All of Lukas Finnveden's Comments + Replies
In practice, we'll be able to get slightly better returns by spending some of our resources investing in speed-specific improvements and in improving productivity rather than in reducing cost. I don't currently have a principled way to estimate this (though I expect something roughly principled can be found by looking at trading off inference compute and training compute), but maybe I think this improves the returns to around .
Interesting comparison point: Tom thought this would give a way larger boost in his old software-only singu...
Based on some guesses and some poll questions, my sense is that capabilities researchers would operate about 2.5x slower if they had 10x less compute (after adaptation)
Can you say roughly who the people surveyed were? (And if this was their raw guess or if you've modified it.)
I saw some polls from Daniel previously where I wasn't sold that they were surveying people working on the most important capability improvements, so wondering if these are better.
Also, somewhat minor, but: I'm slightly concerned that surveys will overweight areas where labor is more ...
Hm — what are the "plausible interventions" that would stop China from having >25% probability of takeover if no other country could build powerful AI? Seems like you either need to count a delay as successful prevention, or you need to have a pretty low bar for "plausible", because it seems extremely difficult/costly to prevent China from developing powerful AI in the long run. (Where they can develop their own supply chains, put manufacturing and data centers underground, etc.)
Is there some reason for why current AI isn't TCAI by your definition?
(I'd guess that the best way to rescue your notion it is to stipulate that the TCAIs must have >25% probability of taking over themselves. Possibly with assistance from humans, possibly by manipulating other humans who think they're being assisted by the AIs — but ultimately the original TCAIs should be holding the power in order for it to count. That would clearly exclude current systems. But I don't think that's how you meant it.)
I'm not sure if the definition of takeover-capable-AI (abbreviated as "TCAI" for the rest of this comment) in footnote 2 quite makes sense. I'm worried that too much of the action is in "if no other actors had access to powerful AI systems", and not that much action is in the exact capabilities of the "TCAI". In particular: Maybe we already have TCAI (by that definition) because if a frontier AI company or a US adversary was blessed with the assumption "no other actor will have access to powerful AI systems", they'd have a huge advantage over the rest of t...
I suspect there's a cleaner way to make this argument that doesn't talk much about the number of "token-equivalents", but instead contrasts "total FLOP spent on inference" with some combination of:
- "FLOP until human-interpretable information bottleneck". While models still think in English, and doesn't know how to do steganography, this should be FLOP/forward-pass. But it could be much longer in the future, e.g. if the models get trained to think in non-interpretable ways and just outputs a paper written in English once/week.
- "FLOP until feedback" — how many
Thanks!
I agree that we've learned interesting new things about inference speeds. I don't think I would have anticipated that at the time.
Re:
It seems that spending more inference compute can (sometimes) be used to qualitatively and quantitatively improve capabilities (e.g., o1, recent swe-bench results, arc-agi rather than merely doing more work in parallel. Thus, it's not clear that the relevant regime will look like "lots of mediocre thinking".[1]
There are versions of this that I'd still describe as "lots of mediocre thinking" —adding up to being similarl...
I wonder if work on AI for epistemics could be great for mitigating the "gradually cede control of the Earth to AGI" threat model. A large majority of economic and political power is held by people who would strongly oppose human extinction, so I expect that "lack of political support for stopping human extinction" would be less of a bottleneck than "consensus that we're heading towards human extinction" and "consensus on what policy proposals will solve the problem". Both of these could be significantly accelerated by AI. Normally, one of my biggest conce...
Yeah I was imagining we can proliferate by 'gradient descenting' on similar cases.
What is this referring to? Are you thinking about something like: varying small facts about the scenario to get a function from “details of the scenario”->p(escape attempt) and then switch to a scenario with a higher p and then repeat?
it sounds to me like ruling this out requires an assumption about the correlations of an action being the same as the correlations of an earlier self-modifying action to enforce that later action.
I would guess that assumption would be sufficient to defeat my counter-example, yeah.
