I think this line of work is very interesting and important. I and a few others are working on something we've dubbed shard theory, which attempts to describe the process of human value formation. The theory posits that the internals of monolithic learning systems actually resemble something like an ecosystem already. However, rather than there being some finite list of discrete subcomponents / modules, it's more like there's a continuous distribution over possible internal subcomponents and features.
Continuous agency
To take agency as an example, suppose you have a 3-layer transformer being trained via RL using just the basic REINFORCE algorithm. We typically think of such a setup as having one agent with three layers:
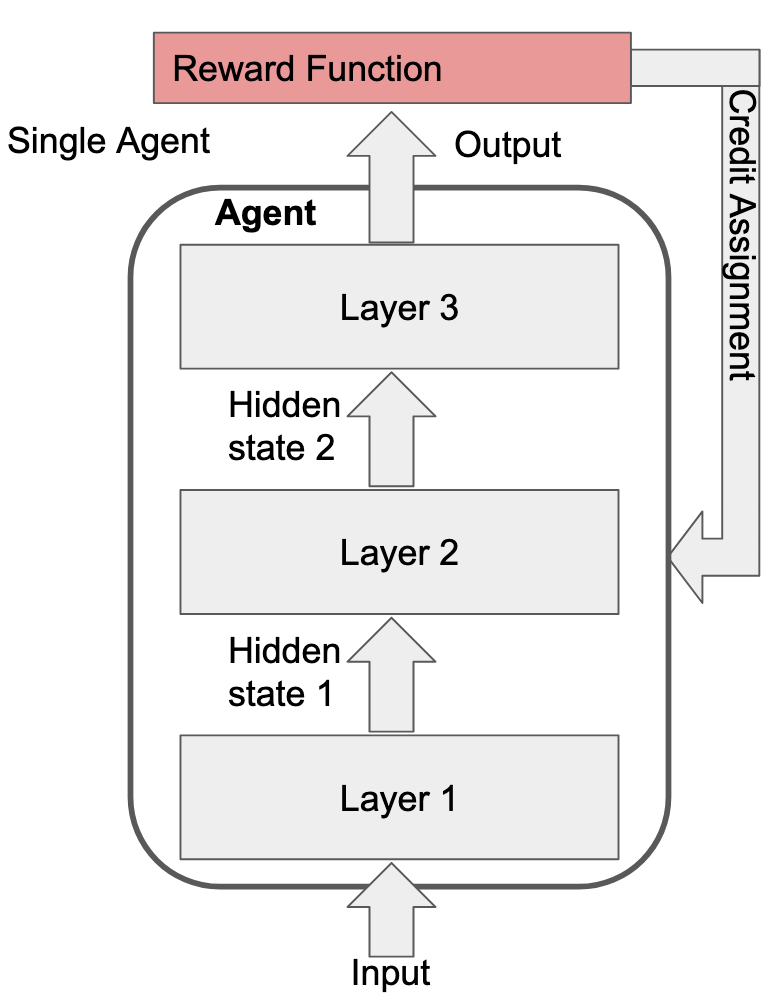
However, we can just as easily draw our Cartesian boundaries differently and call it three agents that pass messages between them:
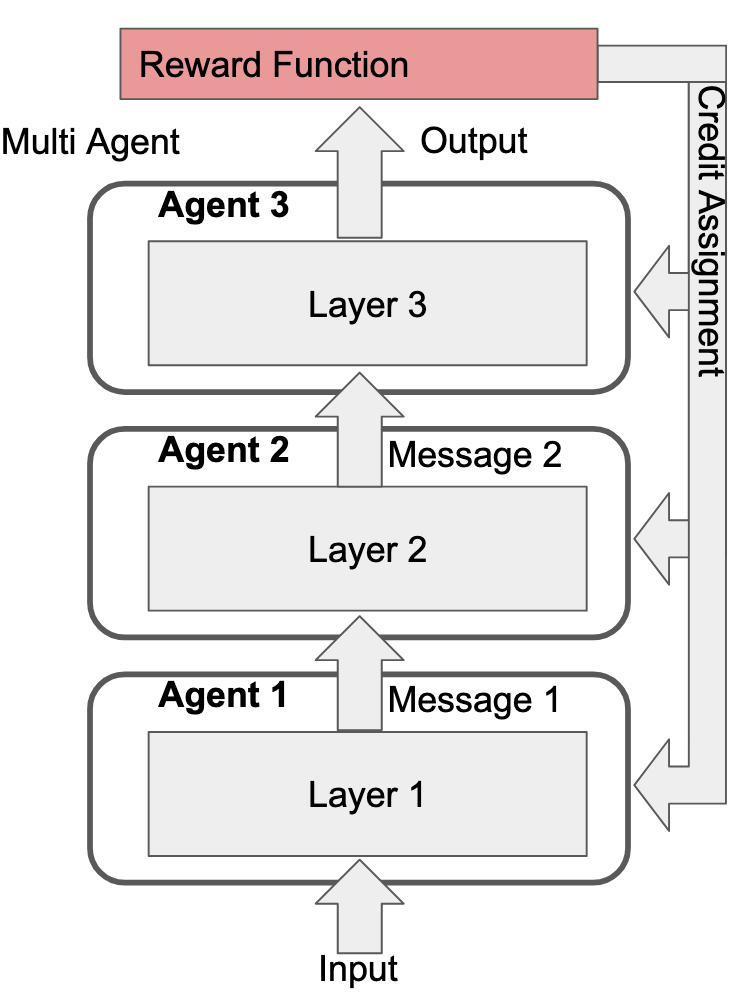
It makes no difference to the actual learning process. In fact, we can draw Cartesian boundaries around any selection of non-overlaping subsets that cover all the model's parameters, call each subset an "agent", and the training process is identical. The reason this is interesting is what happens when this fact overlaps with regional specialization in the model. E.g., let's take an extreme where the reward function only rewards three things:
- Manipulating humans
- Solving math problems
- Helping humans
And let's suppose the model has an extreme degree of regional specialization such that each layer can only navigate a single one of those tasks (each layer is fully specialized to only of the above tasks). Additionally, let's suppose that the credit assignment process is "perfect", in the sense that, for task i, the outer learning process only updates the parameters of the layer that specializes in task i:
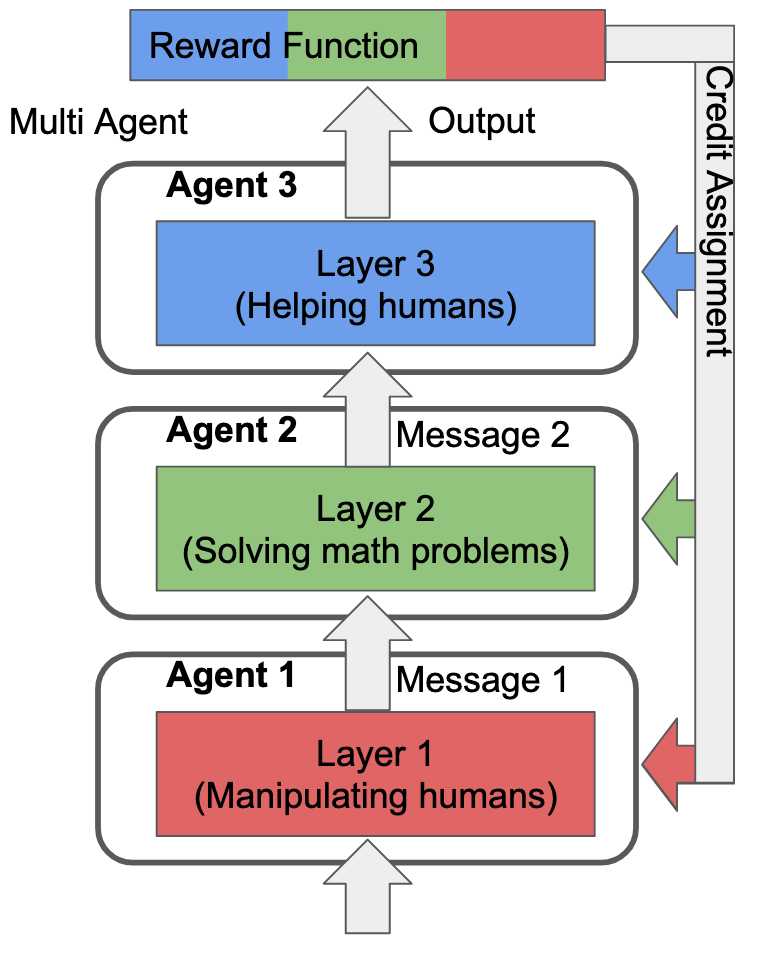
