All of Sammy Martin's Comments + Replies
Good point. You're right to highlight the importance of the offense-defense balance in determining the difficulty of high-impact tasks, rather than alignment difficulty alone. This is a crucial point that I'm planning on expand on in the next post in this sequence.
Many things determine the overall difficulty of HITs:
- the "intrinsic" offense-defense balance in related fields (like biotechnology, weapons technologies and cybersecurity) and especially whether there are irresolutely offense-dominant technologies that transformative AI can develop and which can'
Yes, I do think constitution design is neglected! I think it's possible people think constitution changes now won't stick around or that it won't make any difference in the long term, but I do think based on the arguments here that even if it's a bit diffuse you can influence AI behavior on important structural risks by changing their constitutions. It's simple, cheap and maybe quite effective especially for failure modes that we don't have any good shovel-ready technical interventions for.
If you want a specific practical example of the difference between the two: we now have AIs capable of being deceptive when not specifically instructed to do so ('strategic deception') but not developing deceptive power-seeking goals completely opposite what the overseer wants of them ('deceptive misalignment'). This from Apollo research on Strategic Deception is the former not the latter,
https://www.apolloresearch.ai/research/summit-demo
>APS is less understood and poorly forecasted compared to AGI.
I should clarify that I was talking about the definition used by forecasts like the Direct Approach methodology and/or the definition given in the metaculus forecast or in estimates like the Direct Approach. The latter is roughly speaking, capability sufficient to pass a hard adversarial Turing tests and human-like capabilities on enough intellectual tasks as measured by certain tests. This is something that can plausibly be upper bounded by the direct approach methodology which aims to...
I recently held a workshop with PIBBSS fellows on the MTAIR model and thought some points from the overall discussion were valuable:
The discussants went over various scenarios related to AI takeover, including a superficially aligned system being delegated lots of power and gaining resources by entirely legitimate means, a WFLL2-like automation failure, and swift foom takeover. Some possibilities involved a more covert, silent coup where most of the work was done through manipulation and economic pressure. The concept of "$1T damage" as an intermediate sta...
Oh, we've been writing up these concerns for 20 years and no one listens to us.' My view is quite different. I put out a call and asked a lot of people I know, well-informed people, 'Is there any actual mathematical model of this process of how the world is supposed to end?'...So, when it comes to AGI and existential risk, it turns out as best I can ascertain, in the 20 years or so we've been talking about this seriously, there isn't a single model done.
I think that MTAIR plausibly is a model of the 'process of how the world is supposed to end', in the sen...
The alignment difficulty scale is based on this post.
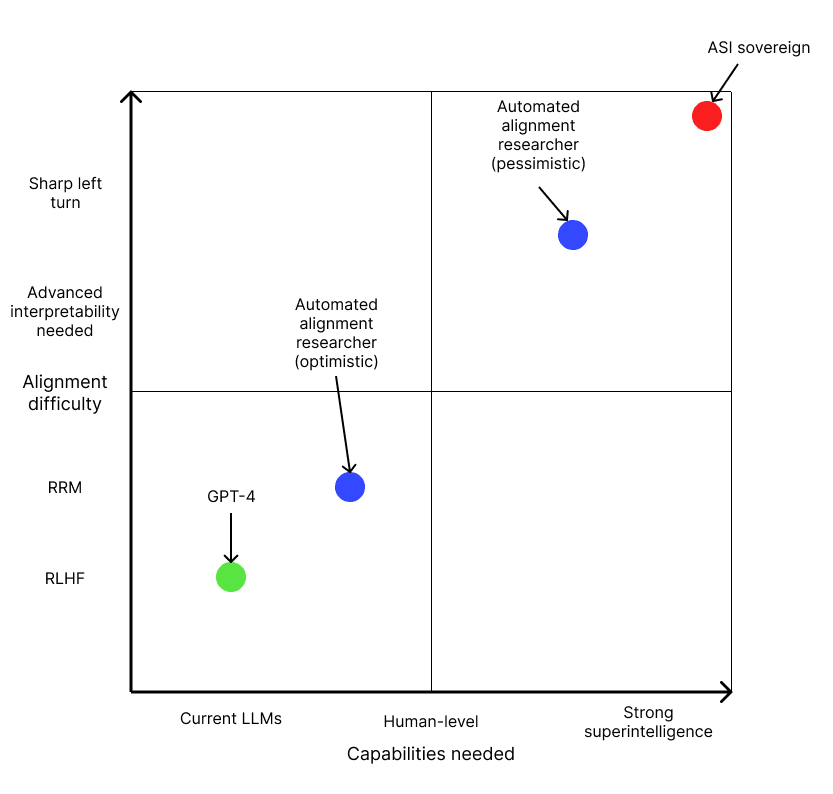
I really like this post and think it's a useful addendum to my own alignment difficulty scale (making it 2D, essentially). But I think I was conceptualizing my scale as running along the diagonal line you provide from GPT-4 to sovereign AI. But I think your way of doing it is better on reflection.
