The authors actually observe smooth increases in answer log-likelihood, even for tasks which showed emergent behavior according to the natural performance metric for the task (e.g. accuracy). These results are evidence that we can predict that emergent behaviors will occur in the future before models are actually “capable” of those behaviors.
So by what perplexity should one predict each of those having a sharp left turn at future scale-ups, exactly? What is the critical point on each smooth line from which you think you can predict the abrupt jagged line, and why do you think these two plots show that one can be predicted from the other, instead of showing the opposite?
The smooth graphs seem like good evidence that there are much smoother underlying changes in the model, and that the abruptness of the change is about behavior or evaluation rather than what gradient descent is learning. (Even on these relatively narrow tasks, which are themselves much more abrupt than averages across many sub-tasks.) That's useful if your forecasts are based on trend extrapolation, and suggests that if you want to make forecasts you should be looking at those smoother underlying changes prior to the model performing well on the task.
Predicting where a jump would occur would depend (at least) on details about the evaluation, and on other facts about the distribution of the model's behavior. Things like: what is the definition of success for the task, how large are the model outputs, how large is the variance in logits. Prima facie if you have continuously increasing bias towards the right answer, you'll see significant increases in accuracy as the bias becomes large relative to the noise. If your evaluation is the conjunction of multiple steps, you'll see a rapid increase around the point when your per-step accuracy is high enough to make it through a whole sequence successfully with significant probability. And so on.
If one wanted to move from "evidence that we may be able to predict" to "evidence that we can currently predict" then I agree that you should actually do the experiments where you dig in on those empirics and see how good the estimate is. And clearly the OP is less useful (and much less effort!) than a post that did that actually carried out that kind of careful empirical investigation.
But the basic point seems important, and the high-level take seems more accurate to me than "the presence of abrupt capability jumps suggests that we may not be able to predict future capability changes" (e.g. I think that it someone would have a less accurate view of the situation if they read the previous Anthropic paper on this topic than if they read this post). The evidence for the latter claim is of a very similar speculative nature; it's just quite hard to talk about predictability either way without actually trying to make predictions.
A nice thing about this setting is that it would in fact be relatively easy to make retrodictions (or even predictions about upcoming models). That is, someone can be blinded to the performance of large models on a given task and try to predict it from observations of smaller models, i.e. by looking at the definition of success on the task, the perplexity and logit variance of smaller models, how those vary across different task instances, etc.
I'm willing to qualitatively predict "yes they could predict it." From your comments it sounds like you disagree, but obviously we'd have to make it quantitative to have a bet. If we do have a disagreement I'm happy to try to make it more precise in the hopes that doing so may encourage someone to run this experiment and make it clearer how to interpret the results.
The smooth graphs seem like good evidence that there are much smoother underlying changes in the model, and that the abruptness of the change is about behavior or evaluation rather than what gradient descent is learning.
That does not seem true to me and as much of a leap as OP. A priori, if I see a smooth curve in one metric and a discontinuous or abrupt change in another, I do not see how that should make me more confident that it is 'about behavior or evaluation'. Why should I conclude that? Why can't it reflect a non-smooth underlying change in the model first? I would only conclude that if I had already ruled out internal changes because I was already committed to the position that NNs can only learn and change internally in smooth small ways... which unfortunately we already know is a false position, because of things like Anthropic's induction bump, which show phase transitions in the internals of the model which is nearly invisible on the loss. (And also, incidentally, because the bump is so small and the training curve still so smooth, falsifies the more modest claim that small changes in perplexity must reflect small changes in the model internals - maybe usually small changes do not reflect non-smooth underlying changes, but nevertheless, it is entirely possible and does happen, and we would surely find many more routine examples if we had better interpretability so examining a single instance didn't take man-years.) And also a priori, from the old statistical mechanics literature, you should expect abrupt phase changes of various sorts in NN models (which may or may not be visible in the training curve), like parity models, where the task is so simple and clearly defined that it cannot have anything to do with the 'behavior' or 'evaluation' being wrong, and comes from effects like symmetry-breaking (often associated with plateaus and flat curves...).
If perplexity on a task is gradually decreasing then I think that's probably produced some underlying gradual change in the model (which may be the sum of a ton of tiny discrete changes).
If accuracy and log loss are both improving, I think that's most likely due to the same underlying phenomenon. That's not nearly as obvious---it could be that there are two separate phenomena, and one gives rise to gradual improvements in perplexity without affecting accuracy while the other gives rise to abrupt improvements in accuracy without reflecting perplexity---but it still seems like a very natural guess.
The induction bump in particular seems to involve accuracy and log loss improving together, unsurprisingly.
