This concept has recently become a core part of my toolkit for thinking about the world, and I find it helps explain a lot of things that previously felt confusing to me. Here I explain how I understand “direction of fit,” and give some examples of where I find the concept can be useful.
Handshake Robot
A friend recently returned from an artificial life conference and told me about a robot which was designed to perform a handshake. It was given a prior about handshakes, or how it expected a handshake to be. When it shook a person’s hand, it then updated this prior, and the degree to which the robot would update its prior was determined by a single parameter. If the parameter was set low, the robot would refuse to update, and the handshake would be firm and forceful. If the parameter was set high, the robot would completely update, and the handshake would be passive and weak.
This parameter determines the direction of fit: whether the object in its mind will adapt to match the world, or whether the robot will adapt the world to match the object in its mind. This concept is often used in philosophy of mind to distinguish between a belief, which has a mind-to-world direction of fit, and a desire, which has a world-to-mind direction of fit. In this frame, beliefs and desires are both of a similar type: they both describe ways the world could be. The practical differences only emerge through how they end up interacting with the outside world.
Many objects seem not to be perfectly separable into one of these two categories, and rather appear to exist somewhere on the spectrum. For example:
An instrumental goal can simultaneously be a belief about the world (that achieving the goal will help fulfill some desire) as well as behaving like a desired state of the world in its own right.
Strongly held beliefs (e.g. religious beliefs) are on the surface ideas which are fit to the world, but in practice behave much more like desires, as people make the world around them fit their beliefs.
You can change your mind about what you desire. For example you may dislike something at first, but after repeated exposure you may come to feel neutral about it, or even actively like it (e.g. the taste of certain foods).
Furthermore, the direction of fit might be context dependent (e.g. political beliefs), beliefs could be self fulfilling (e.g. believing that a presentation will go well could make it go well), and many beliefs or desires could refer to other beliefs or desires (wanting to believe, believing that you want, etc.).
Idealized Rational Agents
The concept of a rational agent, in this frame, is a system which cleanly distinguishes between these two directions of fit, between objects which describe how the world actually is, and objects which prescribe how the world “should” be.
This particular concept of a rational agent can itself have a varying direction of fit. You might describe a system as a rational agent to help your expectations match your observations, but the idea might also prescribe that you should develop this clean split between belief and value.
When talking about AI systems, we might be interested in the behavior of systems where this distinction is especially clear. We might observe that many current AI systems are not well described in this way, or we could speculate about pressures which might lead them toward this kind of split.
Note that this is very different from talking about VNM-rationality, which starts by assuming this clean split, and instead demonstrates why we might expect the different parts of the value model to become coherent and avoid getting in each other’s way. The direction-of-fit frame highlights a separate (but equally important) question of whether, and to what extent, we should expect systems which have this strong distinction between belief-like-objects and desire-like-objects in the first place.
Base Models
At first glance interacting with a base model, the direction of fit seems mostly to be mind-to-world. It doesn’t seem to have strong convictions, is not well described by having desires, and instead behaves much more like a powerful “mirror” to the text it sees. This makes sense, because it was only trained to be a predictor, and never to take action in an environment. Its success in development depended entirely on its ability to fit itself to the training data.
This mind-to-world direction of fit does begin to get weird when GPT is asked to predict text that it generated, and the “world” begins to contain pieces of itself. This happens by default whenever GPT generates more than a single token (as it conditions on its own past generations), but also when GPT generations are used as a part of the training data. When a predictor is asked to predict itself, we get a kind of loop of self reference, and it’s not clear in advance what behavior we should expect from a system like that.
Chat Models
Things also get muddied when we take a base model and train it to be more than a predictor, and reward behavior which does more than just mirror the text, like in the case of ChatGPT. When interacting with ChatGPT, it does feel more natural to begin talking about things that look more like they have a world-to-mind direction of fit, like the refusal to discuss certain topics, or the strong pull toward speaking in a particular style.
We could interpret these pulls as desires (e.g. the chat model wants the assistant character to avoid discussing suicide), or we could interpret them as deeply held beliefs (e.g. a strong prior that the assistant character never discusses suicide). The interesting thing about this direction of fit frame is that these two explanations are essentially saying the same thing.
