Stefan Heimersheim. Research Scientist at Apollo Research, Mechanistic Interpretability. The opinions expressed here are my own and do not necessarily reflect the views of my employer.
Posts
Wikitag Contributions
Here's a quick snipped to load the model into TransformerLens!
import torch
from transformers import GPT2LMHeadModel
from transformer_lens import HookedTransformer
model = GPT2LMHeadModel.from_pretrained("apollo-research/gpt2_noLN").to("cpu")
hooked_model = HookedTransformer.from_pretrained("gpt2", hf_model=model, fold_ln=False, center_unembed=False).to("cpu")
# Kill the LayerNorms because TransformerLens overwrites eps
for block in hooked_model.blocks:
block.ln1.eps = 1e12
block.ln2.eps = 1e12
hooked_model.ln_final.eps = 1e12
# Make sure the outputs are the same
prompt = torch.tensor([1,2,3,4], device="cpu")
logits = hooked_model(prompt)
logits2 = model(prompt).logits
print(logits.shape, logits2.shape)
print(logits[0, 0, :10])
print(logits2[0, :10])Nice work! I'm especially impressed by the [word] and [word] example: This cannot be read-off the embeddings, thus the model must be actually computing and storing this feature somewhere! I think this is exciting since the things we care about (deception etc.) are also definitely not included in the embeddings. I think you could make a similar case for Title Case and Beginning & End of First Sentence but those examples look less clear, e.g. the Title Case could be mostly stored in "embedding of uppercase word that is usually lowercase".
Thank you for making the early write-up! I'm not entirely certain I completely understand what you're doing, could I give you my understanding and ask you to fill the gaps / correct me if you have the time? No worries if not, I realize this is a quick & early write-up!
Setup:
As previously you run Pythia on a bunch of data (is this the same data for all of your examples?) and save its activations.
Then you take the residual stream activations (from which layer?) and train an autoencoder (like Lee, Dan & beren here) with a single hidden layer (w/ ReLU), larger than the residual stream width (how large?), trained with an L1-regularization on the hidden activations. This L1-regularization penalizes multiple hidden activations activating at once and therefore encourages encoding single features as single neurons in the autoencoder.
Results:
You found a bunch of features corresponding to a word or combined words (= words with similar meaning?). This would be the embedding stored as a features (makes sense).
But then you also find e.g. a "German Feature", a neuron in the autoencoder that mostly activates when the current token is clearly part of a German word. When you show Uniform examples you show randomly selected dataset examples? Or randomly selected samples where the autoencoder neuron is activated beyond some threshold?
When you show Logit lens you show how strong the embedding(?) or residual stream(?) at a token projects into the read-direction of that particular autoencoder neuron?
In Ablated Text you show how much the autoencoder neuron activation changes (change at what position?) when ablating the embedding(?) / residual stream(?) at a certain position (same or different from the one where you measure the autoencoder neuron activation?). Does ablating refer to setting some activations at that position to zero, or to running the model without that word?
Note on my use of the word neuron: To distinguish residual stream features from autoencoder activations, I use neuron to refer to the hidden activation of the autoencoder (subject to an activation function) while I use feature to refer to (a direction of) residual stream activations.
Hi, and thanks for the comment!
Do you think there should be a preference to the whether one patches clean --> corrupt or corrupt --> clean?
Both of these show slightly different things. Imagine an "AND circuit" where the result is only correct if two attention heads are clean. If you patch clean->corrupt (inserting a clean attention head activation into a corrupt prompt) you will not find this; but you do if you patch corrupt->clean. However the opposite applies for a kind of "OR circuit". I historically had more success with corrupt->clean so I teach this as the default, however Neel Nanda's tutorials usually start the other way around, and really you should check both. We basically ran all plots with both patching directions and later picked the ones that contained all the information.
did you find that the selection of [the corrupt words] mattered?
Yes! We tried to select equivalent words to not pick up on properties of the words, but in fact there was an example where we got confused by this: We at some point wanted to patch param and naively replaced it with arg, not realizing that param is treated specially! Here is a plot of head 0.2's attention pattern; it behaves differently for certain tokens. Another example is the self token: It is treated very differently to the variable name tokens.
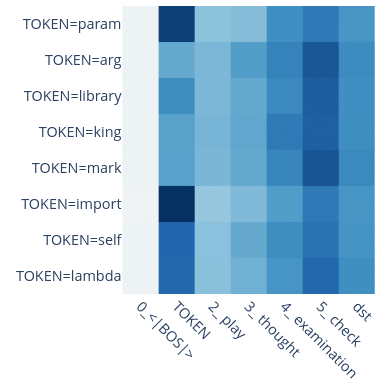
{kind=link}
So it definitely matters. If you want to focus on a specific behavior you probably want to pick equivalent tokens to avoid mixing in other effects into your analysis.
Thank for for the extensive comment! Your summary is really helpful to see how this came across, here's my take on a couple of these points:
2.b: The network would be sneaking information about the size of the residual stream past LayerNorm. So the network wants to implement an sort of "grow by a factor X every layer" and wants to prevent LayerNorm from resetting its progress.
- There's the difference between (i) How does the model make the residual stream grow exponentially -- the answer is probably theory 1, that something in the weights grow exponentially. And there is (ii) our best guess on Why the model would ever want this, which is the information deletion thing.
How and why disconnected
Yep we give some evidence for How, but for Why we have only a guess.
still don't feel like I know why though
earn generic "amplification" functions
Yes, all we have is some intuition here. It seems plausible that the model needs to communicate stuff between some layers, but doesn't want this to take up space in the residual stream. So this exponential growth is a neat way to make old information decay away (relatively). And it seems plausible to implement a few amplification circuits for information that has to be preserved for much later in the network.
We would love to see more ideas & hypotheses on why the model might be doing this, as well as attempts to test this! We mainly wrote-up this post because both Alex and I independently noticed this and weren't aware of this previously, so we wanted to make a reference post.
And here's the code to do it with replacing the LayerNorms with identities completely: