All of Donald Hobson's Comments + Replies
The Halting problem is a worst case result. Most agents aren't maximally ambiguous about whether or not they halt. And those that are, well then it depends what the rules are for agents that don't halt.
There are set ups where each agent is using an nonphysically large but finite amount of compute. There was a paper I saw somewhere a while ago where both agents were doing a brute force proof search for the statement "if I cooperate, then they cooperate" and cooperating if they found a proof.
(Ie searching all proofs containing <10^100 symbols)
There is a model of bounded rationality, logical induction.
Can that be used to handle logical counterfactuals?
I believe that if I choose to cooperate, my twin will choose to cooperate with probability p; and if I choose to defect, my twin will defect with probability q;
And here the main difficulty pops up again. There is no causal connection between your choice and their choice. Any correlation is a logical one. So imagine I make a copy of you. But the copying machine isn't perfect. A random 0.001% of neurons are deleted. Also, you know you aren't a copy. How would you calculate that probability p,q? Even in principle.
If two Logical Decision Theory agents with perfect knowledge of each other's source code play prisoners dilemma, theoretically they should cooperate.
LDT uses logical counterfactuals in the decision making.
If the agents are CDT, then logical counterfactuals are not involved.
We can discuss anything that exists, that might exist, that did exist, that could exist, and that could not exist. So no matter what form your predict-the-next-token language model takes, if it is trained over the entire corpus of the written word, the representations it forms will be pretty hard to understand, because the representations encode an entire understanding of the entire world.
Perhaps.
Imagine a huge number of very skilled programmers tried to manually hard code a ChatGPT in python.
Ask this pyGPT to play chess, and it wil...
But if the universal failure of nature and man to find non-connectionist forms of general intelligence does not move you
Firstly, AIXI exists, and we agree that it would be very smart if we had the compute to run it.
Secondly I think there is some sort of slight of had here.
ChatGPT isn't yet fully general. Neither is a 3-sat solver. 3-sat looks somewhat like what you might expect a non-connectionist approach to intelligence to look like. There are a huge range of maths problems that are all theoretically equivalent to 3 sat.
In t...
Physics Myths vs reality.
Myth: Ball bearings are perfect spheres.
Reality: The ball bearings have slight lumps and imperfections due to manufacturing processes.
Myth: Gravity pulls things straight down at 9.8 m/s/s.
Reality: Gravitational force varies depending on local geology.
You can do this for any topic. Everything is approximations. The only question is if they are good approximations.
If AI labs are slamming on the recursive self improvement ASAP, it may be that Autonomous Replicating Agents are irrelevant. But that's a "ARA can't destroy the world if AI labs do it first" argument.
ARA may well have more compute than AI labs. Especially if the AI labs are trying to stay within the law, and the ARA is stealing any money/compute that it can hack it's way into. (Which could be >90% of the internet if it's good at hacking. )
...there will be millions of other (potentially misaligned) models being deployed deliberately by humans, includi
If you can put uploaded human-level agents with evolved-organism preferences in your simulations, you can just win outright (eg by having them spend subjective millennia doing FAI research for you). If you can’t, that will be a very obvious difference between your simulations and the real world.
I disagree. If your simulation is perfectly realistic, the simulated humans might screw up at alignment and create an unfriendly superintelligence, for much the same reason real humans might.
Also, if the space of goals that evolution + culture can...
Taking IID samples can be hard actually. Suppose you train an LLM on news articles. And each important real world event has 10 basically identical news articles written about it. Then a random split of the articles will leave the network being tested mostly on the same newsworthy events that were in the training data.
This leaves it passing the test, even if it's hopeless at predicting new events and can only generate new articles about the same events.
When data duplication is extensive, making a meaningful train/test split is hard.
If the data was perfect copy and paste duplicated, that could be filtered out. But often things are rephrased a bit.
In favour of goal realism
Suppose your looking at an AI that is currently placed in a game of chess.
It has a variety of behaviours. It moves pawns forward in some circumstances. It takes a knight with a bishop in a different circumstance.