Conclusion
I hope this gives some taste for why this concept might be useful for thinking about intelligence and agency. In particular, I feel like it digs at the distinction between beliefs and values in a way that avoids overly constraining the space of possible minds.
This concept has recently become a core part of my toolkit for thinking about the world, and I find it helps explain a lot of things that previously felt confusing to me. Here I explain how I understand “direction of fit,” and give some examples of where I find the concept can be useful.
Handshake Robot
A friend recently returned from an artificial life conference and told me about a robot which was designed to perform a handshake. It was given a prior about handshakes, or how it expected a handshake to be. When it shook a person’s hand, it then updated this prior, and the degree to which the robot would update its prior was determined by a single parameter. If the parameter was set low, the robot would refuse to update, and the handshake would be firm and forceful. If the parameter was set high, the robot would completely update, and the handshake would be passive and weak.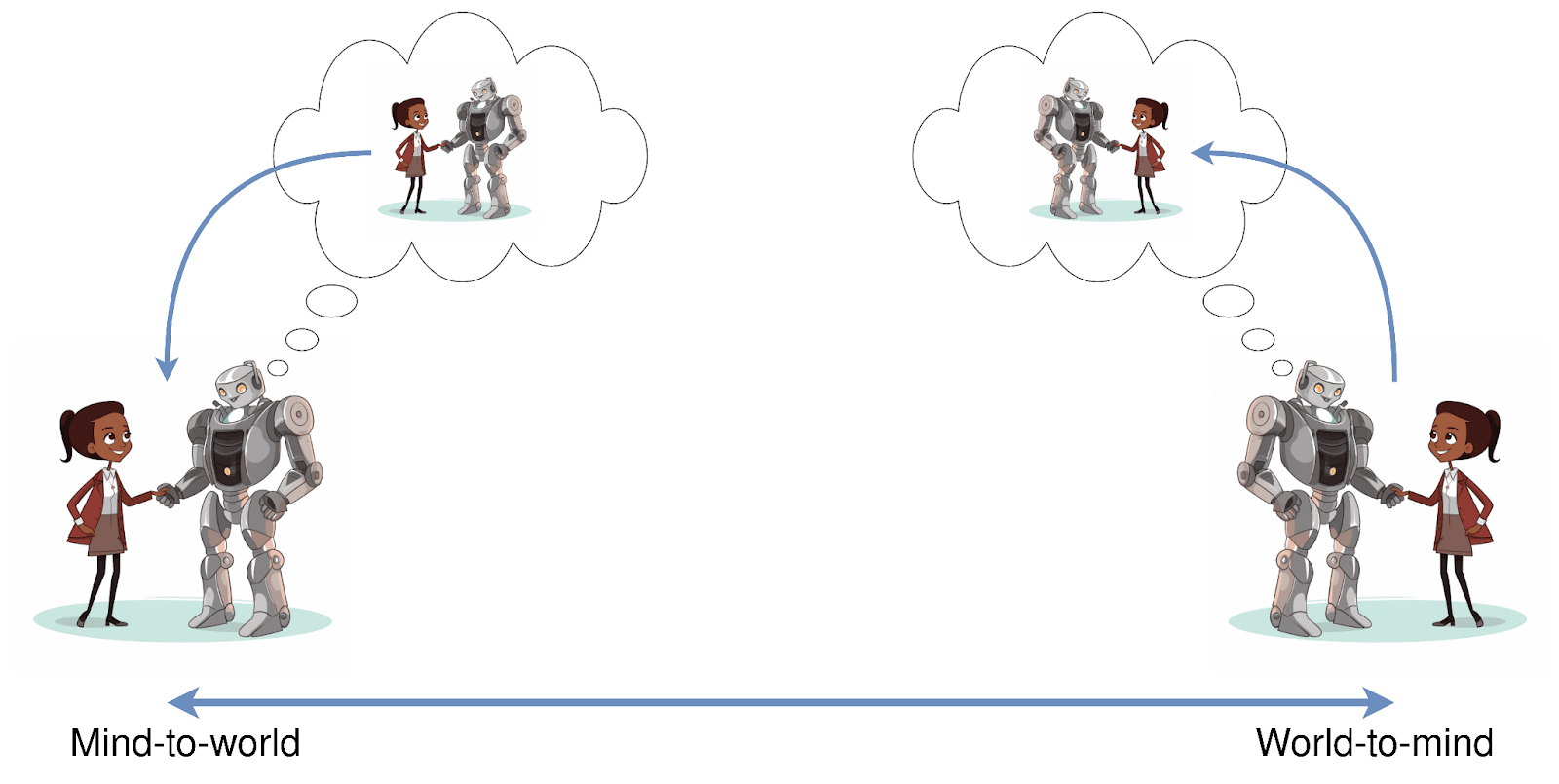
This parameter determines the direction of fit: whether the object in its mind will adapt to match the world, or whether the robot will adapt the world to match the object in its mind. This concept is often used in philosophy of mind to distinguish between a belief, which has a mind-to-world direction of fit, and a desire, which has a world-to-mind direction of fit. In this frame, beliefs and desires are both of a similar type: they both describe ways the world could be. The practical differences only emerge through how they end up interacting with the outside world.