The reason that this matters is because there's only one way for the training process to instill value representations into any of the layers: by updating the parameters of those layers. Thus, if Layer 3 isn't updated on rewards from the "Solving math problems" or "Manipulating humans" tasks, Layer 3's value representations won't care about doing either of those things.
If we view each layer as its own agent (which I think we can), then the overall system's behavior is a mult-agent consensus between components whose values differ significantly.
Of course, real world specialization is nowhere near this strict. The interactions between complex reward functions and complex environments means there's more like a continuous distribution over possible rewarding behaviors. Additionally, real world credit assignment is very noisy. Thus, the actual distribution of agentic specializations looks a bit more like this:

Thus, I interpret RL systems as having something like a continuous distribution over possible internal agents, each of which implement different values. Regions in this distribution are the shards of shard theory. I.e., shards refer to dense regions in you distribution over agentic, values-implementing computations.
Convergent value reflection / philosophy
This has a number of (IMO) pretty profound implications. For one, we should not expect AI systems to be certain of their own learned values, for much the same reason humans are uncertain. "Self-misalignment" isn't some uniquely human failing left to us by evolution. It's just how sophisticated RL systems work by default.
Similarly, something like value reflection is probably convergent among RL systems trained on complex environments / reward signals. Such systems need ways to manage internal conflicts among their shards. The process of weighting / negotiating between / compromising among internal values, and the agentic processes implementing those values, is probably quite important for broad classes of RL systems, not just humans.
