Two-year update on my personal AI timelines
31Matthew Barnett
17Daniel Kokotajlo
11Daniel_Eth
7nostalgebraist
7Zach Stein-Perlman
4Ajeya Cotra
4Zach Stein-Perlman
6Rob Bensinger
3Ajeya Cotra
5Adam Scholl
5Ajeya Cotra
5Quadratic Reciprocity
3Zach Stein-Perlman
3Ajeya Cotra
4Lauro Langosco
5kave
2Lauro Langosco
2Shiroe
2Ajeya Cotra
1rossg
New Comment
I'm curious if you have any thoughts on the effect regulations will have on AI timelines. To have a transformative effect, AI would likely need to automate many forms of management, which involves making a large variety of decisions without the approval of other humans. The obvious effect of deploying these technologies will therefore be to radically upend our society and way of life, taking control away from humans and putting it in the hands of almost alien decision-makers. Will bureaucrats, politicians, voters, and ethics committees simply stand idly by while the tech industry takes over our civilization like this?
On the one hand, it is true that cars, airplanes, electricity, and computers were all introduced with relatively few regulations. These technologies went on to change our lives greatly in the last century and a half. On the other hand, nuclear power, human cloning, genetic engineering of humans, and military weapons each have a comparable potential to change our lives, and yet are subject to tight regulations, both formally, as the result of government-enforced laws, and informally, as engineers regularly refuse to work on these technologies indiscriminately, fearing backlash from the public.
One objection is that it is too difficult to slow down AI progress. I don't buy this argument.
A central assumption of the Bio Anchors model, and all hardware-based models of AI progress more generally, is that getting access to large amounts of computation is a key constraint to AI development. Semiconductor fabrication plants are easily controllable by national governments and require multi-billion dollar upfront investments, which can hardly evade the oversight of a dedicated international task force.
We saw in 2020 that, if threats are big enough, governments have no problem taking unprecedented action, quickly enacting sweeping regulations of our social and business life. If anything, a global limit on manufacturing a particular technology enjoys even more precedent than, for example, locking down over half of the world's population under some sort of stay-at-home order.
Another argument states that the incentives to make fast AI progress are simply too strong: first mover advantages dictate that anyone who creates AGI will take over the world. Therefore, we should expect investments to accelerate dramatically, not slow down, as we approach AGI. This argument has some merit, and I find it relatively plausible. At the same time, it relies on a very pessimistic view of international coordination that I find questionable. A similar first-mover advantage was also observed for nuclear weapons, prompting Bertrand Russell to go as far as saying that only a world government could possibly deter nations from developing and using nuclear weapons. Yet, I do not think this prediction was borne out.
Finally, it is possible that the timeline you state here is conditioned on no coordinated slowdowns. I sometimes see people making this assumption explicit, and in your report you state that you did not attempt to model "the possibility of exogenous events halting the normal progress of AI research". At the same time, if regulation ends up mattering a lot -- say, it delays progress by 20 years -- then all the conditional timelines will look pretty bad in hindsight, as they will have ended up omitting one of the biggest, most determinative factors of all. (Of course, it's not misleading if you just state upfront that it's a conditional prediction).
Thanks so much for this update! Some quick questions:
- Are you still estimating that the transformative model uses probably about 1e16 parameters & 1e16 flops? IMO something more like 1e13 is more reasonable.
- Are you still estimating that algorithmic efficiency doubles every 2.5 years (for now at least, until R&D acceleration kicks in?) I've heard from thers (e.g. Jaime Sevilla) that more recent data suggests it's doubling every 1 year currently.
- Do you still update against the lower end of training FLOP requirements, on the grounds that if we were 1-4 OOMs away right now the world would look very different?
- Is there an updated spreadsheet we can play around with?
Great post!
