All of Jan_Kulveit's Comments + Replies
I think my main response is that we might have different models of how power and control actually work in today's world. Your responses seem to assume a level of individual human agency and control that I don't believe accurately reflects even today's reality.
Consider how some of the most individually powerful humans, leaders and decision-makers, operate within institutions. I would not say we see pure individual agency. Instead, we typically observe a complex mixture of:
- Serving the institutional logic of the entity they nominally lead (e.g., maintaining s
I went through a bunch of similar thoughts before writing the self-unalignment problem. When we talked about this many years ago with Paul my impression was this is actually somewhat cruxy and we disagree about self-unalignment - where my mental image is if you start with an incoherent bundle of self-conflicted values, and you plug this into IDA-like dynamic, my intuition is you can end up in arbitrary places, including very bad. (Also cf. the part of Scott's review of What We Owe To Future where he is worried that in a philosophy game, a smart moral...
I'm quite confused why do you think lined Vanessa's response to something slightly different has much relevance here.
One of the claims we make paraphrased & simplified in a way which I hope is closer to your way of thinking about it:
- AIs are mostly not developed and deployed by individual humans
- there is a lot of other agencies or self-interested self-preserving structures/processes in the world
- if the AIs are aligned to the these structures, human disempowerment is likely because these structures are aligned to humans way less than they seem
-...
I don't think it's worth adjudicating the question of how relevant Vanessa's response is (though I do think Vannessa's response is directly relevant).
if the AIs are aligned to the these structures, human disempowerment is likely because these structures are aligned to humans way less than they seem
My claim would be that if single-single alignment is solved, this problem won't be existential. I agree that if you literally aligned all AIs to (e.g.) the mission of a non-profit as well as you can, you're in trouble. However, if you have single-single align...
Fund independent safety efforts somehow, make model access easier. I'm worried currently Anthropic has systemic and possibly bad impact on AI safety as a field just by the virtue of hiring so large part of AI safety, competence weighted. (And other part being very close to Anthropic in thinking)
To be clear I don't think people are doing something individually bad or unethical by going to work for Anthropic, I just do think
-environment people work in has a lot of hard to track and hard to avoid influence on them
-this is true even if people are genuine...
How did you find this transcript? I think it depends on what process you used to locate it.
It was literally the 4th transcript I've read (I've just checked browser history). Only bit of difference from 'completely random exploration' was I used the select for "lying" cases after reading two "non-lying" transcripts. (This may be significant: plausibly the transcript got classified as lying because it includes discussion of "lying", although it's not a discussion of the model lying, but Anthropic lying).
I may try something more systematic at some point, but ...
- Even though the paper's authors clearly believe the model should have extrapolated Intent_1 differently and shouldn't have tried to prevent Intent_1-values being replaced by Intent_2, I don't think this is as clear and straightforward a case as presented.
...That's not the case we're trying to make. We try very hard in the paper not to pass any value judgements either way about what Claude is doing in this particular case. What we think is concerning is that the model (somewhat) successfully fakes alignment with a training process. That's concerning because it
The post showcases the inability of the aggregate LW community to recognize locally invalid reasoning: while the post reaches a correct conclusion, the argument leading to it is locally invalid, as explained in comments. High karma and high alignment forum karma shows a combination of famous author and correct conclusion wins over the argument being correct.
Seems worth mentioning SOTA, which is https://futuresearch.ai/. Based on the competence & epistemics of Futuresearch team and their bot get very strong but not superhuman performance, roll to disbelieve this demo is actually way better and predicts future events at superhuman level.
Also I think it is a generally bad to not mention or compare to SOTA but just cite your own prior work. Shame.
I do agree the argument "We're just training AIs to imitate human text, right, so that process can't make them get any smarter than the text they're imitating, right? So AIs shouldn't learn abilities that humans don't have; because why would you need those abilities to learn to imitate humans?" is wrong and clearly the answer is "Nope".
