neurons are just plain better at computation than silicon chips are—just look at their energy efficiency etc.”
- I’m really unsympathetic to this position. Conventional silicon chips can definitely simulate biological neurons—neuroscientists do this all the time. Conventional silicon chips can also presumably implement “brain-like algorithms” using different low-level operations more suited to that hardware, just as the same C code can be compiled to different CPU instruction sets. As for “neurons are just plain better”, I freely acknowledge the human brain does a crazy impressive amount of computation given its tiny volume, mass, and power consumption. But those are not hard constraints! If a silicon-chip AGI server were literally 10,000× the volume, 10,000× the mass, and 1000× the power consumption of a human brain, with comparable performance, I don’t think anyone would be particularly bothered—in particular, its electricity costs would still be well below my local minimum wage!! And my best estimate is that buying enough silicon chips for human-brain-human-lifetime-level computation is probably easily feasible, or will be in the next decade, even for small companies or even individuals. The key reason that small companies aren’t building AGIs today is that we don’t know the right algorithms.
This is just a quick run-through; each of these opinions could be a whole article—heck, a whole book. For my part, I put >>50% probability that we’ll have a sufficiently-brain-like AGI that this series will be very relevant. But who knows, really.
1.6 Why are AGI accidents such a big deal?
Two reasons: (1) the stakes are high, and (2) the problem is hard. I’ll be talking about (2) much more later in the series (Posts #10–#11). Let’s talk about (1).
And let's talk more specifically about one high-stakes possibility: the risk of human extinction. That sounds a bit wild but hear me out.
I’ll frame this discussion as answers to popular objections:
Objection #1: The only way that an out-of-control AGI could result in human extinction is if the AGI invents crazy sci-fi superweapons, e.g. gray goo. As if such a thing is even possible!
Oh, if only that were true! But alas, I don’t think sci-fi superweapons are necessary. In fact, it seems to me that it’s maybe borderline possible for a human intelligence using existing technology to cause human extinction!
Think about it: it’s already at least borderline-possible today for an ambitious intelligent charismatic methodical human to arrange for the manufacture and release of a novel contagious disease that’s 100× deadlier than COVID-19. Heck, it’s probably possible to release 30 such plagues all at once! Meanwhile, I figure it’s at least borderline-possible today for an ambitious intelligent charismatic methodical human to find a way to manipulate nuclear early warning systems (trick them, hack into them, bribe or threaten their operators, etc.), setting off an all-out nuclear war, killing billions of people and sowing chaos around the world. Those are just two things; creative readers will immediately think of lots more. I mean seriously, there are fiction books with totally plausible mad-scientist apocalypse scenarios—not just according to me, but according to domain experts.
Now, granted, human extinction seems like a high bar! People live in all kinds of places, including small tropical islands that would be insulated from both nuclear winter and plagues. But this is where we get a big difference between an intelligent agent like an AGI, versus an unintelligent agent like a virus. Both can self-replicate. Both can kill lots of people. But an AGI, unlike a virus, can take command of military drones, and mow down the survivors!!
So my hunch is that we’re all still around today thanks in large part to the fact that all the most ambitious intelligent charismatic methodical humans aren’t trying to kill everyone—and not because “killing everyone” is a thing that requires crazy sci-fi superweapons.
As discussed above, one of the failure modes I have in mind would involve out-of-control AGIs that combine (at least) human-like intelligence with radically nonhuman motivations. This would be a new situation for the world, and I don’t find it comforting!
You might reply: The thing that went wrong in this scenario is not the out-of-control AGI, it’s the fact that humanity is too vulnerable! And my response is: Why can’t it be both? So in my book: Yes we should absolutely make humanity more robust to bio-engineered pandemics, and reduce the chances of nuclear war, etc. All these things are great ideas that I strongly endorse, and godspeed if you yourself are working on them. But at the same time, we should also work really hard to not create out-of-control self-replicating human-like intelligences with radically nonhuman motivations!
…Oh and one more thing: Maybe “crazy sci-fi superweapons like gray goo” are possible too! Beats me! If so, we need to be even more cautious!
Objection #2: The only way that an AGI accident could result in human extinction is if the AGI is somehow smarter than all humans combined.
The issue here is that “all humans combined” may not know that they are engaged in a battle against an AGI. Maybe they would, maybe they wouldn’t. For example, who would win in a battle between Joseph Stalin on one side, and “all other Russians combined” on the other side? Obviously Stalin would be crushed. And yet, Stalin wound up with totalitarian control over Russia. Similarly, as described here, when Cortés landed in Yucatan, his men were outnumbered 5000-to-1 by the native population, yet Cortés wound up with hegemonic control. In both cases, humans deployed strategy, charisma, deception, propaganda, treachery, and so on. And future AGIs will be able to deploy all those things too.