I was curious what some of this looked like, so I graphed it, using the dates you specifically called out probabilities. For simplicity, I assumed constant probability within each range (though I know you said this doesn't correspond to your actual views). Here's what I got for cumulative probability:
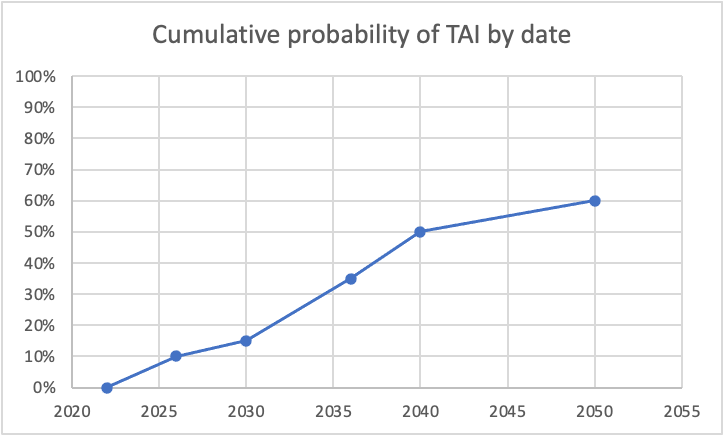
And here's the corresponding probabilities of TAI being developed per specific year: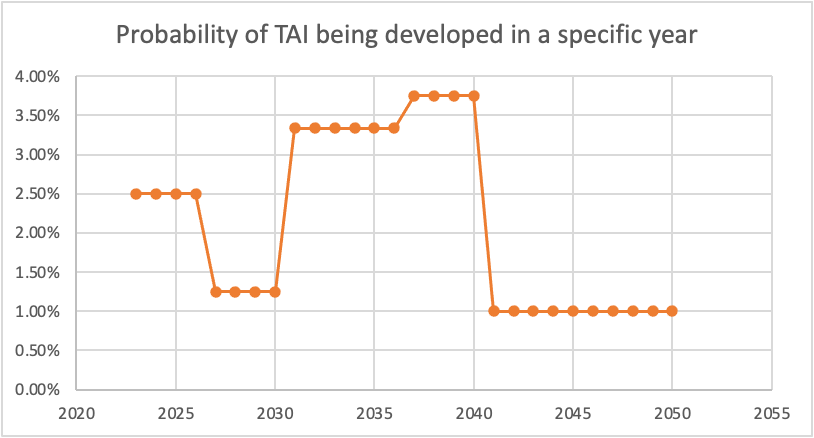
The dip between 2026 and 2030 seems unjustified to me. (I also think the huge drop from 2040-2050 is too aggressive, as even if we expect a plateauing of compute/another AI winter/etc, I don't think we can be super confident exactly when that would happen, but this drop seems more defensible to me than the one in the late 2020s.)
If we instead put 5% for 2026, here's what we get:
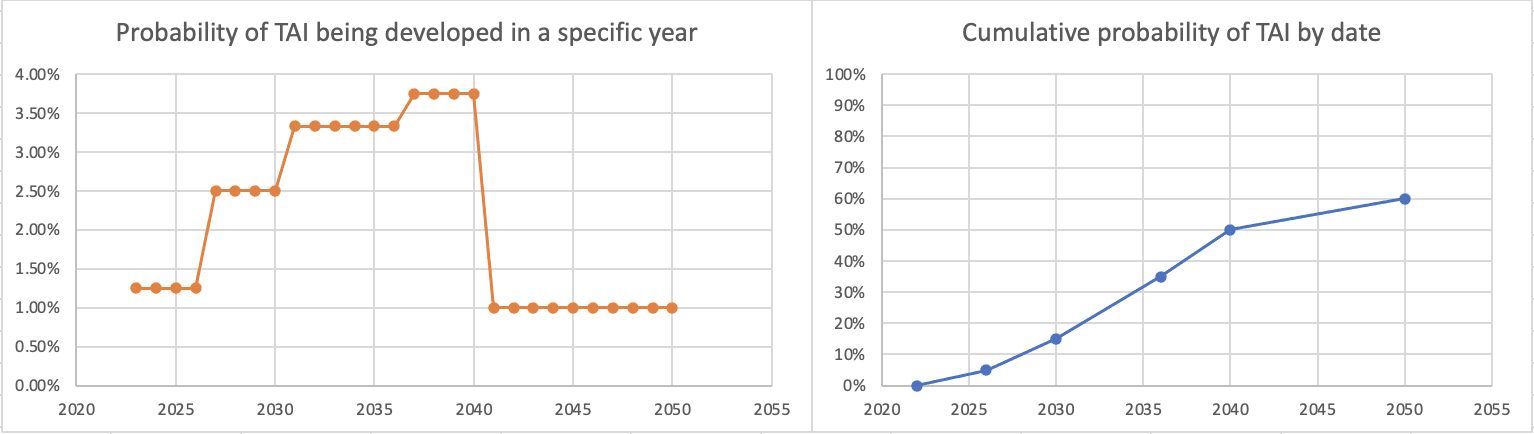
which seems more intuitively defensible to me. I think this difference may be important, as even shift of small numbers of years like this could be action-relevant when we're talking about very short timelines (of course, you could also get something reasonable-seeming by shifting up the probabilities of TAI in the 2026-2030 range).
I'd also like to point out that your probabilities would imply that if TAI is not developed by 2036, there would be an implied 23% conditional chance of it then being developed in the subsequent 4 years ((50%-35%)/(100%-35%)), which also strikes me as quite high from where we're now standing.
Now I’m inclined to think that just automating most of the tasks in ML research and engineering -- enough to accelerate the pace of AI progress manyfold -- is sufficient.
This seems to assume that human labor is currently the limiting bottleneck in AI research, and by a large multiplicative factor.
