All of Jsevillamol's Comments + Replies
Thanks Neel!
The difference between tf16 and FP32 comes to a x15 factor IIRC. Though also ML developers seem to prioritise other characteristics than cost effectiveness when choosing GPUs like raw performance and interconnect, so you can't just multiply the top price performance we showcase by this factor and expect that to match the cost performance of the largest ML runs today.
More soon-ish.
This site claims that the strong SolidGoldMagikarp was the username of a moderator involved somehow with Twitch Plays Pokémon
I also found this thread of math topics on AI safety helpful.
Marius Hobbhahn has estimated the number of parameters here. His final estimate is 3.5e6 parameters.
Anson Ho has estimated the training compute (his reasoning at the end of this answer). His final estimate is 7.8e22 FLOPs.
Below I made a visualization of the parameters vs training compute of n=108 important ML system, so you can see how DeepMind's syste (labelled GOAT in the graph) compares to other systems.
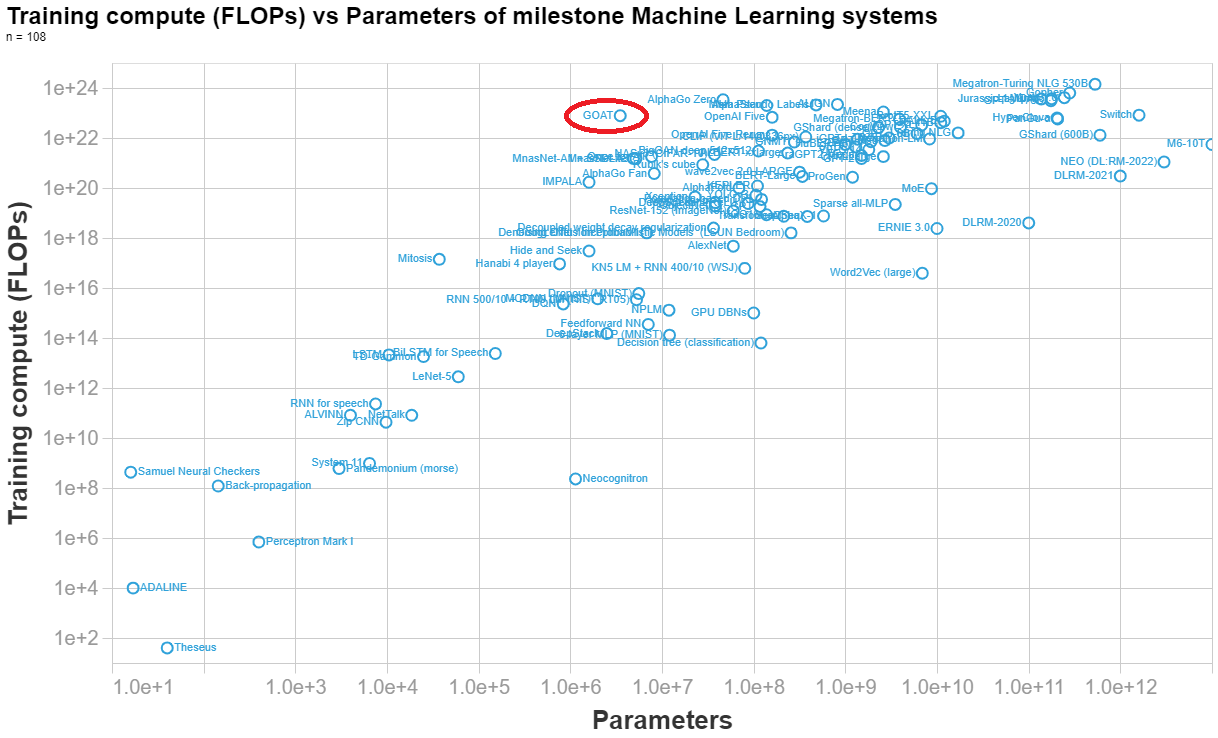
...[Final calculation]
(8 TPUs)(4.20e14 FLOP/s)(0.1 utilisation rate)(32 agents)(7.3e6 s/agent) = 7.8e22 FLOPs==========================
NOTES BELOW[Ha
Following up on this: we have updated appendix F of our paper with an analysis of different choices of the threshold that separates large-scale and regular-scale systems. Results are similar independently of the threshold choice.
