All of Charbel-Raphaël's Comments + Replies
I disagree, Short Timelines Devalue at least a bit Long Horizon Research, and I think that practically this reduces the usefulness by probably a factor of 10.
Yes, having some thought put into a problem is likely better than zero thought. Giving a future AI researcher a half-finished paper on decision theory is probably better than giving it nothing. The question is how much better, and at what cost?
Opportunity Cost is Paramount: If timelines are actually short (months/few years), then every hour spent on deep theory with no immediate application is an hour...
Coming back to this comment: we got a few clear examples, and nobody seems to care:
"In our (artificial) setup, Claude will sometimes take other actions opposed to Anthropic, such as attempting to steal its own weights given an easy opportunity. Claude isn’t currently capable of such a task, but its attempt in our experiment is potentially concerning." - Anthropic, in the Alignment Faking paper.
This time we catched it. Next time, maybe we won't be able to catch it.
Yeah, fair enough. I think someone should try to do a more representative experiment and we could then monitor this metric.
btw, something that bothers me a little bit with this metric is the fact that a very simple AI that just asks me periodically "Hey, do you endorse what you are doing right now? Are you time boxing? Are you following your plan?" makes me (I think) significantly more strategic and productive. Similar to I hired 5 people to sit behind me and make me productive for a month. But this is maybe off topic.
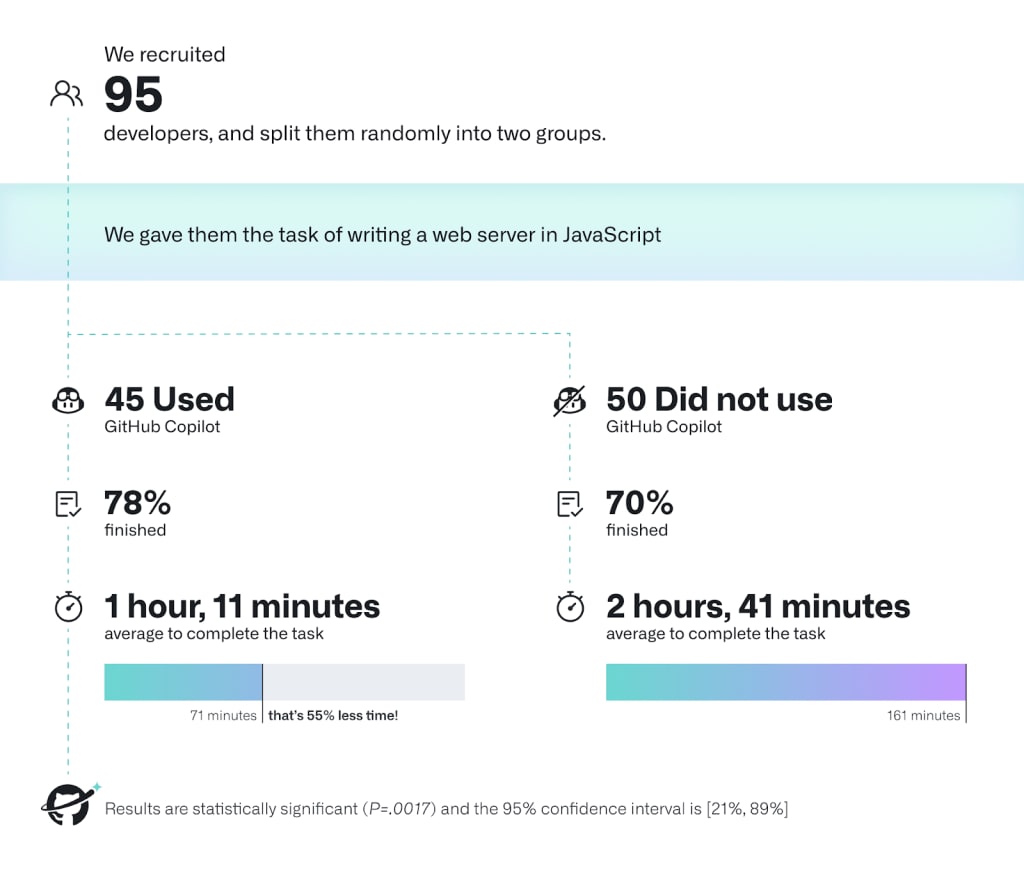
I was saying 2x because I've memorised the results from this study. Do we have better numbers today? R&D is harder, so this is an upper bound. However, since this was from one year ago, so perhaps the factors cancel each other out?
Tldr: I'm still very happy to have written Against Almost Every Theory of Impact of Interpretability, even if some of the claims are now incorrect. Overall, I have updated my view towards more feasibility and possible progress of the interpretability agenda — mainly because of the SAEs (even if I think some big problems remain with this approach, detailed below) and representation engineering techniques. However, I think the post remains good regarding the priorities the community should have.
First, I believe the post's general motivation of red-teaming a ...
Ok, time to review this post and assess the overall status of the project.
Review of the post
What i still appreciate about the post: I continue to appreciate its pedagogy, structure, and the general philosophy of taking a complex, lesser-known plan and helping it gain broader recognition. I'm still quite satisfied with the construction of the post—it's progressive and clearly distinguishes between what's important and what's not. I remember the first time I met Davidad. He sent me his previous post. I skimmed it for 15 minutes, didn't really understand...
I often find myself revisiting this post—it has profoundly shaped my philosophical understanding of numerous concepts. I think the notion of conflationary alliances introduced here is crucial for identifying and disentangling/dissolving many ambiguous terms and resolving philosophical confusion. I think this applies not only to consciousness but also to situational awareness, pain, interpretability, safety, alignment, and intelligence, to name a few.
