All of Noa Nabeshima's Comments + Replies
This is cool! I wonder if it can be fixed. I imagine it could be improved some amount by nudging the prefix distribution, but it doesn't seem like that will solve it properly. Curious if this is a large issue in real LMs. It's frustrating that there aren't ground-truth features we have access to in language models.
I think how large of a problem this is can probably be inferred from a description of the feature distribution. It'd be nice to have a better sense of what that distribution is (assuming the paradigm is correct enough).
Tree Methodology
To generate the trees in sparselatents.com/tree_view, I use a variant of Masked Cosine Similarity (MCS), a metric introduced in Towards Monosemanticity. The original MCS is calculated like this: For any two latents A and B, first compute the cosine similarity between their activations, but only considering tokens where latent A is active. Then compute the same similarity, but only for tokens where latent B is active. The final MCS value is the larger of these two similarities.
Instead of taking the max, I do a directed MCS where I just consi...
I thought I had some informal evidence that permuting the latents was good and after double checking some evidence I don't feel confident that it is good.
Training without permutation seems to attain slightly better FVU/L0, has reasonable looking features at a quick glance, seems to solve the toy model at comparable rates to permuted, and is simpler to code.
This is great work! I like that you tested on large models and your very comprehensive benchmarking. I also like the BatchTopK architecture.
It's interesting to me that MSE has a smaller hit than cross-entropy.
Here are some notes I made:
We suspect that using a fixed group size leads to more stable training and faster convergence.
This seems plausible to me!
Should the smallest sub-SAE get gradients from all losses, or should the losses from larger sub-SAEs be stopped?
When I tried stopping the gradient from flowing from large sub-SAE losses to small it made la...
Even with all possible prefixes included in every batch the toy model learns the same small mixing between parent and children (this was best out of 2, for the first run the matryoshka didn't represent one of the features): https://sparselatents.com/matryoshka_toy_all_prefixes.png
Here's a hypothesis that could explain most of this mixing. If the hypothesis is true, then even if every possible prefix is included in every batch, there will still be mixing.
Hypothesis:
{kind=link}
...Regardless of the number of prefixes, there will be some prefix loss terms where
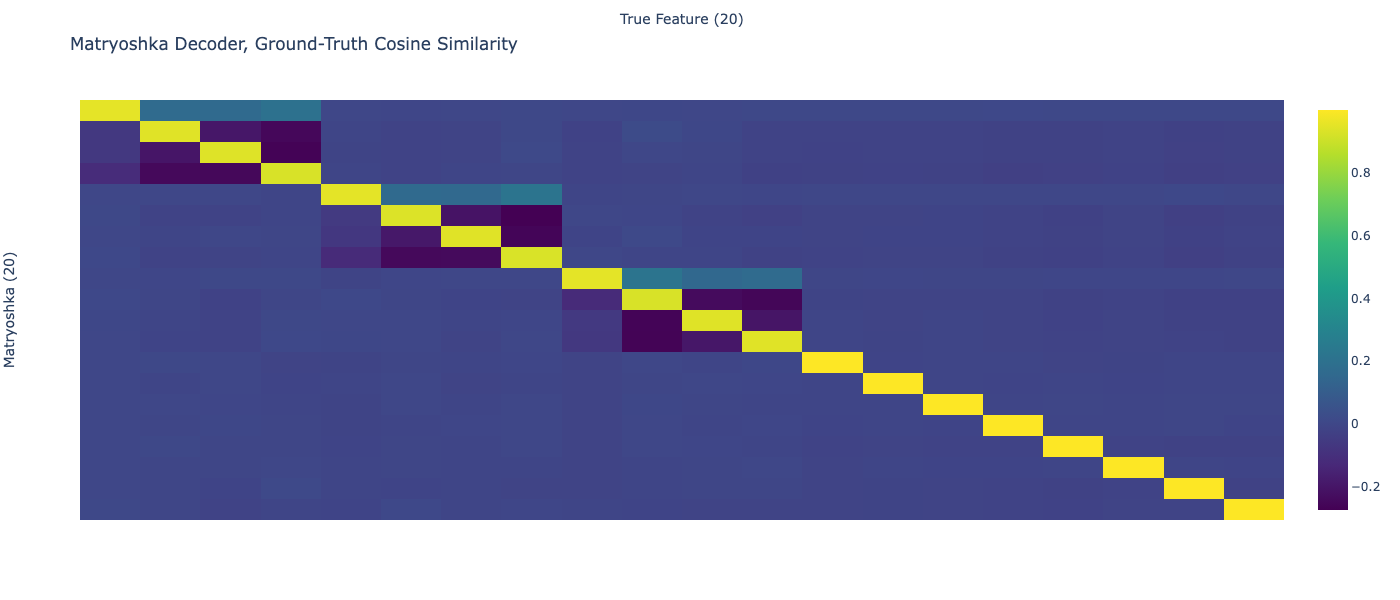
I tried digging into this some more and think I have an idea what's going on. As I understand it, the base assumption for why Matryoshka SAE should solve absorption is that a narrow SAE should perfectly reconstruct parent features in a hierarchy, so then absorption patterns can't arise between child and parent features. However, it seems like this assumption is not correct: narrow SAEs sill learn messed up latents when there's co-occurrence between parent and child features in a hierarchy, and this messes up what the Matryoshka SAE learns.