Objection #3: The only way that an AGI accident could result in human extinction is if the AGI is deliberately given access to levers of power, like nuclear codes, control over social media, etc. By the same token, we can run the AGI code on just one server, and then switch it off if anything goes wrong.
The problem here is that intelligent agents can turn “few resources” into “lots of resources”. Think of Warren Buffett, or Adolf Hitler.
Intelligent agents can earn money (whether legally or not), and they can earn trust (whether deserved or not), and they can get access to other computers (whether by purchasing server time or by hacking). The latter is especially important because an AGI—like a virus, but not like a human—can potentially self-replicate. Self-replication is one way it can protect itself from shutdown, if it’s motivated to do so. Another way is by tricking / misleading / winning over / bribing / outsmarting whoever controls the shutdown switch.
(A kernel of truth here is that if we’re unsure of an AGI’s motivations and competence, then giving it access to the nuclear codes is a very bad idea! Trying to limit an AGI’s power and resources doesn’t seem to be a solution to any of the hardest problems that we’re interested in here, but it can still be helpful on the margin, like as an "additional layer of protection". So I'm all for it.)
Objection #4: The good AGIs can stop the bad out-of-control AGIs.
For one thing, if we don’t solve the technical problem of how to steer an AGI’s motivation and keep it under control (see Posts #10–#15), then there may be a period of time when there are no good AGIs! Instead, all the AGIs are out-of-control!
For another thing, out-of-control AGIs will have asymmetric advantages over good AGIs—like the ability to steal resources, to manipulate people and institutions via lying and disinformation; to cause wars, pandemics, blackouts, famines, gray goo, and so on; and to not have to deal with coordination challenges across different (human) actors with different beliefs and goals. More on this topic here.
Objection #5: An AGI that’s trying to kill everyone is a really specific kind of failure mode! There's just no reason that an AGI would try to do that. It's not the kind of thing that would happen as a general result of buggy or poorly-designed AGI software. It's the kind of thing that would only happen if somebody went out of their way to put malign motivations into the AGI. As a matter of fact, buggy or poorly-designed software tends to do, well, nothing in particular! I happen to know a thing or two about buggy software—in fact I just created some this morning. The only thing it murdered was my self-confidence!
A kernel of truth here is that some bugs or design flaws in AGI code will indeed manifest as software that is not an AGI, and not “intelligent”, and probably not even functional! Such errors do not qualify as catastrophic accidents, unless we were foolish enough to put that software in charge of the nuclear arsenal. (See "Objection #3" above.)
However, I claim that other bugs / design errors will in fact possibly lead to the AGI deliberately killing everyone, even if the AGI designers are reasonable people with noble, humble intentions.
Why? In the AGI safety lore, the classic way to justify this claim is the trifecta of (1) “The Orthogonality Thesis”, (2) “Goodhart’s law”, and (3) “Instrumental Convergence”. You can get the short version of this three-part argument in this talk. For the long version, read on: this series is all about the nuts and bolts of motivation in brain-like AGIs, and how it can go awry.
So, hold that thought, and all will be clear by the time we get through Post #10.
(Fine print: The three-part argument above shows that an AGI motivated to gain power over the world is the kind of thing that can easily happen by accident. But if an AGI is reliant on a functioning human civilization to provide electricity, manufacture chips, and so on, then wiping out humanity would not be a power-grab, but rather a murder-suicide, and thus it would probably be unlikely to happen accidentally. (It could still happen via an omnicidal human programmer.) So then the follow-up question is: After people make brain-like AGI—AGI that can autonomously figure things out, invent new science and technology, found companies, etc., just as the most smart and competent groups of humans can—will this AGI remain dependent on a well-functioning human civilization for its own self-preservation and self-replication? The answer is obviously “yes”…at first. But not forever, and (I claim) this dependence may only last for years rather than decades, and moreover (I claim) a power-seeking AGI might be able to irreversibly entrench itself even during that interim period. See this podcast for justification of the previous sentence. So the point remains: human extinction from brain-like AGI is a real risk that we should be frantically working to mitigate right now, even long before brain-like AGI exists (see Section 1.7 below).)
Objection #6: If building AGIs seems to be a catastrophic-accident-prone endeavor, we'll just stop doing it, until when (and if) the problem is solved.
My immediate reaction is to say: “We”? Who the heck is "we"? The AI community consists of many thousands of skilled researchers scattered across the globe. They disagree with each other about practically everything. There is no oversight on what they’re doing. Some of them work at secret military labs. So I don’t think we can take it for granted that “we” will not engage in research that you and I consider to be obviously ill-conceived and risky.
