All of steven0461's Comments + Replies
This seems to be missing what I see as the strongest argument for "utopia": most of what we think of as "bad values" in humans comes from objective mistakes in reasoning about the world and about moral philosophy, rather than from a part of us that is orthogonal to such reasoning in a paperclip-maximizer-like way, and future reflection can be expected to correct those mistakes.
future reflection can be expected to correct those mistakes.
I'm pretty worried that this won't happen, because these aren't "innocent" mistakes. Copying from a comment elsewhere:
...Why did the Malagasy people have such a silly belief? Why do many people have very silly beliefs today? (Among the least politically risky ones to cite, someone I’ve known for years who otherwise is intelligent and successful, currently believes, or at least believed in the recent past, that 2⁄3 of everyone will die as a result of taking the COVID vaccines.) I think the unfort
Is it naive to imagine AI-based anti-propaganda would also be significant? E.g. "we generated AI propaganda for 1000 true and 1000 false claims and trained a neural net to distinguish between the two, and this text looks much more like propaganda for a false claim".
What does GDP growth look like in this world?
Another reason the hype fades is that a stereotype develops of the naive basement-dweller whose only friend is a chatbot and who thinks it’s conscious and intelligent.
Things like this go somewhat against my prior for how long it takes for culture ...
Thanks for the critique!
Propaganda usually isn't false, at least not false in a nonpartisan-verifiable way. It's more about what facts you choose to emphasize and how you present them. So yeah, each ideology/faction will be training "anti-propaganda AIs" that will filter out the propaganda and the "propaganda" produced by other ideologies/factions.
In my vignette so far, nothing interesting has happened to GDP growth yet.
I think stereotypes can develop quickly. I'm not saying it's super widespread and culturally significant, just that it blunts the hype a ...
A few of the answers seem really high. I wonder if anyone interpreted the questions as asking for P(loss of value | insufficient alignment research) and P(loss of value | misalignment) despite Note B.
I would add "will relevant people expect AI to have extreme benefits, such as a significant percentage point reduction in other existential risk or a technological solution to aging"
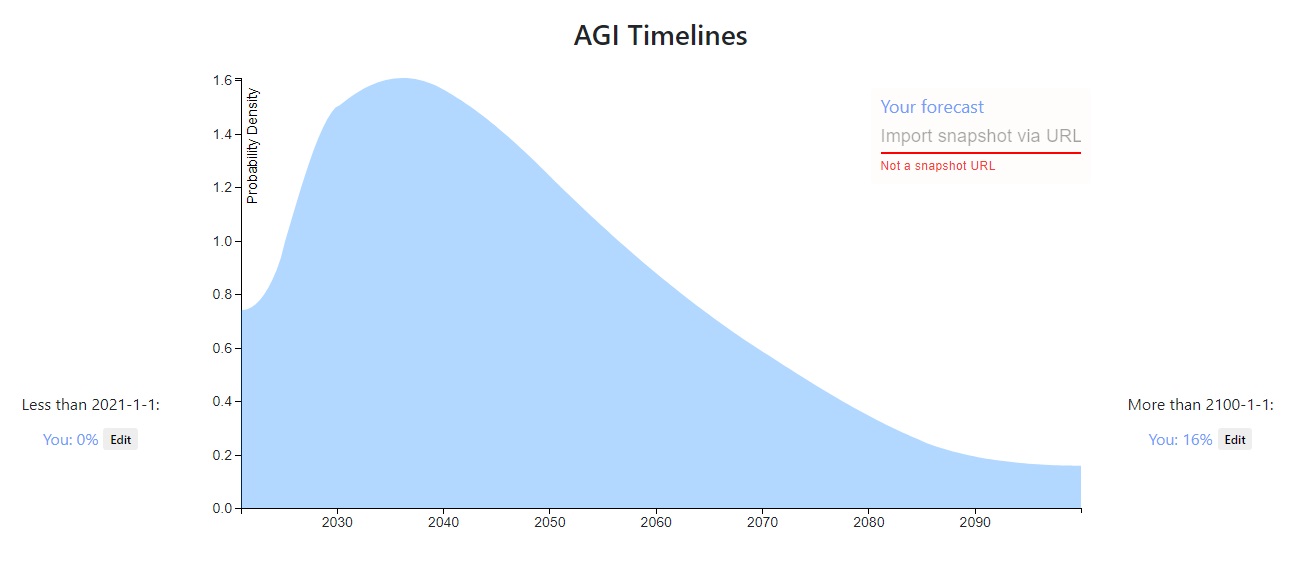
To the extent that it differs from others' predictions, probably the most important factor is that I think even if AGI is hard, there are a number of ways in which human civilization could become capable of doing almost arbitrarily hard things, like through human intelligence enhancement or sufficiently transformative narrow AI. I think that means the question is less about how hard AGI is and more about general futurism than most people think. It's moderately hard for me to imagine how business as usual could go on for the rest of the...
I meant to assume that away:
But we'll assume that her information stays the same while her utility function is being inferred, and she's not doing anything to get more; perhaps she's not in a position to.
In cases where you're not in a position to get more information about your utility function (e.g. because the humans you're interacting with don't know the answer), your behavior won't depend on whether or not you think it would be useful to have more information about your utility function, so someone observing your beh...
I tend to want to split "value drift" into "change in the mapping from (possible beliefs about logical and empirical questions) to (implied values)" and "change in beliefs about logical and empirical questions", instead of lumping both into "change in values".