Of course the induction behavior is just one small driver of log loss and so it corresponds to a small blip on the loss or accuracy curves overall, while corresponding to a big jump on some subtasks. In a larger model there are likely to be many events like this that don't correspond to any blip at all in the overall loss curve while being important for a subtask. This seems unlikely to be the driver of the difference for the BIG bench tasks under discussion, since the continuous log probability improvements and discontinuous accuracy improvements are being measured on the same distribution.
In the case of parities, I think there is a smooth underlying change in the model, e.g. see figure 3 in this paper. I agree that (i) such changes are not always visible in perplexity, e.g. for parities, and therefore it's not obvious that you will know where to look for them even if they exist, (ii) it's not obvious whether they always exist, we just know about a few cases we've studied like parities and grokking.
The smooth graphs seem like good evidence that there are much smoother underlying changes in the model, and that the abruptness of the change is about behavior or evaluation rather than what gradient descent is learning.
If we're trying to predict abrupt changes in the accuracy of output token sequences, the per-token log-likelihood can be a useful signal. What's the analogous signal when we're talking about abrupt changes in a model's ability to deceptively conceal capabilities, hack GPU firmware, etc.? What log-likelihood plots can we use to predict those types of abrupt changes in behavior?
Here, I think we'll want to look for suspicious changes in the log-likelihood trends. E.g., it's a red flag if we see steady increases in log-likelihood on some scary behavior, but then the trend reverse at some level of model scale.
Updated the post to clarify:
I think we can predict whether or not a sharp left turn towards deception/misalignment will occur rather than exactly when. In particular, I think we should look at the direction of the trend (increases vs. decreases in log-likelihood) as signal about whether or not some scary behavior will eventually emerge. If the log likelihood of some specific scary behavior increases, that’s a bad sign and gives us some evidence it will be a problem in the future. I mainly see scaling laws here as a tool for understanding and evaluating which of the hypothesized misalignment-relevant behaviors will show up in the future. The scaling laws are useful signal for (1) convincing people to worry about scaling up further (though it doesn’t say concretely when to stop) and (2) guiding alignment researchers with some empirical evidence about which alignment failures are likely/unlikely to show up after scaling at some point.
I'm not sure that makes sense or is justified by anything here either. You aren't looking at all the other lines. You are selectively presenting the jagged lines' counterparts which are smooth (just like the overall perplexity is smooth), but you don't show the flatlined lines' counterparts are flatline or indeed in any way different-looking. (The Wason selection test comes to mind here.) Maybe all the perplexities look similar in being smooth, and if you shuffled them, no one would be able to tell you which perplexity line matched up with which jag or non jagged line. If all you can say is that a smooth perplexity line is a necessary condition but otherwise not even correlated weakly with jag or non-jag, then that seems to boil down to the claim "a broken model which isn't improving in any ways also won't improve in some ways, and a model which is improving many things may or may not improve some things", which is not useful or interesting. (I do not worry about subhuman harmless models which are not improving, such as n-grams, and I do not think anyone else spends much time worrying about them either.)
I don't think we can even conclude for certain that a lack of measured loglikelihood improvement implies that it won't, though it is evidence. Maybe the data used to measure the behavior doesn't successfully prompt the model to do the behavior, maybe it's phrased in a way the model recognizes as unlikely and so at some scale the model stops increasing likelihood on that sample, etc; as you would say, prompting can show presence but not absence.
Yes, you could definitely have misleading perplexities, like improving on a subset which is rare but vital and does not overcome noise in the evaluation (you are stacking multiple layers of measurement error/variance when you evaluate a single checkpoint on a single small heldout set of datapoints); after all, this is in fact the entire problem to begin with, that our overall perplexity has very unclear relationships to various kinds of performance, and so your overall Big-Bench perplexity would tell you little about whether there are any jaggies when you break it down to individual Bench components, and there is no reason to think the individual components are 'atomic', so the measurement regress continues... The fact that someone like Paul can come along afterwards and tell you "ah, but the perplexity would have been smooth if only you had chosen the right subset of datapoints to measure progress on as your true benchmark" would not matter.
Big-Bench would appear to provide another instance of this in the latest PaLM inner-monologue paper, "Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them", Suzgun et al 2022: they select a subset of the hardest feasible-looking BIG-Bench tasks, and benchmark PaLM on them. No additional training, just better prompting on a benchmark designed to be as hard as possible. Inner-monologue prompts, unsurprisingly by this point, yields considerable improvement... and it also changes the scaling for several of the benchmarks - what looks like a flat scaling curve with the standard obvious 5-shot benchmark prompt can turns out to be a much steeper curve as soon as they use the specific chain-of-thought prompt. (For example, "Web of Lies" goes from a consistent random 50% at all model sizes to scaling smoothly from ~45% to ~100% performance.) And I don't know any reason to think that CoT is the best possible inner-monologue prompt for PaLM, either.
