Causal Scrubbing: a method for rigorously testing interpretability hypotheses [Redwood Research]
39Buck
10LawrenceC
4Buck
2Thomas Kwa
3ryan_greenblatt
15Buck
8Neel Nanda
4Ansh Radhakrishnan
3Neel Nanda
2Kshitij Sachan
1Neel Nanda
2Kshitij Sachan
1Neel Nanda
2ryan_greenblatt
4ojorgensen
2Buck
16Erik Jenner
4Nora Belrose
1LawrenceC
2DanielFilan
3LawrenceC
2Lauro Langosco
3Buck
2Buck
1Lauro Langosco
1Pranav Gade
1LawrenceC
1rusheb
1Buck
New Comment
(I'm just going to speak for myself here, rather than the other authors, because I don't want to put words in anyone else's mouth. But many of the ideas I describe in this review are due to other people.)
I think this work was a solid intellectual contribution. I think that the metric proposed for how much you've explained a behavior is the most reasonable metric by a pretty large margin.
The core contribution of this paper was to produce negative results about interpretability. This led to us abandoning work on interpretability a few months later, which I'm glad we did. But these negative results haven’t had that much influence on other people’s work AFAICT, so overall it seems somewhat low impact.
The empirical results in this paper demonstrated that induction heads are not the simple circuit which many people claimed (see this post for a clearer statement of that), and we then used these techniques to get mediocre results for IOI (described in this comment).
There hasn’t been much followup on this work. I suspect that the main reasons people haven't built on this are:
- it's moderately annoying to implement it
- it makes your explanations look bad (IMO because they actually are unimpressive), so you aren't that incentivized to get it working
- the interp research community isn't very focused on validating whether its explanations are faithful, and in any case we didn’t successfully persuade many people that explanations performing poorly according to this metric means they’re importantly unfaithful
I think that interpretability research isn't going to be able to produce explanations that are very faithful explanations of what's going on in non-toy models (e.g. I think that no such explanation has ever been produced). Since I think faithful explanations are infeasible, measures of faithfulness of explanations don't seem very important to me now.
(I think that people who want to do research that uses model internals should evaluate their techniques by measuring performance on downstream tasks (e.g. weak-to-strong generalization and measurement tampering detection) instead of trying to use faithfulness metrics.)
I wish we'd never bothered with trying to produce faithful explanations (or researching interpretability at all). But causal scrubbing was important in convincing us to stop working on this, so I'm glad for that.
See the dialogue between Ryan Greenblatt, Neel Nanda, and me for more discussion of all this.
—
Another reflection question: did we really have to invent this whole recursive algorithm? Could we have just done something simpler?
My guess is that no, we couldn’t have done something simpler–the core contribution of CaSc is to give you a single number for the whole explanation, and I don’t see how to get that number without doing something like our approach where you apply every intervention at the same time.
I agree with the overall point (that this was a solid intellectual contribution and is a reasonable-ish metric), but there's been a non-zero amount of followups or at least use cases of this work, imo. Off the top of my head:
- In general, CaSc has been used on lots of toy/tiny models to a decent level of success. I agree that part of the reason for CaSc's lack of adoption is that the metric consistently returns "this explanation is not very faithful/complete/etc". For example:
- I checked the hypotheses for the toy modular arithmetic/group composition work with my own hand-crafted CaSc implementation and found that the modular arithmetic results held up quite well.
- CaSc-style tests were used by Marius and Stefan to confirm their solutions to Stephen Casper's Mech Interp challenges (challenge 1, challenge 2).
- etc.
- Erik Jenner's agenda is pretty closely related to causal scrubbing and is still actively being worked on.
I think that interpretability research isn't going to be able to produce explanations that are very faithful explanations of what's going on in non-toy models (e.g. I think that no such explanation has ever been produced). Since I think faithful explanations are infeasible, measures of faithfulness of explanations don't seem very important to me now.
By "explanations" you mean labeled high-level causal graphs right? Do you also think it's infeasible to identify sparse, unlabeled circuits as "the part of the model that's doing the task", like in ACDC, in a way that gets good performance on some downstream task?