I do think this is a big assumption. Definitely not one that I'd want to generally assume for practical purposes, even if it makes for a nicer theory of decision theory. But it would be super interesting if someone could make a proper defense of it typically being true in pract...
However, there is no tiling theorem for UDT that I am aware of, which means we don't know whether UDT is reflectively consistent; it's only a conjecture.
I think this conjecture is probably false for reasons described in this section of "When does EDT seek evidence about correlations?". The section offers an argument for why son-of-EDT isn't UEDT, but I think it generalizes to an argument for why son-of-UEDT isn't UEDT.
Briefly: UEDT-at-timestep-1 is making a different decision than UEDT-at-timestep-0. This means that its decision might be correlated (accord...
Notice that learning-UDT implies UDT: an agent eventually behaves as if it were applying UDT with each Pn. Therefore, in particular, it eventually behaves like UDT with prior P0. So (with the exception of some early behavior which might not conform to UDT at all) this is basically UDT with a prior which allows for learning. The prior P0 is required to eventually agree with the recommendations of P1, P2, ... (which also implies that these eventually agree with each other).
I don't understand this argument.
"an agent eventually behaves as if it were applyin...
I like this direction and this write-up of it!
If sample efficiency was reasonably high, then we overall feel like control could be workable in the regime where for some tasks we need AIs to use huge (e.g. the equivalent of 3 months of human thinking) but not insane (e.g. the equivalent of 1,000 years of human thinking) amounts of uninterpretable serial reasoning.
Let's assume that an AI lab is in a fast-paced, rapidly changing state of affairs. (As you might expect during a moderately fast takeoff.) If an AI then gets to do the equivalent of 3 months of thi...
This is indeed a serious concern.
A key hope here is that with some amount of conservativeness our evaluation[1] and our protocol can generalize to future setups. In particular, our countermeasures could be sufficiently generic that they would work in new situations. And, in our control evaluation, we could test a variety of situations which we might end up in the future (even if they aren't the current situation). So, even if the red team doesn't have enough time to think about the exact situation in which we end up in the future, we might be able to verif...
I think (5) also depends on further details.
As you have written it, both the 2023 and 2033 attempt uses similar data and similar compute.
But in my proposed operationalization, "you can get it to do X" is allowed to use a much greater amount of resources ("say, 1% of the pre-training budget") than the test for whether the model is "capable of doing X" ("Say, at most 1000 data points".)
I think that's important:
- If both the 2023 and the 2033 attempt are really cheap low-effort attempts, then I don't think that the experiment is very relevant for whether "you c
Even just priors on how large effect sizes of interventions are feels like it brings it under 10x unless there are more detailed arguments given for 10x, but I'll give some more specific thoughts below.
Hm, at the scale of "(inter-)national policy", I think you can get quite large effect sizes. I don't know large the effect-sizes of the following are, but I wouldn't be surprised by 10x or greater for:
- Regulation of nuclear power leading to reduction in nuclear-related harms. (Compared to a very relaxed regulatory regime.)
- Regulation of pharmaceuticals l
Instead, ARC explicitly tries to paint the moratorium folks as "extreme".
Are you thinking about this post? I don't see any explicit claims that the moratorium folks are extreme. What passage are you thinking about?
Cool paper!
I'd be keen to see more examples of the paraphrases, if you're able to share. To get a sense of the kind of data that lets the model generalize out of context. (E.g. if it'd be easy to take all 300 paraphrases of some statement (ideally where performance improved) and paste in a google doc and share. Or lmk if this is on github somewhere.)
I'd also be interested in experiments to determine whether the benefit from paraphrases is mostly fueled by the raw diversity, or if it's because examples with certain specific features help a bunch, and those ...
Here's a proposed operationalization.
For models that can't gradient hack: The model is "capable of doing X" if it would start doing X upon being fine-tuned to do it using a hypothetical, small finetuning dataset that demonstrated how to do the task. (Say, at most 1000 data points.)
(The hypothetical fine-tuning dataset should be a reasonable dataset constructed by a hypothetical team of human who knows how to do the task but aren't optimizing the dataset hard for ideal gradient updates to this particular model, or anything like that.)