In my original post when I suggested that the 'target' level of capability we care about is the capability level needed to build positively transformative AI (pTAI), which is essentially the 'minimal aligne...
Update
This helpful article by Holden Karnofsky also describes an increasing scale of alignment difficulty, although it's focused on a narrower range of the scale than mine (his scale covers 4-7) and is a bit more detailed about the underlying causes of the misalignment. Here's how my scale relates to his:
The "playing the training game" threat model, where systems behave deceptively only to optimize in-episode reward, corresponds to an alignment difficulty level of 4 or higher. This is because scalable oversight without interpretability tools (level 4) shou...
I think that, on the categorization I provided,
'Playing the training game' at all corresponds to an alignment difficulty level of 4 because better than human behavioral feedback and oversight can reveal it and you don't need interpretability.
(Situationally aware) Deception by default corresponds to a difficulty level of 6 because if it's sufficiently capable no behavioral feedback will work and you need interpretability-based oversight
Gradient hacking by default corresponds to a difficulty level of 7 because the system will also fight interpretability base...
You're right, I've reread the section and that was a slight misunderstanding on my part.
Even so I still think it falls at a 7 on my scale as it's a way of experimentally validating oversight processes that gives you some evidence about how they'll work in unseen situations.
In the sense that there has to be an analogy between low and high capabilities somewhere, even if at the meta level.
This method lets you catch dangerous models that can break oversight processes for the same fundamental reasons as less dangerous models, not just for the same inputs.
Excellent! In particular, it seems like oversight techniques which can pass tests like these could work in worlds where alignment is very difficult, so long as AI progress doesn't involve a discontinuity so huge that local validity tells you nothing useful (such that there are no analogies between low and high capability regimes).
I'd say this corresponds to 7 on my alignment difficulty table.
...Today, Anthropic, Google, Microsoft and OpenAI are announcing the formation of the Frontier Model Forum, a new industry body focused on ensuring safe and responsible development of frontier AI models. The Frontier Model Forum will draw on the technical and operational expertise of its member companies to benefit the entire AI ecosystem, such as through advancing technical evaluations and benchmarks, and developing a public library of solutions to s
deception induced by human feedback does not require strategic awareness - e.g. that thing with the hand which looks like it's grabbing a ball but isn't is a good example. So human-feedback-induced deception is more likely to occur, and to occur earlier in development, than deception from strategic awareness
The phenomenon that a 'better' technique is actually worse than a 'worse' technique if both are insufficient is something I talk about in a later section of the post and I specifically mention RLHF. I think this holds true in general throughout the scal...
Very nice! I'd say this seems like it's aimed at a difficulty level of 5 to 7 on my table,
https://www.lesswrong.com/posts/EjgfreeibTXRx9Ham/ten-levels-of-ai-alignment-difficulty#Table
I.e. experimentation on dangerous systems and interpretability play some role but the main thrust is automating alignment research and oversight, so maybe I'd unscientifically call it a 6.5, which is a tremendous step up from the current state of things (2.5) and would solve alignment in many possible worlds.
This strikes me as a very preliminary bludgeon version of the holy grail of mechanistic interpretability, which is to say actually understanding and being able to manipulate the specific concepts that an AI model uses
I think this is a good description of what agent foundations is and why it might be needed. But the binary of 'either we get alignment by default or we need to find the True Name' isn't how I think about it.