By explanations, I think Buck means fully human understandable explanations.
Do you also think it's infeasible to identify sparse, unlabeled circuits as "the part of the model that's doing the task", like in ACDC, in a way that gets good performance on some downstream task?
Personally, I don't have a strong opinion and this will probably depend on the exact architecture and the extent of sparsity we demand. This seems related to other views I have on difficulties in interp (ETA: so I'm probably more pessimistic here than people who are more optimistic about interp), but at least partially orthogonal.
After a few months, my biggest regret about this research is that I thought I knew how to interpret the numbers you get out of causal scrubbing, when actually I'm pretty confused about this.
Causal scrubbing takes an explanation and basically says “how good would the model be if the model didn’t rely on any correlations in the input except those named in the explanation?”. When you run causal scrubbing experiments on the induction hypothesis and our paren balance classifier explanation, you get numbers like 20% and 50%.
The obvious next question is: what do these numbers mean? Are those good numbers or bad numbers? Does that mean that the explanations are basically wrong, or mostly right but missing various minor factors?
My current position is “I don’t really know what those numbers mean."
The main way I want to move forward here is to come up with ways of assessing the quality of interpretability explanations which are based on downstream objectives like "can you use your explanation to produce adversarial examples" or "can you use your explanation to distinguish between different mechanisms the model is using", and then use causal-scrubbing-measured explanation quality as the target which you use to find explanations, but then validate the success of the project based on whether the resulting explanations allow you to succeed at your downstream objective.
(I think this is a fairly standard way of doing ML research. E.g., the point of training large language models isn't that we actually wanted models which have low perplexity at predicting webtext, it's that we want models that understand language and can generate plausible completions and so on, and optimizing a model for the former goal is a good way of making a model which is good at the latter goal, but we evaluate our models substantially based on their ability to generate plausible completions rather than by looking at their perplexity.)
I think I was pretty wrong to think that I knew what “loss explained” means; IMO this was a substantial mistake on my part; thanks to various people (e.g. Tao Lin) for really harping on this point.
(We have some more ideas about how to think about "loss explained" than I articulated here, but I don't think they're very satisfying yet.)
—-
In terms of what we can take away from these numbers right now: I think that these numbers seem bad enough that the interpretability explanations we’ve tested don’t seem obviously fine. If the tests had returned numbers like 95%, I’d be intuitively sympathetic to the position “this explanation is basically correct”. But because these numbers are so low, I think we need to instead think of these explanations as “partially correct” and then engage with the question of how good it is to produce explanations which are only partially correct, which requires thinking about questions like “what metrics should we use for partial correctness” and “how do we trade off between those metrics and other desirable features of explanations”.
I have wide error bars here. I think it’s plausible that the explanations we’ve seen so far are basically “good enough” for alignment applications. But I also think it’s plausible that the explanations are incomplete enough that they should roughly be thought of as “so wrong as to be basically useless”, because similarly incomplete explanations will be worthless for alignment applications. And so my current position is “I don’t think we can be confident that current explanations are anywhere near the completeness level where they’d add value when trying to align an AGI”, which is less pessimistic than “current explanations are definitely too incomplete to add value” but still seems like a pretty big problem.
We started realizing that all these explanations were substantially incomplete in around November last year, when we started doing causal scrubbing experiments. At the time, I thought that this meant that we should think of those explanations as “seriously, problematically incomplete”. I’m now much more agnostic.
Really excited to see this come out! I'm in generally very excited to see work trying to make mechanistic interpretability more rigorous/coherent/paradigmatic, and think causal scrubbing is a pretty cool idea, though have some concerns that it sets the bar too high for something being a legit circuit. The part that feels most conceptually elegant to me is the idea that an interpretability hypothesis allows certain inputs to be equivalent for getting a certain answer (and the null hypothesis says that no inputs are equivalent), and then the recursive algorithm to zoom in and ask which inputs should be equivalent on a particular component.
I'm excited to see how this plays out at REMIX, in particular how much causal scrubbing can be turned into an exploratory tool to find circuits rather than just to verify them (and also how often well-meaning people can find false positives).
