All of Vivek Hebbar's Comments + Replies
We're then going to use a small amount of RL (like, 10 training episodes) to try to point it in this direction. We're going to try to use the RL to train: "Act exactly like [a given alignment researcher] would act."
Why are we doing RL if we just want imitation? Why not SFT on expert demonstrations?
Also, if 10 episodes suffices, why is so much post-training currently done on base models?
If the agent follows EDT, it seems like you are giving it epistemically unsound credences. In particular, the premise is that it's very confident it will go left, and the consequence is that it in fact goes right. This was the world model's fault, not EDT's fault. (It is notable though that EDT introduces this loopiness into the world model's job.)
The idea of dividing failure stories into "failures involving rogue deployments" and "other failures" seems most useful if the following argument goes through:
1. Catastrophes require a very large (superhuman?) quantity and/or quality of intellectual labor
2. Either this labor is done by AIs in approved scaffolds, or it is done in "rogue deployments"
3. Hence the only easy-by-default disaster route is through a rogue deployment
4. Hence if we rule out rogue deployments and very impressive/difficult malicious labor in our scaffolds, we are safe
This seems true f...
This google search seems to turn up some interesting articles (like maybe this one, though I've just started reading it).
Paul [Christiano] called this “problems of the interior” somewhere
Since it's slightly hard to find: Paul references it here (ctrl+f for "interior") and links to this source (once again ctrl+f for "interior"). Paul also refers to it in this post. The term is actually "position of the interior" and apparently comes from military strategist Carl von Clausewitz.
Here's a fun thing I noticed:
There are 16 boolean functions of two variables. Now consider an embedding that maps each of the four pairs {(A=true, B=true), (A=true, B=false), ...} to a point in 2d space. For any such embedding, at most 14 of the 16 functions will be representable with a linear decision boundary.
For the "default" embedding (x=A, y=B), xor and its complement are the two excluded functions. If we rearrange the points such that xor is linearly represented, we always lose some other function (and its complement). In fact...
The variance of the multivariate uniform distribution is largest along the direction , which is exactly the direction which we would want to represent a AND b.
The variance is actually the same in all directions. One can sanity-check by integration that the variance is 1/12 both along the axis and along the diagonal.
In fact, there's nothing special about the uniform distribution here: The variance should be independent of direction for any N-dimensional joint distribution where the N constituent distributions are ind...
POV: I'm in an ancestral environment, and I (somehow) only care about the rewarding feeling of eating bread. I only care about the nice feeling which comes from having sex, or watching the birth of my son, or being gaining power in the tribe. I don't care about the real-world status of my actual son, although I might have strictly instrumental heuristics about e.g. how to keep him safe and well-fed in certain situations, as cognitive shortcuts for getting reward (but not as terminal values).
Would such a person sacrifice themselves for their children (in situations where doing so would be a fitness advantage)?
Agreed. To give a concrete toy example: Suppose that Luigi always outputs "A", and Waluigi is {50% A, 50% B}. If the prior is {50% luigi, 50% waluigi}, each "A" outputted is a 2:1 update towards Luigi. The probability of "B" keeps dropping, and the probability of ever seeing a "B" asymptotes to 50% (as it must).
This is the case for perfect predictors, but there could be some argument about particular kinds of imperfect predictors which supports the claim in the post.

In ML terms, nearly-all the informational work of learning what “apple” means must be performed by unsupervised learning, not supervised learning. Otherwise the number of examples required would be far too large to match toddlers’ actual performance.
I'd guess the vast majority of the work (relative to the max-entropy baseline) is done by the inductive bias.
As I understand Vivek's framework, human value shards explain away the need to posit alignment to an idealized utility function. A person is not a bunch of crude-sounding subshards (e.g. "If
food nearbyandhunger>15, then be more likely togo to food") and then also a sophisticated utility function (e.g. something like CEV). It's shards all the way down, and all the way up.[10]
This read to me like you were saying "In Vivek's framework, value shards explain away .." and I was confused. I now think you mean "My take on Vivek's is that value s...