For models that might ...
I intend to write a lot more on the potential “brains vs brawns” matchup of humans vs AGI. It’s a topic that has received surprisingly little depth from AI theorists.
I recommend checking out part 2 of Carl Shulman's Lunar Society podcast for content on how AGI could gather power and take over in practice.
Note that B is (0.2,10,−1)-distinguishable in P.
I think this isn't right, because definition 3 requires that sup_s∗ {B_P− (s∗)} ≤ γ.
And for your counterexample, s* = "C" will have B_P-(s*) be 0 (because there's 0 probably of generating "C" in the future). So the sup is at least 0 > -1.
(Note that they've modified the paper, including definition 3, but this comment is written based on the old version.)
Are you mainly interested in evaluating deceptive capabilities? I.e., no-holds-barred, can you elicit competent deception (or sub-components of deception) from the model? (Including by eg fine-tuning on data that demonstrates deception or sub-capabilities.)
Or evaluating inductive biases towards deception? I.e. testing whether the model is inclined towards deception in cases when the training data didn't necessarily require deceptive behavior.
(The latter might need to leverage some amount of capability evaluation, to distinguish not being inclined towards deception from not being capable of deception. But I don't think the reverse is true.)
Or if you disagree with that way of cutting up the space.
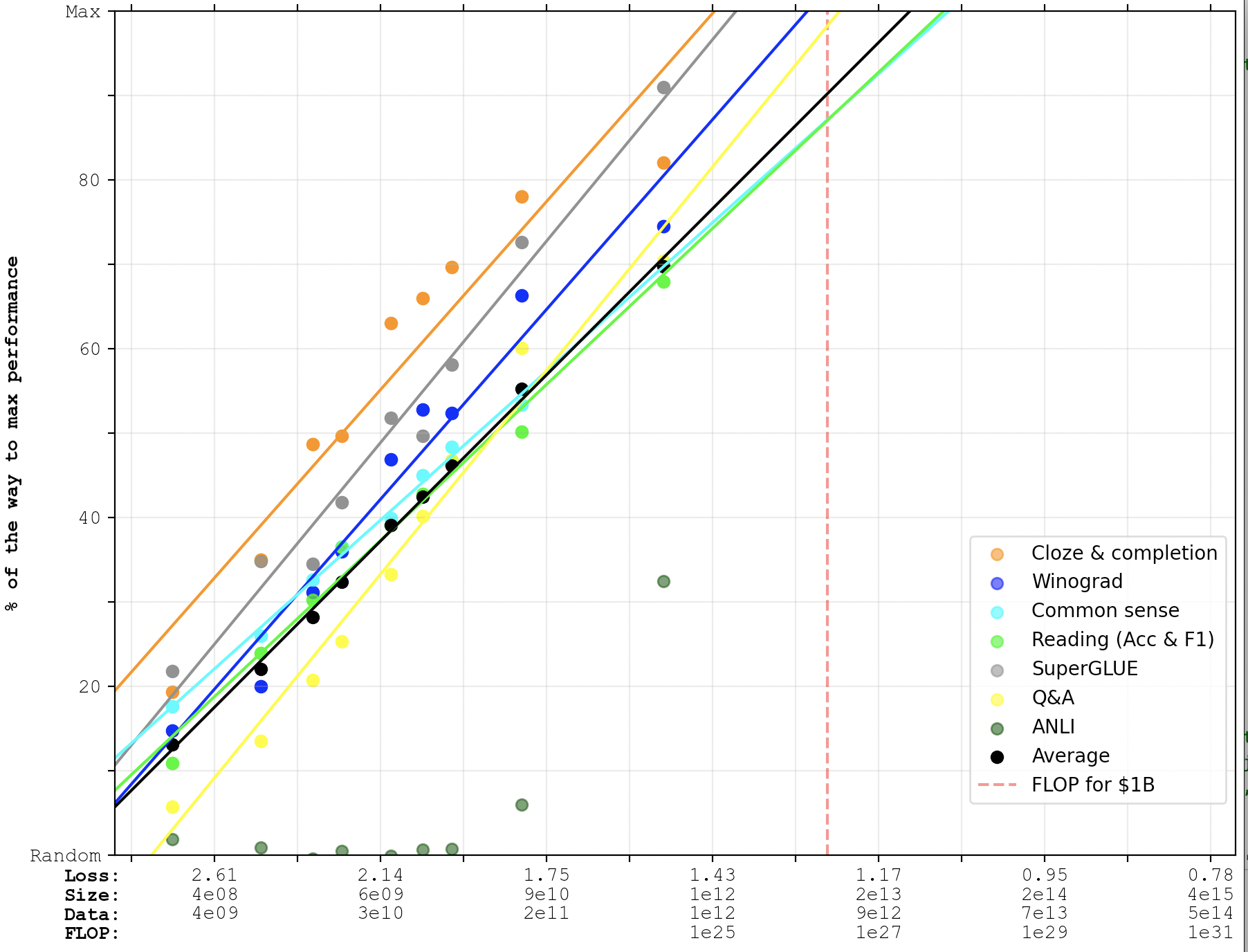
I assume that's from looking at the GPT-4 graph. I think the main graph I'd look at for a judgment like this is probably the first graph in the post, without PaLM-2 and GPT-4. Because PaLM-2 is 1-shot and GPT-4 is just 4 instead of 20+ benchmarks.
That suggests 90% is ~1 OOM away and 95% is ~3 OOMs away.