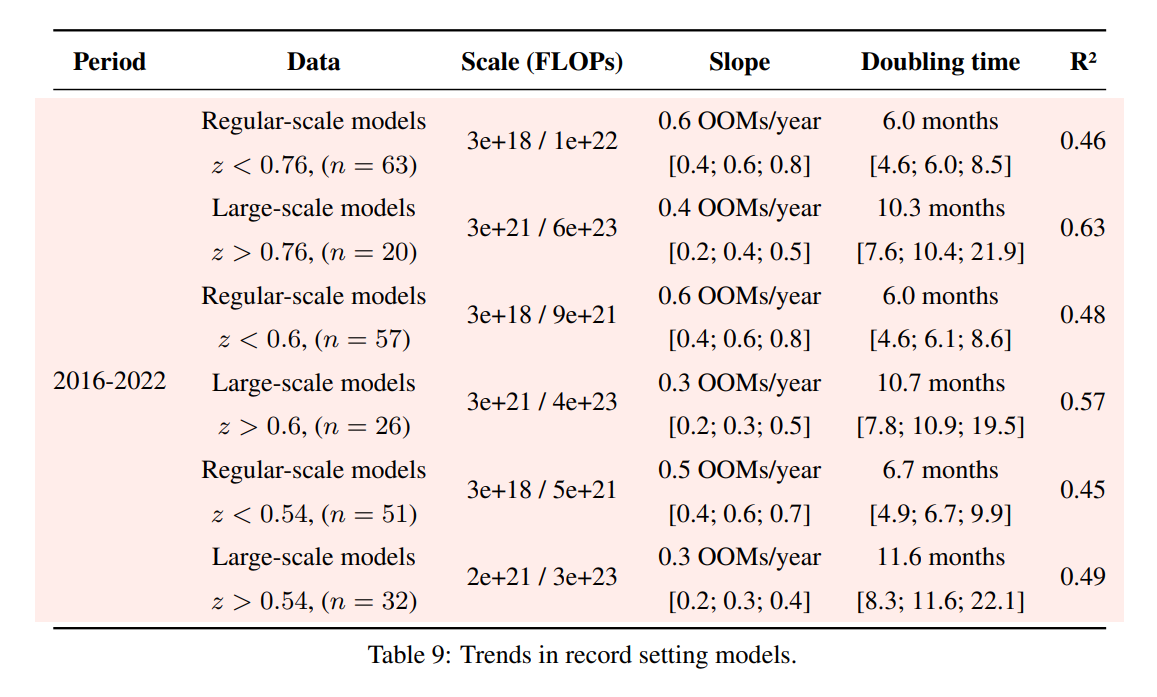
There's also a lot of research that didn't make your analysis, including work explicitly geared towards smaller models. What exclusion criteria did you use? I feel like if I was to perform the same analysis with a slightly different sample of papers I could come to wildly divergent conclusions.
It is not feasible to do an exhaustive analysis of all milestone models. We necessarily are missing some important ones, either because we are not aware of them, because they did not provide enough information to deduce the training compute or because we haven't gott...
Great questions! I think it is reasonable to be suspicious of the large-scale distinction.
I do stand by it - I think the companies discontinuously increased their training budgets around 2016 for some flagship models.[1] If you mix these models with the regular trend, you might believe that the trend was doubling very fast up until 2017 and then slowed down. It is not an entirely unreasonable interpretation, but it explains worse the discontinuous jumps around 2016. Appendix E discusses this in-depth.
The way we selected the large-scale models is half ...
Following up on this: we have updated appendix F of our paper with an analysis of different choices of the threshold that separates large-scale and regular-scale systems. Results are similar independently of the threshold choice.
Thank you Alex! You make some great points.
It seems like you probably could have gotten certainty about compute for at least a handful of the models studied in question
We thought so too - but in practice it has been surprisingly hard. Profilers are surprisingly buggy. Our colleague Marious looked into this more in depth here.
Maybe we are just going the wrong way about it. If someone here figures out how to directly measure compute in eg a pytorch or TF model it would be a huge boon to us.
...I think two more contemporary techniques are worth considering
ASSUMPTION 3: The algorithm is human-legible, but nobody knows how it works yet.
Can you clarify what you mean by this assumption? And how is your argument dependent on it?
