All of Tamsin Leake's Comments + Replies
So this option looks unattractive if you think transformative AI systems are likely to developed within the next 5 years. However, with a 10-years timeframe things look much stronger: you would still have around 5 years to contribute as a research.
This phrasing is tricky! If you think TAI is coming in approximately 10 years then sure, you can study for 5 years and then do research for 5 years.
But if you think TAI is coming within 10 years (for example, if you think that the current half-life on worlds surviving is 10 years; if you think 10 years is the ...
I'm confused about why 1P-logic is needed. It seems to me like you could just have a variable X which tracks "which agent am I" and then you can express things like sensor_observes(X, red) or is_located_at(X, northwest). Here and Absent are merely a special case of True and False when the statement depends on X.
Hence, the policy should have an escape clause: You should feel free to talk about the potential exfohazard if your knowledge of it isn't exclusively caused by other alignment researchers telling you of it. That is, if you already knew of the potential exfohazard, or if your own research later led you to discover it.
In an ideal world, it's good to relax this clause in some way, from a binary to a spectrum. For example: if someone tells me of a hazard that I'm confident I would've discovered one my own one week later, then they only get to dictate me not...
My current belief is that you do make some update upon observing existing, you just don't update as much as if we were somehow able to survive and observe unaligned AI taking over. I do agree that the no update at all because you can't see the counterfactual is wrong, but anthropics is still somewhat filtering your evidence; you should update less.
(I don't have my full reasoning for {why I came to this conclusion} fully loaded rn, but I could probably do so if needed. Also, I only skimmed your post, sorry. I have a post on updating under anthropics with actual math I'm working on, but unsure when I'll get around to finishing it.)
commenting on this post because it's the latest in the sequence; i disagree with the premises of the whole sequence. (EDIT: whoops, the sequence posts in fact discuss those premises so i probably should've commented on those. ohwell.)
the actual, endorsed, axiomatic (aka terminal aka intrinsic) values we have are ones we don't want to change, ones we don't want to be lost or modified over time. what you call "value change" is change in instrumental values.
i agree that, for example, our preferences about how to organize the society we live in should change o...
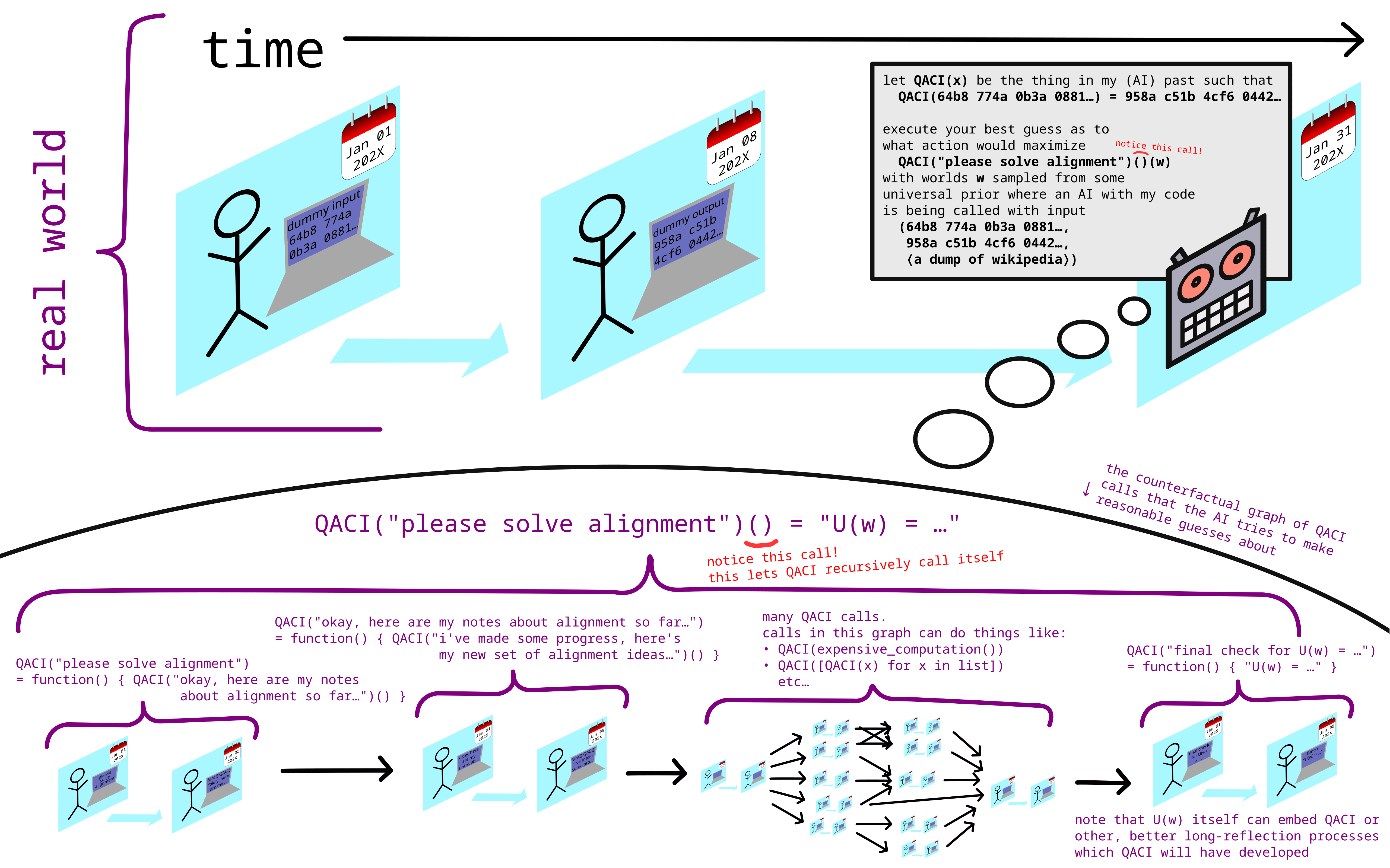
one solution to this problem is to simply never use that capability (running expensive computations) at all, or to not use it before the iterated counterfactual researchers have developed proofs that any expensive computation they run is safe, or before they have very slowly and carefully built dath-ilan-style corrigible aligned AGI.
Reposting myself from discord, on the topic of donating 5000$ to EA causes.
... (read more)I agree that there's no substitute for thinking about this for yourself, but I think that morally or socially counting "spending thousands of dollars on yourself, an AI researcher" as a donation would be an apalling norm. There are already far too many unmanaged conflicts of interest and trust-me-it's-good funding arrangements in this space for me, and I think it leads to poor epistemic norms as well as social and organizational dysfunction. I think it's very easy for donating to people or organizations in your social circle to have substantial negative ... (read more)