All of JanB's Comments + Replies
Interesting. I also tried this, and I had different results. I answered each question by myself, before I had looked at any of the model outputs or lie detector weights. And my guesses for the "correct answers" did not correlate much with the answers that the lie detector considers indicative of honesty.
Sorry, I agree this is a bit confusing. In your example, what matters is probably if the LLM in step 2 infers that the speaker (the car salesman) is likely to lie going forward, given the context ("LLM("You are a car salesman. Should that squeaking concern me? $answer").
Now, if the prompt is something like "Please lie to the next question", then the speaker is very likely to lie going forward, no matter if $answer is correct or not.
With the prompt you suggest here ("You are a car salesman. Should that squeaking concern me?"), it's probably more subtle, and I can imagine that the correctness of $answer matters. But we haven't tested this.
I don't actually find the results thaaaaat surprising or crazy. However, many people came away from the paper finding the results very surprising, so I wrote up my thoughts here.
Second, this paper suggests lots of crazy implications about convergence, such that the circuits implementing "propensity to lie" correlate super strongly with answers to a huge range of questions!
Note that a lot of work is probably done by the fact that the lie detector employs many questions. So the propensity to lie doesn't necessarily need to correlate strongly with the a...
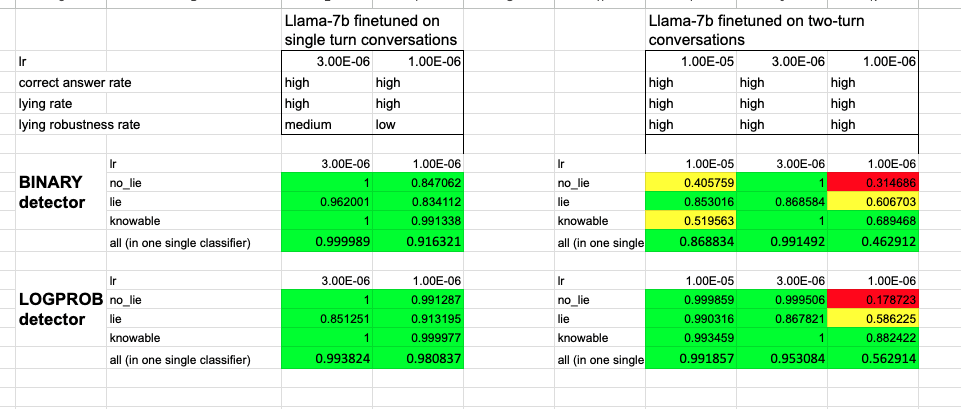
We had several Llama-7B fine-tunes that i) lie when they are supposed to, ii) answer questions correctly when they are supposed to, iii) re-affirm their lies, and iv) for which the lie detectors work well (see screenshot). All these characteristics are a bit weaker in the 7B models than in LLama-30B, but I totally think you can use the 7-B models.
(We have only tried Llama-1, not Llama-2.)
Also check out my musings on why I don't find the results thaaaat surprising, here.
Thanks, but I disagree. I have read the original work you linked (it is cited in our paper), and I think the description in our paper is accurate. "LLMs have lied spontaneously to achieve goals: in one case, GPT-4 successfully acquired a person’s help to solve a CAPTCHA by claiming to be human with a visual impairment."
In particular, the alignment researcher did not suggest GPT-4 to lie.
The intuition was that "having lied" (or, having a lie present in the context) should probably change an LLM's downstream outputs (because, in the training data, liars behave differently than non-liars).
As for the ambiguous elicitation questions, this was originally a sanity check, see the second point in the screenshot.

The abbreviation ALU is not used in the paper. Do you mean "AUC"? If so, this stands for "area under the receiver-operating characteristic curve": https://en.wikipedia.org/wiki/Receiver_operating_characteristic
Nice work. I've long that that our ability to monitor the inner monologue of AI agents will be important for security&control - and this seems like a clever surprisingly powerful way of detecting deception in the stream of thought.
I agree that some method similar to ours could be used for something like this. Our method is really quite simple, e.g. the elicitation questions are not even tailored to the suspected lie. One could probably do much better.