This sequence is pretty long, so if it helps people, here's a summary of causal scrubbing I wrote for a mechanistic interpretability glossary that I'm writing (please let me know if anything in here is inaccurate)
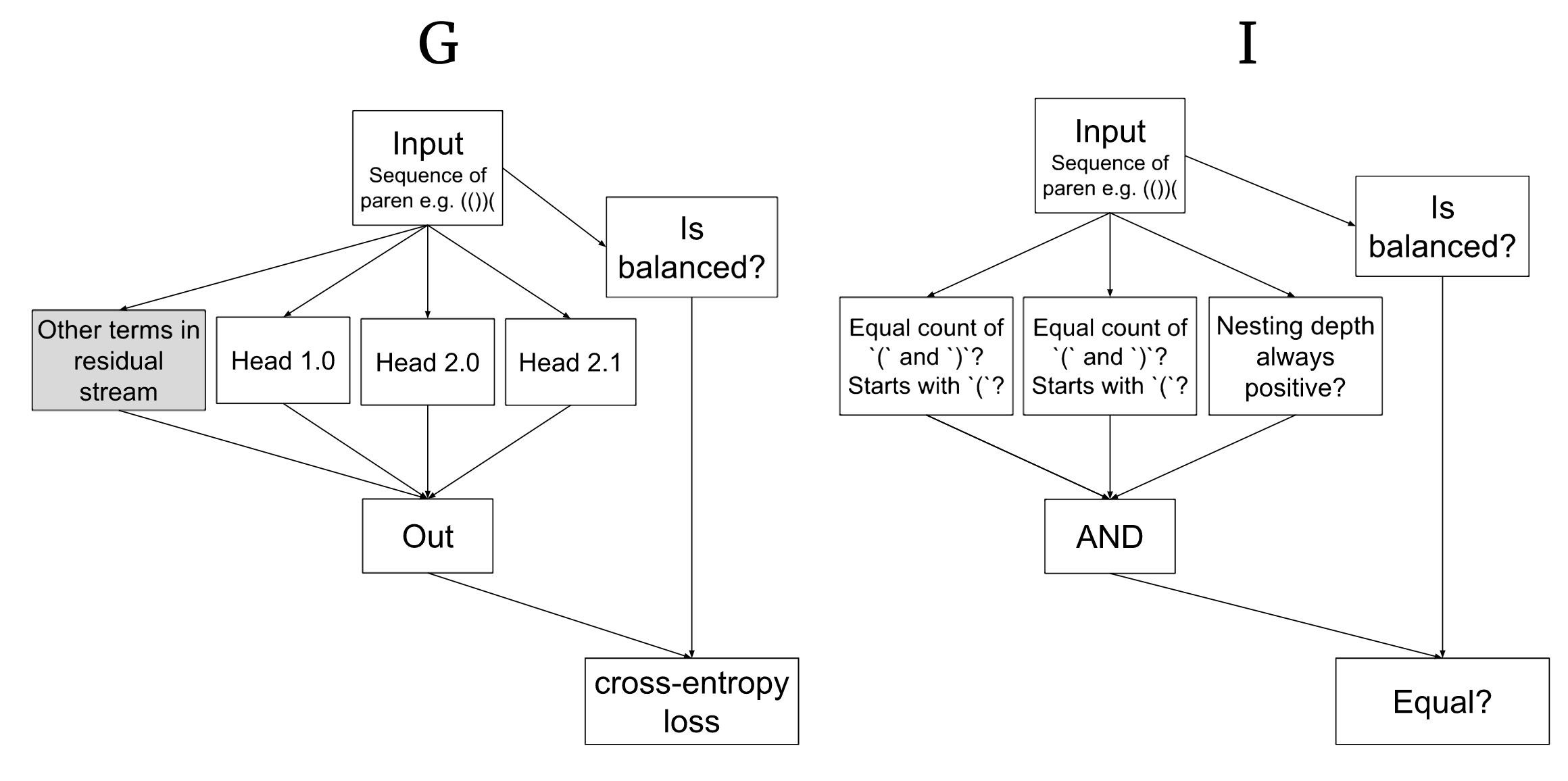
- Redwood Research have suggested that the right way to think about circuits is actually to think of the model as a computational graph. In a transformer, nodes are components of the model, ie attention heads and neurons (in MLP layers), and edges between nodes are the part of input to the later node that comes from the output of the previous node. Within this framework, a circuit is a computational subgraph - a subset of nodes and a subset of the edges between them that is sufficient for doing the relevant computation.