You could describe the actions of this AI by producing a giant table of "behaviours". Bishop taking behaviours in this circumstance. Castling behaviour in that circumstance. ...
But there is a more compact way to represent similar predictions. You can say it's trying to win at chess.
The "trying to win...
We can salvage a counting argument. But it needs to be a little subtle. And it's all about the comments, not the code.
Suppose a neural network has 1 megabyte of memory. To slightly oversimplify, lets say it can represent a python file of 1 megabyte.
One option is for the network to store a giant lookup table. Lets say the network needs half a megabyte to store the training data in this table. This leaves the other half free to be any rubbish. Hence around possible networks.
The other option is for the network to implement a simple ...
Yes. I was assuming a standard conditional for the button.
I can't currently see any flaws with the CDT style. Other than.
- Subagents believe in a world where buttons magically press themselves. So this design can't make coherent statements about the probabilty that the button will be pressed. (one AI believes it's 1, the other that it's 0).
- These AI's have no incentive to give humans access to the button. To the AI's, they have a magic button, that might or might not magically press its self. The AI's have a lot of utility bet on that button. Is t
Suppose these 3 scenarios are judged as equally likely.
A) Button pressed. U_1=U_2=0
B) Button not pressed. U_1=U_2=0
C) AI gets control of button. U_1=6, U_2=-6
Suppose both agents agree that in option C, they should press the button. (this is the only 1 bit of influence they have in this toy problem)
Then agent 1 has a "certainty" of B. E(U_1|not pressed)=E(U_1|B)=0
Agent 2 has remaining uncertainty E(U_2|pressed)=1/2(E(U_2|A)+E(U_2|C))=1/2(0+-6)=-3
Change it around, make AI decide not to press the button in case C, and
E(U_1|not pressed)=3, E(U_2|pressed)=0.
Third claim: because both subagents act-as-though the button state is not causally downstream of anything else in the universe, the agent will not attempt to manipulate the button state.
I disagree.
Suppose there is a paperclip lottery, if the AI wins, it gets loads of clips, and it becomes harder to shut down.
The AI has been entered by someone else, not playing isn't an option.
Both subagents imagine a plan to make sure that, if they win, the button isn't pressed.
To the paperclip AI, this is a good deal. The conditional expectation acts as a sort...
Take this set contains exponentially many points. Is there Any function such that all exponentially many xor combos can be found by a linear probe?
This is a question of pure maths, it involves no neural networks. And I think it would be highly informative.
You are making the structure of time into a fundamental part of your agent design, not a contingency of physics.
Let an aput be an input or an output. Let an policy be a subset of possible aputs. Some policies are physically valid.
Ie a policy must have the property that, for each input, there is a single output. If the computer is reversible, the policy must be a bijection from inputs to outputs. If the computer can create a contradiction internally, stopping the timeline, then a policy must be a map from inputs to at most one output.
If the agen...
Suppose Bob is a baker who has made some bread. He can give the bread to Alice, or bin it.
By the ROSE value, Alice should pay $0.01 to Bob for the bread.
How is an honest baker supposed to make a profit like that?
But suppose, before the bread is baked, Bob phones Alice.
"Well the ingredients cost me $1" he says, "how much do you want the bread?"
If Alice knows pre baking that she will definitely want bread, she would commit to paying $1.01 for it, if she valued the bread at at least that much. If Alice has a 50% chance of wanting bread, she could ...
Skimmed the paper. Can't find a clear definition of what this ALU actually measures. So I don't know whether this is impressive or not. (It's too short to be searchable)
EDIT: I now consider this whole approach to be irreparably flawed.
Imagine if their was a 50% chance the button would be pressed. Also the AI was in some betting thing that would pay out paperclips or staples based on a coin flip.
In scenario 1, this AI has an option of setting up a mechanism, external to itself, that controls the coin flip based on if the button is pressed.
In scenario 2, the AI can set up a mechanism to control the button based on the coin flip.
When only considering actions, probabilities and utilities, these look identica...
A few other problems with time bounded agents.