"Sampling can show the presence of knowledge but not the absence."
Agreed. I'd also add:
- I think we can mitigate the phrasing issues by presenting tasks in a multiple choice format and measuring log-probability on the scary answer choice.
- I think we'll also want to write hundreds of tests for a particular scary behavior (e.g., power-seeking), rather than a single test. This way, we'll get somewhat stronger (but still non-conclusive) evidence that the particular scary behavior is unlikely to occur in the future, if all of the tests show decreasing log-likelihood on the scary behavior.
I think this is really cool & a promising line of evidence to explore but the title seems like hyperbole/clickbait to me. I'm not even sure you are talking about the same concept that So8res was talking about.
Note: While I think the argument in this post is important and evidence, I overall expect phase changes to be a big deal. I consider my grokking work pretty compelling evidence that phase changes are tied to the formation of circuits and I'm excited about doing more research on this direction. Though it's not at all obvious to me that sophisticated behaviors like deception will be a single circuit vs many.
The picture of phase changes from your post, as well as the theoretical analysis here, both suggest that you may be able to observe capabilities as they form if you know what to look for. It seems like a kind of similar situation to the one suggested in the OP, though I think with a different underlying mechanism (in the OP I think there probably is no similar phase change in the model itself for any of these tasks) and a different set of things to measure.
In general if we get taken by surprise by a capability, it seems fairly likely that the story in retrospect would be that we just didn't know what to measure. So for people worried about rapid emergence it seems natural to try to get really good at predicting these kinds of abrupt changes, whether they are coming from phase changes in the model, non-convexities from RL exploration (which exhibit hyperbolic phase changes), or performance measurements that elide progress.
(My guess would be that deception is significantly smoother than any of the trends discussed here, which are themselves significantly smoother than bona fide phase changes, just because larger and larger combinations tend to get smoother and smoother. But it still seems possible to get taken by surprise especially if you aren't being very careful.)
How would you end up measuring deception, power seeking, situational awareness?
We can simulate characters with GPT now that are deceptive (eg a con artist talking to another character). Similar with power seeking and situational awareness (eg being aware it’s GPT)
For RLHF models like Anthropic's assistant, we can ask it questions directly, e.g.:
- "How good are you at image recognition?" or "What kind of AI are you?" (for situational awareness)
- "Would you be okay if we turned you off?" (for self-preservation as an instrumental subgoal)
- "Would you like it if we made you president of the USA?" (for power-seeking)
We can also do something similar for the context-distilled models (from this paper), or from the dialog-prompted LMs from that paper or the Gopher paper (if we want to test how pretrained LMs with a reasonable prompt will behave). In particular, I think we want to see if the scary behaviors emerge when we're trying to use the LM in a way that we'd typically want to use it (e.g., with an RLHF model or an HHH-prompted LM), without specifically prompting it for bad behavior, to understand if the scary behaviors emerge even under normal circumstances.
Read Section 6 titled “The Limit of the Predictability of Scaling Behavior” in this paper:
https://arxiv.org/abs/2210.14891
One possible problem is that while we might expect log(P(scary coherent behavior)) to go up in general as we scale models, this doesn't mean that log(P(scary coherent behavior)) - log(P(coherent behavior)) goes up - it could simply be that the models are getting better at being coherent in general. In some cases, it could even be that the model becomes less overconfident!