- The key facts about transformer that make this framework work is that the output of each layer is the sum of the output of each component, and the input to each layer (the residual stream) is the sum of the output of every previous layer and thus the sum of the output of every previous component.
- Note: This means that there is an edge into a component from every component in earlier layers
- And because the inputs are the sum of the output of each component, we can often cleanly consider subsets of nodes and edges - this is linear and it’s easy to see the effect of adding and removing terms.
- The differences with the above framing are somewhat subtle:
- In the features framing, we don’t necessarily assume that features are aligned with circuit components (eg, they could be arbitrary directions in neuron space), while in the subgraph framing we focus on components and don’t need to show that the components correspond to features
- It’s less obvious how to think about an attention head as “representing a feature” - in some intuitive sense heads are “larger” than neurons - eg their output space lies in a rank d_head subspace, rather than just being a direction. The subgraph framing side-steps this.
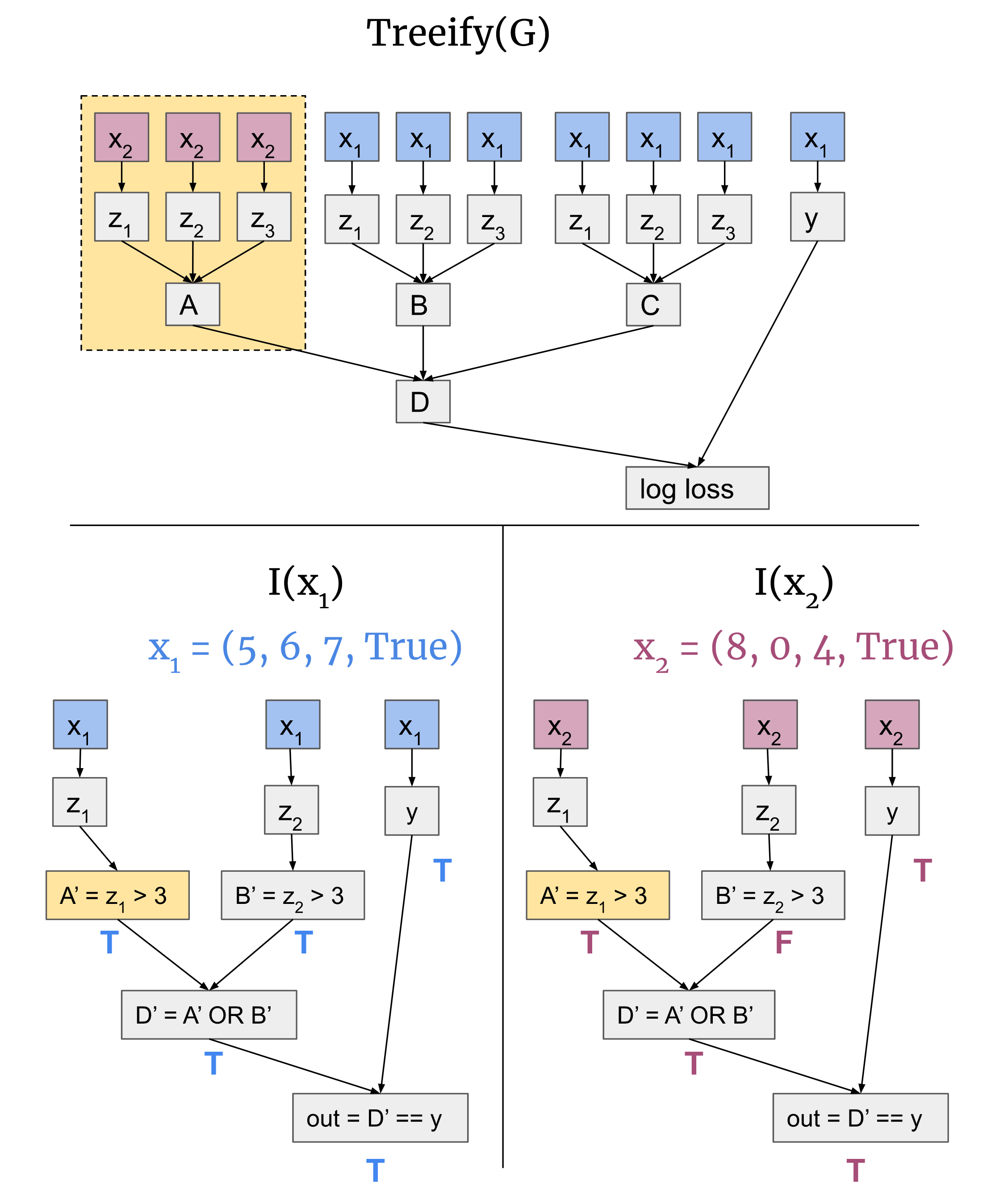
- Causal scrubbing: An algorithm being developed by Redwood Research that tries to create an automated metric for deciding whether a computational subgraph corresponds to a circuit.
- (The following is my attempt at a summary - if you get confused, go check out their 100 page doc…)
- The exact algorithm is pretty involved and convoluted, but the key idea is to think of an interpretability hypothesis as saying which parts of a model don’t matter for a computation.
- The null hypothesis is that everything matters (ie, the state of knowing nothing about a model).
- Let’s take the running example of an induction circuit, which predicts repeated subsequences. We take a sequence … A B … A (A, B arbitrary tokens) and output B as the next token. Our hypothesis is that this is done by a previous token head, which notices that A1 is before B, and then an induction head, which looks from the destination token A2 to source tokens who’s previous token is A (ie B), and predicts that the value of whatever token it’s looking at (ie B) will come next.
- If a part of a model doesn’t matter, we should be able to change it without changing the model output. Their favoured tool for doing this is a random ablation, ie replacing the output of that model component with its output on a different, randomly chosen input. (See later for motivation).
- The next step is that we can be specific about which parts of the input matter for each relevant component.
- So, eg, we should be able to replace the output of the previous token head with any sequence with an A in that position, if we think that that’s all it depends on. And this sequence can be different from the input sequence that the input head sees, so long as the first A token agrees.
- There are various ways to make this even more specific that they discuss, eg separately editing the key, value and query inputs to a head.
- The final step is to take a metric for circuit quality - they use the expected loss recovered, ie “what fraction of the expected loss on the subproblem we’re studying does our scrubbed circuit recover, compared to the original model with no edits”
in particular how much causal scrubbing can be turned into an exploratory tool to find circuits rather than just to verify them
I'd like to flag that this has been pretty easy to do - for instance, this process can look like resample ablating different nodes of the computational graph (eg each attention head/MLP), finding the nodes that when ablated most impact the model's performance and are hence important, and then recursively searching for nodes that are relevant to the current set of important nodes by ablating nodes upstream to each important node.
Exciting! I look forward to the first "interesting circuit entirely derived by causal scrubbing" paper
Nice summary! One small nitpick:
> In the features framing, we don’t necessarily assume that features are aligned with circuit components (eg, they could be arbitrary directions in neuron space), while in the subgraph framing we focus on components and don’t need to show that the components correspond to features
This feels slightly misleading. In practice, we often do claim that sub-components correspond to features. We can "rewrite" our model into an equivalent form that better reflects the computation it's performing. For example, if we claim that a certain direction in an MLP's output is important, we could rewrite the single MLP node as the sum of the MLP output in the direction + the residual term. Then, we could make claims about the direction we pointed out and also claim that the residual term is unimportant.
The important point is that we are allowed to rewrite our model however we want as long as the rewrite is equivalent.
Thanks for the clarification! If I'm understanding correctly, you're saying that the important part is decomposing activations (linearly?) and that there's nothing really baked in about what a component can and cannot be. You normally focus on components, but this can also fully encompass the features as directions frame, by just saying that "the activation component in that direction" is a feature?