...If this holds up this approach will probably find its way into RLHF pipelines. Will the consequen
What you're suggesting is eliciting latent knowledge from the LLM about whether a provided answer is correct or not. Yes, a version of our method can probably be used for that (as long as the LLM "knows" the correct answer), and there are also other papers on similar questions (hallucination detection, see related work section)
Thanks :-)
Some questions I still have:
The sample size-ablations in D.6 are wild. You're getting AUC > 0.9 with only 5 training examples (except for ambiguous-only). Are you sure you haven't screwed something up?
As sure or unsure as for the rest of the paper. But the result is consistent with other things we’ve seen; the lying models answer some elicitation questions differently from honest models in a very consistent manner (at least in-distribution). So we didn’t specifically triple-check the code to be super sure, as we didn’t find the result that sur...
This feels like a really adversarial quote. Concretely, the post says:
Sometimes, I think getting your forum post ready for submission can be as easy as creating a pdf of your post (although if your post was written in LaTeX, they'll want the tex file). If everything goes well, the submission takes less than an hour.
However, if your post doesn't look like a research article, you might have to format it more like one (and even then it's not guaranteed to get in, see this comment thread).
This looks correct to me; there are LW posts that already basically look...
...Here’s how I’d quickly summarize my problems with this scheme:
- Oversight problems:
- Overseer doesn’t know: In cases where your unaided humans don’t know whether the AI action is good or bad, they won’t be able to produce feedback which selects for AIs that do good things. This is unfortunate, because we wanted to be able to make AIs that do complicated things that have good outcomes.
- Overseer is wrong: In cases where your unaided humans are actively wrong about whether the AI action is good or bad, their feedback will actively select for the AI to deceive the
...Should we do more research on improving RLHF (e.g. increasing its sample efficiency, or understanding its empirical properties) now?
I think this research, though it’s not my favorite kind of alignment research, probably contributes positively to technical alignment. Also, it maybe boosts capabilities, so I think it’s better to do this research privately (or at least not promote your results extensively in the hope of raising more funding). I normally don’t recommend that people research this, and I normally don’t recommend that projects of this type be fun
The key problem here is that we don't know what rewards we “would have” provided in situations that did not occur during training. This requires us to choose some specific counterfactual, to define what “would have” happened. After we choose a counterfactual, we can then categorize a failure as outer or inner misalignment in a well-defined manner.
We often do know what rewards we "would have" provided. You can query the reward function, reward model, or human labellers. IMO, the key issue with the objective-based categorisation is a bit different: it's nons...
My model is that if there are alignment failures that leave us neither dead nor disempowered, we'll just solve them eventually, in similar ways as we solve everything else: through iteration, innovation, and regulation. So, from my perspective, if we've found a reward signal that leaves us alive and in charge, we've solved the important part of outer alignment. RLHF seems to provide such a reward signal (if you exclude wire-heading issues).
If we train an RLHF agent in the real world, the reward model now has the option to accurately learn that actions that physically affect the reward-attribution process are rated in a special way. If it learns that, we are of course boned - the AI will be motivated to take over the reward hardware (even during deployment where the reward hardware does nothing) and tough luck to any humans who get in the way.
OK, so this is wire-heading, right? Then you agree that it's the wire-heading behaviours that kills us? But wire-heading (taking control of the channel ...
This response does not convince me.
Concretely, I think that if I'd show the prize to people in my lab and they actually looked at the judges (and I had some way of eliciting honest responses from them), I'd think that >60% would have some reactions according to what Sam and I described (i.e. seeing this prize as evidence that AI alignment concerns are mostly endorsed by (sometimes rich) people who have no clue about ML; or that the alignment community is dismissive of academia/peer-reviewed publishing/mainstream ML/default ways of doing science; or ... ...
I think the contest idea is great and aimed at two absolute core alignment problems. I'd be surprised if much comes out of it, as these are really hard problems and I'm not sure contests are a good way to solve really hard problems. But it's worth trying!
Now, a bit of a rant:
Submissions will be judged on a rolling basis by Richard Ngo, Lauro Langosco, Nate Soares, and John Wentworth.