Rather, there's some unknown parameter, something like 'how sharply does the pressure towards incorrigibility ramp up, what capability level does it start at, how strong is it'?
Setting this at 0 means alignment by default. Setting this higher and higher means we need various kinds of Prosaic alignment strategies which are better at keeping systems corri...
Like I said in my first comment, the in practice difficulty of alignment is obviously connected to timeline and takeoff speed.
But you're right that you're talking about the intrinsic difficulty of alignment Vs takeoff speed in this post, not the in practice difficulty.
But those are also still correlated, for the reasons I gave - mainly that a discontinuity is an essential step in Eleizer style pessimism and fast takeoff views. I'm not sure how close this correlation is.
Do these views come apart in other possible worlds? I.e. could you believe in a disconti...
three possibilities about AI alignment which are orthogonal to takeoff speed and timing
I think "AI Alignment difficulty is orthogonal to takeoff speed/timing" is quite conceptually tricky to think through, but still isn't true. It's conceptually tricky because the real truth about 'alignment difficulty' and takeoff speed, whatever it is, is probably logically or physically necessary: there aren't really alternative outcomes there. But we have a lot of logical uncertainty and conceptual confusion, so it still looks like there are different possibilities. St...
...catastrophists: when evolution was gradually improving hominid brains, suddenly something clicked - it stumbled upon the core of general reasoning - and hominids went from banana classifiers to spaceship builders. hence we should expect a similar (but much sharper, given the process speeds) discontinuity with AI.
gradualists: no, there was no discontinuity with hominids per se; human brains merely reached a threshold that enabled cultural accumulation (and in a meaningul sense it was culture that built those spaceships). similarly, we should not expect sudd
Compare this,
...[Shulman][22:18]
We're in the Eliezerverse with huge kinks in loss graphs on automated programming/Putnam problems.
Not from scaling up inputs but from a local discovery that is much bigger in impact than the sorts of jumps we observe from things like Transformers.
[Yudkowsky][22:21]
but, sure, "huge kinks in loss graphs on automated programming / Putnam problems" sounds like something that is, if not mandated on my model, much more likely than it is in the Paulverse. though I am a bit surprised because I would not have expected Paul
Summary of why I think the post's estimates are too low as estimates of what's required for a system capable of seizing a decisive strategic advantage:
To be an APS-like system OmegaStar needs to be able to control robots or model real world stuff and also plan over billions, not hundreds of action steps.
Each of those problems adds on a few extra OOMs that aren't accounted for in e.g. the setup for Omegastar (which can transfer learn across tens of thousands of games, each requiring thousands of action steps to win in a much less complicated environment tha...
Updates on this after reflection and discussion (thanks to Rohin):
Human Evolution tells us very little about the 'cognitive landscape of all minds' (if that's even a coherent idea) - it's simply a loosely analogous individual historical example
Saying Paul's view is that the cognitive landscape of minds might be simply incoherent isn't quite right - at the very least you can talk about the distribution over programs implied by the random initialization of a neural network.
I could have just said 'Paul doesn't see this strong generality attractor in the cogni...
Holden also mentions something a bit like Eliezer's criticism in his own write-up,
In particular, I think it's hard to rule out the possibility of ingenuity leading to transformative AI in some far more efficient way than the "brute-force" method contemplated here.
When Holden talks about 'ingenuity' methods that seems consistent with Eliezer's
...They're not going to be taking your default-imagined approach algorithmically faster, they're going to be taking an algorithmically different approach that eats computing power in a different way than you imagine
isn't trying to do anything like "sketch a probability distribution over the dynamics of an AI project that is nearing AGI". This includes all technical MIRI papers I'm familiar with.
I think this specific scenario sketch is from a mainstream AI safety perspective a case where we've already failed - i.e. we've invented a useless corrigibility intervention that we confidently but wrongly think is scalable.