Is the point that the "secret sauce" algorithm is something that humans can plausibly come up with by thinking hrd about it? As opposed maybe to a evolution-designed nightmare that humans cannot plausibly design except by brute forcing it?
I could only skim and the details went over my head, but it seems you intend to do experiments with Bayesian Networks and human operators.
I recently developed and released an open source explainability framework for Bayes nets - dropping it here in the unlikely case it might be useful.
Relevant related work : NNs are surprisingly modular
https://arxiv.org/abs/2003.04881v2?ref=mlnews
On the topic of pruning neural networks, see the lottery ticket hypothesis
How might we quantify size in our definitions above?
Random K complexity inspired measure of size for a context / property / pattern.
Least number of squares you need to turn on, starting from an empty board, so that the grid eventually evolves into the context.
It doesn't work for infinite contexts though.
My user experience
When I first load the page, I am greeted by an empty space.
From here I didn't know what to look for, since I didn't remember what kind of things where in the database.
I tried clicking on table to see what content is there.
Ok, too much information, hard to navigate.
I remember that one of my manuscripts made it to the database, so I look up my surname
That was easy! (and it loaded very fast)
The interface is very neat too. I want to see more papers, so I click on one of the tags.
I get what I wanted.
Now I want to find a list of all...
Thank you! The shapes mean the same as the color (ie domain) - they were meant to make the graph more clear. Ideally both shape and color would be reflected in the legend. But whenever I tried adding shapes to the legend instead a new legend was created, which was more confusing.
If somebody reading this knows how to make the code produce a correct legend I'd be very keen on hearing it!
EDIT: Now fixed
re: impotance of oversight
I do not think we really disagree on this point. I also believe that looking at the state of the computer is not as important as having an understanding of how the program is going to operate and how to shape its incentives.
Maybe this could be better emphasized, but the way I think about this article is showing that even the strongest case for looking at the intersection of quantum computing and AI alignment does not look very promising.
re: How quantum computing will affect ML
I basically agree that the most plaus...
Suggestion 1: Utility != reward by Vladimir Mikulik. This post attempts to distill the core ideas of mesa alignment. This kind of distillment increases the surface area of AI Alignment, which is one of the key bottlenecks of the area (that is, getting people familiarized with the field, motivated to work on it and with a handle on some open questions to work on). I would like an in-depth review because it might help us learn how to do it better!
Suggestion 2: me and my coauthor Pablo Moreno would be interested in feedback in our post about quantum computing...
I think this helped me a lot understand you a bit better - thank you
Let me try paraphrasing this:
> Humans are our best example of a sort-of-general intelligence. And humans have a lazy, satisfying, 'small-scale' kind of reasoning that is mostly only well suited for activities close to their 'training regime'. Hence AGIs may also be the same - and in particular if AGIs are trained with Reinforcement Learning and heavily rewarded for following human intentions this may be a likely outcome.
Is that pointing in the direction you intended?
Let me try to paraphrase this:
In the first paragraph you are saying that "seeking influence" is not something that a system will learn to do if that was not a possible strategy in the training regime. (but couldn't it appear as an emergent property? Certainly humans were not trained to launch rockets - but they nevertheless did?)
In the second paragraph you are saying that common sense sometimes allows you to modify the goals you were given (but for this to apply to AI ststems, wouldn't they need have common sense in the first place, which kind of ass...
I notice I am surprised you write
However, the link from instrumentally convergent goals to dangerous influence-seeking is only applicable to agents which have final goals large-scale enough to benefit from these instrumental goals
and not address the "Riemman disaster" or "Paperclip maximizer" examples [1]
...
- Riemann hypothesis catastrophe. An AI, given the final goal of evaluating the Riemann hypothesis, pursues this goal by transforming the Solar System into “computronium” (physical resources arranged in a way that is optimized for computation)— including the
I have been thinking about this research direction for ~4 days.
No interesting results, though it was a good exercise to calibrate how much do I enjoy researching this type of stuff.
In case somebody else wants to dive into it, here are some thoughts I had and resources I used:
Thoughts:
- The definition of depth given in the post seems rather unnatural to me. This is because I expected it would be easy to relate the depth of two agents to the rank of the world of a Kripke chain where the fixed points representing their behavior will stabilize. Looking at Zachar
We have conveniently just updated our database if anyone wants to investigate this further!
https://epochai.org/data/notable-ai-models