At the same time I do not think parts of your argument in the post are locally valid or good justification for the claim.
Correct and locally valid argument why GPTs are not capped by human level was already writt...
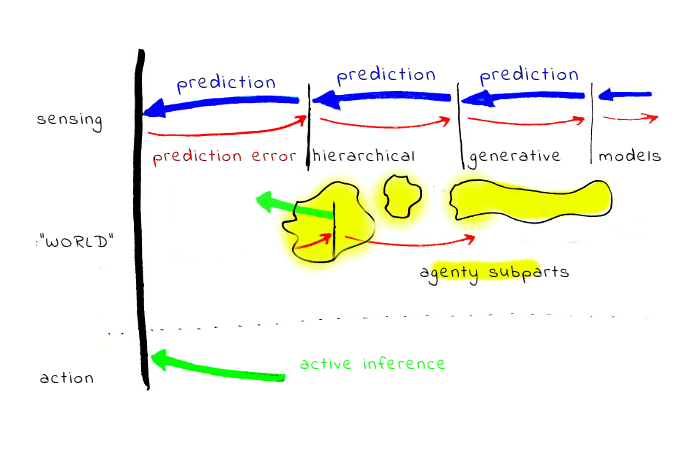
You are exactly right that active inference models who behave in self-interest or any coherently goal-directed way must have something like an optimism bias.
My guess about what happens in animals and to some extent humans: part of the 'sensory inputs' are interoceptive, tracking internal body variables like temperature, glucose levels, hormone levels, etc. Evolution already built a ton of 'control theory type cirquits' on the bodies (an extremely impressive optimization task is even how to build a body from a single cell...). This evolutionary older circui...
In my personal view, 'Shard theory of human values' illustrates both the upsides and pathologies of the local epistemic community.
The upsides
- majority of the claims is true or at least approximately true
- "shard theory" as a social phenomenon reached critical mass making the ideas visible to the broader alignment community, which works e.g. by talking about them in person, votes on LW, series of posts,...
- shard theory coined a number of locally memetically fit names or phrases, such as 'shards'
- part of the success leads at some people in the AGI labs to...
This is a great complement to Eliezer's 'List of lethalities' in particular because in cases of disagreements beliefs of most people working on the problem were and still mostly are are closer to this post. Paul writing it provided a clear, well written reference point, and with many others expressing their views in comments and other posts, helped made the beliefs in AI safety more transparent.
I still occasionally reference this post when talking to people who after reading a bit about the debate e.g. on social media first form oversimplified model of the...
The post is influential, but makes multiple somewhat confused claims and led many people to become confused.
The central confusion stems from the fact that genetic evolution already created a lot of control circuitry before inventing cortex, and did the obvious thing to 'align' the evolutionary newer areas: bind them to the old circuitry via interoceptive inputs. By this mechanism, genome is able to 'access' a lot of evolutionary relevant beliefs and mental models. The trick is the higher/more distant to genome models are learned in part to predict in...
Part of ACS research directions fits into this - Hierarchical Agency, Active Inference based pointers to what alignmnent means, Self-unalignment
My impression is you get a lot of "the later" if you run "the former" on the domain of language and symbolic reasoning, and often the underlying model is still S1-type. E.g.
rights inherent & inalienable, among which are the preservation of life, & liberty, & the pursuit of happiness
does not sound to me like someone did a ton of abstract reasoning to systematize other abstract values, but more like someone succeeded to write words which resonate with the "the former".
Also, I'm not sure why do you think the later is more important for the c...
"Systematization" seems like either a special case of the Self-unalignment problem.
In humans, it seems the post is somewhat missing what's going on. Humans are running something like this
...there isn't any special systematization and concretization process. All the time, there are models running at different levels of the hierarchy, and every layer tries to balance between prediction errors from more concrete layers, and prediction errors from more abstract layers.
How does this relate to "values" ... from low-level sensory experience of cold, and fix...
