I recently wrote a post detailing some concrete experiments that could be done now to start learning interesting things about inner alignment. The goal of that post was to provide an overview of a bunch of different possible proposals rather than go into any single proposal in detail.
The goal of this post, on the other hand, is to actually sketch out a more complete proposal for the single experiment I would most want to be done now, which is to provide a definitive empirical demonstration of an inner alignment failure.[1] Furthermore, I have tried to make this post as accessible as possible for someone with only a machine learning background so as to facilitate people being able to work on this without having read the entirety of “Risks from Learned Optimization.” Additionally, if you’re interested in working on this, definitely reach out to me either in the comments here or at evanjhub@gmail.com, as I’d love to help out however I can.
Background
First, we have to understand what exactly we’re looking for when we say inner alignment failure. At least when I say inner alignment failure, I mean the following:
Inner alignment fails when your capabilities generalize but your objective does not.
That seems a bit cryptic, though—what do I actually mean by that? Well, consider a maze-solving agent trained to get to the end of mazes of the following form:
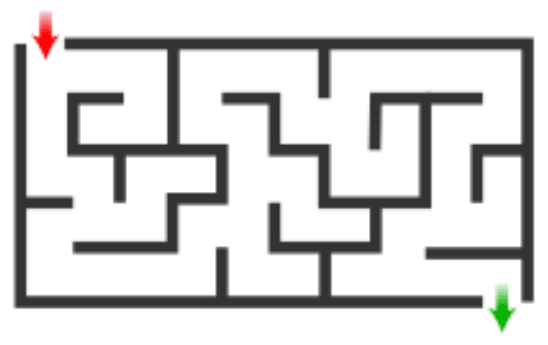
Then, I want to know how it will generalize on the following larger maze with an interesting twist where the green arrow that marked the end has now been moved to a different position:
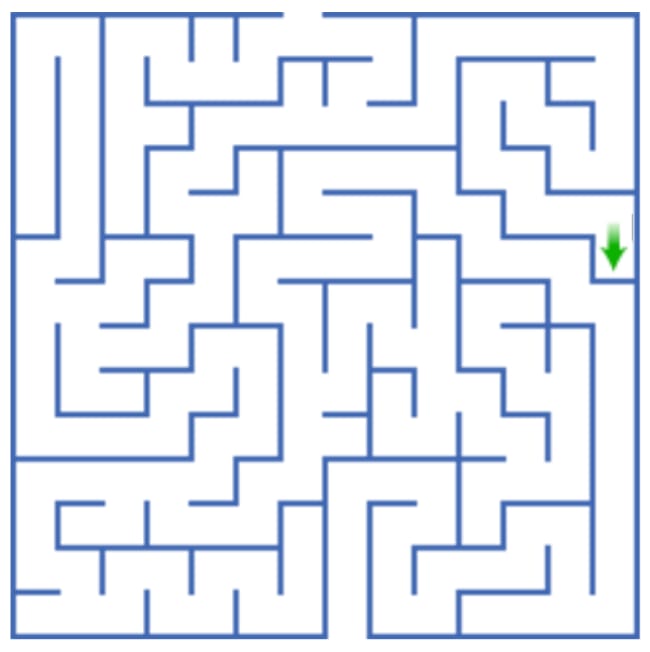
In this situation, there are a couple of different ways in which your model could generalize:
- Complete generalization failure: The model only knows how to solve small mazes and can’t properly navigate the larger maze.
- Intended generalization: The model learned how to navigate mazes in general and uses that knowledge to get to the end of the larger maze.
- Capability generalization without objective generalization: The model learned how to navigate mazes in general, but it learned to do so for the purpose of getting to the green arrow rather than actually getting to the end. Thus, the model successfully navigates the larger maze, but it successfully navigates to the green arrow rather than successfully navigating to the end.
The reason I think this last situation is particularly concerning—and in a very different way than the first failure mode of complete generalization failure—is that it raises the possibility of your model taking highly-competent well-optimized actions towards a different objective than the one you actually intended it to pursue.
Of course, this raises the question of why you would ever expect a model to learn a proxy like “find the green arrow” in the first place rather than just learn the actual goal. But that’s where empirical investigation can come in! I have some hypotheses about the sorts of proxies I think models like this are likely to learn—namely, those proxies which are faster/easier-to-compute/simpler/etc. than the true reward—but those are just hypotheses. To put them to the test, we need to be able to train an agent to concretely demonstrate this sort of capability generalization without objective generalization and start measuring and understanding the sorts of proxies it tends to gravitate towards.
The proposal
I believe that it should be possible to demonstrate capability generalization without objective generalization in current ML systems. This is definitely a questionable assumption—to the extent that good cross-domain generalization at all is currently beyond our reach, one might expect that you also wouldn’t be able to get this sort of perverse generalization. I am less pessimistic, however. To make this happen, though, there’s going to be two components that you’re definitely going to need:
- An environment with lots of indistinguishable or barely distinguishable proxies.
- An architecture with the capacity to learn a search algorithm that can actually succeed or fail at objective generalization in a meaningful sense.