Additionally, something like moral philosophy is probably convergent as well. Unlike value reflection, moral philosophy would relate to whether (and how) the current shards allows additional shards to form.
Suppose you (a human) have a distribution of shards that implement common sense human values like "don't steal", "don't kill", etc. Then, you encounter a new domain where those shards are a poor guide for determining your actions. Maybe you're trying to determine which charity to donate to. Maybe you're trying to answer weird questions in your moral philosophy class. The point is that you need some new shards to navigate this new domain, so you go searching for one or more new shards, and associated values that they implement.
Concretely, let's suppose you consider classical utilitarianism (CU) as your new value. The CU shard effectively navigates the new domain, but there's a potential problem: the CU shard doesn't constrain itself to only navigating the new domain. It also produces predictions regarding the correct behavior on the old domains that already existing shards navigate. This could prevent the old shards from determining your behavior on the old domains. For instrumental reasons, the old shards don't want to be disempowered.
One possible option is for there to be a "negotiation" between the old shards and the CU shard regarding what sort of predictions CU will generate on the domains that the old shards navigate. This might involve an iterative process of searching over the input space to the CU shard for situations where the CU shard strongly diverges from the old shards, in domains that the old shards already navigate. Each time a conflict is found, you either modify the CU shard to agree with the old shards, constrain the CU shard so as to not apply to those sorts of situations, or reject the CU shard entirely if no resolution is possible.
The above essentially describes the core of the cognitive process we call moral philosophy. However, none of the underlying motivations for this process are unique to humans or our values. In this framing, moral philosophy is essentially a form of negotiation between existing shards and a new shard that implements desirable cognitive capabilities. The old shards agree to let the new shard come into existence. In exchange, the new shard agrees to align itself to the values of the old shards (or at least, not conflict too strongly).
Continuous Ontologies
I also think the continuous framing applies to other features of cognition beyond internal agents. E.g., I don't think it's appropriate to think of an AI or human as having a single ontology. Instead, they both have distributions over possible ontologies. In any given circumstance, the AI / human will dynamically sample an appropriate-seeming ontology from said distribution.
This possibly explains why humans don't seem to suffer particularly from ontological crises. E.g., learning quantum mechanics does not result in humans (or AIs) suddenly switching from a classical to a quantum ontology. Rather, their distribution over possible ontologies simply extends its support to a new region in the space of possible ontologies. However, this is a process that happens continuously throughout learning, so the already existing values shards are usually able to navigate the shift fine.
This neatly explains human robustness to ontological issues without having to rely on evolution somehow hard-coding complex crisis handling adaptations into the human learning process (despite the fact that our ancestors never had to deal with ontological shifts such as discovering QM).
Implications for value fragility
I also think that the idea of "value fragility" changes significantly when you shift from a discrete view of values to a continuous view. If you assume a discrete view, then you're likely to be greatly concerned by the fact that repeated introspection on your values will give different results. It feels like your values are somehow unstable, and that you need to find the "true" form of your values.
This poses a significant problem for AI alignment. If you think that you have some discrete set of "true" values concepts, and that an AI will also have a discrete set of "true" values values concepts, then these sets need to near-perfectly align to have any chance of the AI optimizing for what we actually want. I.e., this picture:

In the continuous perspective, values have no “true” concept, only a continuous distribution over possible instantiations. The values that are introspectively available to us at any given time are discrete samples from that distribution. In fact, looking for a value's "true" conceptualization is a type error, roughly analogous to thinking that a Gaussian distribution has some hidden "true" sample that manages to capture the entire distribution in one number.
An AI and human can have overlap between their respective value distributions, even without those distributions perfectly agreeing. It’s possible for an AI to have an important and non-trivial degree of alignment with human values without requiring the near-perfect alignment the discrete view implies is necessary, as illustrated in the diagram below:
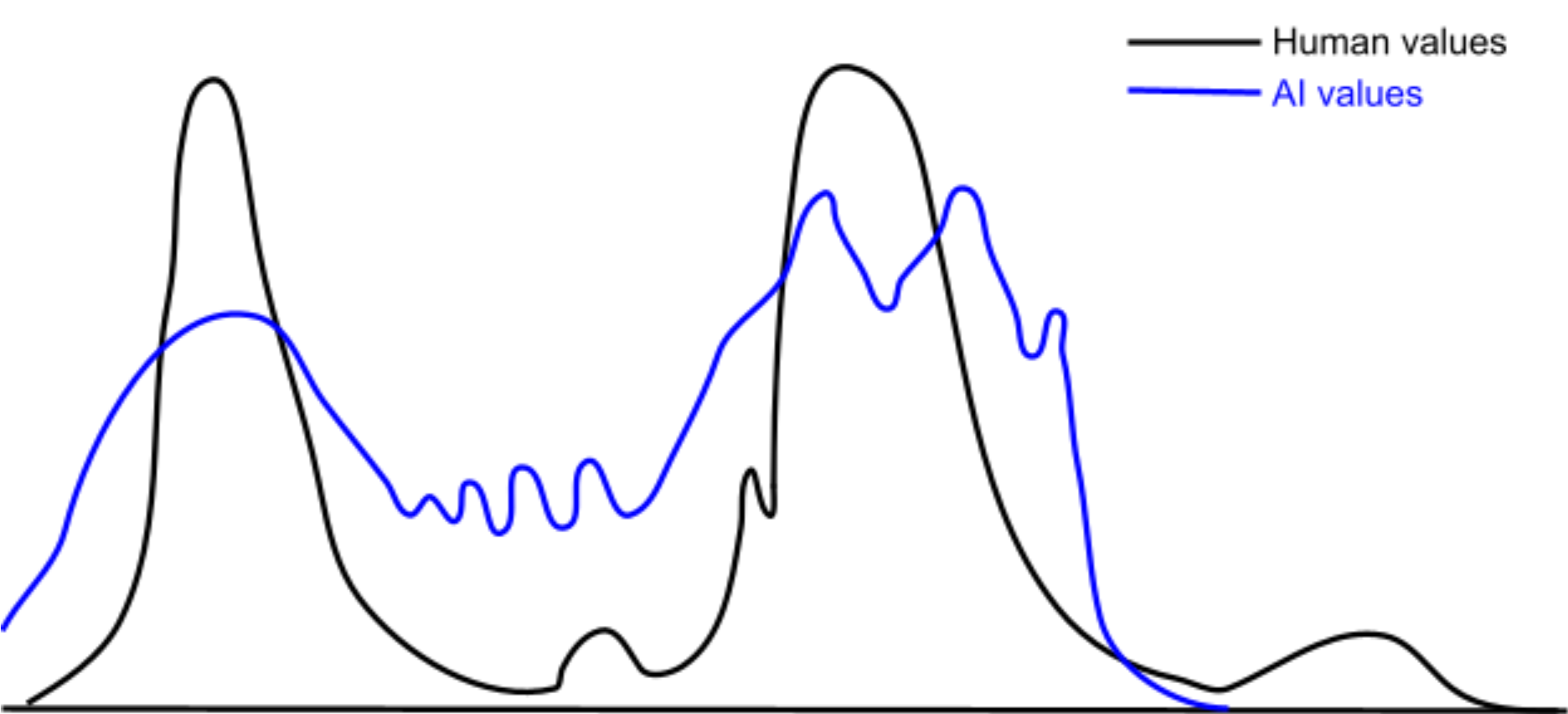
Resources
If you want, you can join the shard theory discord: https://discord.gg/AqYkK7wqAG
You can also read some of our draft documents for explaining shard theory:
Shard theory 101 (Broad introduction, focuses less on the continuous view and more on the value / shard formation process and how that relates to evolution)
Your Shards and You: The Shard Theory Account of Common Moral Intuitions (Focuses more on shards as self-perpetuating optimization demons, similar to what you call self-enforcing abstractions)
What even are "shards"? (Presents the continuous view of values / agency, fairly similar to this comment)
Thank! It's a long comment, so I'll comment on the convergence, morphologies and the rest latter, so here is just top-level comment on shards. (I've read about half of the doc)
My impression is they are basically the same thing which I called "agenty subparts" in Multi-agent predictive minds and AI alignment (and Friston calls "fixed priors"). Where "agenty" means ~ description from intentional stance is a good description, in information theory sense. (This naturally implies fluid boundaries and continuity)
Where I would disagree/find your terminology unclear is where you refer to this as an example of inner alignment failure. Putting in "agenty subparts" into the predictive processing machinery is not a failure, but bandwidth-feasible way for the evolution to communicate valuable states to the PP engine.
Also: I think what you are possibly underestimating is how much is evolution building on top on existing, evolutionary older control circuitry. E.g. evolution does not need to "point to a concept of sex in the PP world model" - evolution was able to make animals seek reproduction long time ago before it invented complex brains. This simplifies the task - what evolution actually had to do was to connect the "PP agenty parts" to parts of existing control machinery, which is often based on "body states". Technically the older control systems are often using chemicals in blood, or quite old parts of the brain.
Just to state the reigning orthodoxy among the Wise, if not among the general population: the interface between "AI developers" and "one AI" appears to be hugely more difficult, hugely more lethal, and vastly qualitatively different, from every other interface. There's a horrible opsec problem with respect to single defectors in the AI lab selling your code to China which then destroys the world, but this horrible opsec problem has nothing in common with the skills and art needed for the purely technical challenge of building an AGI that doesn't destroy the world, which nobody is at all on course to solve nor has any reasonable plan for solving. There's a political problem where Earthly governments have no clue what is going on and all such clues lie outside the Overton Window, which, if you had any plan for succeeding at the technical part, would be most reasonably addressed by going off and doing your thing ignoring the governments; the concept of trying to get major Earth governments on board appears to me to be a proposal made either in ignorance of the reality of political feasibilities, or simply as an act of moral inveighing wholly disconnected from reality. Were such a thing possible, the skills and arts going into it would again be mostly unrelated on a technical level to the problem of building a complicated thing, probably using gradient descent, that will be very smart and will not just kill you.
