As the title says, Meta trained 4 foundational models with 7B, 13B, 33B, and 65B parameters respectively, and is open sourcing them for research.[1] You can get their code on their Github repo: https://github.com/facebookresearch/llama but you need to fill in a Google form to get the weights.
On downstream benchmarks, the models do comparably well with Chinchilla and PaLM and only a bit worse than Flan-PaLM-540B and code-davinci-002/text-davinci-002. (The authors don't evaluate on those models, but you can look at their performance from other work such as Stanford's HELM or Chung, Hou, Longpre et al's "Scaling Instruction-Finetuned Language Models".
Abstract:
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla70B and PaLM-540B. We release all our models to the research community.
Eliezer guesses that the model won't be impressive in practice:
I blindly guess, could be wrong, that this model will turn out sufficiently unimpressive in practice that nobody uses it for much. Basically based on a guess that more than benchmarks matter, and Meta has no people competent to do the tricky stuff needed to stay on current edge.
It's not necessarily open source as you think of it -- you need to fill in a Google form, and then they might give it to you:
In order to download the checkpoints and tokenizer, fill this google form
The license is intended only for non-commercial, research work:
Meta grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty free and limited license under Meta’s copyright interests to reproduce, distribute, and create derivative works of the Software solely for your non-commercial research purposes.
As the title says, Meta trained 4 foundational models with 7B, 13B, 33B, and 65B parameters respectively, and is open sourcing them for research.[1] You can get their code on their Github repo: https://github.com/facebookresearch/llama but you need to fill in a Google form to get the weights.
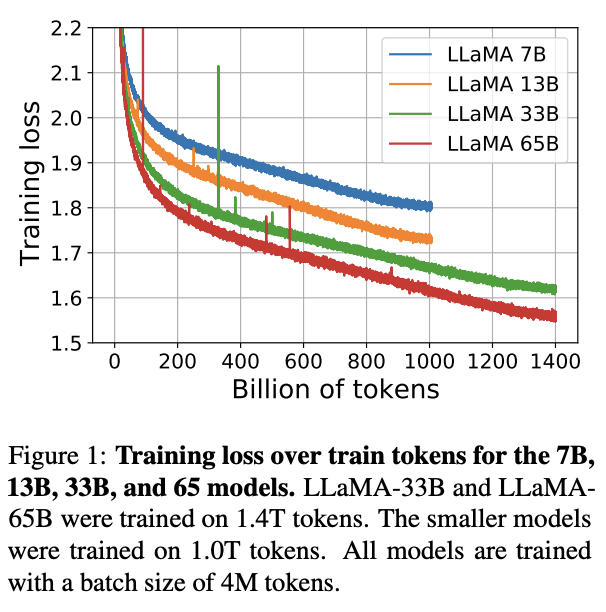
On downstream benchmarks, the models do comparably well with Chinchilla and PaLM and only a bit worse than Flan-PaLM-540B and
code-davinci-002/text-davinci-002. (The authors don't evaluate on those models, but you can look at their performance from other work such as Stanford's HELM or Chung, Hou, Longpre et al's "Scaling Instruction-Finetuned Language Models".Abstract:
Twitter thread from authors: https://twitter.com/GuillaumeLample/status/1629151231800115202
Eliezer guesses that the model won't be impressive in practice:
It's not necessarily open source as you think of it -- you need to fill in a Google form, and then they might give it to you:
The license is intended only for non-commercial, research work: