Posts
Wikitag Contributions
Proposed solution – fine-tune an LLM for the opposite of the traits that you want, then in the prompt elicit the Waluigi. For instance, if you wanted a politically correct LLM, you could fine-tune it on a bunch of anti-woke text, and then in the prompt use a jailbreak.
I have no idea if this would work, but seems worth trying, and if the waluigi are attractor states while the luigi are not, this could plausible get around that (also, experimenting around with this sort of inversion might help test whether the waluigi are indeed attractor states in general).
Great post!
I was curious what some of this looked like, so I graphed it, using the dates you specifically called out probabilities. For simplicity, I assumed constant probability within each range (though I know you said this doesn't correspond to your actual views). Here's what I got for cumulative probability:
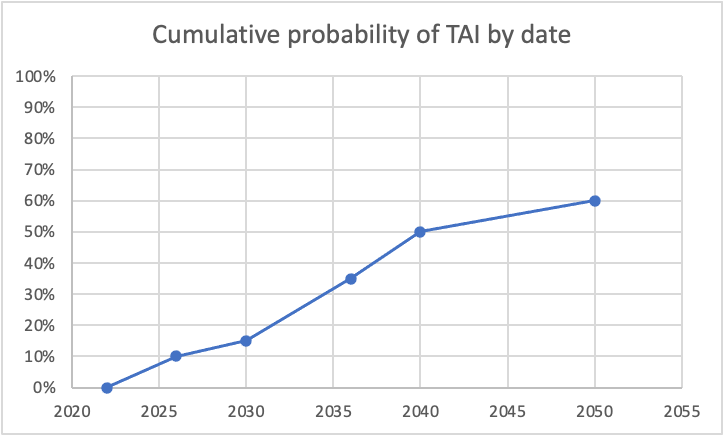
And here's the corresponding probabilities of TAI being developed per specific year: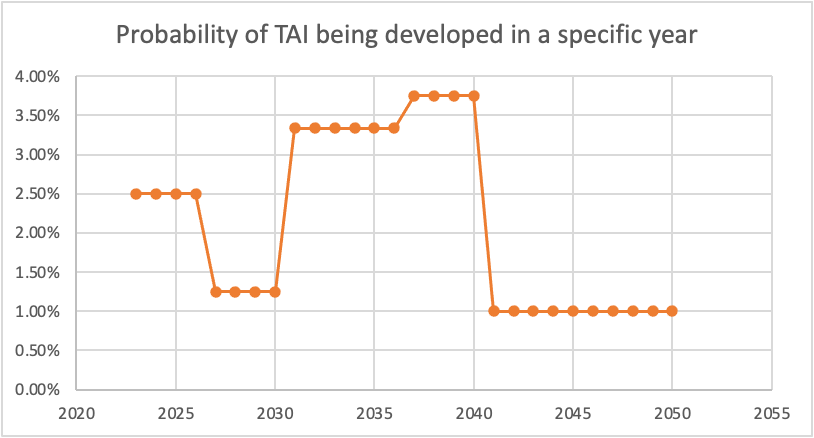
The dip between 2026 and 2030 seems unjustified to me. (I also think the huge drop from 2040-2050 is too aggressive, as even if we expect a plateauing of compute/another AI winter/etc, I don't think we can be super confident exactly when that would happen, but this drop seems more defensible to me than the one in the late 2020s.)