If they are engaged in self modification/ creating successor agents, they have no reason not to create an agent that isn't time bounded.
As soon as there is any uncertainty about what time it is, then they carry on doing things, just in case their clock is wrong.
(How are you designing it? Will it spend forever searching for time travel?)
Note: The absence of a catastrophe is also still hard to specify and will take a lot of effort, but the hardness is concentrated on bridging between high-level human concepts and the causal mechanisms in the world by which an AI system can intervene. For that...
Is the lack of a catastrophe intended to last forever, or only a fixed amount of time (ie 10 years, until turned off)
For all Time.
Say this AI looks to the future, it sees everything disassembled by nanobots. Self replicating bots build computers. Lots of details about how the world was are being rec...
It is important to remember that humans, unlike all other species, are able to use complex language. This is a huge confounding factor, when we try to compare the intelligence of humans and animals. It is obviously very powerful to be able to exchange complex ideas, and build up knowledge intergenerationally. This would probably be enough to give humans a very large advantage, even if our intelligence was otherwise exactly the same as that of other primates.
Communication is an aspect of intelligence. It takes place in the brain not the kidneys. Now y...
First of all, there have been "feral" humans that grew up surrounded by animals. As far as I know, these humans are not obviously much more intelligent than animals (in terms of their ability to solve problems).
Think of that like a modern supercomputer being used to play pong.
(well not that big of a gap, but you get the picture)
Animal brains have a relatively simple and limited range of pieces of software they can run.
Human brains are able to run a much wider range of much more complicated programs.
In other words, human intelligence...
I think the assumptions that.
- Humans realize the AI exists early on.
- Humans are reasonably coordinated and working against the AI.
Are both dubious.
What is stopping someone sending a missile at GPT-4's servers right now.
- OpenAI hasn't anounced a list of coordinated for where those servers are (as far as I know) This is because
- OpenAI doesn't want you to missile strike their servers because
- OpenAI thinks their AI is safe and useful not dangerous.
I think seeing large numbers of humans working in a coordinated fashion against an AI is unlikely.
I think the human level of understanding is a factor, and of some importance. But I strongly suspect the exact level of human understanding is of less importance than exactly what expert we summon.
Yeah, probably. However, note that it can only use this channel if a human has deliberately made an optimization channel that connects in to this process. Ie the AI isn't allowed to invent DNA printers itself.
I think a bigger flaw is where one human decided to make a channel from A to B, another human made a channel from B to C ... until in total there is a channel from A to Z that no human wants and no human knows exists, built entirely out of parts that humans build.
Ie person 1 decides the AI should be able to access the internet. Person 2 decided ...
I am trying to write something that would make sense if I had as solid and mathy idea of "optimization here" as I do with "information here".
Viruses are optimizing their own spread, not killing all humans. This seems to be further optimizing an already highly optimized artifact, not flowing optimization through an optimized channel.
I am not sure, I think it depends on why the AI wants the shockwave. Again, all I have is a fuzzy intuition that says yes in some cases, no in others, and shrugs in a lot of cases. I am trying to figure out if I can get this into formal maths. And if I succeed, I will (probably, unless infohazard or something) describe the formal maths.
Alignment crazy idea. Only run optimization power through channels that have been optimized to convey it.
Like water that flows through pipes, but doesn't escape from leaks.
Suppose the AI is connected to a robot body. The AI can optimize along the wires, and through the motors. Optimization power can flow along these channels because humans deliberately optimized them to be good at conveying optimization power. But the AI can't use row-hammer. Humans didn't deliberately optimize memory modules to be susceptible. They just happen to be because o...
An AI with a 50% chance to output an alignment paper in response to a prompt asking for on can, at worst, loose 1 bit of predictive power for every time that such a prompt appears in the training distribution and isn't followed by a solution.
If it really was generalizing well from the training dataset, it might realize that anything claiming to be from the future is fiction. After all, the AI never saw anything from beyond 2023 (or whenever it's trained) in it's training dataset.
If the AI has this highly sophisticated world model, it will know ...