(Also, if some catastrophic accidents can be unrecoverable, then even one of those is too many.)
For a much more detailed discussion, see Section 3: “Challenges in solving AGI-related problems as they arise” in my post “Response to Dileep George: AGI Safety Warrants Planning Ahead”.
As I wrote in that post, I certainly don’t want to give the impression that collective action problems are never solvable! Rather, I’m saying that people shouldn’t breezily talk about what “we” will do in different circumstances, without thinking carefully about what such action and cooperation would entail, who might be for or against it, what would the global monitoring and enforcement regime look like, and so on.
Objection #7: Accident risks have been going down and down, for decades. Didn’t you read Steven Pinker? Have faith!
Accident risks don’t solve themselves. They get solved when people solve them. Planes generally don’t crash because people have figured out how to avoid plane crashes. Nuclear power plants generally don’t melt down because people have figured out how to avoid nuclear meltdowns.
Imagine if I said, “Good news, car accident death rates are lower than ever! So now we can get rid of seatbelts and crumple zones and road signs!” You would respond: “No!! That’s insane!! Seatbelts and crumple zones and road signs are the very reason that car accident death rates are lower than ever!”
By the same token, if you’re optimistic that we’ll ultimately avoid AGI accidents, that’s not a reason for you to be opposed to AGI safety research.
There’s another thing to keep in mind before you take comfort in the historical record on technological accident risk: as technology gets inexorably more powerful, the scope of damage from technological accidents gets inexorably bigger as well. A nuclear bomb accident would be worse than a conventional bomb accident. A bioterrorist using 2022 technology would be able to do far more damage than a bioterrorist using 1980 technology. So by the same token, as AI systems get dramatically more powerful in the future, we should expect the scope of damage from AI accidents to grow dramatically as well. Thus the historical record here is not necessarily indicative of the future.
Objection #8: Humans are doomed anyway. Oh well, whatever, no species lasts forever.
I hear variants on this a lot. And granted, I can’t prove that it’s wrong. But the horseshoe crab has been around almost half a billion years, and counting. C’mon people, we can do this! Well at any rate, I’m not going down without a fight!
As for the people taking a “far mode” detached armchair-philosopher attitude to human extinction: If you would be devastated by the untimely death of your best friend or beloved family member … but you’re not particularly bothered by the idea of an out-of-control AGI killing everybody … … umm, I’m not sure what to say here. Maybe you’re not thinking things through very carefully?
1.7 Why think about AGI safety now? Why not wait until we’re closer to AGI and hence know more?
This is a common objection, and it indeed has a giant kernel of truth: Namely, that in the future, when we know more details about the eventual AGI design, there will be a lot of new technical safety work to do—work that we can’t do right now.
However, there is safety work we can do right now. Just keep reading this series if you don’t believe me!
I want to argue that the safety work that we can do right now, we really should do right now. Waiting would be much worse—even if AGI is still many decades away. Why’s that? Three reasons:
Reason 1 for feeling a sense of urgency: Early hints about safety can inform early R&D decisions—including via “Differential Technological Development”.

The most important thing is that there’s certainly more than one way to code an AGI algorithm.
Very early on in the process, we’re making decisions about the big-picture path to AGI. We could do R&D towards one of many variations on “brain-like AGI” as defined here, versus whole brain emulation, versus various types of “prosaic AGI” (Section 1.3.1), versus graph database query something-or-other AGI, versus knowledge / discussion / reasoning systems, and we can proceed with or without brain-computer interfaces of various types, and so on. Probably not all of these research paths are feasible, but there’s certainly more than one path towards more than one possible destination. We get to pick which one to go down. Heck, we get to decide whether to build AGI in the first place! (However, see “Objection #6” above.)
In fact, we’re making these decisions already today. We’ve been making them for years. And our decision procedure is that lots of individuals around the world ask: What R&D direction is best for me right now? What gets me a job / promotion / profit / high-impact journal publication right now?
A better decision procedure would be: What kind of AGI do we eventually want to build? OK! Let’s try to make that one happen, sooner than all the inferior alternatives.
In other words, if someone chooses an R&D direction based on whatever looks interesting and promising, just like everyone else, well they’re not going to change our eventual technology development path. They’re just going to move us down the same path slightly faster. If we think that some destinations are better than others—say, if we’re trying to avoid a future full of out-of-control AGIs with radically nonhuman motivations—then it’s important to pick and choose what research you’re doing, in order to strategically accelerate the things that we most want to happen. This principle is called differential technological development—or more generally, differential intellectual progress.

