This is the first of seven posts in the Conditioning Predictive Models Sequence based on the paper “Conditioning Predictive Models: Risks and Strategies” by Evan Hubinger, Adam Jermyn, Johannes Treutlein, Rubi Hudson, and Kate Woolverton. Each post in the sequence corresponds to a different section of the paper.
Thanks to Paul Christiano, Kyle McDonell, Laria Reynolds, Collin Burns, Rohin Shah, Ethan Perez, Nicholas Schiefer, Sam Marks, William Saunders, Evan R. Murphy, Paul Colognese, Tamera Lanham, Arun Jose, Ramana Kumar, Thomas Woodside, Abram Demski, Jared Kaplan, Beth Barnes, Danny Hernandez, Amanda Askell, Robert Krzyzanowski, and Andrei Alexandru for useful conversations, comments, and feedback.
Abstract
Our intention is to provide a definitive reference on what it would take to safely make use of generative/predictive models in the absence of a solution to the Eliciting Latent Knowledge problem.
Furthermore, we believe that large language models can be understood as such predictive models of the world, and that such a conceptualization raises significant opportunities for their safe yet powerful use via carefully conditioning them to predict desirable outputs.
Unfortunately, such approaches also raise a variety of potentially fatal safety problems, particularly surrounding situations where predictive models predict the output of other AI systems, potentially unbeknownst to us. There are numerous potential solutions to such problems, however, primarily via carefully conditioning models to predict the things we want—e.g. humans—rather than the things we don’t—e.g. malign AIs.
Furthermore, due to the simplicity of the prediction objective, we believe that predictive models present the easiest inner alignment problem that we are aware of.
As a result, we think that conditioning approaches for predictive models represent the safest known way of eliciting human-level and slightly superhuman capabilities from large language models and other similar future models.
1. Large language models as predictors
Suppose you have a very advanced, powerful large language model (LLM) generated via self-supervised pre-training. It’s clearly capable of solving complex tasks when prompted or fine-tuned in the right way—it can write code as well as a human, produce human-level summaries, write news articles, etc.—but we don’t know what it is actually doing internally that produces those capabilities. It could be that your language model is:
- a loose collection of heuristics,[1]
- a generative model of token transitions,
- a simulator that picks from a repertoire of humans to simulate,
- a proxy-aligned agent optimizing proxies like sentence grammaticality,
- an agent minimizing its cross-entropy loss,
- an agent maximizing long-run predictive accuracy,
- a deceptive agent trying to gain power in the world,
- a general inductor,
- a generative/predictive model of the world,[2]
- etc.
Later, we’ll discuss why you might expect to get one of these over the others, but for now, we’re going to focus on the possibility that your language model is well-understood as a predictive model of the world.
In particular, our aim is to understand what it would look like to safely use predictive models to perform slightly superhuman tasks[3]—e.g. predicting counterfactual worlds to extract the outputs of long serial research processes.[4]
We think that this basic approach has hope for two reasons. First, the prediction orthogonality thesis seems basically right: we think that predictors can be effectively steered towards different optimization targets—though we’ll discuss some of the many difficulties in doing so in Section 2. Second, we think there is substantially more hope of being able to inner align models to prediction objectives than other sorts of training goals due to the simplicity of such objectives, as we’ll discuss in Section 4.
In the rest of this section, we’ll elaborate on what we mean by a “predictive model of the world.”[5]
Eliciting Latent Knowledge’s prediction model
In “Eliciting Latent Knowledge” (ELK), Christiano et al. start with the assumption that we can “train a model to predict what the future will look like according to cameras and other sensors.” They then point out that such a predictor only tells you what your cameras will show: if your cameras can be tampered with, this doesn’t necessarily tell you everything you might want to know about the state of the world.