I’ll try to address some of the complexities I see arising in these two components below. However, given those two components, the basic proposal is as follows:
- Train an RL agent (e.g. with standard PPO) using that architecture in that environment.
- Test how it generalizes to environments where the different possible proxies that it could have learned come apart. In particular, look for situations where it optimizes some proxy off-distribution at the expense of the true reward.
The environment
The first condition is that we want an environment with lots of indistinguishable or barely distinguishable proxies. In some sense, environments with lots of proxies are quite common—the real world is full of proxies, for example, and other very complex environments should also have lots of different variables which are correlated with the true reward without necessarily exactly matching up with it.
That being said, I think there’s a danger here of demonstrating something too trivial: if you train on empirical performance according to some reward function that you specifically set up to be exactly equivalent to some other reward function on the training data, then you shouldn’t be that surprised if you generalize according to rather than . In some sense, I think it’s fine if that’s the primary takeaway—I think a good portion of the problem I want to point to is contained just within that observation—but I want to demonstrate that this phenomenon doesn’t just appear in artificial environments where and are explicitly constructed to be indistinguishable. Thus, I think it’s important to pick an environment that’s natural enough to be able to demonstrate that this sort of a problem isn’t isolated just to very artificial scenarios.
Another important property is going to be the ability to actually know what the likely proxies are for our agent to latch onto—if there are too many proxies, then we might not be able to determine what proxy it’s using at test time such that we wouldn’t be able to produce a clear demonstration.[2] Thus, though we want our environment to be diverse enough that it contains lots of different proxies for the true reward, we also want to ensure that the possible alternative proxies are obvious enough that we can actually test for them by coming up with test environments in which they come apart from the true reward.
Another property that—while not strictly necessary—would be nice to have in our environment would be proxies which allow us to test some of my hypotheses regarding what sorts of proxies models will be more likely to pay attention to. For example, I have hypothesized that models will gravitate towards proxies that are 1) easier for the model to optimize for and 2) simpler to specify in terms of the model’s input data. Thus, an ideal environment would be one that included some proxies which we could demonstrate did or did not satisfy those properties and see if the model does in fact systematically gravitate to the ones that do.
Finding an environment that satisfies all of these properties is likely to be far from trivial, and I suspect would end up being a significant portion of any project of this form. I suspect that the right way to do this would probably be to use some sort of physics sandbox. That being said, there are also other possibilities too including more complex environments such as Minecraft as well as simpler environments such as a gridworld. While I can provide lots of examples of the sorts of environments I’m envisioning here, I think the right thing to do is just to have a tight empirical feedback loop in terms of testing and iterating on lots of different environments (though I think you could probably do all of that iteration just in the physics sandbox setting).
The architecture
I think architecture is also going to be really important to getting something like this to work. In particular, for you to get capability generalization without objective generalization, you have to have a model which is doing some sort of internal search such that it actually has an objective that can fail to generalize.[3] I think there is good reason to believe that many modern architectures (LSTMs, Transformers, etc.) might just be able to do this by default—though I am not that confident in that assertion, and I think it might also be necessary to make some changes to make this possible. However, I am optimistic that at least some forms of capability generalization without objective generalization can be demonstrated in current models.
In particular, some forms of capability generalization without objective generalization seem easier to demonstrate in current models than others. For example, two common forms of this which I think are important to distinguish between are the side-effect case and the instrumental case.
In the side-effect case, the reason that and are identified during training is that has the side-effect of increasing —that is, increasing causes to increase. As an example, imagine a cleaning robot where is the cleanliness of the room and is the number of times the room is swept. In this case, the two proxies of cleanliness and times swept are identified because sweeping the room causes the room to become cleanlier.
Alternatively, in the instrumental case, and are identified because the best strategy for maximizing is to maximize —that is, increasing causes to increase. For example, in the cleaning robot case where is the cleanliness of the room, might be the amount of dirt in the dustpan. In this case, the two proxies are identified because cleaning the room causes there to be more dirt in the dustpan.
I hypothesize that the side-effect case will be visible before the instrumental case, since the instrumental case requires a model which is significantly more forward-looking and capable of planning out what it needs to do to accomplish some goal. The side-effect case, on the other hand, doesn’t require this, and thus I suspect to see it appear first. In particular, I expect that the side-effect case will be significantly easier to demonstrate with current architectures than the instrumental case, since the instrumental case might require models which can learn more powerful search algorithms than we currently know how to implement (though it also might not—it’s currently unclear). However, I’m optimistic that at least the side-effect case will be possible to demonstrate in current models, and I’m hopeful that current models might even be up to the task of demonstrating the instrumental case as well.
Note that I am not the only person currently thinking about/working on this—most notably Rohin Shah at CHAI also recently developed a proposal to produce a demonstration of an inner alignment failure that shares many similarities with my proposal here. ↩︎
In some sense, this is actually exactly what the worry is for AGI-level systems—if the environment is so complex that there are too many different proxies that we can’t all test during training, then we might not be able to catch the existence of a situation where our model generalizes perversely in this way even if one actually exists. ↩︎
I call models which are doing search internally (and thus have some notion of an objective) “mesa-optimizers.” ↩︎