That doesn't seem likely to me. Compute is a nontrivial bottleneck even in many small-scale experiments, and in particular is a major bottleneck for research that pushes the envelope of scale, which is generally how new SOTA results and such get made these days.
To be concrete, consider this discussion of "the pace of AI progress" elsewhere in the post:
But progress on some not-cherry-picked benchmarks was notably faster than what forecasters predicted, so that should be some update toward shorter timelines for me.
That post is about four benchmarks. Of the four, it's mostly MATH and MMLU that are driving the sense of "notably faster progress" here. The SOTAs for these were established by
- MATH: Minerva, which used a finetuned PaLM-540B model together with already existing (if, in some cases, relatively recently introduced) techniques like chain-of-thought
- MMLU: Chinchilla, a model with the same design and (large) training compute cost as the earlier Gopher, but with different hyperparameters chosen through a conventional (if unusually careful) scaling law analysis
In both cases, relatively simple and mostly non-original techniques were combined with massive compute. Even if you remove the humans entirely, the computers still only go as far as they go.
(Human labor is definitely a bottleneck in making the computers go faster -- like hardware development, but also specialized algorithms for large-scale training. But this is a much more specialized area than "AI research" generally, so there's less available pretraining data on it -- especially since a large[r] fraction of this kind of work is likely to be private IP.)
Good post!
I understand that the specific numbers in this post are "rough" and "volatile," but I want to note that 35% by 2036, 50% by 2040, and 60% by 2050 means 3.75% per year 2036–2040 and 1% per year 2040–2050, which is a surprisingly steep drop-off. Or as an alternative framing, conditional on TAI not having appeared by 2040, my expected credence in 2040 that TAI appears in the next 10 years is much greater than 20% (where 20% is your implied probability of TAI between 2040 and 2050, conditional on no TAI in 2040). My median timeline is somewhat shorter than yours, but my credence in TAI by 2050 is substantially higher.
(That said, I lack something like the knowledge, courage, or epistemic virtue to be more explicit about my timelines, because it's hard; strong-upvote for this useful and virtuous post, and thanks for using specific numbers so much.)
Hm, yeah, I bet if I reflected more things would shift around, but I'm not sure the fact that there's a shortish period where the per-year probability is very elevated followed by a longer period with lower per-year probability is actually a bad sign.
Roughly speaking, right now we're in an AI boom where spending on compute for training big models is going up rapidly, and it's fairly easy to actually increase spending quickly because the current levels are low. There's some chance of transformative AI in the middle of this spending boom -- and because resource inputs are going up a ton each year, the probability of TAI by date X would also be increasing pretty rapidly.
But the current spending boom is pretty unsustainable if it doesn't lead to TAI. At some point in the 2040s or 50s, if we haven't gotten transformative AI by then, we'll have been spending 10s of billions training models, and it won't be that easy to keep ramping up quickly from there. And then because the input growth will have slowed, the increase in probability from one year to the next will also slow. (That said, not sure how this works out exactly.)
(+1. I totally agree that input growth will slow sometime if we don't get TAI soon. I just think you have to be pretty sure that it slows right around 2040 to have the specific numbers you mention, and smoothing out when it will slow down due to that uncertainty gives a smoother probability distribution for TAI.)
Thanks for the update, Ajeya! I found the details here super interesting.
I already thought that timelines disagreements within EA weren't very cruxy, and this is another small update in that direction: I see you and various MIRI people and Metaculans give very different arguments about how to think about timelines, and then the actual median year I tend to hear is quite similar.
(And also, all of the stated arguments on all sides continue to seem weak/inconclusive to me! So IMO there's not much disagreement, and it would be very easy for all of us to be wrong simultaneously. My intuition is that it would be genuinely weird if AGI is much more than 70 years away, but not particularly weird if it's 1 year away, 10 years away, 60 years away, etc.)
I think the main value of in-depth timelines research and debate has been that it reveals disagreements about other topics (background views about ML, forecasting methodology, etc.).
Yeah I agree more of the value of this kind of exercise (at least within the community) is in revealing more granular disagreements about various things. But I do think there's value in establishing to more external people something high level like "It really could be soon and it's not crazy or sci fi to think so."
I don’t expect a discontinuous jump in AI systems’ generality or depth of thought from stumbling upon a deep core of intelligence
I felt surprised reading this, since "ability to automate AI development" feels to me like a central example of a "deep core of intelligence"—i.e., of a cognitive ability which makes attaining many other cognitive abilities far easier. Does it not feel like a central example to you?
I don't see it that way, no. Today's coding models can help automate some parts of the ML researcher workflow a little bit, and I think tomorrow's coding models will automate more and more complex parts, and so on. I think this expansion could be pretty rapid, but I don't think it'll look like "not much going on until something snaps into place."