"Well, what if I take the variables that I'm given in a Pearlian problem and I just forget that structure? I can just take the product of all of these variables that I'm given, and consider the space of all partitions on that product of variables that I'm given; and each one of those partitions will be its own variable.
How can a partition be a variable? Should it be "part" instead?
ETA: Koen recommends reading Counterfactual Planning in AGI Systems before (or instead of) Corrigibility with Utility Preservation
Update: I started reading your paper "Corrigibility with Utility Preservation".[1] My guess is that readers strapped for time should read {abstract, section 2, section 4} then skip to section 6. AFAICT, section 5 is just setting up the standard utility-maximization framework and defining "superintelligent" as "optimal utility maximizer".
Quick thoughts after reading less than half:
AFAICT,[2] this is a mathematica...
OK, Below I will provide links to few mathematically precise papers about AGI corrigibility solutions, with some comments. I do not have enough time to write short comments, so I wrote longer ones.
This list or links below is not a complete literature overview. I did a comprehensive literature search on corrigibility back in 2019 trying to find all mathematical papers of interest, but have not done so since.
I wrote some of the papers below, and have read all the rest of them. I am not linking to any papers I heard about but did not read (yet).
Math-based w...
- Try to improve my evaluation process so that I can afford to do wider searches without taking excessive risk.
Improve it with respect to what?
My attempt at a framework where "improving one's own evaluator" and "believing in adversarial examples to one's own evaluator" make sense:
- The agent's allegiance is to some idealized utility function (like CEV). The agent's internal evaluator is "trying" to approximate by reasoning heuristically. So now we ask Eval to evaluate the plan "do argmax w.r.t
Yeah, the right column should obviously be all 20s. There must be a bug in my code[1] :/
I like to think of the argmax function as something that takes in a distribution on probability distributions on with different sigma algebras, and outputs a partial probability distribution that is defined on the set of all events that are in the sigma algebra of (and given positive probability by) one of the components.
Take the following hypothesis :
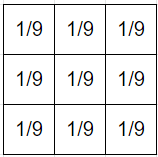
If I add this into with weight , then the middle column is still near...
Now, let's consider the following modification: Each hypothesis is no longer a distribution on , but instead a distribution on some coarser partition of . Now is still well defined
Playing around with this a bit, I notice a curious effect (ETA: the numbers here were previously wrong, fixed now):
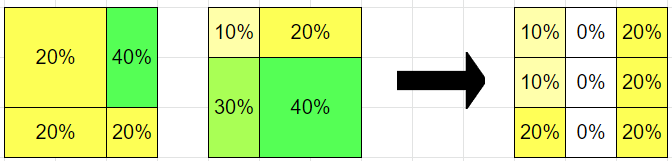
The reason the middle column goes to zero is that hypothesis A puts 60% on the rightmost column, and hypothesis B puts 40% on the leftmost, and neither cares about the middle column specifically.
But philosophically, what d...
A framing I wrote up for a debate about "alignment tax":
- "Alignment isn't solved" regimes:
- Nobody knows how to make an AI which is {safe, general, and broadly superhuman}, with any non-astronomical amount of compute
- We know how to make an aligned AGI with 2 to 25 OOMs more compute than making an unaligned one
- "Alignment tax" regimes:
- We can make an aligned AGI, but it requires a compute overhead in the range 1% - 100x. Furthermore, the situation remains multipolar and competitive for a while.
- The alignment tax is <0.001%, so it's not a concern.
- The leadi
If the system is modular, such that the part of the system representing the goal is separate from the part of the system optimizing the goal, then it seems plausible that we can apply some sort of regularization to the goal to discourage it from being long term.
What kind of regularization could this be? And are you imagining an AlphaZero-style system with a hardcoded value head, or an organically learned modularity?
Pr π∈ξ [U(⌈G⌉,π) ≥ U(⌈G⌉,G*)]is the probability that, for a random policyπ∈ξ, that policy has worse utility than the policyG*its program dictates; in essence, how goodG's policies are compared to random policy selection
What prior over policies?
given
g(G|U), we can infer the probability that an agentGhas a given utility functionU, asPr[U] ∝ 2^-K(U) / Pr π∈ξ [U(⌈G⌉,π) ≥ U(⌈G⌉,G*)])where∝means "is proportional to" andK(U)is the kolmogorov complexity of utility functionU.