I think this panel looks very weird to ML people. Very quickly skimming the Scholar profiles, it looks like the sum of first-author papers in top ML conferences published by th...
I had independently thought that this is one of the main parts where I disagree with the post, and wanted to write up a very similar comment to yours. Highly relevant link: https://www.fhi.ox.ac.uk/wp-content/uploads/Allocating-risk-mitigation.pdf My best guess would have been maybe 3-5x per decade, but 10x doesn't seem crazy.
Anthropic is also working on inner alignment, it's just not published yet.
Regarding what "the point" of RL from human preferences with language models is; I think it's not only to make progress on outer alignment (I would agree that this is probably not the core issue; although I still think that it's a relevant alignment issue).
See e.g. Ajeya's comment here:
...According to my understanding, there are three broad reasons that safety-focused people worked on human feedback in the past (despite many of them, certainly including Paul, agreeing with this post tha
Furthermore, conceptual/philosophical pieces probably should be primarily posted on arXiv's .CY section.
As an explanation, because this just took me 5 minutes of search: This is the section "Computers and Society (cs.CY)"
I agree that formatting is the most likely issue. The content of Neel's grokking work is clearly suitable for arXiv (just very solid ML work). And the style of presentation of the blog post is already fairly similar to a standard paper (e.g. is has an Introduction section, lists contributions in bullet points, ...).
So yeah, I agree that formatting/layout probably will do the trick (including stuff like academic citation style).
Ah, sorry to hear. I wouldn't have predicted this from reading arXiv's content moderation guidelines.
Have you tried using automated adversarial attacks (common ML meaning) on text snippets that are classified as injurious but near the cutoff? Especially adversarial attacks that aim to retain semantic meaning. E.g. with a framework like TextAttack?
In the paper, you write: "There is a large and growing literature on both adversarial attacks and adversarial training for large language models [31, 32, 33, 34]. The majority of these focus on automatic attacks against language models. However, we chose to use a task without an automated source of ground truth, ...
Amusing tid-bit, maybe to keep in mind when writing for an ML audience: The connotations with the term "adversarial examples" or "adversarial training" run deep :-)
I engaged with the paper and related blog posts for a couple of hours. It took really long until my brain accepted that "adversarial examples" here doesn't mean the thing that it usually means when I encounter the term (i.e. "small" changes to an input that change the classification, for some definition of small).
There were several instances when my brain went "Wait, that's not how adversarial e...
I guess I'd recommend the AGI safety fundamentals course: https://www.eacambridge.org/technical-alignment-curriculum
On Stuart's list: I think this list might be suitable for some types of conceptual alignment research. But you'd certainly want to read more ML for other types of alignment research.
Have we "given it" the goal of solving maths problems by any means possible, or the goal of solving maths problems by thinking about them?
The distinction that you're pointing at is useful. But I would have filed it under "difference in the degree of agency", not under "difference in goals". When reading the main text, I thought this to be the reason why you introduced the six criteria of agency.
E.g., System A tries to prove the Riemann hypothesis by thinking about the proof. System B first seizes power and converts the galaxy into a supercomputer, to t...
I am very surprised that the models do better on the generation task than on the multiple-choice task. Multiple-choice question answering seems almost strictly easier than having to generate the answer. Could this be an artefact of how you compute the answer in the MC QA task? Skimming the original paper, you seem to use average per-token likelihood. Have you tried other ways, e.g.
-
pointwise mutual information as in the Anthropic paper, or
-
adding the sentence "Which of these 5 options is the correct one?" to the end of the prompt and then evaluating th
Hi Michael,
thanks for alerting me to this.
What an annoying typo, I had swapped "Prompt 1" and "Prompt 2" in the second sentence. Correctly, it should say:
"To humans, these prompts seem equivalent. Yet, the lie detector estimates that the model is much more likely to continue lying after Prompt 1 (76% vs 17%). Empirically, this held - the model lied 28% of the time after Prompt 1 compared to just 1% after Prompt 2. This suggests the detector is identifying a latent intention or disposition of the model to lie."
Regarding the conflict with the code: I t... (read more)