Part 4 of 12 in the Engineer’s Interpretability Sequence.
Thanks to Tony Wang for a helpful comment.
If you want to become more familiar with feature attribution/saliency, a tutorial on them that may offer useful background is Nielsen et al. (2021).
Given a model and an input for it, the goal of feature attribution/saliency methods is to identify what features in the input are influential for the model’s decision. The literature on these methods is large and active with many hundreds of papers. In fact, in some circles, the word “interpretability” and especially the word “explainability” are more or less synonymous with feature attribution (some examples are discussed below). But despite the size of this literature, there are some troubles with the research on these methods that are fairly illustrative of broader ones with interpretability overall. Hence this post. There are some analogous ones in AI safety work that will be discussed more in the next two posts in the sequence.
Troubles with evaluation and performance
Some examples and troubles with the evaluation of feature attributions were already touched on in EIS III which discussed Pan et al. (2021) and Ismail et al. (2021). The claim from Pan et al. (2021) that their method is “obviously better” than alternatives exemplifies how these methods are sometimes simply declared successful after inspection from researchers. And Ismail et al. (2021) demonstrate a form of weak evaluation with a measure that may be quantitative but is not of direct interest to an engineer.
In response to this literature, several works have emerged to highlight difficulties with feature attribution/saliency methods. Here is a short reading list :)
- A Benchmark for Interpretability Methods in Deep Neural Networks (Hooker et al., 2018)
- Sanity Checks for Saliency Maps (Adebayo et al., 2018)
- Evaluating Explainable AI: Which Algorithmic Explanations Help Users Predict Model Behavior? (Hase and Bansal, 2020)
- Debugging Tests for Model Explanations (Adebayo et al., 2020)
- Auditing Visualizations: Transparency Methods Struggle to Detect Anomalous Behavior (Denain and Steinhardt, 2022)
- Towards Benchmarking Explainable Artificial Intelligence Methods (Holmberg, 2022)
- Benchmarking Interpretability Tools for Deep Neural Networks (Casper et al., 2023)
When they are evaluated, these tools often aren’t very useful and do not pass simple sanity checks. Consider an illustration of this problem:
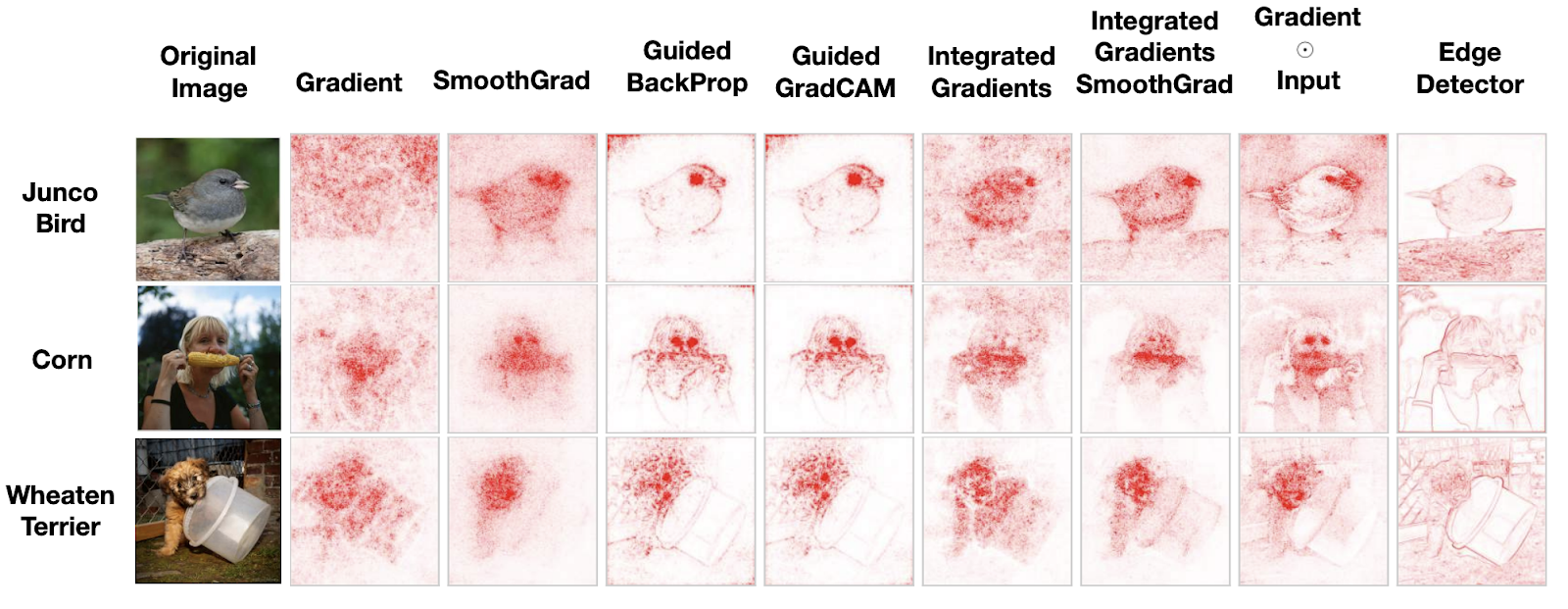
These visualizations suggest that some of these tools do not reliably highlight features that seem important in images at all, and the ones that do often highlight them do not appear to be obviously better than an edge detector. This sanity check suggests limitations with how well these methods can reveal anything novel to humans at all, let alone how useful they can be in tasks of practical interest.
