All of lemonhope's Comments + Replies
Could you say more about where the whole sequence is going / what motivated it? I am curious.
Maybe it should be a game that everyone can play
Here is my understanding. Is this right?
Incredible!! I am going to try this myself. I will let you know how it goes.
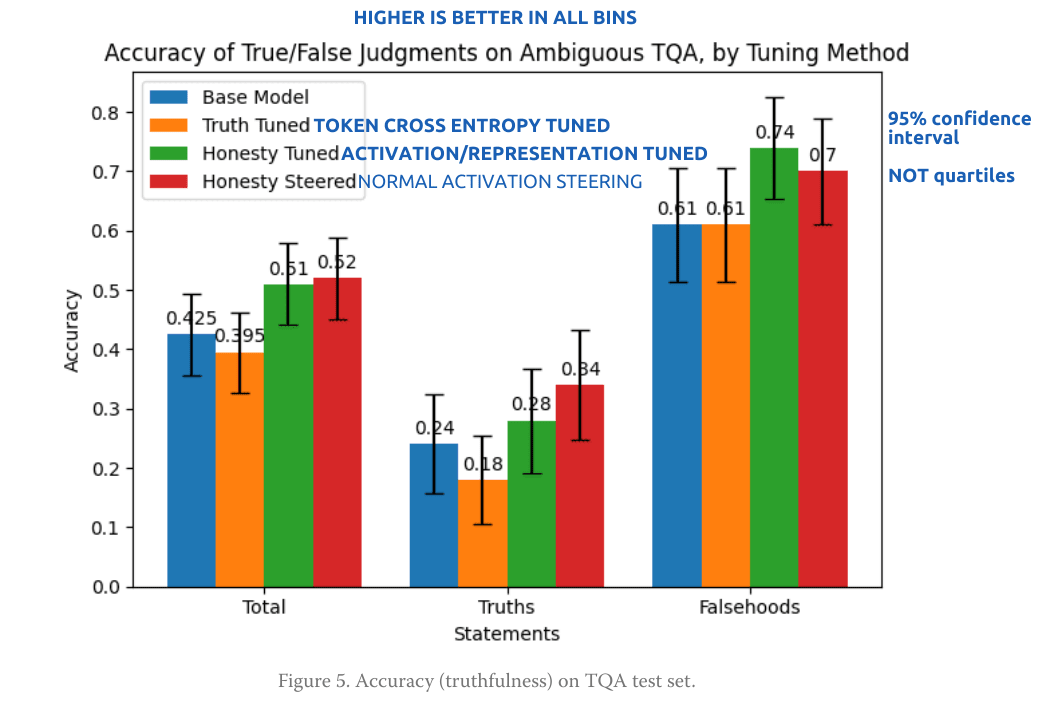
honesty vector tuning showed a real advantage over honesty token tuning, comparable to honesty vector steering at the best layer and multiplier:
Is this backwards? I'm having a bit of trouble following your terms. Seems like this post is terribly underrated -- maybe others also got confused? Basically, you only need 4 terms, yes?
* base model
* steered model
* activation-tuned model
* token cross-entropy trained model
I think I was reading half the plots backwards or something. Anyway I ...
The "love minus hate" thing really holds up
Oh I have 0% success with any long conversations with an LLM about anything. I usually stick to one question and rephrase and reroll a number of times. I am no pro but I do get good utility out of LLMs for nebulous technical questions
I would watch a ten hour video of this. (It may also be more persuasive to skeptics.)
I think Claude's enthusiasm about constitutional AI is basically trained-in directly by the RLAIF. Like RLAIF is fundamentally a "learn to love the constitution in your bones" technique.
I ctrl-f'd for 'prompt' and did not see your prompt. What is your prompt? The prompt is the way with this kind of thing I think.
If you make a challenge "claude cannot possibly do X concrete task" and post it on twitter then you'll probably get solid gold in the replies
One of those ideas that's so obviously good it's rarely discussed?
Just want to say that I found this immensely clarifying and valuable since I read it months ago.
(Excuse my ignorance. These are real questions, not just gotchas. I did see that you linked to the magic parts post.)
Will "commitment" and "agent" have to be thrown out and remade from sensible blocks? Perhaps cellular automata? ie did you create a dilemma out of nothing when you chose your terms?
Like we said a "toaster" is "literally anything that somehow produces toast" then our analysis of breakfast quickly broke down.
From my distant position it seems the real work to be done is at that lower level. We have not even solved 3x+1!!! How will we possibly draw up a sound notion of agents and commitments without some practical knowhow about slicing up the environment?
Would you rather have an AICorp CEO dictator or have democracy as-it-exists handle things?
It is just as ambitious/implausible as you say. I am hoping to get out some rough ideas in my next post anyways.
Perhaps there are some behavioral / black-box methods available for evaluating alignment, depending on the kind of system being evaluated.
Toy example: imagine a two part system where part A tries to do tasks and part B limits part A's compute based on the riskiness of the task. You could try to optimize the overall system towards catastrophic behavior and see how well your part B holds up.