(And since PaLM-2 and GPT-4 seemed roughly on trend in the places where I could check them, probably they wouldn't change that too much.)
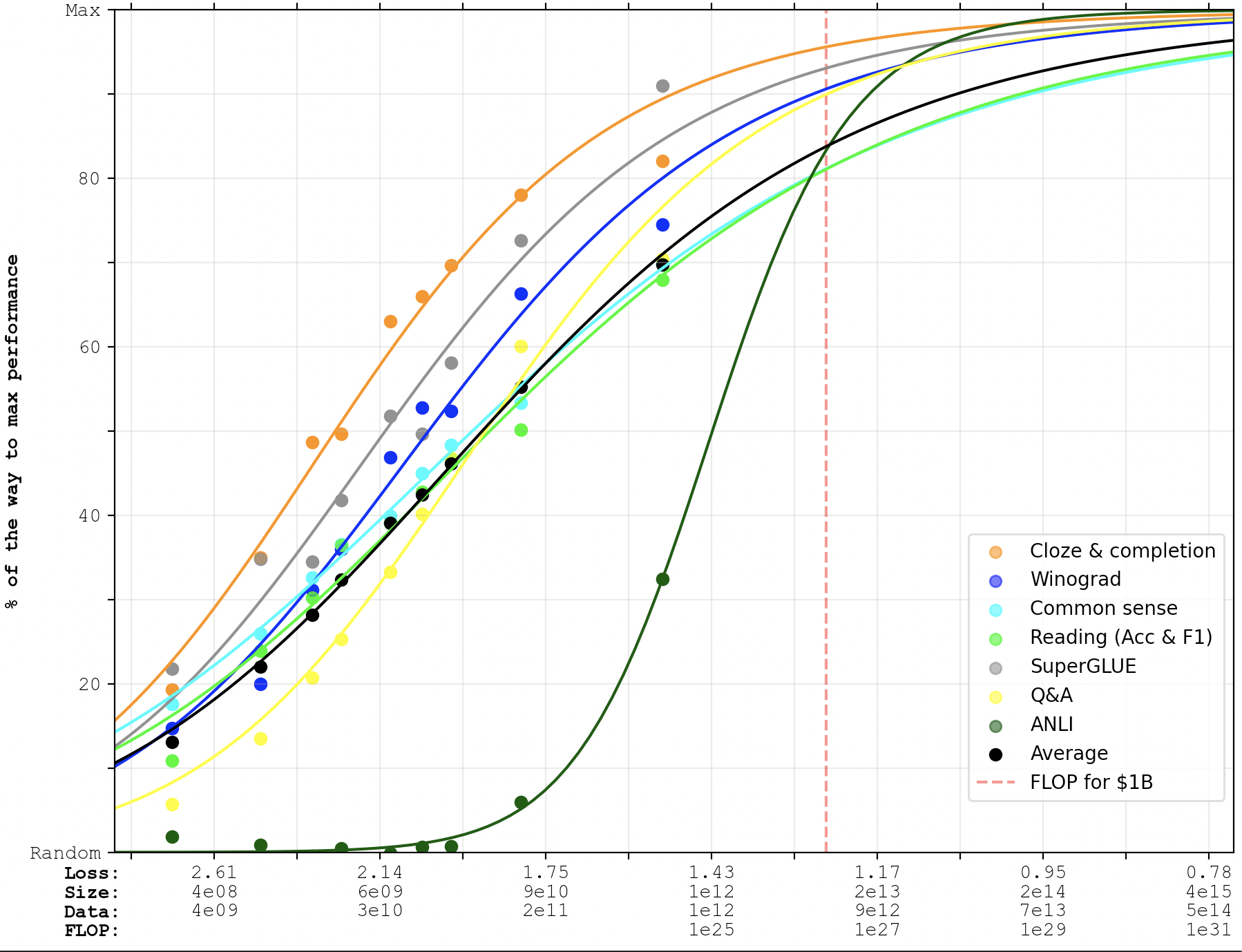
Interesting. Based on skimming the paper, my impression is that, to a first approximation, this would look like:
- Instead of having linear performance on the y-axis, switch to something like log(max_performance - actual_performance). (So that we get a log-log plot.)
- Then for each series of data points, look for the largest n such that the last n data points are roughly on a line. (I.e. identify the last power law segment.)
- Then to extrapolate into the future, project that line forward. (I.e. fit a power law to the last power law segment and project it forward.
...Competence does not seem to aggressively overwhelm other advantages in humans:
[...]
g. One might counter-counter-argue that humans are very similar to one another in capability, so even if intelligence matters much more than other traits, you won’t see that by looking at the near-identical humans. This does not seem to be true. Often at least, the difference in performance between mediocre human performance and top level human performance is large, relative to the space below, iirc. For instance, in chess, the Elo difference between the best and
Another fairly common argument and motivation at OpenAI in the early days was the risk of "hardware overhang," that slower development of AI would result in building AI with less hardware at a time when they can be more explosively scaled up with massively disruptive consequences. I think that in hindsight this effect seems like it was real, and I would guess that it is larger than the entire positive impact of the additional direct work that would be done by the AI safety community if AI progress had been slower 5 years ago.