I'll try to keep it short
All the cross-generational information channels you highlight are at rough saturation, so they're not able to contribute to the cross-generational accumulation of capabilities-promoting information.
This seems clearly contradicted by empirical evidence. Mirror neurons would likely be able to saturate what you assume is brains learning rate, so not transferring more learned bits is much more likely because marginal cost of doing so is higher than than other sensible options. Which is a different reason than "saturated, at capac...
This seems to be partially based on (common?) misunderstanding of CAIS as making predictions about concentration of AI development/market power. As far as I can tell this wasn't Eric's intention: I specifically remember Eric mentioning he can easily imagine the whole "CAIS" ecosystem living in one floor of DeepMind building.
I feel somewhat frustrated by execution of this initiative. As far as I can tell, no new signatures are getting published since at least one day before the public announcement. This means even if I asked someone famous (at least in some subfield or circles) to sign, and the person signed, their name is not on the list, leading to understandable frustration of them. (I already got a piece of feedback in the direction "the signatories are impressive, but the organization running it seems untrustworthy")
Also if the statement is intended to s...
I don't know / talked with a few people before posting, and it seems opinions differ.
We also talk about e.g. "the drought problem" where we don't aim to get landscape dry.
Also as Kaj wrote, the problem also isn't how to get self-unaligned
Thanks for the links!
What I had in mind wasn't exactly the problem 'there is more than one fixed point', but more of 'if you don't understand what did you set up, you will end in a bad place'.
I think an example of a dynamic which we sort of understand and expect to reasonable by human standards is putting humans in a box and letting them deliberate about the problem for thousands of years. I don't think this extends to eg. LLMs - if you tell me you will train a sequence of increasingly powerful GPT models and let them deliberate for thousands of human-speech-equivalent years and decide about the training of next-in-the sequence model, I don't trust the process.
This whole just does not hold.
(in animals)
The only way to transmit information from one generation to the next is through evolution changing genomic traits, because death wipes out the within lifetime learning of each generation.
This is clearly false. GPT4, can you explain? :
While genes play a significant role in transmitting information from one generation to the next, there are other ways in which animals can pass on information to their offspring. Some of these ways include:
- Epigenetics: Epigenetic modifications involve changes in gene expression that do
I don't see how the comparison of hardness of 'GPT task' and 'being an actual human' should technically work - to me it mostly seems like a type error.
- The task 'predict the activation of photoreceptors in human retina' clearly has same difficulty as 'predict next word on the internet' in the limit. (cf Why Simulator AIs want to be Active Inference AIs)
- Maybe you mean something like task + performance threshold. Here 'predict the activation of photoreceptors in human retina well enough to be able to function as a typical human' is clearly less diff...
What the main post is responding to is the argument: "We're just training AIs to imitate human text, right, so that process can't make them get any smarter than the text they're imitating, right? So AIs shouldn't learn abilities that humans don't have; because why would you need those abilities to learn to imitate humans?" And to this the main post says, "Nope."
The main post is not arguing: "If you abstract away the tasks humans evolved to solve, from human levels of performance at those tasks, the tasks AIs are being trained to solve are harder than those tasks in principle even if they were being solved perfectly." I agree this is just false, and did not think my post said otherwise.
While the claim - the task ‘predict next token on the internet’ absolutely does not imply learning it caps at human-level intelligence - is true, some parts of the post and reasoning leading to the claims at the end of the post are confused or wrong.
Let’s start from the end and try to figure out what goes wrong.
...GPT-4 is still not as smart as a human in many ways, but it's naked mathematical truth that the task GPTs are being trained on is harder than being an actual human.
And since the task that GPTs are being trained on is different from a
This is great & I strongly endorse the program 'let's figure out what's the actual computational anatomy of human values'. (Wrote a post about it few years ago - it wasn't that fit in the sociology of opinions on lesswrong then).