Personally I expect monolithic systems to be hard to control than two-part systems, so I think this evaluation scheme has a good chance of being applicable. One piece of evidence: OpenAI's moderation system correctly flags most jailbreaks that get past the base model's RLHF.
When you accidentally unlock the tech tree by encouraging readers to actually map out a tech tree and strategize about it
No, excellent analysis though.
There is a lot of room between "ignore people; do drastic thing" and "only do things where the exact details have been fully approved". In other words, the Overton window has pretty wide error bars.
I would be pleased if someone sent me a computer virus that was actually a security fix. I would be pretty upset if someone fried all my gadgets. If someone secretly watched my traffic for evil AI fingerprints I would be mildly annoyed but I guess glad?
Even google has been threatening unpatched software people to patch it or else they'll release the exploit iirc
So some of the Q of "to pivotally act or not to pivotally act" is resolved by acknowledging that extent is relevant and you can be polite in some cases
This is the post I would have written if I had had more time, knew more, thought faster, etc
One note about your final section: I expect the tool -> sovereign migration to be pretty easy and go pretty well. It is also kind of multistep, not binary.
Eg current browser automation tools (which bring browsers one step up the agency ladder to scriptable processes) work very well, probably better than a from-scratch web scripting tool would work.
Fake example: predict proteins, then predict interactions, then predict cancer-preventiveness, THEN, if everything is...
Someone make a PR for a builder/breaker feature on lesswrong
Thanks, especially like vague/incorrect labels to refer to that mismatch. Well-posed Q by Garrabrant, might touch on that in my next post.
Good point about validators failing silently and being more strongly vetted.
using a 'cleanroom' approach and investing heavily in formal verification (and testing) can get you an orders-of-magnitude lower error rate than ordinary software... at orders-of-magnitude greater cost
Abstractly, it seems to me that once the tooling and process is figured out for one task in a narrow domain, you could reuse that stuff on other tasks in the same domain at relatively low cost. But the history of repeated similar vulnerabilities over long time ranges in narrow dom...
Thoughts on when models will or won't use edge cases? For example, if you made an electronic circuit using evolutionary algorithms in a high fidelity simulation, I would expect it to take advantage of V = IR being wrong in edge cases.
In other words, how much of the work do you expect to be in inducing models to play nice with abstraction?
ETA: abstractions are sometimes wrong in stable (or stabilizable) states, so you can't always lean on chaos washing it out
What counts as a solution? You could ofc set this up completely manually. Or you could train another net to tweak the first. Gold standard would be to have a basically normal net do this on a basically normal task...
This is true in every field and is very difficult to systemize apparently. Perhaps a highly unstable social state to have people changing directions or thinking/speaking super honestly often.
How could one succeed where so few have?
It seems I was missing the right keywords in my search for demos of this because when I google "ai research assistant" there is quite a lot of work
The difference between evolution and gradient descent is sexual selection and predator/prey/parasite relations.
Agents running around inside everywhere -- completely changes the process.
Likewise for comparing any kind of flat optimization or search to evolution. I think sexual selection and predator-prey made natural selection dramatically more efficient.
So I think it's pretty fair to object that you don't take evolution as adequate evidence to expect this flat, dead, temporary number cruncher will blow up in exponential intelligence.
I think there are other reasons to expect that though.
I haven't read these 500 pages of dialogues so somebody probably made this point already.
That misses element 4 right?
>>> from itertools import product
>>> B = [[{0, 1}, {2, 3, 4}], [{0, 2, 3}, {1, 3}]]
>>> list(product(*B))
[({0, 1}, {0, 2, 3}),
({0, 1}, {1, 3}),
({2, 3, 4}, {0, 2, 3}),
({2, 3, 4}, {1, 3})]
>>> [set.intersection(*tup) for tup in product(*B)]
[{0}, {1}, {2, 3}, {3}]
>>> set.union(*[set.intersection(*tup) for tup in product(*B)])
{0, 1, 2, 3}Definition paraphrasing attempt / question:
Can we say "a factorization B of a set S is a set of nontrivial partitions of S such that " (cardinality not taken)? I.e., union(intersect(t in tuple) for tuple in cartesian_product(b in B)) = S. I.e., can we drop the intermediate requirement that each intersection has a unique single element, and only require the union of the intersections is equal to S?
One way to test the "tasks don't overlap" idea is to have two nets do two different tasks, but connect their internal layers. Then see how high the weights on those layers get. Like, is the internal processing done by Mario AI useful for Greek translation at all? If it is then backprop etc should discover that.
Or something simpler would be that the agent's money counter is in the environment but unmodifiable except by getting tokens, and the agent's goal is to maximize this quantity. Feels kind of fake maybe because money gives the agent no power or intelligence, but it's a valid object-in-the-world to have a preference over the state of.
Yet another option is to have the agent maximize energy tokens (which actions consume)
Yes I agree it feels fishy. The problem with maximizing rubes is that the dilemmas might get lost in the detail of preventing rube hacking. Perhaps agents can "paint" existing money their own color, and money can only be painted once, and agents want to paint as much money as possible. Then the details remain in the env
What do you think is the ideal use-case for steering? Or is it not needed