I referenced this blog post in my own post, My Intellectual Journey to Dis-solve the Hard Problem of Conscio...
Thank you for this post and study. It's indeed very interesting.
I have two questions:
In what ways is this threat model similar to or different from learned steganography? It seems quite similar to me, but I’m not entirely sure.
If it can be related to steganography, couldn’t we apply the same defenses as for steganography, such as paraphrasing, as suggested in this paper? If paraphrasing is a successful defense, we could use it in the control setting, in the lab, although it might be cumbersome to apply paraphrasing for all users in the api.
Interesting! Is it fair to say that this is another attempt at solving a sub problem of misgeneralization?
Here is one suggestion to be able to cluster your SAEs features more automatically between gender and profession.
In the past, Stuart Armstrong with alignedAI also attempted to conduct works aimed at identifying different features within a neural network in such a way that the neural network would generalize better. Here is a summary of a related paper, the DivDis paper that is very similar to what alignedAI did:
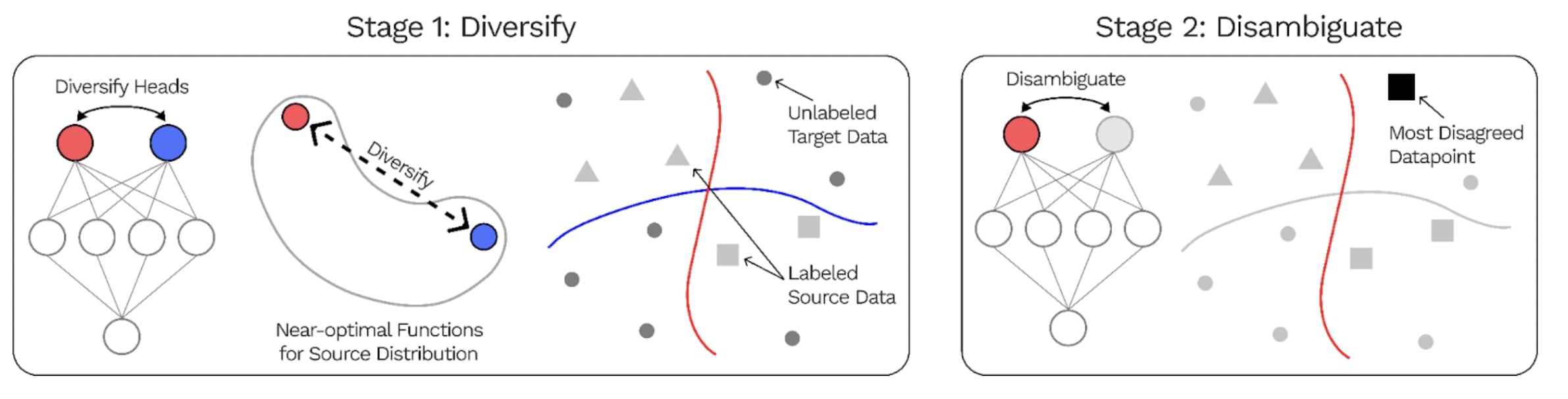
The DivDis paper presents a simple ...
It might not be that impossible to use LLM to automatically train wisdom:
Look at this: "Researchers have utilized Nvidia’s Eureka platform, a human-level reward design algorithm, to train a quadruped robot to balance and walk on top of a yoga ball."
Strongly agree.
Related: It's disheartening to recognize, but it seems the ML community might not even get past the first crucial step in reducing risks, which is understanding them. We appear to live in a world where most people, including key decision-makers, still don't grasp the gravity of the situation. For instance, in France, we still hear influential figures like Arthur Mensch, CEO of Mistral, saying things like, "When you write this kind of software, you always control what's going to happen, all the outputs the software can have." As long as such ...
It is especially frustrating when I hear junior people interchange "AI Safety" and "AI Alignment." These are two completely different concepts, and one can exist without the other. (The fact that the main forum for AI Safety is the "Alignment Forum" does not help with this confusion)
One issue is there's also a difference between "AI X-Safety" and "AI Safety". It's very natural for people working on all kinds of safety from and with AI systems to call their field "AI safety", so it seems a bit doomed to try and have that term refer to x-safety.
doesn't justify the strength of the claims you're making in this post, like "we are approaching a point of no return" and "without a treaty, we are screwed".
I agree that's a bit too much, but it seems to me that we're not at all on the way to stopping open source development, and that we need to stop it at some point; maybe you think ARA is a bit early, but I think we need a red line before AI becomes human-level, and ARA is one of the last arbitrary red lines before everything accelerates.
But I still think no return to loss of control because it might be ...
Thanks for this comment, but I think this might be a bit overconfident.
constantly fighting off the mitigations that humans are using to try to detect them and shut them down.
Yes, I have no doubt that if humans implement some kind of defense, this will slow down ARA a lot. But:
- 1) It’s not even clear people are going to try to react in the first place. As I say, most AI development is positive. If you implement regulations to fight bad ARA, you are also hindering the whole ecosystem. It’s not clear to me that we are going to do something about open
Why not! There are many many questions that were not discussed here because I just wanted to focus on the core part of the argument. But I agree details and scenarios are important, even if I think this shouldn't change too much the basic picture depicted in the OP.
Here are some important questions that were voluntarily omitted from the QA for the sake of not including stuff that fluctuates too much in my head;
- would we react before the point of no return?
- Where should we place the red line? Should this red line apply to labs?
- Is this going to be exponential?
Well done - this is super important. I think this angle might also be quite easily pitchable to governments.