If we instead put 5% for 2026, here's what we get:
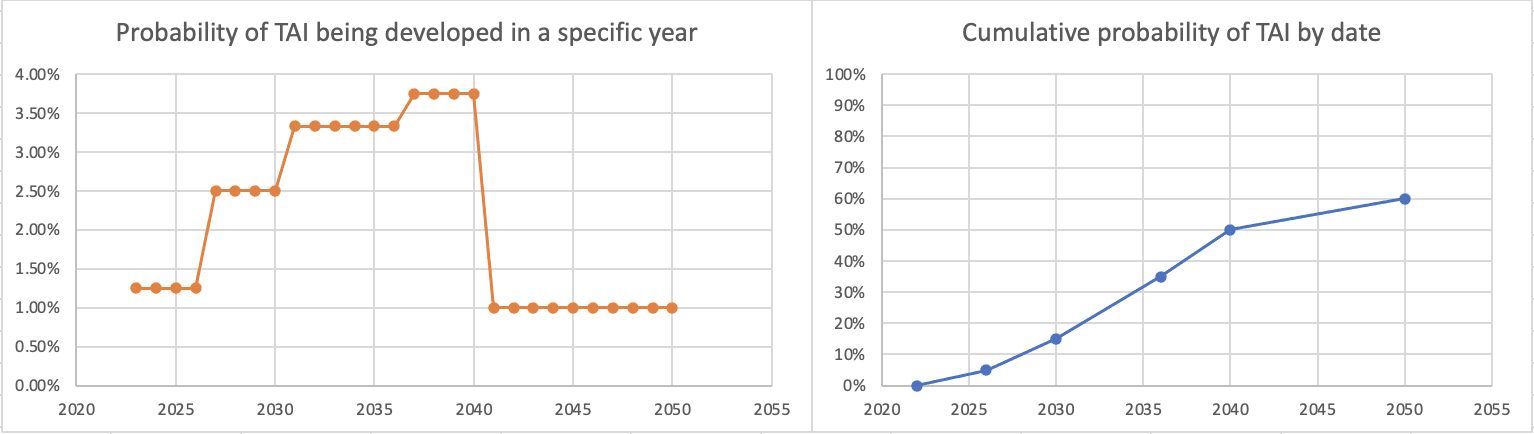
which seems more intuitively defensible to me. I think this difference may be important, as even shift of small numbers of years like this could be action-relevant when we're talking about very short timelines (of course, you could also get something reasonable-seeming by shifting up the probabilities of TAI in the 2026-2030 range).
I'd also like to point out that your probabilities would imply that if TAI is not developed by 2036, there would be an implied 23% conditional chance of it then being developed in the subsequent 4 years ((50%-35%)/(100%-35%)), which also strikes me as quite high from where we're now standing.
Play with GPT-3 for long, and you'll see it fall hard too.
...
This sample is a failure. No one would have written this, not even as satire or surrealism or experimental literature. Taken as a joke, it's a nonsensical one. Taken as a plot for a film, it can't even keep track of who's alive and who's dead. It contains three recognizable genres of writing that would never appear together in this particular way, with no delineations whatsoever.
This sample seems pretty similar to the sort of thing that a human might dream, or that a human might say during/immediately after a stroke, a seizure, or certain types of migraines. It's clear that the AI is failing here, but I'm not sure that humans don't also sometimes fail in somewhat similar ways, or that there's a fundamental limitation here that needs to be overcome in order to reach AGI.
The first time you see it, it surprises you, a crack in the floor... Eventually, you no longer picture of a floor with cracks in it. You picture a roiling chaos which randomly, but regularly, coalesces into ephemeral structures possessing randomly selected subsets of the properties of floors.
^I guess the corollary here would be that human minds may also be roiling chaos which randomly coalesce into ephemeral structures possessing properties of floors, but just are statistically much more likely to do so than current language models.
FWIW, Hanson has elsewhere promoted the idea that algorithmic progress is primarily due to hardware progress. Relevant passage:
Maybe there are always lots of decent ideas for better algorithms, but most are hard to explore because of limited computer hardware. As hardware gets better, more new ideas can be explored, and some of them turn out to improve on the prior best algorithms. This story seems to at least roughly fit what I’ve heard about the process of algorithm design.
So he presumably would endorse the claim that HLMI will likely requires several tens of OOM more compute than we currently have, but that a plateauing in other inputs (such as AI researchers) won't be as relevant. (Here's also another post of Hanson where he endorses a somewhat related claim that we should expect exponential increases in hardware to translate to ~linear social impact and rate of automation.)
I like this comment, though I don't have a clear-eyed view of what sort of research makes (A) or (B) more likely. Is there a concrete agenda here (either that you could link to, or in your head), or is the work more in the exploratory phase?
Yeah, I'm not trying to say that the point is invalid, just that phrasing may give the point more appeal than is warranted from being somewhat in the direction of a deepity. Hmm, I'm not sure what better phrasing would be.
The statement seems almost tautological – couldn't we somewhat similarly claim that we'll understand NNs in roughly the same ways that we understand houses, except where we have reasons to think otherwise? The "except where we have reasons to think otherwise" bit seems to be doing a lot of work.
Also, these physical limits – insofar as they are hard limits – are limits on various aspects of the impressiveness of the technology, but not on the cost of producing the technology. Learning-by-doing, economies of scale, process-engineering R&D, and spillover effects should still allow for costs to come down, even if the technology itself can hardly be improved.
Potentially worth noting that if you add the lifetime anchor to the genome anchor, you most likely get ~the genome anchor.
Igor Babuschkin has also signed it.