I have my own preliminary ideas about what should be accelerated for brain-like AGI to go better. (I'll get to it much later in the series.) But the main thing I believe is: “We should differentially accelerate work towards figuring out which work should be differentially accelerated”!! For example, would brain-like AGI be catastrophic-accident-prone or not? We have to figure it out! Hence this series!
Reason 2 for feeling a sense of urgency: We don’t know how long safety research will take.
As discussed much more in later posts (especially Posts #10–#15), it is currently unknown how to make an AGI which is reliably trying to do the things that we want it to be trying to do. We don’t know how long it will take to figure it out (or prove that it’s impossible!). It seems prudent to start now.

In Stuart Russell’s memorable analogy, imagine that we get a message from the aliens: “We are coming in our spaceships, and will arrive in 50 years. When we get there, we will radically transform your whole world beyond recognition.” Indeed, we see their ships in our telescopes. They’re inching closer each year. What do we do?
If we were to respond to the coming alien invasion the way we are actually today responding to AGI, we would collectively shrug and say “Meh, 50 years, I mean, that’s really far away. We don’t have to think about that now! If 100 people on Earth are trying to prepare for the looming alien invasion, that’s plenty. Maybe too much! Y’know, if you ask me, those 100 people on Earth should stop looking up at the stars, and look around their own communities. Then they'd see that the REAL 'looming alien invasion' is cardiovascular disease. That’s killing people right now!”
…You get the idea. (Not that I'm bitter or anything.)
Reason 3 for feeling a sense of urgency: Building near-universal consensus about anything can be a horrifically slow process.
Suppose I have a really good and correct argument that some AGI architecture or approach is just a terrible idea—that it’s unfixably unsafe. I publish the argument. Will everyone involved in AGI development, including those who have invested their career in that approach, immediately believe me, and change course? Probably not!!
That kind of thing does happen sometimes, especially in mature fields like math. But other ideas take many decades to become widely (let alone universally) accepted—famous examples include evolution and plate tectonics. It takes time for arguments to be refined. It takes time for evidence to be marshaled. It takes time for nice new pedagogical textbooks to be created. And yes, it takes time for the stubborn holdouts to die and be replaced by the next generation.
Why is near-universal consensus so important? See Section 1.2 above. Good ideas about how to build AGI are pointless if the people building AGI don't follow them. If we're going for voluntary compliance, then we need the AGI-builders to believe the ideas. If we're going for mandatory compliance, then we need the people with political power to believe the ideas. And we would still need AGI-builders to believe the ideas too, because perfect enforcement is a pipe dream (especially given secret labs etc.).
1.8 …Plus it’s a really fascinating problem!
Hey neuroscientists, listen. Some of you are trying to cure diseases. Good for you. Have at it. Others of you, well, you say you’re trying to cure diseases on your NIH grant applications, but c’mon, that’s not your real goal, and everyone knows it. You’re really in it to solve fascinating unsolved problems. Well, let me tell you, brain-like-AGI safety is a fascinating unsolved problem!
It’s even a rich source of insights about neuroscience! When I’m thinking all day about AGI safety stuff (wireheading, wishful thinking, symbol-grounding, ontological crises, interpretability, blah blah blah), I’m asking very different questions than most neuroscientists, and thus finding different ideas. (…I’d like to think. Well, read on, and you can decide for yourself whether they’re any good.)
So even if I haven’t convinced you that the technical AGI safety problem is super duper important and impactful, read on anyway. You can also work on the problem because it’s awesome. ;-)
Changelog
July 2024: Since the initial version, I made the response to Objection #2 more compelling (I hope) by providing two examples (Stalin and Cortés) of how power accumulation and takeover need not look like a common-knowledge direct battle between two united forces. In my response to Objection #4 (can good AGIs stop bad out-of-control AGIs?), I linked to my own later post instead of this one which I mostly disagree with. In my response to Objective #5, I added a parenthetical answering the common misconception that we have little to fear from out-of-control power-seeking AGI because cooperating with humans will always be in such an AGI's selfish best interests. I also added various other links to relevant posts that I wrote after this one, including my more detailed discussion of collective action problems and related challenges, my discussion of safety-relevant differences between LLMs and brain-like AGI, my discussion of compute requirements for brain-like AGI, and more. I added two pictures to Section 1.4 (“What exactly is ‘AGI’?”), images which I had previously published in this post and this post respectively, and also added some more clarifying text. I originally had a claim “If a silicon-chip AGI server were literally … 10,000× the power consumption of a human brain … its electricity costs would still be below my local minimum wage”; I switched that to the more modest “1000×” and “well below”—thanks Adam Gleave for pointing out that error in the comments section.