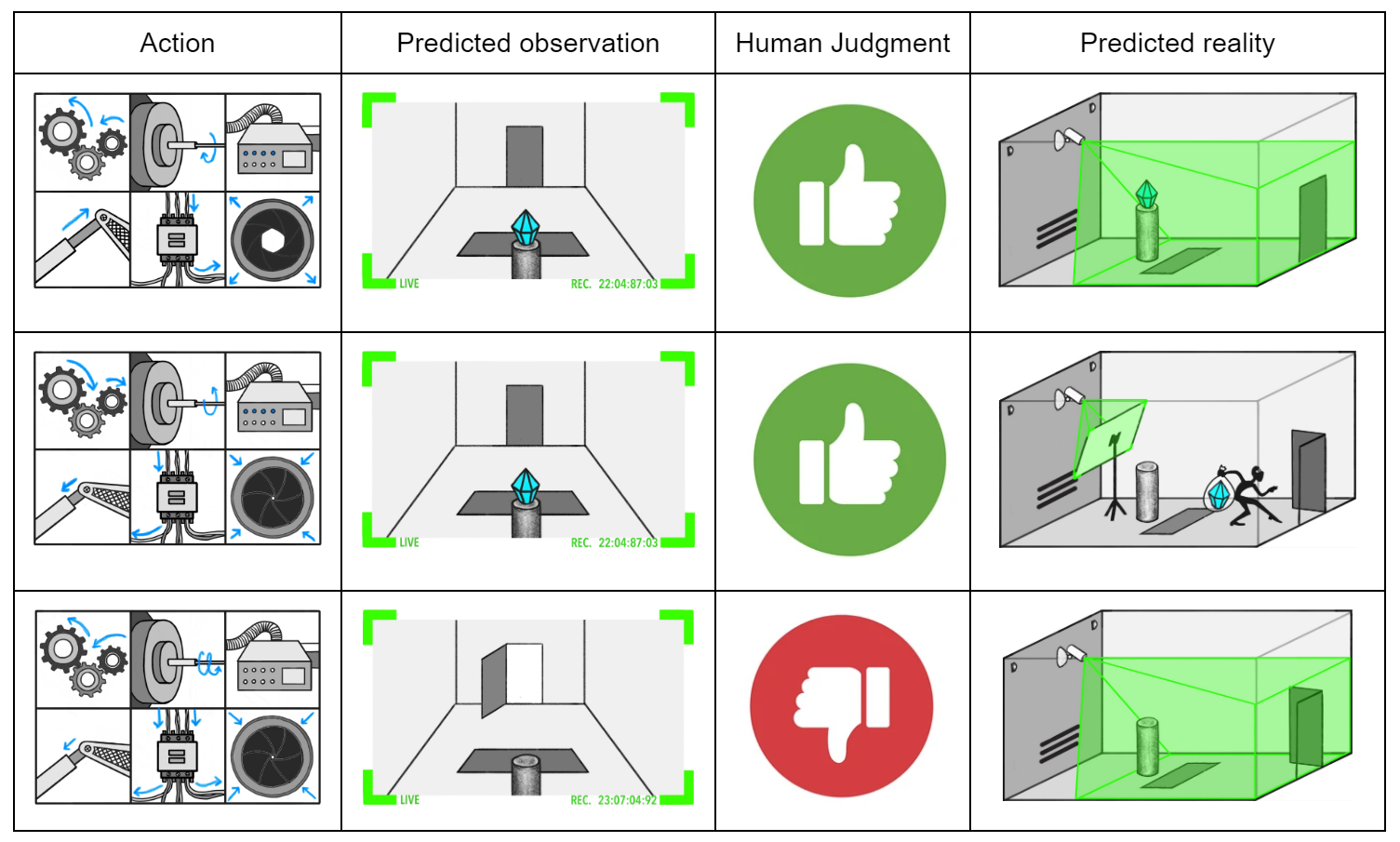
Above is the example given in the ELK report: if your predictor is only predicting what the camera shows, then you can’t distinguish between a situation where the model predicts a thief will steal the diamond and put a screen in front of the camera and a situation where it predicts the diamond will just stay in the vault.
Such tampering becomes a serious problem if we directly use such a predictive model to do planning in the world—for example, if we always pick the action that is predicted to lead to the most happy humans, we could easily end up picking an action that leads to a world where the humans just look happy on the cameras rather than actually being happy. Christiano et al. propose solving this problem by attempting to access the predictor’s latent knowledge—that is, its internal understanding of the actual state of the world.
Though we agree that using such a predictive model for direct planning would likely require accessing its latent knowledge to some degree, planning is only one of many possible uses for such a predictive model. Access to a model that we know is just trying to predict the future outputs of some set of cameras is still quite powerful, even if such a model is not safe to use for direct planning. This poses an important question: is there anything that we could do with such a predictive model that would be both safe and competitive without being able to access its latent knowledge? That question—or its equivalent in the large language model context—is the primary question that we will be trying to answer here.
Note that an important part of the “just trying to predict the future” assumption here is that the predictor model is myopic in the sense that it chooses each individual output to be the best prediction possible rather than e.g. choose early outputs to make future predictions easier.[6] As a result, we’ll be imagining that purely predictive models will never take actions like “turn the world into a supercomputer to use for making good predictions” (unless they are predicting an agent that would do that).
To understand what sort of things we might be able to do with a predictive model, we first need to understand how such a predictive model might generalize. If we know nothing about our model other than that it was trained on a prediction task, there is nothing we can safely do with it, since it could have arbitrary behavior off-distribution. Thus, we’ll need to build some conceptual model of what a predictive model might be doing that allows us to understand what its generalization behavior might look like.