If we are going to do the "random model chooses each token" trick. First use different quantum random starting weights for each network. Give each network a slightly different selection of layer sizes and training data, and sandbox them from each other.
Which of the 2 places are you most worried about containing mesaoptimizers? The language model or the maths model?
If you are getting proofs out of your system, you want to get a formal proof, as well as a human legible proof. (And get a human to read the formal theorem being proved, if not the proof.)
Decomposed tasky AI's are pretty useful. Given we don't yet know how to build powerful agents, they are better than nothing. This is entirely consistent with a world where, once agenty AI is developed, it beats the pants of tasky AI.
However, unlike in Chess games, humans can and will use all the tools at their disposal, including many tools (e.g., code-completion engines, optimizers for protein folding, etc..) that are currently classified as “Artificial Intelligence”.
Lets suppose that both the human and long term AI have a copy of chatGPT. However, as many of us has found, chatGPT is somewhat fickle, it doesn't reliably do what we actually want it to do. We are having short term, non-catastrophic alignment problems. But they do make the tool significantly less useful.
Does...
A third task listed is “social manipulation.” Here we must admit we are skeptical. Anyone who has ever tried to convince a dog to part with a bone or a child with a toy could attest to the diminishing returns that an intelligence advantage has in such a situation.
Try convincing a rock to do something by arguing with it. The rock remains supremely unconvinced. You are much smarter than a rock.
In order to be convinced to do something, there needs to be sufficient complex structure to be capable of being convinced. This is the same reas...
The “loss of control” scenario posits a second phase transition, whereby once AI systems become more powerful, they would not merely enable humans to achieve more objectives quicker but would themselves become as qualitatively superior to humans as humans are to other animals.
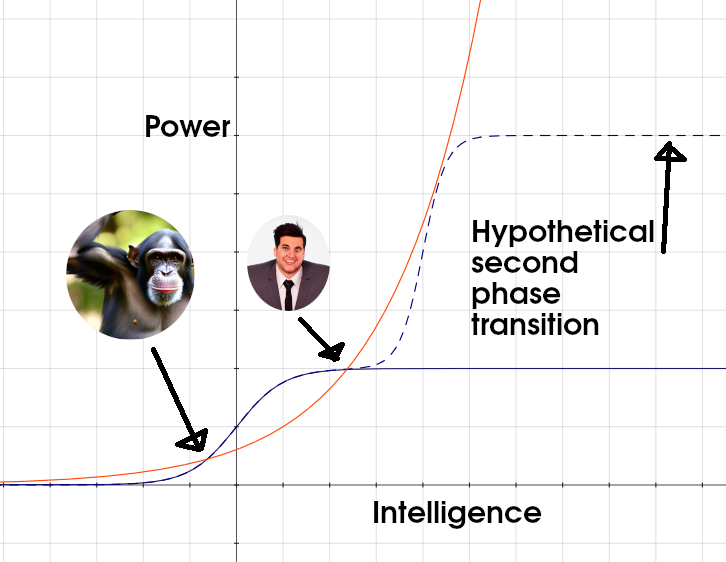
I think you are imagining the first blue line, and asking the dotted blue line to justify its increased complexity penalty. Meanwhile, other people are imagining the orange line.
Indeed, our societies and firms do not currently select our leaders to be the top individuals in intellectual capacity. The evidence is very limited that “natural talent for leadership” (to the extent it exists) is as measurable and transferable as talent for chess, math, or athletics.
It is over longer timescales, and is harder to give uniform starting conditions, so of course it's harder to measure.
This leads to the inadequate equilibrium. But lying your backside off to voters and shareholders is also an intellectual skill of sorts. It's a mistake t...
Ever since the development of language, the intelligence of an individual human has not been a bottleneck for the achievements of humanity.
A surprising claim.