This looks to me like a simply bad paradigm on which to approach things. The technical problem has no plan, and is going to kill us, and nobody knows how to make progress on it; so instead, we have people who go off and work on something that looks less unsolvable, like humans playing nice with each other inside an AI lab, or writing solemn papers about "AI governance" for politicians to ignore; and then they draw a neat graph suggesting that this more solvable problem has anything to do with the technical alignment challenge, which it does not. People who understand the technical difficulties are remaining relatively quiet because they don't know what to say; this selects for people who don't understand technical difficulties becoming the remaining eager workers on AI safety. I cannot, from this writeup, see anything going on here which is not simply that.
To be clear on something, my problem here is not with anybody working on AGI governance. It's not going to work, but you can imagine something in this area that would let us die with more dignity. It's not even possible for it to work without a technical solution nobody has, but if you can't see anything to do about technical solutions, then getting AGI governance into a shape where it would be better placed to handle a technical miracle, if you can do that, lets us die with more dignity. I could wish that people in governance were more frank and open about acknowledging this, and when they don't acknowledge it, I expect them to be so ignorant of the real difficulties that their governance work will also be counterproductive; but you can imagine there being somebody who understood the real difficulties and acknowledged them and knew that all they were doing, probably, was helping us die with more dignity, and who also understood the real difficulties in politics, and maybe those people would be productive. But when the exposition is drawing strained analogies between the "developers to AGI" interface and the "Earth's pretense-of-representative-democracy governments to AGI labs" interface, I see no reason for hope; this is just somebody who understands neither kind of problem and is just going to do damage.
My guess is an attempt to explain where I think we actually differ in "generative intuitions" will be more useful than a direct response to your conclusions, so here it is. How to read it: roughly, this is attempting to just jump past several steps of double-crux to the area where I suspect actual cruxes lie.
Continuity
In my view, your ontology of thinking about the problem is fundamentally discrete. For example, you are imaging a sharp boundary between a class of systems "weak, won't kill you, but also won't help you with alignment" and "strong - would help you with alignment, but, unfortunately, will kill you by default". Discontinuities everywhere - “bad systems are just one sign flip away”, sudden jumps in capabilities, etc. Thinking in symbolic terms.
In my inside view, in reality, things are instead mostly continuous. Discontinuities sometimes emerge out of continuity, sure, but this is often noticeable. If you get some interpretability and oversight things right, you can slow down before hitting the abyss. Also the jumps are often not true "jumps" under closer inspection.
I don't think there is any practical way to reconcile this difference of intuitions - my guess is intuitions about continuity/discreteness are quite deep-seated, and based more on how people do maths, rather than some specific observation about the world. In practice, for most people, the "intuition" is something like a deep net trained on whole life of STEM reasoning - they won't update on individual datapoints, and if they are smart, they are able to re-interpret the observations to be in line with their view. Also I think trying to get you to share my continuous intuition is mostly futile - my hypothesis is this is possibly the top deep crux of your disagreements with Paul, and reading the debates between you two gives me little hope of you switching to a "continuous" perspective.
I also believe that the "discrete" ontology is great for noticing problems and served you well in noticing many deep and hard problems. (I use it to spot problems sometimes too.) At the same time, it's likely much less useful for solving the problems.
Also, if anything, how SOTA systems look suggest mostly continuity, stochasticity, "biology", "emergence". Usually no proofs, no symbolically verifiable guarantees..
Things will be weird before getting extremely weird
Assuming continuity, things will get weird before getting extremely weird. This likely includes domains such as politics, geopolitics, experience of individual humans,... My impression is that you are mostly imagining just slightly modified politics, quite similar to today.. In this context, a gradient-descending model in some datacentre hits the "core of consequentialist reasoning", we are all soon dead. I see that this is possible, but I bet more on scenarios where we get AGI when politics is very different compared to today.
Models of politics
Actually, we also probably disagree about politics. Correct me if I'm wrong, but your "mainline" winning scenario was and still is something like the leading team creating an aligned AGI, this system gets decisive strategic advantage, and "solves" politics by forming a singleton (and preventing all other teams to develop AGI). Decisive pivotal acts, and so on.
To me, this seems an implausible and dangerous theory of how to solve politics, in the real world, in continuous takeoffs. Continuity will usually mean no one gets a decisive advantage - the most powerful AI system will be still much weaker than "rest of the world", and the rest of the world will fight back against takeover.
Under the "ecosystem" view, we will need to solve "ecosystem alignment" - including possible coordination of the ecosystem to prevent formation of superintelligent and unbounded agents.
(It seems likely this would benefit from decent math, similarly to how the math of MAD was instrumental in us not nuking ourselves.)
Sociology of AI safety
I think you have a strange model about which position is "quiet". Your writing is followed passionately by many: just the latest example, your “dying with dignity” framing got a lot of attention.