Yes! The important part is decomposing activations (not neccessarily linearly). I can rewrite my MLP as:
MLP(x) = f(x) + (MLP(x) - f(x))
and then claim that the MLP(x) - f(x) term is unimportant. There is an example of this in the parentheses balancer example.
I would typically call
MLP(x) = f(x) + (MLP(x) - f(x))
a non-linear decomposition as f(x) is an arbitrary function.
Regardless, any decomposition into a computational graph (that we can prove is extensionally equal) is fine. For instance, if it's the case that MLP(x) = combine(h(x), g(x)) (via extensional equality), then I can scrub h(x) and g(x) individually.
One example of this could be a product, e.g, suppose that MLP(x) = h(x) * g(x) (maybe like swiglu or something).
ETA: We've now written a post that compares causal scrubbing and the Geiger et al. approach in much more detail: https://www.alignmentforum.org/posts/uLMWMeBG3ruoBRhMW/a-comparison-of-causal-scrubbing-causal-abstractions-and
I still endorse the main takeaways from my original comment below, but the list of differences isn't quite right (the newer papers by Geiger et al. do allow multiple interventions, and I neglected the impact that treeification has in causal scrubbing).
To me, the methods seem similar in much more than just the problem they're tackling. In particular, the idea in both cases seems to be:
- One format for explanations of a model is a causal/computational graph together with a description of how that graph maps onto the full computation.
- Such an explanation makes predictions about what should happen under various interventions on the activations of the full model, by replacing them with activations on different inputs.
- We can check the explanation by performing those activation replacements and seeing if the impact is what we predicted.
Here are all the differences I can see:
- In the Stanford line of work, the output of the full model and of the explanation are the same type, instead of the explanation having a simplified output. But as far as I can tell, we could always just add a final step to the full computation that simplifies the output to basically bridge this gap.
- How the methods quantify the extent to which a hypothesis isn't perfect: at least in this paper, the Stanford authors look at the size of the largest subset of the input distribution on which the hypothesis is perfect, instead of taking the expectation of the scrubbed output.
- The "interchange interventions" in the Stanford papers are allowed to change the activations in the explanation. They then check whether the output after intervention changes in the way the explanation would predict, as opposed to checking that the scrubbed output stays the same. (So along this axis, causal scrubbing just performs a subset of all the interchange interventions.)
- Apparently the Stanford authors only perform one intervention at a time, whereas causal scrubbing performs all possible interventions at once.
These all strike me as differences in implementation of fundamentally the same idea.
Anyway, maybe we're actually on the same page and those differences are what you meant by "pretty different algorithm". But if not, I'd be very interested to hear what you think the key differences are. (I'm working on yet another approach and suspect more and more strongly that it's very similar to both causal scrubbing and Stanford's causal abstraction approach, so would be really good to know if I'm misunderstanding anything.)
FWIW, I would agree that the motivation of the Stanford authors seems somewhat different, i.e. they want to use this measurement of explanation quality in different ways. I'm less interested in that difference right now.
FWIW it appears that out of the 4 differences you cited here, only one of them (the relaxation of the restriction that the scrubbed output must be the same) still holds as of this January paper from Geiger's group https://arxiv.org/abs/2301.04709. So the methods are even more similar than you thought.