Suppose the prior over policies is max-entropy (uniform over all action seq...
I have seen one person be surprised (I think twice in the same convo) about what progress had been made.
ETA: Our observations are compatible. It could be that people used to a poor and slow-moving state of interpretability are surprised by the recent uptick, but that the absolute progress over 6 years is still disappointing.
The perspective and the computations that are presented here (which in my opinion are representative of the mathematical parts of the linked posts and of various other unnamed posts) do not use any significant facts about neural networks or their architecture.
You're correct that the written portion of the Information Loss --> Basin flatness post doesn't use any non-trivial facts about NNs. The purpose of the written portion was to explain some mathematical groundwork, which is then used for the non-trivial claim. (I did not know at the time ...
Note that, for rational *altruists* (with nothing vastly better to do like alignment), voting can be huge on CDT grounds -- if you actually do the math for a swing state, the leverage per voter is really high. In fact, I think the logically counterfactual impact-per-voter tends to be lower than the impact calculated by CDT, if the election is very close.

From this paper, "Theoretical work limited to ReLU-type activation functions, showed that in overparameterized networks, all global minima lie in a connected manifold (Freeman & Bruna, 2016; Nguyen, 2019)"
So for overparameterized nets, the answer is probably:
- There is only one solution manifold, so there are no separate basins. Every solution is connected.
- We can salvage the idea of "basin volume" as follows:
- In the dimensions perpendicular to the manifold, calculate the basin cross-section using the Hessian.
- In the dimensions parallel to the manifol
The loss is defined over all dimensions of parameter space, so is still a function of all 3 x's. You should think of it as . It's thickness in the direction is infinite, not zero.
Here's what a zero-determinant Hessian corresponds to:
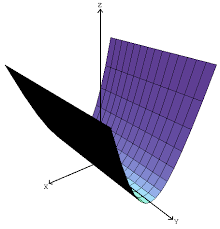
The basin here is not lower dimensional; it is just infinite in some dimension. The simplest way to fix this is to replace the infinity with some large value. Luckily, there is a fairly principled way to do this:
- Regularization / weight decay prov
I will split this into a math reply, and a reply about the big picture / info loss interpretation.
Math reply:
Thanks for fleshing out the calculus rigorously; admittedly, I had not done this. Rather, I simply assumed MSE loss and proceeded largely through visual intuition.
I agree that assuming MSE, and looking at a local minimum, you have
This is still false! Edit: I am now confused, I don't know if it is false or not.
You are conflating and . Adding disa...
Thanks for this reply, its quite helpful.
I feel it ought to be pointed out that what is referred to here as the key result is a standard fact in differential geometry called (something like) the submersion theorem, which in turn is essentially an application of the implicit function theorem.
Ah nice, didn't know what it was called / what field it's from. I should clarify that "key result" here just meant "key result of the math so far -- pay attention", not "key result of the whole post" or "profound/original".
...The Jacobian matrix is what you call
About the contours: While the graphic shows a finite number of contours with some spacing, in reality there are infinite contour planes and they completely fill space (as densely as the reals, if we ignore float precision). So at literally every point in space there is a blue contour, and a red one which exactly coincides with it.
Yep, I am assuming MSE loss generally, but as you point out, any smooth and convex loss function will be locally approximately quadratic. "Saddle points all the way down" isn't possible if a global min exists, since a saddle point implies the existence of an adjacent lower point. As for asymptotes, this is indeed possible, especially in classification tasks. I have basically ignored this and stuck to regression here.
I might return to the issue of classification / solutions at infinity in a later post, but for now I will say this: &...
Is the claim here that the 2^200 "persuasive ideas" would actually pass the scrutiny of top human researchers (for example, Paul Christiano studies one of them for a week and concludes that it is probably a full solution)? Or do you just mean that they would look promising in a shorter evaluation done for training purposes?
Though I understood what you meant, perhaps a clearer terminology is all-things-considered beliefs vs. independent impressions.
Do you want to try playing this game together sometime?