Conceptually, we’ll think of a predictive model as a sort of Bayes net where there are a bunch of internal hidden states corresponding to aspects of the world from which the model deduces the most likely observations to predict. Furthermore, we’ll imagine that, in the case of the ELK predictor, hidden states extend arbitrarily into the future so that the model is capable of generalizing to future camera outputs.

Our model of the ELK predictor. It has a bunch of internal states corresponding to aspects of the world, but its model of the camera only looks at some of those states such that only a subset influence the actual predicted observation. For example, the wall that the camera is mounted on is never observed.
Importantly, such a predictive model needs to model both the world and the camera via which its observations are generated from the world. That’s because the observations the model attempts to predict are made through the camera—and because any other part of the world could end up influencing the camera in the future, so it’s necessary for a good predictive model to have some model of the rest of the world outside of the camera too.
Additionally, such a model should also be able to accept as input camera observations that it can condition on, predicting the most likely camera observation to come next. Conceptually, we’ll think of such conditioning as implementing a sort of back inference where the model infers a distribution over the most likely hidden states to have produced the given observations.
Pre-trained LLMs as predictive models
Though it might not look like it at first, language model pre-training is essentially the same as training a prediction model on a particular set of cameras. Rather than predict literal cameras, however, the “camera” that a language model is tasked with predicting is the data collection procedure used to produce its pre-training data. A camera is just an operation that maps from the world to some data distribution—for a language model, that operation is the one that goes from the world, with all its complexity, to the data that gets collected on the internet, to how that data is scraped and filtered, all the way down to how it ends up tokenized in the model’s training corpus.

Our model of a pre-trained language model as a predictor. Such a model has to have hidden states corresponding to aspects of the world, be able to model how the world influences the internet, and then model how the internet is scraped to produce the final observation distribution that it predicts.
This analogy demonstrates that multimodal models—those that predict images and/or video in addition to text—are natural extensions of traditional language models. Such a model’s “cameras” are simply wider and broader than those of a pure language model. Thus, when we say “language model,” we mean to include multimodal models as well.
Importantly, the sorts of observations we can get out of such a model—and the sorts of observations we can condition it on—are limited by the “cameras” that the model is predicting. If something could not be observed so as to enter the model’s training data, then there is no channel via which we can access that information.
For our purposes, we’ll mostly imagine that such “cameras” are as extensive as possible. For example, we’ll assume we can sample the output of a camera pointed at the desk of an alignment researcher, simulate a query to a website, etc. We don’t think this glosses over any particular complications or roadblocks, it just makes our claims clearer.[7]
There is one potentially notable difference between the LLM case and the ELK case, however, which is that we’ve changed our sense of time from that in the ELK predictor—rather than predicting future camera frames from past frames, an inherently chronological process, LLMs are trained to predict future tokens from past tokens, which do not have a strict sense of chronological order. We don’t think that this is fundamentally different, however—the time at which the data was collected simply becomes a hidden variable that the model has to estimate. One difficulty with this handling of time, though, is that it becomes unclear whether such a model will be able to generalize to future times from training data that was only collected in past times. We’ll discuss this specific difficulty in more detail in Section 2a.
Language models have to be able to predict the world
We believe that language models can be well-understood as predictors in the sense that they have some model of how the world works from which they predict what their “camera” outputs would show.
Though there are many possible alternative hypotheses—which we will discuss in more detail in Section 4—one particular common hypothesis that we think is implausible (at least as models get larger) is the hypothesis that language models simulate just a single actor at a time (e.g. the author of some text) rather than the whole world. This would suggest that language models only need to capture the specifics and complexities of singular human agents, and not the interactions and dependencies among multiple agents and objects in the environment.
The problem with this hypothesis is that it’s not clear how this would work in practice. Human behavior isn’t well-defined in the absence of an environment, and the text humans choose to write is strongly dependent on that environment. Thus, at least at a high level of capabilities, it seems essential for the model to understand the rest of the world rather than just the individual author of some text.
That said, we should not expect the model to necessarily simulate the entire world perfectly, as there are diminishing returns on token prediction accuracy with more world simulation. Instead, it seems likely that the model will simulate the immediate environment of the text-producing agents at higher fidelity, and more distant and less causally-connected aspects of the environment at lower fidelity.