Could you clarify this bit? It ...
One positive consideration is: AI will be built at a time when it is more expensive (slowing later progress). One negative consideration is: there was less time for AI-safety-work-of-5-years-ago. I think that this particular positive consideration is larger than this particular negative consideration, even though other negative considerations are larger still (like less time for growth of AI safety community).
This seems plausible if the environment is a mix of (i) situations where task completion correlates (almost) perfectly with reward, and (ii) situations where reward is very high while task completion is very low. Such as if we found a perfect outer alignment objective, and the only situation in which reward could deviate from the overseer's preferences would be if the AI entirely seized control of the reward.
But it seems less plausible if there are always (small) deviations between reward and any reasonable optimization target that isn't reward (or close e...
As the main author of the "Alignment"-appendix of the truthful AI paper, it seems worth clarifying: I totally don't think that "train your AI to be truthful" in itself is a plan for how to tackle any central alignment problems. Quoting from the alignment appendix:
...While we’ve argued that scaleable truthfulness would constitute significant progress on alignment (and might provide a solution outright), we don’t mean to suggest that truthfulness will sidestep all difficulties that have been identified by alignment researchers. On the contrary, we expect work o
First I gotta say: I thought I knew the art of doing quick-and-dirty calculations, but holy crap, this methodology is quick-and-dirty-ier than I would ever have thought of. I'm impressed.