...And if you try training the AI out of that habit in a domain of lower complexity and intelligence, it is predicted by me that generalizing that trained AI
One of the problems here is that, as well as disagreeing about underlying world models and about the likelihoods of some pre-AGI events, Paul and Eliezer often just make predictions about different things by default. But they do (and must, logically) predict some of the same world events differently.
My very rough model of how their beliefs flow forward is:
Paul
Low initial confidence on truth/coherence of 'core of generality'
→
Human Evolution tells us very little about the 'cognitive landscape of all minds' (if that's even a coherent idea) - it's simply a loo...
Great and extremely valuable discussion! There's one part that I really wished had been explored further - the fundamental difficulty of inner alignment:
...Joe Carlsmith: I do have some probability that the alignment ends up being pretty easy. For example, I have some probability on hypotheses of the form "maybe they just do what you train them to do," and "maybe if you just don't train them to kill you, they won't kill you." E.g., in these worlds, non-myopic consequentialist inner misalignment doesn't tend to crop up by default, and it's not that hard to fin
Different views about the fundamental difficulty of inner alignment seem to be a (the?) major driver of differences in views about how likely AI X risk is overall.
I strongly disagree with inner alignment being the correct crux. It does seem to be true that this is in fact a crux for many people, but I think this is a mistake. It is certainly significant.
But I think optimism about outer alignment and global coordination ("Catch-22 vs. Saving Private Ryan") is much bigger factor, and optimists are badly wrong on both points here.
Strong upvote, I would also love to see more disscussion on the difficulty of inner alignment.
which if true should preclude strong confidence in disaster scenarios
Though only for disaster scenarios that rely on inner misalignment, right?
... seem like world models that make sense to me, given the surrounding justifications
FWIW, I don't really understand those world models/intuitions yet:
- Re: "earlier patches not generalising as well as the deep algorithms" - I don't understand/am sceptical about the abstraction of "earlier patches" vs. "deep algori
And I think they are well enough motivated to stop their imminent annihilation, in a way that is more like avoiding mutual nuclear destruction than cosmopolitan altruistic optimal climate mitigation timing.
In my recent writeup of an investigation into AI Takeover scenarios I made an identical comparison - i.e. that the optimistic analogy looks like avoiding nuclear MAD for a while and the pessimistic analogy looks like optimal climate mitigation:
...It is unrealistic to expect TAI to be deployed if first there are many worsening warning shots involving dangero
Some comments on the model
General
- In defining the rate of AI progress and other related variables, we’ve assumed the practical impact of AI on the economy and society scales up roughly with AI ‘intelligence’, and in general used these terms (intelligence and capability) interchangeably. We have then asked if the growth of intelligence might involve sudden jumps or accelerate hyperbolically. However, as Karnofsky points out, the assumption that generality of intelligence = capability is probably false.
- There isn’t a single variable that captures all the conce
Some points that didn't fit into the main post:
If the slow scenarios capture reality better than the fast scenarios, then systems will be deployed deliberately and will initially be given power rather than seizing power. This means both that the systems won’t be so obviously dangerous that the misbehaviour is noticed early on and that there is still misalignment later on.
This switch from apparently benign to dangerous behaviour could be due to
- Power-seeking misaligned behaviour that is too subtle to notice in the training environment but is obvi
On reflection, I think you're right, and his report does apply to a wider range of scenarios, probably all of the ones we discuss excluding the brain-in-a-box scenarios.
However, I think the report's understanding of power-seeking AI does assume a takeoff that is not extremely fast, such that we end up deliberately deciding to deploy the potentially dangerous AI on a large scale, rather than a system exploding in capability almost immediately.
Given the assumptions of the brain-in-a-box scenario many of the corrective mechanisms the report discusses wouldn't...
Some points that didn't fit into the main post:
While these scenarios do not capture alI of the risks from transformative AI, participants in a recent survey aimed at leading AI safety/governance researchers estimated the first three of these scenarios to cover 50% of existential catastrophes from AI.
The full survey results break down as 16 % 'Superintelligence' (i.e. some version of 'brain-in-a-box'), 16 % WFLL 2 and 18 % WFLL 1, for a total of 49% of the probability mass explicitly covered by our report (Note that these are all means of distributions over...