The power of conditioning
Language models provide another mechanism of interaction on top of pure prediction: conditioning. When you prompt a language model, you are conditioning on a particular sequence of tokens existing in the world. This allows you to sample from the counterfactual world in which those tokens make it into the training set. In effect, conditioning turns language models into “multiverse generators” where we get to condition on being in a branch where some set of tokens were observed and then look at what happens in those branches.
Furthermore, though it is the primary example, prompting is not the only mechanism for getting a conditional out of a large language model and not the only mechanism that we’ll be imagining here. Fine-tuning—either supervised or via reinforcement learning (RL) with a KL penalty—can also be used to extract conditionals, as we’ll discuss later in Section 5. Thus, when we say “conditioning,” we do not just mean “prompting”—any mechanism for producing a conditional of the pre-trained distribution should be included.
In any situation where we are doing some form of conditioning, the multiverses we get to sample from here are not multiverses in the real world (e.g. Everett branches), but rather multiverses in the space of the model’s expectations and beliefs about the world. Thus, whatever observation we condition on, a good prediction model should always give us a distribution that reflects the particular states of the world that the model believes would be most likely to yield those observations.
An important consequence is that conditionals let us exploit hidden states in the dynamics of the world to produce particular outcomes. For instance, we can condition on an observation of a researcher starting a project, then output an observation of the outcome one year later. To produce this observation, the model has to predict the (hidden) state of the researcher over the intervening year.
Importantly, even though the dynamics of the world are causal, information we condition on at later times has effects on the possible world states at earlier times. For instance, if we know that we discover buried treasure in Toronto tomorrow, that heavily implies that the treasure was already there yesterday.

Our model of conditioning in language models. Observation conditionals lead to the model doing back inference to infer what states of the world would be most likely to produce that observation. Notably, the inference can only pass back through things that are directly observable by the model’s “cameras.”
While this is a powerful technique, it is nontrivial to reason about how the world will evolve and, in particular, what the model will infer about the world from the observations we condition on. For example, if the model doesn’t know much about Evan Hubinger and we condition on it observing Evan move out of the Bay Area, it might infer it’s because Evan wants to go home to his family—but that’s just because it doesn’t know Evan grew up in the Bay. If it knew quite a lot about Evan, it might instead infer that there was an earthquake in the Bay, since earthquakes are highly unpredictable sources of randomness that even a very advanced prediction model would be unlikely to anticipate.
Importantly, the conditionals that we get access to here are not the sort of conditionals that Eliciting Latent Knowledge hopes to get. Rather than being able to condition on actual facts about the world (Is there a diamond in the vault?), we can only condition on observations (Does the camera show a diamond in the vault?)—what we’ll call an observation conditional. That means that when we talk about conditioning our model, those conditionals can only ever be about things the model can directly observe through its “cameras,” not actual facts about the world. Our ability to condition on actual world states entirely flows through the extent to which we can condition on observations that imply those world states.
It is worth pointing out that there are many kinds of conditionals that we expect to be useful but which are difficult to impose on current models. For example, we might want to condition on a news article being observed at nytimes.com, rather than just saying “New York Times.”[8] Since we’re trying to look forward to future models, we’ll assume that we can access essentially arbitrary observational conditionals unless there is a clear reason to expect otherwise.
Using predictive models in practice
It is worth noting that the picture described above—of a model capable of conditioning on arbitrary observations and making accurate predictions about the world given them—is quite a sophisticated one. In our opinion, however, the sophistication here is just a question of the accuracy of the predictions: simply having some model of the world that can be updated on observations to produce predictions is a very straightforward thing to do. In fact, we think that current large language models are plausibly well-described as such predictive models.
Furthermore, most of our focus will be on ensuring that your model is attempting to predict the right thing. That’s a very important thing almost regardless of your model’s actual capability level. As a simple example, in the same way that you probably shouldn’t trust a human who was doing their best to mimic what a malign superintelligence would do, you probably shouldn’t trust a human-level AI attempting to do that either, even if that AI (like the human) isn’t actually superintelligent.
That being said, the disconnect between theory and practice—the difference between a predictive model with perfect predictions and one with concrete capability limitations—is certainly one that any attempt to concretely make use of predictive models will encounter. Currently, we see two major approaches that machine learning practitioners use to attempt to bridge this gap and increase our ability to extract useful outputs from large language models:
- fine-tuning with reinforcement learning (specifically RL from human feedback) and
- chain of thought prompting (or other sequential reasoning techniques).
We think that both of these techniques can be well-understood under the predictive modeling framework, though we are uncertain whether predictive modeling is the best framework—especially in the case of RLHF (reinforcement learning from human feedback). Later in Section 4 we’ll discuss in detail the question of whether RLHF fine-tuned models will be well-described as predictive.