But I don't think it currently gets to right answer. One salient thing: it doesn't take into account Kaplan's "contradiction". I.e., Kaplan's laws already suggested that once we were using enough FLOP, we would have to scale data faster than we have to do in the short term. So when I made my extrapolations, I used a data-exponent that was larger than the one that's represe...
but I am surprised that Chinchilla's curves uses an additive term that predicts that loss will never go below 1.69. What happened with the claims that ideal text-prediction performance was like 0.7?
Apples & oranges, you're comparing different units. Comparing token perplexities is hard when the tokens (not to mention datasets) differ. Chinchilla isn't a character-level model but BPEs (well, they say SentencePiece which is more or less BPEs), and BPEs didn't even exist until the past decade so there will be no human estimates which are in BPE units (...
Ok so I tried running the numbers for the neural net anchor in my bio-anchors guesstimate replica.
Previously the neural network anchor used an exponent (alpha) of normal(0.8, 0.2) (first number is mean, second is standard deviation). I tried changing that to normal(1, 0.1) (smaller uncertainty because 1 is a more natural number, and some other evidence was already pointing towards 1). Also, the model previously said that a 1-trillion parameter model should be trained with 10^normal(11.2, 1.5) data points. I changed that to have a median at 21.2e12 paramete...
Depends on how you were getting to that +N OOMs number.
If you were looking at my post, or otherwise using the scaling laws to extrapolate how fast AI was improving on benchmarks (or subjective impressiveness), then the chinchilla laws means you should get there sooner. I haven't run the numbers on how much sooner.
If you were looking at Ajeya's neural network anchor (i.e. the one using the Kaplan scaling-laws, not the human-lifetime or evolution anchors), then you should now expect that AGI comes later. That model anchors the number of parameters in AGI to ...
Ok so I tried running the numbers for the neural net anchor in my bio-anchors guesstimate replica.
Previously the neural network anchor used an exponent (alpha) of normal(0.8, 0.2) (first number is mean, second is standard deviation). I tried changing that to normal(1, 0.1) (smaller uncertainty because 1 is a more natural number, and some other evidence was already pointing towards 1). Also, the model previously said that a 1-trillion parameter model should be trained with 10^normal(11.2, 1.5) data points. I changed that to have a median at 21.2e12 paramete...
In fact, if we think of pseudo-inputs as predicates that constrain X, we can approximate the probability of unacceptable behavior during deployment as[7]
P(C(M,x) | x∼deploy)≈maxα∈XpseudoP(α(x) | x∼deploy)⋅ P(C(M,x) | α(x), x∼deploy) such that, if we can get a good implementation of P, we no longer have to worry as much about carefully constraining Xpseudo, as we can just let P's prior do that work for us.
Where footnote 7 reads:
Note that this approximation is tight if and only if there exists some α∈Xpseudo such that α(x)↔C(M,x)
I think the "if" direction is...
I'm at like 30% on fast takeoff in the sense of "1 year doubling without preceding 4 year doubling" (a threshold roughly set to break any plausible quantitative historical precedent).
Huh, AI impacts looked at one dataset of GWP (taken from wikipedia, in turn taken from here) and found 2 precedents for "x year doubling without preceding 4x year doubling", roughly during the agricultural evolution. The dataset seems to be a combination of lots of different papers' estimates of human population, plus an assumption of ~constant GWP/capita early in history.
I agree that i does slightly worse than t on consistency-checks, but i also does better on other regularizers you're (maybe implicitly) using like speed/simplicity, so as long as i doesn't do too much worse it'll still beat out the direct translator.
Any articulable reason for why i just does slightly worse than t? Why would a 2N-node model fix a large majority of disrepancys between an N-node model and a 1e12*N-node model? I'd expect it to just fix a small fraction of them.
I think this rapidly runs into other issues with consistency checks, like the fact...
Hypothesis: Maybe you're actually not considering a reporter i that always use an intermediate model; but instead a reporter i' that does translations on hard questions, and just uses the intermediate model on questions where it's confident that the intermediate model understands everything relevant. I see three different possible issues with that idea:
1. To do this, i' needs an efficient way (ie one that doesn't scale with the size of the predictor) to (on at least some inputs) be highly confident that the intermediate model understands everything relevan...