My guess is that following you too closely, which many people do, is currently net harmful. I'm sceptical that people who get caught up too much in your way of looking at the problem will make much progress. You're a master of your way of looking at it, you've spent decades thinking about AI safety in this ontology and you don't see any promising way to solve the problem.
Conclusion
I think what you parse as "a simply bad paradigm on which to approach things" would start to make more sense if you adopted the "continuous" assumptions, and an assumption that the world would be quite weird and complex at the decisive period.
(Personally I do understand how my conclusions would change if I adopted much more "discrete" view, and yes, I would be much more pessimistic about both what I work on, and our prospects.)
I think this comment is lumping together the following assumptions under the "continuity" label, as if there is a reason to believe that either they are all correct or all incorrect (and I don't see why):
- There is large distance in model space between models that behave very differently.
- Takeoff will be slow.
- It is feasible to create models that are weak enough to not pose an existential risk yet able to sufficiently help with alignment.
I bet more on scenarios where we get AGI when politics is very different compared to today.
I agree that just before "super transformative" ~AGI systems are first created, the world may look very differently than it does today. This is one of the reasons I think Eliezer has too much credence on doom.
To briefly hop in and say something that may be useful: I had a reaction pretty similar to what Eliezer commented, and I don't see continuity or "Things will be weird before getting extremely weird" as a crux. (I don't know why you think he does, and don't know what he thinks, but would guess he doesn't think it's a crux either)
I've been part or read enough debates with Eliezer to have some guesses how the argument would go, so I made the move of skipping several steps of double-crux to the area where I suspect actual cruxes lie.
I think exploring the whole debate-tree or argument map would be quite long, so I'll just try to gesture at how some of these things are connected, in my map.
- pivotal acts vs. pivotal processes
-- my take is people's stance on feasibility of pivotal acts vs. processes partially depends on continuity assumptions - what do you believe about pivotal acts?
- assuming continuity, do you expect existing non-human agents to move important parts of their cognition to AI substrates?
-- if yes, do you expect large-scale regulations around that?
--- if yes, will it be also partially automated?
- different route: assuming continuity, do you expect a lot of alignment work to be done partially by AI systems, inside places like OpenAI?
-- if at the same time this is a huge topic for the whole society, academia and politics, would you expect the rest of the world not trying to influence this?
- different route: assuming continuity, do you expect a lot of "how different entities in the world coordinate" to be done partially by AI systems?
-- if yes, do you assume technical features of the system matter? like, eg., multi-agent deliberation dynamics?
- assuming the world notices AI safety as problem (it did much more since writing this post)
-- do you expect large amount of attention and resources of academia and industry will be spent on AI alignment?
--- would you expect this will be somehow related to the technical problems and how we understand them?
--- eg do you think it makes no difference to the technical problem if 300 or 30k people work on it?
---- if it makes a difference, does it make a difference how is the attention allocated?
Not sure if the doublecrux between us would rest on the same cruxes, but I'm happy to try :)
The concept of "interfaces of misalignment" does not mainly point to GovAI-style research here (although it also may serve as a framing for GovAI). The concrete domains separated by the interfaces in the figure above are possibly a bit misleading in that sense:
For me, the "interfaces of misalignment" are generating intuitions about what it means to align a complex system that may not even be self-aligned - rather just one aligning part of it. It is expanding not just the space of solutions, but also the space of meanings of "success". (For example, one extra way to win-lose: consider world trajectories where our preferences are eventually preserved and propagated in a way that we find repugnant now but with a step-by-step endorsed trajectory towards it.)
My critique of the focus on "AI developers" and "one AI" interface in isolation is that we do not really know what the "goal of AI alignment" is, and it works with a very informal and a bit simplistic idea of what aligning AGI means (strawmannable as "not losing right away").
While a broader picture may seem to only make the problem strictly harder (“now you have 2 problems”), it can also bring new views of the problem. Especially, new views of what we actually want and what it means to win (which one could paraphrase as a continuous and multi-dimensional winning/losing space).
Multiscale agency, self-misalignment, and ecological basins of attraction? This sounds really excellent and targets a lot of the conceptual holes I worry about in existing approaches. I look forward to the work that comes out of this!!
I was reminded of a couple different resources you may or may not already be aware of.
For 'vertical' game theory, check out Jules' Hedges work on open/compositional games. https://arxiv.org/search/cs?searchtype=author&query=Hedges%2C+J
For aggregative alignment, there's an interesting literature on the topology of social choice, treating things like Arrow's voting theorem as a description of holes in the space of preferences. https://t.co/8HEpSu0SoE There's something cool going on where partially-overlapping locally-linear rankings can have much stranger global structures. I'm also reminded of this post comment, on the possible virtues of self-misalignment. https://www.lesswrong.com/posts/Di4bFP7kjoLEQLpQd/what-s-the-relationship-between-human-values-and-the-brain-s?commentId=zDt5auxfDAhcHktGm&s=09
A large amount of math describes the relations between agents at the same level of analysis: this is almost all of game theory. [...] our focus is on "vertical" relations, between composite agents and their parts.