As a result, my timelines have also concentrated more around a somewhat narrower band of years. Previously, my probability increased from 10% to 60% over the course of the ~32 years from ~2032 and ~2064; now this happens over the ~24 years between ~2026 and ~2050.
10% probability by 2026 (!!)
Huh, I claim Ajeya's timelines are much more coherent if we replace 2026 with 2027.5 or 2028.* 10% between now and 2026, then 5% between 2026 and 2030, then 20% between 2030 and 2036 is really weird.
*Changing 2026 (rather than 2030) just because Ajeya's 2026 cumulative probability seems less considered than her 2030 and 2036 cumulative probabilities.
(Coherence aside, when I now look at that number it does seem a bit too high, and I feel tempted to move it to 2027-2028, but I dunno, that kind of intuition is likely to change quickly from day to day.)
But in my report I arrive at a forecast by fixing a model size based on estimates of brain computation, and then using scaling laws to estimate how much data is required to train a model of that size. The update from Chinchilla is then that we need more data than I might have thought.
I'm confused by this argument. The old GPT-3 scaling law is still correct, just not compute-optimal. If someone wanted to, they could still go on using the old scaling law. So discovering better scaling can only lead to an update towards shorter timelines, right?
(Except if you had expected even better scaling laws by now, but it didn't sound like that was your argument?)
If you assume the human brain was trained roughly optimally, then requiring more data, at a given parameter number, to be optimal pushes timelines out. If instead you had a specific loss number in mind, then a more efficient scaling law would pull timelines in.
Gotcha, this makes sense to me now, given the assumption that to get AGI we need to train a P-parameter model on the optimal scaling, where P is fixed. Thanks!
...though now I'm confused about why we would assume that. Surely that assumption is wrong?
- Humans are very constrained in terms of brain size and data, so we shouldn't assume that these quantities are scaled optimally in some sense that generalizes to deep learning models.
- Anyhow we don't need to guess the amount of data the human brain needs: we can just estimate it directly, just like we estimate brain-parameter count.
To move to a more general complaint about the bio anchors paradigm: it never made much sense to assume that current scaling laws would hold; clearly scaling will change once we train on new data modalities; we know that human brains have totally different scaling laws than DL models; and an AGI architecture will again have different scaling laws. Going with the GPT-3 scaling law is a very shaky best guess.
So it seems weird to me to put so much weight on this particular estimate, such that someone figuring out how to scale models much more cheaply would update one in the direction of longer timelines! Surely the bio anchor assumptions cannot possibly be strong enough to outweigh the commonsense update of 'whoa, we can scale much more quickly now'?
The only way that update makes sense is if you actually rely mostly on bio anchors to estimate timelines (rather than taking bio anchors to be a loose prior, and update off the current state and rate of progress in ML), which seems very wrong to me.
You mention that you're surprised to have not seen "more vigorous commercialization of language models" recently beyond mere "novelty". Can you say more about what particular applications you had in mind? Also, do you consider AI companionship as useful or merely novel?
I expect the first killer app that goes mainstream will mark the PONR, i.e. the final test of whether the market prefers capabilities or safety.
Can you say more about what particular applications you had in mind?
Stuff like personal assistants who write emails / do simple shopping, coding assistants that people are more excited about than they seem to be about Codex, etc.
(Like I said in the main post, I'm not totally sure what PONR refers to, but don't think I agree that the first lucrative application marks a PONR -- seems like there are a bunch of things you can do after that point, including but not limited to alignment research.)
I think your timeline is on point regarding capabilities. However, I do not entirely follow the jump from expert-level programming and brute-force search to an "explosive feedback loop of AI progress". You point out that there is a "clear-cut search space" in machine learning, which is true, and I agree that brute-force search could be expected to yield some progress, likely substantial progress, whereas in other scientific disciplines similar progress would be unlikely. I will even concede that explosive progress is possible, but I fail to grasp why it is likely. I think that the "clear-cut search space" is limited to low-hanging fruit, such as "different small tweaks to architectures, loss functions, optimization algorithms", and I expect that to get from automated AI progress to automated scientific discovery something more is needed. If you're suggesting that efficiency improvements from "different small tweaks to architectures, loss functions, optimization algorithms" would be of an order of magnitude or greater—enough to move progressively on to medium and longer horizon models—is there evidence in this post or the original report to support this that I am missing? This could plausibly lead to an "explosive feedback loop of AI progress", but I would not assume that it will. Alternatively, it seems plausible that "directly writing learning algorithms much more sample-efficient than SGD" would be sufficient to get to automated scientific discovery—are you suggesting that "different small tweaks to architectures, loss functions, optimization algorithms" is going to be enough to generate a novel learning algorithm? The search space for that seems "less clear-cut" and much more like what would be required to automate progress in other scientific disciplines.
Curated and popular this week