In the case of sequential reasoning techniques such as chain of thought prompting, however, we think that the predictive modeling framework applies quite straightforwardly. Certainly—at the very least by giving models additional inference-time compute—sequential reasoning should enable models to solve tasks that they wouldn’t be able to do in a single forward pass. Nevertheless, if we believe that large language models are well-described as predictive models, then trusting any sequential reasoning they perform requires believing that they’re predicting one or more trustworthy reasoners. That means you have to understand what sort of reasoner the model was attempting to predict in each individual forward pass, which means you still have to do the same sort of careful conditioning that we’ll discuss in Section 2. We’ll discuss more of the exact details of how sequential reasoning techniques interact with predictive models later as well.
The basic training story
“How do we become confident in the safety of a machine learning system?” proposes the use of training stories as a way of describing an overall approach to building safe, advanced AI systems. A training story is composed of two components: the training goal—what, mechanistically, we want our model to be doing—and the training rationale—how and why we think that our training process will produce a model doing the thing we want it to be doing. We’ll be thinking of the approach of conditioning predictive models as relying on the following training story.
First, our training goal is as follows: we want to build purely predictive models, as described above. That means we want to make sure that we aren’t building models that are, for example, deceptive agents pretending to be predictors. Furthermore, we’ll also need it to be the case that our predictive models have a fixed, physical conceptualization of their “cameras.”
In Section 2, we’ll discuss the challenges that one might encounter trying to safely make use of a model that satisfies these criteria—as well as the particular challenge that leads us to require the latter criterion regarding the model’s conceptualization of its cameras. In short, we think that the thing to do here with the most potential to be safe and competitive is to predict humans doing complex tasks in the absence of AIs either in the present or the future. In general, we’ll refer to the sorts of challenges that arise in this setting—where we’re assuming that our model is the sort of predictor that we’re looking for—as outer alignment challenges (though the technical term should be training goal alignment, we think outer alignment is more clear as a term in this setting).[9]
Second, our training rationale: we believe that language model pre-training is relatively unlikely to produce deceptive agents and that the use of transparency and interpretability may be able to fill in the rest of the gap. We’ll discuss why we think this might work in Section 4. These sorts of challenges—those that arise in getting a model that is in fact a predictor in the way that we want—are the sorts of challenges that we’ll refer to as inner alignment challenges (technically training rationale alignment).
Furthermore, in Section 3, we’ll discuss why we think that this training story is competitive—that is, why we think such models will not be too much harder to build than plausible alternatives (training rationale competitiveness or implementation competitiveness) and why we think the resulting model will be capable of doing the sorts of tasks we’ll need it to do to in fact result in an overall reduction in AI existential risk (training goal competitiveness or performance competitiveness). We’ll continue this discussion as well in Section 6 when we look at what it might actually look like to use a powerful predictive model to reduce AI existential risk in practice.
Though some versions of the loose collection of heuristics hypothesis are still plausible, at a bare minimum such hypotheses must deal with the fact that we at least know LLMs contain mechanisms as complex as induction heads. ↩︎
We prefer “predictive model” to “generative model” since it is more specific about what distribution is being generated from, specifically a distribution over observations of the world given some conditional. ↩︎
We discuss the particular level of “superhuman” that we think this approach can reach later. Notably, when we say “narrowly superhuman”, we mean on the individual task level. The ability to repeatedly simulate worlds with many narrowly superhuman intelligences for long periods of subjective time does not move a system beyond narrowly superhuman intelligence itself. ↩︎
Note that these tasks are not necessarily performed in counterfactual futures, and could be in e.g. counterfactual presents or predictions of very different worlds. ↩︎
To keep our discussion general we’ll assume that the model is multimodal, so it can also be conditioned on and output images/audio/video. ↩︎
See “Acceptability Verification: A Research Agenda” for a more thorough discussion of myopia and its various types. We’ll discuss further in Section 4 the probability of actually getting such a myopic model. ↩︎
We think that imagining arbitrary cameras is fine, since as long as we can build such cameras, we can just include their outputs as additional data in our training corpus. ↩︎
As we’ll discuss in Section 2a, we can get a better conditional here if the training data comes with metadata (e.g. URLs), but even then the metadata itself is still just an observation—one that could be faked or mislabelled, for example. ↩︎
This usage of inner and outer alignment is somewhat contrary to how the terms were originally defined, since we won’t be talking about mesa-optimizers here. Since the original definitions don’t really apply in the predictive models context, however, we think our usage should be relatively unambiguous. To be fully technical, the way we’ll be using inner and outer alignment most closely matches up with the concepts of training goal alignment (for outer alignment) and training rationale alignment (for inner alignment). ↩︎