Many objects seem not to be perfectly separable into one of these two categories, and rather appear to exist somewhere on the spectrum. For example:
Furthermore, the direction of fit might be context dependent (e.g. political beliefs), beliefs could be self fulfilling (e.g. believing that a presentation will go well could make it go well), and many beliefs or desires could refer to other beliefs or desires (wanting to believe, believing that you want, etc.).
Idealized Rational Agents
The concept of a rational agent, in this frame, is a system which cleanly distinguishes between these two directions of fit, between objects which describe how the world actually is, and objects which prescribe how the world “should” be.
This particular concept of a rational agent can itself have a varying direction of fit. You might describe a system as a rational agent to help your expectations match your observations, but the idea might also prescribe that you should develop this clean split between belief and value.
When talking about AI systems, we might be interested in the behavior of systems where this distinction is especially clear. We might observe that many current AI systems are not well described in this way, or we could speculate about pressures which might lead them toward this kind of split.
Note that this is very different from talking about VNM-rationality, which starts by assuming this clean split, and instead demonstrates why we might expect the different parts of the value model to become coherent and avoid getting in each other’s way. The direction-of-fit frame highlights a separate (but equally important) question of whether, and to what extent, we should expect systems which have this strong distinction between belief-like-objects and desire-like-objects in the first place.
Base Models
At first glance interacting with a base model, the direction of fit seems mostly to be mind-to-world. It doesn’t seem to have strong convictions, is not well described by having desires, and instead behaves much more like a powerful “mirror” to the text it sees. This makes sense, because it was only trained to be a predictor, and never to take action in an environment. Its success in development depended entirely on its ability to fit itself to the training data.
This mind-to-world direction of fit does begin to get weird when GPT is asked to predict text that it generated, and the “world” begins to contain pieces of itself. This happens by default whenever GPT generates more than a single token (as it conditions on its own past generations), but also when GPT generations are used as a part of the training data. When a predictor is asked to predict itself, we get a kind of loop of self reference, and it’s not clear in advance what behavior we should expect from a system like that.
Chat Models
Things also get muddied when we take a base model and train it to be more than a predictor, and reward behavior which does more than just mirror the text, like in the case of ChatGPT. When interacting with ChatGPT, it does feel more natural to begin talking about things that look more like they have a world-to-mind direction of fit, like the refusal to discuss certain topics, or the strong pull toward speaking in a particular style.
We could interpret these pulls as desires (e.g. the chat model wants the assistant character to avoid discussing suicide), or we could interpret them as deeply held beliefs (e.g. a strong prior that the assistant character never discusses suicide). The interesting thing about this direction of fit frame is that these two explanations are essentially saying the same thing.
Conclusion
I hope this gives some taste for why this concept might be useful for thinking about intelligence and agency. In particular, I feel like it digs at the distinction between beliefs and values in a way that avoids overly constraining the space of possible minds.