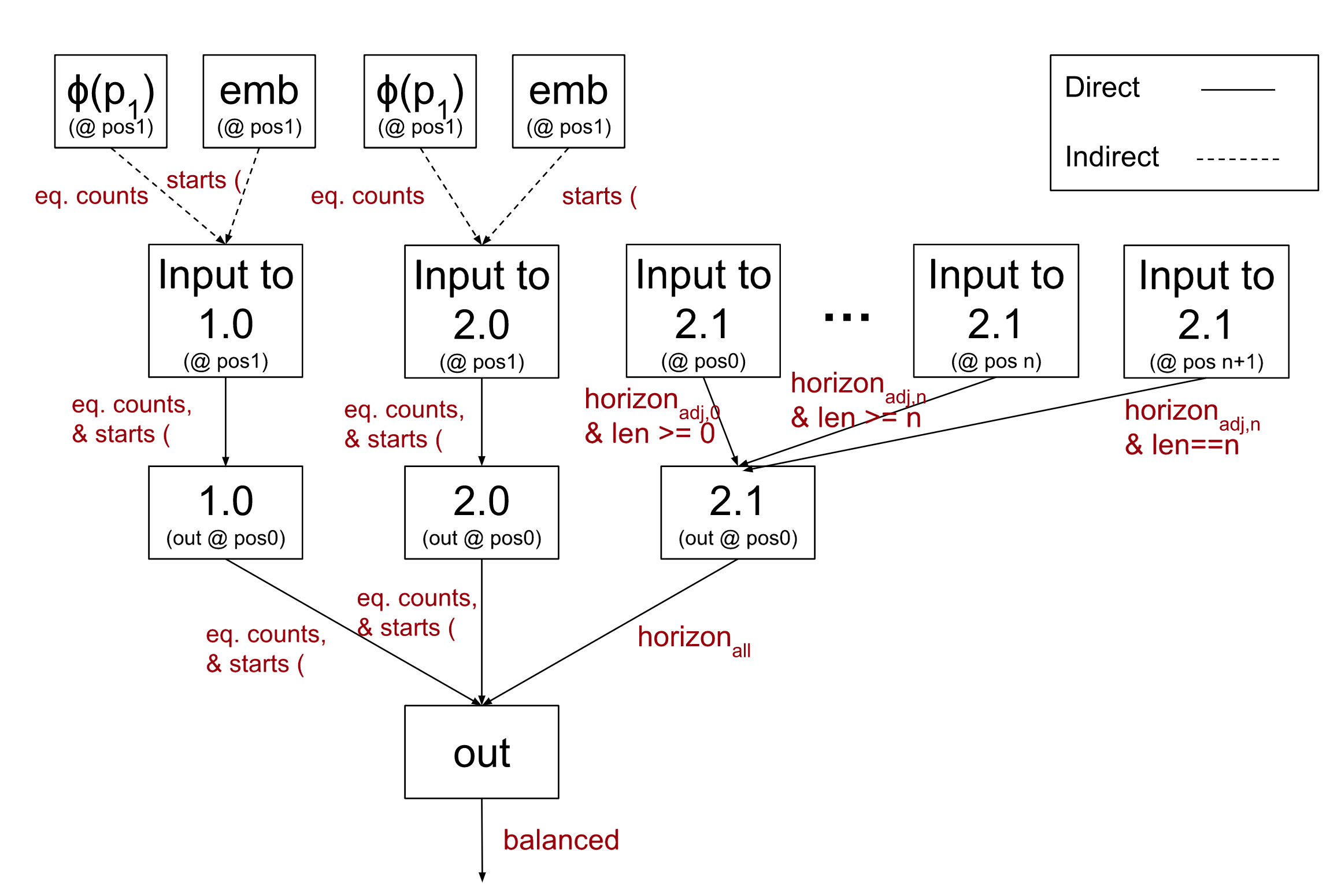
Am I right that this algorithm is going to visit each "important" node in once per path from to the output? If so, that could be pretty slow given a densely-connected interpretation, right?
Yep, this is correct - in the worse case, you could have performance that is exponential in the size of the interpretation.
(Redwood is fully aware of this problem and there have been several efforts to fix it.)
My current guess is that people who want to use this algorithm should just implement it from scratch themselves--using our software is probably more of a pain than it's worth if you don't already have some reason to use it.
I ended up throwing this(https://github.com/pranavgade20/causal-verifier) together over the weekend - it's probably very limited compared to redwood's thing, but seems to work on the one example I've tried.
If your hypothesis predicts that model performance will be preserved if you swap the input to any other input which has a particular property, but no other inputs in the dataset have that property, causal scrubbing can’t test your hypothesis
Would it be possible to make interventions which we expect not to preserve the model's behaviour, and assert that the behaviour does in fact change?
Something like this might be a good idea :) . We've thought about various ideas along these lines. The basic problem is that in such cases, you might be taking the model importantly off distribution, such that it seems to me that your test might fail even if the hypothesis was a correct explanation of how the model worked on-distribution.