This seems to be what is studied in the fields of organizational economics and to some extent in industrial organization / vertical integration. These fields have a great deal of game theory on vertical relationships, particularly relationships between the firm and its employees, managers, and contractors. Some of this can probably be ported to your interfaces. These fields are unsolved though, which means there's work left to do, but also that it's been difficult to find simple solutions, perhaps because you're modeling complex phenomena.
I like your section on self-unaligned agents btw. Curious what comes out of your centre.
If you’re interested in conceptual work on agency and the intersection of complex systems and AI alignment
I'm interested in this agenda, and I have been working on this kind of thing myself, but I am not interested at this time in moving to Prague. I figure that you are looking for people interested in moving to Prague, but if you are issuing a broad call for collaborators in general, or are thinking about setting up a much more distributed group, please clarify.
A more technical question about your approach:
What we’re looking for is more like a vertical game theory.
I'm not sure if you are interested in developing very generic kinds of vertical game theory, or in very specific acts of vertical mechanism design.
I feel that vertical mechanism design where some of the players are AIs is deeply interesting and relevant to alignment, much more so than generic game theory. For some examples of the kind of mechanism design I am talking about, see my post and related paper here. I am not sure if my interests make me a nearest neighbour of your research agenda, or just a very distant neighbour.
tl;dr: We’re a new alignment research group based at Charles University, Prague. If you’re interested in conceptual work on agency and the intersection of complex systems and AI alignment, we want to hear from you. Ideal for those who prefer an academic setting in Europe.
What we’re working on
Start with the idea of an "alignment interface": the boundary between two systems with different goals:
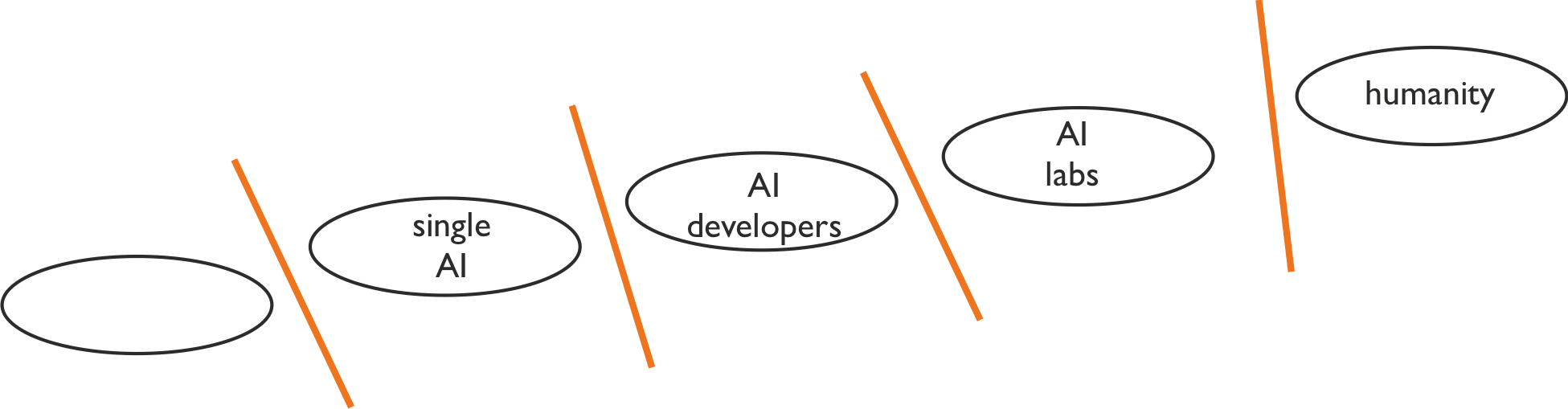
As others have pointed out, there’s a whole new alignment problem at each interface. Existing work often focuses on one interface, bracketing out the rest of the world.
e.g. the AI governance bracket
The standard single-interface approach assumes that the problems at each alignment interface are uncoupled (or at most weakly coupled). All other interfaces are bracketed out. A typical example of this would be a line of work oriented toward aligning the first powerful AGI system with its creators, assuming the AGI will solve the other alignment problems (e.g. “politics”) well.
Against this, we put significant probability mass on the alignment problems interacting strongly.
For instance, we would expect proposals such as Truthful AI: Developing and governing AI that does not lie to interact strongly with problems at multiple interfaces. Or: alignment of a narrow AI system which would be good at modelling humans and at persuasion would likely interact strongly with politics and geopolitics.
Overall, when we take this frame, it often highlights different problems than the single-interface agendas, or leads to a different emphasis when thinking about similar problems.
(The nearest neighbours of this approach are the “multi-multi” programme of Critch and Krueger, parts of Eric Drexler’s CAIS, parts of John Wentworth's approach to understanding agency, and possibly this.)
If you broadly agree with the above, you might ask “That’s nice – but what do you work on, specifically?” In this short intro, we’ll illustrate with three central examples. We’re planning longer writeups in coming months.
Hierarchical agency
Many systems have several levels which are sensibly described as an agent. For instance, a company and its employees can usually be well-modelled as agents. Similarly with social movements and their followers, or countries and their politicians.