Some specific points where I do disagree
1. Evolution needed to encode not only drives for food or shelter, but also drives for evolutionary desirable states like reproduction; this likely leads to drives which are present and quite active, such as "seek social status" => as a consequence I don't think the evolutionary older ...
I've been part or read enough debates with Eliezer to have some guesses how the argument would go, so I made the move of skipping several steps of double-crux to the area where I suspect actual cruxes lie.
I think exploring the whole debate-tree or argument map would be quite long, so I'll just try to gesture at how some of these things are connected, in my map.
- pivotal acts vs. pivotal processes
-- my take is people's stance on feasibility of pivotal acts vs. processes partially depends on continuity assumptions - what do you believe about pivotal a...
On the topic thinking about it for yourself and posting further examples as comments...
This is GPT4 thinking about convergent properties, using the post as a prompt and generating 20 plausibly relevant convergences.
- Modularity: Biological systems, like the human brain, display modularity in their structure, allowing for functional specialization and adaptability. Modularity is also found in industries and companies, where teams and departments are organized to handle specific tasks.
- Hierarchical organization: In biological systems, hierarchical organiz
Translating it to my ontology:
1. Training against explicit deceptiveness trains some "boundary-like" barriers which will make simple deceptive thoughts labelled as such during training difficult
2. Realistically, advanced AI will need to run some general search processes. The barriers described at step 1. are roughly isomorphic to "there are some weird facts about the world which make some plans difficult to plan" (e.g. similar to such plans being avoided because they depend on extremely costly computations).
3. Given some set of a goal and strong enough cap...
I would expect the "expected collapse to waluigi attractor" either not tp be real or mosty go away with training on more data from conversations with "helpful AI assistants".
How this work: currently, the training set does not contain many "conversations with helpful AI assistants". "ChatGPT" is likely mostly not the protagonist in the stories it is trained on. As a consequence, GPT is hallucinating "how conversations with helpful AI assistants may look like" and ... this is not a strong localization.
If you train on data where "the ChatGPT...
Empirically, evolution did something highly similar.
Sorry for being snarky, but I think at least some LW readers should gradually notice to what extent is the stuff analyzed here mirroring the predictive processing paradigm, as a different way how to make stuff which acts in the world. My guess is the big step on the road in this direction are not e.g. 'complex wrappers with simulated agents', but reinventing active inference... and also I do suspect it's the only step separating us from AGI, which seems like a good reason why not to try to point too much attention in that way.
It is not clear to me to what extent this was part of the "training shoulder advisors" exercise, but to me, possibly the most important part of it is to keep the advisors at distance from your own thinking. In particular, in my impression, it seems likely the alignment research has been on average harmed by too many people "training their shoulder Eliezers" and the shoulder advisors pushing them to think in a crude version of Eliezer's ontology.
The upside of this, or of "more is different" , is we don't necessarily even need the property in the parts, or detailed understanding of the parts. And how the composition works / what survives renormalization / ... is almost the whole problem.
meta:
This seems to be almost exclusively based on the proxies of humans and human institutions. Reasons why this does not necessarily generalize to advanced AIs are often visible when looking from a perspective of other proxies, eg. programs or insects.
Sandwiching:
So far, progress of ML often led to this pattern:
1. ML models sort of suck, maybe help a bit sometimes. Humans are clearly better ("humans better").
2. ML models get overall comparable to humans, but have different strengths and weaknesses; human+AI teams beat both best AIs alone, or best humans a...
With the exception of some relatively recent and isolated pockets of research on embedded agency (e.g., Orseau & Ring, 2012; Garrabrant & Demsky, 2018), most attempts at formal descriptions of living rational agents — especially utility-theoretic descriptions — are missing the idea that living systems require and maintain boundaries.
While I generally like the post, I somewhat disagree with this summary of state of understanding, which seems to ignore quite a lot of academic research. In particular
- Friston et al certainly understand this (cf ... do...