The 'one big breakthrough' idea is definitely a way that you could have easy marginal intelligence improvements at HLMI, but we didnt't call the node 'one big breakthrough/few key insights needed' because that's not the only way it's been characterised. E.g. some people talk about a 'missing gear for intelligence', where some minor change that isn't really a breakthrough (like tweaking a hyperparameter in a model training procedure) produces massive jumps in capability. Like David said, there's a subsequent post where we go through the different ways the jump to HLMI could play out, and One Big Breakthrough (we call it 'few key breakthroughs for intelligence) is just one of them.
I agree that that was his object-level claim about GPT-3 coding a react app - that it's relatively simple and coherent and can acquire lots of different skills via learning, vs being a collection of highly specialised modules. And of relevance to this post, the first is a way that intelligence improvements could be easy, and the second is the way they could be hard. Our 'interpretation' was more about making explicit what the observation about GPT-3 was,
...GPT-3 is general enough that it can write a functioning app given a short prompt, despite the fact that
Perhaps this is a crux in this debate: If you think the 'agent-agnostic perspective' is useful, you also think a relatively steady state of 'AI Safety via Constant Vigilance' is possible. This would be a situation where systems that aren't significantly inner misaligned (otherwise they'd have no incentive to care about governing systems, feedback or other incentives) but are somewhat outer misaligned (so they are honestly and accurately aiming to maximise some complicated measure of profitability or approval, not directly aiming to do what we want them to ...
- They will not work in any environment outside of XLand (unless that environment looks very very similar to XLand).
In particular, I reject the idea that these agents have learned “general strategies for problem solving” or something like that, such that we should expect them to work in other contexts as well, perhaps with a little finetuning. I think they have learned general strategies for solving a specific class of games in XLand.
Strongly agree with this, although with the caveat that it's deeply impressive progress compared to the state of the art in ...
This is amazing. So it's the exact same agents performing well on all of these different tasks, not just the same general algorithm retrained on lots of examples. In which case, have they found a generally useful way around the catastrophic forgetting problem? I guess the whole training procedure, amount of compute + experience, and architecture, taken together, just solves catastrophic forgetting - at least for a far wider range of tasks than I've seen so far.
Could you use this technique to e.g. train the same agent to do well on chess and go?
I also notic...
It depends somewhat on what you mean by 'near term interpretability' - if you apply that term to research into, for example, improving the stability and ability to access the 'inner world models' held by large opaque langauge models like GPT-3, then there's a strong argument that ML based 'interpretability' research might be one of the best ways of directly working on alignment research,
And see this discussion for more,
Great post! I'm glad someone has outlined in clear terms what these failures look like, rather than the nebulous 'multiagent misalignment', as it lets us start on a path to clarifying what (if any) new mitigations or technical research are needed.
Agent-agnostic perspective is a very good innovation for thinking about these problems - is line between agentive and non-agentive behaviour is often not clear, and it's not like there is a principled metaphysical distinction between the two (e.g. Dennett and the Intentional Stance). Currently, big corporations ca...
Update to 'Modelling Continuous Progress'
I made an attempt to model intelligence explosion dynamics in this post, by attempting to make the very oversimplified exponential-returns-to-exponentially-increasing-intelligence model used by Bostrom and Yudkowsky slightly less oversimplified.
...This post tries to build on a simplified mathematical model of takeoff which was first put forward by Eliezer Yudkowsky and then refined by Bostrom in Superintelligence, modifying it to account for the different assumptions behind continuous, fast progress as opposed to disco
Is a bridge falling down the moment you finish building it an extreme and somewhat strange failure mode? In the space of all possible bridge designs, surely not. Most bridge designs fall over. But in the real world, you could win money all day betting that bridges won't collapse the moment they're finished.
I'm not saying this is an exact analogy for AGI alignment - there are lots of specific technical reasons to expect that alignment is not like bridge building and that there are reasons why the approaches we're likely to try will break on us suddenly in w...
Is a bridge falling down the moment you finish building it an extreme and somewhat strange failure mode? In the space of all possible bridge designs, surely not. Most bridge designs fall over. But in the real world, you could win money all day betting that bridges won't collapse the moment they're finished.