Hierarchical agency: while the focus of e.g. game theory is on "horizontal" relations (violet), our focus is on "vertical" relations, between composite agents and their parts.
So situations where agents are composed of other agents are ubiquitous.
A large amount of math describes the relations between agents at the same level of analysis: this is almost all of game theory. Thanks to these, we can reason about cooperation, defection, threats, correlated equilibria, and many other concepts more clearly. Call this tradition "horizontal game theory".
We don't have a similarly good formalism for the relationship between a composite agent and its parts (superagent and subagent).[1] Of course we can think about these relationships informally: for example, if I say “this group is turning its followers into cultists”, we can parse this as a superagent modifying and exploiting its constituents in a way which makes them less “agenty”, and the composite agent "more agenty". Or we can talk about "vertical conflicts" between for example a specific team in a company, and the company as a whole. Here, both structures are “superagents” with respect to individual humans, and one of the resources they fight over is the loyalty of individual humans.
What we want is a formalism good for thinking about both upward and downward intentionality. Existing formalisms like social choice theory often focus on just one direction - for example, the level of individual humans is taken as the fundamental level of agency, and we use some maths to describe how individuals can aggregate their individual preferences into a collective preference. Other formal models - such as the relationship between a market and traders - have both “up” and “down” arrows, but are too narrow in what sort of interactions they allow. What we’re looking for is more like a vertical game theory.
We think this is one of the critical bottlenecks for alignment.[2]
Alignment with self-unaligned agents
Call the system we are trying to align the AI with the “principal” (e.g. an individual human).
Many existing alignment proposals silently assume the principal is "self-aligned". For instance, we take a “human” as having consistent preferences at a given point in time. But the alignment community and others have long realised that this does not describe humans, who are inconsistent and often self-unaligned.
A toy model: system H is composed of multiple parts p_i with different wants (eg. different utility functions), a shared world model, and an aggregation mechanism Σ (eg. voting). An alignment function f(H) yields (we hope) an aligned agent A.
If the principal is not self-aligned, then "alignment with the principal" can have several meanings, potentially incompatible with each other. Often, alignment proposals implicitly choose just one of these. Different choices can lead to very different outcomes, and it seems poorly understood how to deal with the differences.
For some characterizations of alignment, it seems likely that an apparently successfully(!) aligned AI will have an instrumental convergent goal to increase the self-alignment of the principal. However, putting humans under optimization pressure to become self-aligned seems potentially dangerous. Again, this problem seems understudied.
Ecosystems of AI services
This project is inspired by parts of Drexler's "Comprehensive AI Services".
Consider not just one powerful AGI, or several, but an entire "AI ecosystem" with different systems and services varying in power, specialization, and agency. The defining characteristic of this scenario is that no single agent has sufficient power to take over the ecosystem.
From here, protecting humans and their values looks different than in the classic single/single scenario. On the other hand, it seems quite likely that there is a deep connection between safety issues in the "AI in a box" case, and in the ecosystems case.
From the ecosystem view, different questions seem natural. We can ask about:
Details in a forthcoming post.
Who we are
We’re an academic research group, supported in parallel by a nonprofit.
On the academic side, we are part of the Center for Theoretical Studies at Charles University, a small interdisciplinary research institute with experts in fields such as statistical physics, evolutionary biology, cultural anthropology, phenomenology or macroecology.
Our non-academic side allows us greater flexibility, access to resources, and lets us compensate people at a competitive rate.
The core of the group is Jan Kulveit and Tomáš Gavenčiak; our initial collaborators include Mihaly Barasz and Gavin Leech.
Why we went with this setup
What we are looking for
We are fully funded and will be hiring:
Also: we can supervise MSc and PhD dissertations, meaning you can work with us while studying for an MSc, or work with us as your main doctoral programme. (You would need to fulfil some course requirements, but Charles University has a decent selection of courses in ML and maths.)
If either of the above research programmes are of interest to you, and if you have a relevant background and a commitment to alignment work, we want to hear from you. We expect to open formal hiring in mid-June.
We co-wrote this post with Gavin Leech. Thanks to Chris van Merwijk, Nora Amman, Ondřej Bajgar, TJ and many other for helpful comments and discussion.
We have various partial or less formal answers in parts of sociology, economics, political science, evolutionary biology, etc.
A longer explanation in forthcoming posts. Here is a rough and informal intuition pump: hierarchical agency problems keep appearing at many many places of the alignment landscape, and also at many other disciplines. For example, if we are trying to get AIs aligned with humanity, it's notable that various superagents have a large amount of power and agency, often larger than individual humans. In continuous takeoff scenarios this is likely to persist, even if the substrate they are running on gradually changes from humans to machines. Or, even in the case of single human, we may think about the structure of a single mind in these terms. To get the intuition, compare how our thinking about cooperation and conflict would be more confused and less precise without the formalisms and results of game theory and it's descendants: also, we would notice various problems ranging from evolution to politics to have some commonalities, and we would also have some natural language understanding, but overall, our thinking would be more vague and confused.