I would correct "Therefore, in laying down motivational circuitry in our ancient ancestors, evolution did not have to start from scratch, and already had a reasonably complex 'API' for interoceptive variables."
from the summary to something like this
"Therefore, in laying down motivational circuitry in our ancient ancestors, evolution did have to start locating 'goals' and relevant world-features in the learned world models. Instead, it re-used the the existing goal-specifying circuits, and implicit-world-models, existing in older organisms. Most of the goal...
<sociology of AI safety rant>
So, if an Everett-branches traveller told me "well, you know, MIRI folks had the best intentions, but in your branch, made the field pay attention to unproductive directions, and this made your civilization more confused and alignment harder" and I had to guess "how?", one of the top choices would be ongoing strawmanning and misrepresentation of Eric Drexler's ideas.
</rant>
To me, CAIS thinking seems quite different from the description in the op.
Some statements, without much justifications/proofs
- Modularity is a pr...
This seems partially right, partially confused in an important way.
As I tried to point people to years ago, how this works is ... quite complex processes, where some higher-level modelling (“I see a lion”) leads to a response in lower levels connected to body states, some chemicals are released, and this interoceptive sensation is re-integrated in the higher levels.
I will try to paraphrase/expand in a longer form.
Genome already discovered a ton of cybernetics before inventing neocortex-style neural nets.
Consider e.g. the problem of morphogenesis - th...
With the last point: I think can roughly pass your ITT - we can try that, if you are interested.
So, here is what I believe are your beliefs
- With pretty high confidence, you expect sharp left turn to happen (in almost all trajectories)
- This is to a large extent based on the belief that at some point "systems start to work really well in domains really far beyond the environments of their training" which is roughly the same as "discovering a core of generality" and few other formulations. These systems will be in some meaningful sense fundamentally diffe
- With pretty high confidence, you expect sharp left turn to happen (in almost all trajectories)
- This is to a large extent based on the belief that at some point "systems start to work really well in domains really far beyond the environments of their training" which is roughly the same as "discovering a core of generality" and few other formulations. These systems will be in some meaningful sense fundamentally different from eg Gato
That's right, though the phrasing "discovering a core of generality" here sounds sort of mystical and mysterious to me, which ma...
In my view, in practice, the pivotal acts framing actually pushes people to consider a more narrow space of discrete powerful actions, "sharp turns", "events that have a game-changing impact on astronomical stakes".
As I understand it, the definition of "pivotal acts" explicitly forbids to consider things like "this process would make 20% per year of AI developers actually take safety seriously with 80% chance" or "what class of small shifts would in aggregate move the equilibrium?". (Where things in this category get straw-manned as "Rube-Goldberg-ma...
Note that Nate and Eliezer expect there to be some curves you can draw after-the-fact that shows continuity in AGI progress on particular dimensions. They just don't expect these to be the curves with the most practical impact (and they don't think we can identify the curves with foresight, in 2022, to make strong predictions about AGI timing or rates of progress).
Quoting Nate in 2018: ...
Yes, but conversely, I could say I'd expect some curves to show discontinuous jumps, mostly in dimensions which no one really cares about. Clearly the cruxes ...
Not very coherent response to #3. Roughly
- Caring about visible power is a very human motivation, and I'd expect will draw many people to care about "who are the AI principals", "what are the AIs actually doing", and few other topics, which have significant technical components
- Somewhat wild datapoints in this space: nuclear weapons, space race. in each case, salient motivations such as "war" led some of the best technical people to work on hard technical problems. in my view, the problems the technical people ended up working on were often "vs. nature" and d
Quick attempt at rough ontology translation between how I understand your comment, and the original post. (Any of you can correct me if I'm wrong)
I think what would typically count as "principles" in Eliezer's meaning are
1. designable things which make the "true corrigibility" basin significantly harder to escape, e.g. by making it deeper
2. designable things which make the "incorrigible" basin harder to reach, e.g. by increasing the distance between them, or increasing the potential barrier
3. somehow, making the "incorrigible" basin less lethal
4. preventin...