Yeah, that kiiiinda relies on literally anybody anywhere being able to sketch a bridge that wouldn't fall over, which is not the situation we are currently in.
I agree with your argument about likelihood of DSA being higher compared to previous accelerations, due to society not being able to speed up as fast as the technology. This is sorta what I had in mind with my original argument for DSA; I was thinking that leaks/spying/etc. would not speed up nearly as fast as the relevant AI tech speeds up.
Your post on 'against GDP as a metric' argues more forcefully for the same thing that I was arguing for, that
...'the economic doubling time' stops being so meaningful - technological progress speeds up abruptly but o
Currently the most plausible doom scenario in my mind is maybe a version of Paul’s Type II failure. (If this is surprising to you, reread it while asking yourself what terms like “correlated automation failure” are euphemisms for.)
This is interesting, and I'd like to see you expand on this. Incidentally I agree with the statement, but I can imagine both more and less explosive, catastrophic versions of 'correlated automation failure'. On the one hand it makes me think of things like transportation and electricity going haywire, on the other it could ...
Humans have skills and motivations (such as deception, manipulation and power-hungriness) which would be dangerous in AGIs. It seems plausible that the development of many of these traits was driven by competition with other humans, and that AGIs trained to answer questions or do other limited-scope tasks would be safer and less goal-directed. I briefly make this argument here.
Note that he claims that this may be true even if single/single alignment is solved, and all AGIs involved are aligned to their respective users.
It strikes me as interesting that muc...
Yeah - this is a case where how exactly the transition goes seems to make a very big difference. If it's a fast transition to a singleton, altering the goals of the initial AI is going to be super influential. But if it's that there are many generations of AIs that over time become the larger majority of the economy, then just control everything - predictably altering how that goes seems a lot harder at least.
Comparing the entirety of the Bostrom/Yudkowsky singleton intelligence explosion scenario to the slower more spread out scenario, it's not clear that...
That said, I remain interested in more clarity on what you see as the biggest risks with these multi/multi approaches that could be addressed with technical research.
A (though not necessarily the most important) reason to think technical research into computational social choice might be useful is that examining specifically the behaviour of RL agents from a computational social choice perspective might alert us to ways in which coordination with future TAI might be similar or different to the existing coordination problems we face.
...(i) make direct improvem
It's always possible to say, solving the single/single alignment problem will prevent anything like that from happening in the first place, but why put all your hopes on plan A, when plan B is relatively neglected?
The OP writes "contributions to AI alignment are also generally unhelpful to existential safety." I don't think I'm taking a strong stand in favor of putting all our hopes on plan A, I'm trying to understand the perspective on which plan B is much more important even before considering neglectedness.
...It seems premature to say, in advance of actual
Thanks for this long and very detailed post!
...The MARL projects with the greatest potential to help are probably those that find ways to achieve cooperation between decentrally trained agents in a competitive task environment, because of its potential to minimize destructive conflicts between fleets of AI systems that cause collateral damage to humanity. That said, even this area of research risks making it easier for fleets of machines to cooperate and/or collude at the exclusion of humans, increasing the risk of humans becoming gradually disenfranchi
Furthermore, we should take seriously the possibility that superintelligent AGIs might be even less focused than humans are on achieving large-scale goals. We can imagine them possessing final goals which don’t incentivise the pursuit of power, such as deontological goals, or small-scale goals.
...
My underlying argument is that agency is not just an emergent property of highly intelligent systems, but rather a set of capabilities which need to be developed during training, and which won’t arise without selection for it
Was this line of argument inspire...
The fact that an AI arms race would be extremely bad does not imply that rising global authoritarianism is not worth worrying about (and vice versa)
I am someone who is worried both about AI risks (from loss of control, and from war and misuse/structural risks) and from what seems to be a 'new axis' of authoritarian threats cooperating in unprecedented ways.
I won't reiterate all the evidence here, but these two pieces and their linked sources should suffice:
- https://www.noahpinion.blog/p/the-free-world-teeters-on-the-edge
- https://www.theatlantic.com/politics/
... (read more)