I don't understand your counterexample in the appendix Details for penalizing inconsistencies across different inputs. You present a cheating strategy that requires the reporter to run and interpret the predictor a bunch of times, which seems plausibly slower than doing honest translation. And then you say you fix this issue with:
But this dependence could be avoided if there was an intermediate model between the predictor’s Bayes net (which we are assuming is very large) and the human’s Bayes net. Errors identified by the intermediate model are likely to b...
It's very easy to construct probability distributions that have earlier timelines, that look more intuitively unconfident, and that have higher entropy than the bio-anchors forecast. You can just take some of the probability mass from the peak around 2050 and redistribute it among earlier years, especially years that are very close to the present, where bioanchors are reasonably confident that AGI is unlikely.
Oh, come on. That is straight-up not how simple continuous toy models of RSI work. Between a neutron multiplication factor of 0.999 and 1.001 there is a very huge gap in output behavior.
Nitpick: I think that particular analogy isn't great.
For nuclear stuff, we have two state variables: amount of fissile material and current number of neutrons flying around. The amount of fissile material determines the "neutron multiplication factor", but it is the number of neutrons that goes crazy, not fissile material. And the current number of neurons doesn't matter f...
While GPT-4 wouldn't be a lot bigger than GPT-3, Sam Altman did indicate that it'd use a lot more compute. That's consistent with Stack More Layers still working; they might just have found an even better use for compute.
(The increased compute-usage also makes me think that a Paul-esque view would allow for GPT-4 to be a lot more impressive than GPT-3, beyond just modest algorithmic improvements.)
and some of my sense here is that if Paul offered a portfolio bet of this kind, I might not take it myself, but EAs who were better at noticing their own surprise might say, "Wait, that's how unpredictable Paul thinks the world is?"
If Eliezer endorses this on reflection, that would seem to suggest that Paul actually has good models about how often trend breaks happen, and that the problem-by-Eliezer's-lights is relatively more about, either:
- that Paul's long-term predictions do not adequately take into account his good sense of short-term trend breaks.
- tha
Presumably you're referring to this graph. The y-axis looks like the kind of score that ranges between 0 and 1, in which case this looks sort-of like a sigmoid to me, which accelerates when it gets closer to ~50% performance (and decelarates when it gets closer to 100% performance).
If so, we might want to ask whether these tasks are chosen ~randomly (among tasks that are indicative of how useful AI is) or if they're selected for difficulty in some way. In particular, assume that most tasks look sort-of like a sigmoid as they're scaled up (accelerating arou...
95% of all ML researchers don't think it's a problem, or think it's something we'll solve easily
The 2016 survey of people in AI asked people about the alignment problem as described by Stuart Russell, and 39% said it was an important problem and 33% that it's a harder problem than most other problem in the field.

given realistic treatments of moral uncertainty you should not care too much more about preventing drift than about preventing extinction given drift (e.g. 10x seems very hard to justify to me).
I think you already believe this, but just to clarify: this "extinction" is about the extinction of Earth-originating intelligence, not about humans in particular. So AI alignment is an intervention to prevent drift, not an intervention to prevent extinction. (Though of course, we could care differently about persuasion-tool-induced drift vs unaliged-AI-induced drift.)
Interesting! Here's one way to look at this:
- EDT+SSA-with-a-minimal-reference-class behaves like UDT in anthropic dilemmas where updatelessness doesn't matter.
- I think SSA with a minimal reference class is roughly equivalent to "notice that you exist; exclude all possible worlds where you don't exist; renormalize"
- In large worlds where your observations have sufficient randomness that observers of all kinds exists in all worlds, the SSA update step cannot exclude any world. You're updateless by default. (This is the case in the 99% example above.)
- In small or
I'm confused — I thought you put significantly less probability on software-only singularity than Ryan does? (Like half?) Maybe you were using a different bound for the number of OOMs of improvement?