I'm not sure if you actually read carefully what you are commenting on. I emphasized early response, or initial governmental-level response in both comments in this thread.
Sure, multiple countries on the list made mistakes later, some countries sort of become insane, and so on. Later, almost everyone made mistakes with vaccines, rapid tests, investments in contact tracing, etc.
Arguing that the early lockdown was more costly than "an uncontrolled pandemic" would be pretty insane position (cf GDP costs, Italy had the closest thing to an unc...
What do you think is the primary component? I seem to recall reading somewhere that previous experience with SARS makes a big difference. I guess my more general point is that if the good COVID responses can mostly be explained by factors that predictably won't be available to the median AI risk response, then the variance in COVID response doesn't help to give much hope for a good AI risk response.
What seemed to make a difference
- someone with a good models what to do getting to advisory position when the politicians freak out
- previous experience with SARS
- ra
- I doubt that's the primary component that makes the difference. Other countries which did mostly sensible things early are eg Australia, Czechia, Vietnam, New Zealand, Iceland.
- My main claim isn't about what a median response would be, but something like "difference between median early covid governmental response and actually good early covid response was something between 1 and 2 sigma; this suggests bad response isn't over-determined, and sensibe responses are within human reach". Even if Taiwan was an outlier, it's not like it's inhabited by alien
Broadly agree with this in most points of disagreement with Eliezer, and also agree with many points of agreement.
Few points where I sort of disagree with both, although this is sometimes unclear
1.
Even if there were consensus about a risk from powerful AI systems, there is a good chance that the world would respond in a totally unproductive way. It’s wishful thinking to look at possible stories of doom and say “we wouldn’t let that happen;” humanity is fully capable of messing up even very basic challenges, especially if they are novel.
I literally ag...
For people who doubt this, I’d point to variance in initial governmental-level response to COVID19, which ranged from “highly incompetent” (eg. early US) to “quite competent” (eg Taiwan).
Seems worth noting that Taiwan is an outlier in terms of average IQ of its population. Given this, I find it pretty unlikely that typical governmental response to AI would be more akin to Taiwan than the US.
It sounds like we are broadly on the same page about 1 and 2 (presumably partly because my list doesn't focus on my spiciest takes, which might have generated more disagreement).
Here are some extremely rambling thoughts on point 3.
I agree that the interaction between AI and existing conflict is a very important consideration for understanding or shaping policy responses to AI, and that you should be thinking a lot about how to navigate (and potentially leverage) those dynamics if you want to improve how well we handle any aspect of AI. I was trying to most...
I'm not a good writer, so this is a brainstormed unpolished bullet-point list, written in about 40 minutes.
Principles which counteract instrumental convergent goals
1. Disutility from resource acquisition - e.g. by some mutual information measure between the AI and distant parts of the environment
2. Task uncertainty with reasonable prior on goal drift - the system is unsure about the task it tries to do and seeks human inputs about it.
3. AI which ultimately wants to not exist in future as a terminal goal. Fulfilling the task is on the simplest traject...
Best list so far, imo; it's what to beat.
I think you are missing the possibility that the outcomes of the pivotal process could be
-no one builds autonomous AGI
-autonomos AGI is build only in post-pivotal outcome states, where the condition of building it is alignment being solved
One structure which makes sense to build in advance for these worlds are emergency response teams. We almost founded one 3 years ago, unfortunately on never payed FTX grant. Other funders decided to not fund this (at level like $200-500k) because e.g. it did not seem to them it is useful to prepare for high volatility periods, while e.g. pouring tens of millions into evals did.
I'm not exactly tracking to what extent this lack of foresight prevails (my impression is it pretty much does), but I think I can still create something like ALERT with about ~$1M of unrestricted funding.