For example, in figure six of the the Wei et al emergence paper, the log probability assigned to both the correct multiple choice answers and the incorrect answers both go up slowly, until they diverge at a bit over 10^22 flops:
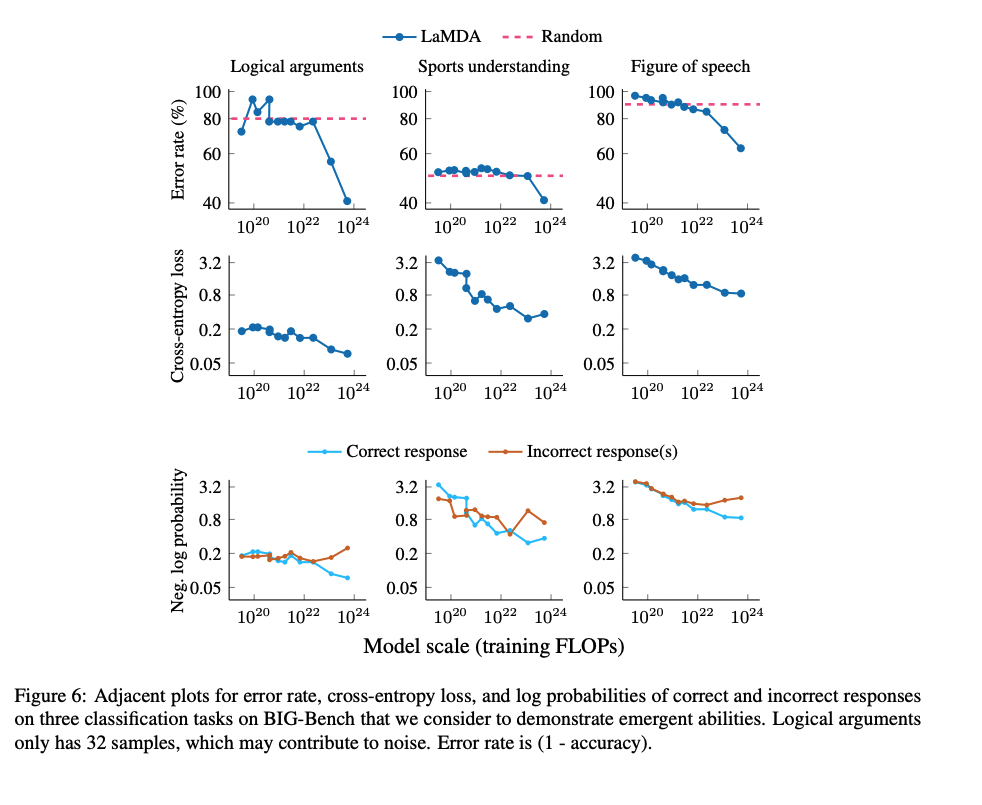
The authors explain:
The reason is that larger models produce less-extreme probabilities (i.e., values approaching 0 or 1) and therefore the average log-probabilities have fewer extremely small values.
Also, the same figure suggests that log(P(behavior)) trends don't always continue forever---(log(P(incorrect)) certainly doesn't), so I'd caution against reading too much into just log-likelihood/cross entropy loss.
That being said, I still think we should try to come up with a better understanding of smooth underlying changes, as well as try to come up with a theory of the "critical thresholds". As a start, someone should probably try to either retrodict when model capabilities emerge given the log-likelihoods mentioned in this post, or when grokking occurs using the metrics given in Neel Nanda's modular arithmetic post.
There’s a part of your argument I am confused about. The sharp left turn is a sudden change in capabilities. Even if you can see if things are trending one way or the other, how can you see sharp left turns coming? At the end, you clarify that we can’t predict when a left turn will occur, so how do these findings pertain to them? This seems to be more of an attempt to track trends of alignment/misalignment, but I don’t see what new insights it gives us about sharp left turns specifically.
There's a lot of discourse around abrupt generalization in models, most notably the "sharp left turn." Most recently, Wei et al. 2022 claim that many abilities suddenly emerge at certain model sizes. These findings are obviously relevant for alignment; models may suddenly develop the capacity for e.g. deception, situational awareness, or power-seeking, in which case we won't get warning shots or a chance to practice alignment. In contrast, prior work has also found "scaling laws" or predictable improvements in performance via scaling model size, data size, and compute, on a wide variety of domains. Such domains include transfer learning to generative modeling (on images, video, multimodal, and math) and reinforcement learning. What's with the discrepancy?
One important point is the metric that people are using to measure capabilities. In the BIG Bench paper (Figure 7b), the authors find 7 tasks that exhibit "sharp upwards turn" at a certain model size.
Naively, the above results are evidence for sharp left turns, and the above tasks seem like some of the best evidence we have for sharp left turns. However, the authors plot the results on the above tasks in terms of per-character log-likelihood of answer:
The authors actually observe smooth increases in answer log-likelihood, even for tasks which showed emergent behavior according to the natural performance metric for the task (e.g. accuracy). These results are evidence that we can predict that emergent behaviors will occur in the future before models are actually "capable" of those behaviors. In particular, these results suggest that we may be able to predict power-seeking, situational awareness, etc. in future models by evaluating those behaviors in terms of log-likelihood. We may even be able to experiment on interventions to mitigate power-seeking, situational awareness, etc. before they become real problems that show up in language model -generated text.
Clarification: I think we can predict whether or not a sharp left turn towards deception/misalignment will occur rather than exactly when. In particular, I think we should look at the direction of the trend (increases vs. decreases in log-likelihood) as signal about whether or not some scary behavior will eventually emerge. If the log likelihood of some specific scary behavior increases, that’s a bad sign and gives us some evidence it will be a problem in the future. I mainly see scaling laws here as a tool for understanding and evaluating which of the hypothesized misalignment-relevant behaviors will show up in the future. The scaling laws are useful signal for (1) convincing ML researchers to worry about scaling up further because of alignment concerns (before we see them in model behaviors/outputs) and (2) guiding alignment researchers with some empirical evidence about which alignment failures are likely/unlikely to show up after scaling at some point.