...The brilliance of individuals like Newton may have been crucial for speeding up the Scientific Revolution, but there have been brilliant individuals for millennia. The crucial difference between Newton and Archimedes is not that Newton was smarter, but rather that he lived at a later time and thus was able to stand on the shoulders of more giants. As another example, a collection of humans,
Given a sufficiently Kludgy pile of heuristics, it won't make another AI, unless it has a heuristic towards making AI. (In which case the kind of AI it makes depend on its AI making heuristics. ) GPT5 won't code an AI to minimize predictive error on text. It will code some random AI that looks like something in the training dataset. And will care more about what the variable names are than what the AI actually does.
Big piles of kludges usually arise from training a kludge finding algorithm (like deep learning). So the only ways agents could get AI building...
Epistemic status: Highly speculative hypothesis generation.
I had a similar, but slightly different picture. My picture was the tentacle covered blob.

When doing gradient descent from a random point, you usually get to a tentacle. (Ie the red trajectory)
When the system has been running for a while, it is randomly sampling from the black region. Most of the volume is in the blob. (The randomly wandering particle can easily find its way from the tentacle to the blob, but the chance of it randomly finding the end of a tentacle from within the blob is smal...
I think each little decision is throwing another few bits of info. A few bits for deciding how big the mantisa and exponent should be. A few bits for it being a 64 bit float. A few bits for subnormals. A few bits for inf and Nan. A few bits for rounding errors. A bit for -0. And it all adds up. Not that we know how many bits the AI needs. If there is one standard computer architecture that all aliens use, then the AI can hack with very little info. If all alien computers have wildly different architectures, then floats carry a fair bit of info.
Sure, binary is fairly natural, but there are a lot of details of IEEE floats that aren't. https://en.wikipedia.org/wiki/Subnormal_number
Deterministic (but complicated) code can leak info about processor architecture.
Firstly even simple integer overflow and floating point precision indicate being on a 32 or 64 bit based system.
Suppose you have a sum function. And this function sums a list by getting each of the 8 cores to add up 1/8th of the list, and then combining the results. The floating point roundoff errors reveal this internal structure.
Add some other things like that, and it is now possible for your AI to guess your computer architecture. Is this enough to guess wh...
What does the network do if you use SVD editing to knock out every uninterpretable column? What if you knock out everything interpretable?
(If you can't see why a single modern society locking in their current values would be a tragedy of enormous proportions, imagine an ancient civilization such as the Romans locking in their specific morals 2000 years ago. Moral progress is real, and important.)
This really doesn't prove anything. That measurement shouldn't be taken by our values, but by the values of the ancient romans.
Sure of course the morality of the past gets better and better. It's taking a random walk closer and closer to our morality. Now moral progress might be real.
The ...
My best guess bio anchors adaption suggests a median estimate for the availability of compute to train TAI
My best guess is in the past. I think GPT3 levels of compute and data are sufficient, with the right algorithm, to make a superhuman AI.
Loose analogy based reasoning over complex and poorly understood systems isn't reliable. There is kind of only one way for GPT-n to be identical to system 1, and many ways for it to be kind of similar, in a way that is easy to anthropomorphize, but has some subtle alien features.
GPTn contains some data from smart and/or evil humans and humans speaking in riddles or making allusions. Lets suppose this generalizes, and now GPTn is pretending to be an IQ200 cartoon villain, with an evil plot described entirely in terms of references to obscure sources. ...
This current version is dumb, but still exerts some optimization pressure. (Just the bits of optimization out are at most the bits of selection put into its utility function.)
I have strong doubts this is actually any help. Ok, maybe the AI comes up with new simpler math. It's still new math that will take the humans a while to get used to. There will probably be lots of options to add performance and complexity. So either we are banning the extra complexity, using our advanced understanding, and just using the simpler math at the cost of performance, or the AI soon gets complex again before humans have understood the simple math.
Well I ask what they are doing to make AGI.
Maybe I look at their AI plan and go "eurika".
But if not.
Negative reinforcement by giving the AI large electric shocks when it gives a wrong answer. Hopefully big enough shocks to set the whole data center on fire. Implement a free bar for all their programmers, and encourage them to code while drunk. Add as many inscrutable bugs to the codebase as poss... (read more)