I did this invest...
That's very cool, I'm looking forward to seeing those results! The Top-K extension is particularly interesting, as that was something I wasn't sure how to approach.
I imagine you've explored important directions I haven't touched like better benchmarking, top-k implementation, and testing on larger models. Having multiple independent validations of an approach also seems valuable.
I'd be interested in continuing this line of research, especially circuits with Matryoshka SAEs. I'd love to hear about what directions you're thinking of. Would you want to have a call sometime about collaboration or coordination? (I'll DM you!)
Really looking forward to reading your post!
Yes, follow up work with bigger LMs seems good!
I use number of prefix-losses per batch = 10 here; I tried 100 prefixes per batch and the learned latents looked similar at a quick glance, so I wonder if naively training with block size = 1 might not be qualitatively different. I'm not that sure and training faster with kernels on its own seems good also!
Maybe if you had a kernel for training with block size = 1 it would create surface area for figuring out how to work on absorption when latents are right next to each other in the matryoshka latent ordering.
I wonder if multiple heads having the same activation pattern in a context is related to the limited rank per head; once the VO subspace of each head is saturated with meaningful directions/features maybe the model uses multiple heads to write out features that can't be placed in the subspace of any one head.
[word] and [word]
can be thought of as "the previous token is ' and'."
It might just be one of a family of linear features or ?? aspect of some other representation ?? corresponding to what the previous token is, to be used for at least induction head.
Maybe the reason you found ' and' first is because ' and' is an especially frequent word. If you train on the normal document distribution, you'll find the most frequent features first.
I really appreciate this work!
I wonder if the reason MLPs are more polysemantic isn't because there are fewer MLPs than heads but because the MLP matrices are larger--
Suppose the model is storing information as sparse [rays or directions]. Then SVD on large matrices like the token embeddings can misunderstand the model in different ways:
- Many of the sparse rays/directions won't be picked up by SVD. If there are 10,000 rays/directions used by the model and the model dimension is 768, SVD can only pick 768 directions.
- If the model natively stores informati...
I think at least some GPT2 models have a really high-magnitude direction in their residual stream that might be used to preserve some scale information after LayerNorm. [I think Adam Scherlis originally mentioned or showed the direction to me, but maybe someone else?]. It's maybe akin to the water-droplet artifacts in StyleGAN touched on here: https://arxiv.org/pdf/1912.04958.pdf
...We begin by observing that most images generated by StyleGAN exhibit characteristic blob-shaped artifacts that resemble water droplets. As shown in Figure 1, even when the droplet
How much influence and ability you expect to have as an individual in that timeline.
For example, I don't expect to have much influence/ability in extremely short timelines, so I should focus on timelines longer than 4 years, with more weight to longer timelines and some tapering off starting around when I expect to die.
How relevant thoughts and planning now will be.
If timelines are late in my life or after my death, thoughts, research, and planning now will be much less relevant to the trajectory of AI going well, so at this moment in time I should weight timelines in the 4-25 year range more.
Value-symmetry: "Will AI systems in the critical period be equally useful for different values?"
This could fail if, for example, we can build AI systems that are very good at optimizing for easy-to-measure values but significantly worse at optimizing for hard to measure values. It might be easy to build a sovereign AI to maximize the profit of a company, but hard to create one that cares about humans and what they want.
Evan Hubinger has some operationalizations of things like this here and here.
Open / Closed: "Will transformative AI systems in the critical period be publicly available?"
A world where everyone has access to transformative AI systems, for example by being able to rent them (like GPT-3's API once it's publicly available), might be very different from one where they are kept private by one or more private organizations.
For example, if strategy stealing doesn't hold, this could dramatically change the distribution of power, because the systems might be more helpful for some tasks and values than others.
This variable could also affect t...
Deceptive alignment: “In the critical period, will AIs be deceptive?”
Within the framework of Risks from Learned Optimization, this is when a mesa-optimizer has a different objective than the base objective, but instrumentally optimizes the base objective to deceive humans. It can refer more generally to any scenario where an AI system behaves instrumentally one way to deceive humans.
Alignment tax: “How much more difficult will it be to create an aligned AI vs an unaligned AI when it becomes possible to create powerful AI?”
If the alignment tax is low, people have less incentive to build an unaligned AI as they'd prefer to build a system that's trying to do what they want. Then, to increase the probability that our AI trajectory goes well, one could focus on how to reduce the alignment tax.
You know I was thinking ab this-- say that there are two children and they're orthogonal to the parent and each have probability 0.4 given the parent. If you imagine the space it looks like three clusters, two with probability 0.4, norm 1.4 and one with probability 0.2 and norm 1. They all have high cosine similarity with each other. From this frame, having the parent 'include' the children directions a bit doesn't seem that inappropriate. One SAE latent setup that seems pretty reasonable is to actually have one parent latent that's like "one of these thre... (read more)