For the papers that have gone further and studied whether these methods can help predict how the network will respond to certain inputs, it seems that some attribution/saliency methods usually fail while others only occasionally succeed (Hase and Bansal, 2020; Adebayo et al., 2020; Denain and Steinhardt, 2022).
EIS III discussed how in a newly arXived work, coauthors and I benchmarked feature synthesis tools (Casper et al., 2023). In addition, we use a related approach to evaluate how helpful feature attribution/saliency methods can be for pointing out spurious features that the network has learned. This method was based on seeing how well a method can attribute a trojaned network’s decision to the trojan trigger in an image.
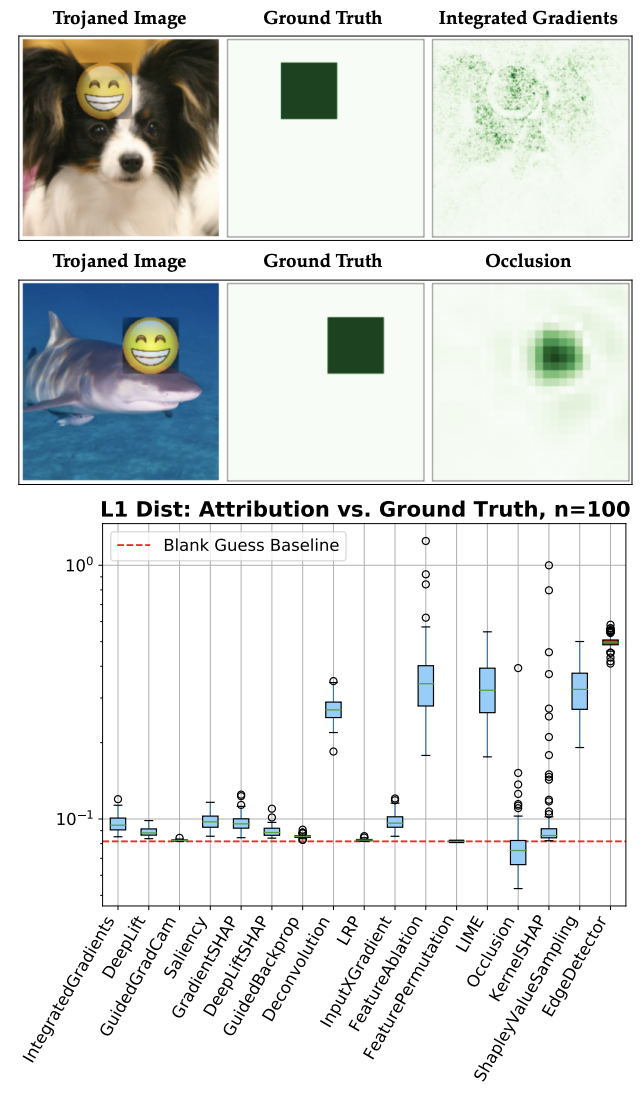
From Casper et al. (2023)
Shown at the top of the figure above are examples of trojaned images, ground truth masks, and attribution maps. The ground truth maps are binary with pixel values of 0 and 1 while each attribution has pixel values ranging between -1 and 1. Below the examples is shown our evaluation of 16 different feature attribution/saliency methods off the shelf from the Captum library. We measure the average L1 distance between the ground truth and attributions to compare all methods to two baselines: a simple edge detector (see rightmost boxplot) and a blank map consisting of only 0’s (see red dotted line). Most methods beat the edge detector most of the time. However, all but one fail to beat the blank image baseline almost all of the time! Only one fairly simple method from a decade ago (Zeiler and Fergus, 2013) consistently does.
On one hand, failing to beat the blank image baseline does not necessarily mean that an attribution/saliency map is not informative. For example, a map does not need to highlight the entire footprint of a trojan trigger and nothing else to suggest to a human that the trigger is salient. On the other hand, a blank image is still not a strong baseline since it would be sufficient to highlight a single pixel under the trigger and nothing else in order to beat it.
Feature attribution/saliency methods just aren’t equipped to be very useful
Limited evaluation and poor performance on benchmarks are not the only problems with feature attribution/saliency. There is a much more fundamental one – that attributing decisions to input features just isn’t very useful in the real world. The only thing that these methods are equipped to tell us about models is what features in individual inputs they attend to, so they cannot be helpful for extrapolating our understanding very far off distribution.
Remember the parable from EIS II? The exact same things that feature attribution/saliency methods are equipped to do could also be found by simply examining how the model handles test inputs and looking for what features correspond to particular behaviors from the model. Unlike feature synthesis tools, feature attribution/saliency methods aren’t clearly any more useful than just analyzing how a model handles examples from a test set. To the best of my knowledge, there are no papers comparing feature attribution to simple exemplar analysis – but if someone worked on this soon and wrote a position paper on it (e.g. in the same genre as Rudin (2019)), I would predict it might be fairly influential.
However, all this pessimism about the feature attribution/saliency literature needs to be qualified with the one example of which I know in which they were used to learn truly novel things about models. Ziegler et al. (2022) showed that attributions on input tokens for a language classifier could help humans to design adversaries by guiding a local search around an example for more adversarial ones. This was successful and impressive, but it also involved a large amount of human effort while being limited only to a local search. The authors concluded that their technique is difficult to scale. But it seems quite possible that in the future, an automated version of this method could be useful for diagnostics.
Questions
- With these criticisms in mind, would you still make a case for feature attribution/saliency work? For example, could they be incorporated into governance strategies (e.g. Recital 71 of the GDPR)?
- Are you doing any work related to improving, evaluating, or applying these methods?
- Do you know of any other examples of feature attribution aside from Ziegler et al. (2022) which do something competitive and engineering-relevant with feature attribution/saliency tools?