Summary
I’m very interested in model-based RL as a framework for how people might build AGI, in large part because I think that human intelligence is built from scratch by within-lifetime learning in a model-based RL framework. (Meanwhile I give Evolution credit for developing the learning & inference algorithms, neural network architecture, reward functions, hyperparameters, various non-”intelligence”-related activities, etc. etc.)
But a lot of people find it more natural to think in terms of “agents with desires” rather than thinking in terms of “model-based RL algorithms”.
So this is my attempt at a pedagogical discussion of how the two paradigms relate: I’ll argue that a model-based RL algorithm is kinda like a system consisting of
- an agent with desires / preferences / goals / etc., and
- a little demon that manipulates the desires of that agent.
This then leads into a discussion of corrigibility and wireheading. For example, I’ll argue:
If you have a model-based RL agent that does foresighted planning, it’s generally “trying to do something”, but that thing it’s trying to do is generally not “maximize the reward signal”.
This parallels the by-now-familiar discourse on inner alignment, but it's not identical because most of the existing discourse is talking about model-free RL instead.
I’ll also talk about some aspects of how this seems to work in humans, which requires going beyond that simple picture, including a system for real-time-editable desires, and the possibility / inevitability of non-self-consistent desires.
Let’s dive in!
Terminology
What do I mean by “model-based RL”?
In My AGI Threat Model: Misaligned Model-Based RL, I offered something like this (somewhat oversimplified) diagram of what I'm thinking about:
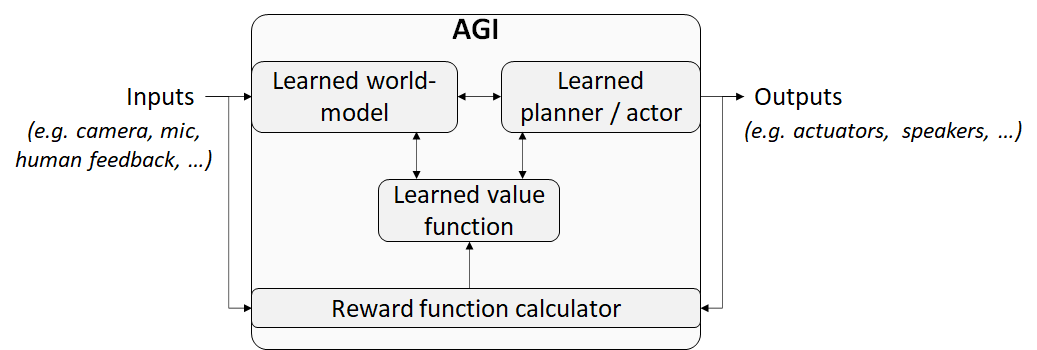
“Model-based RL” is a big category with blurry boundaries, I guess. (I don't keep up with the RL literature.) But when I talk about a model-based RL agent, I mean the following:
- The agent builds a predictive model of itself and its world based on experience of actions and observations. (“If I drop this ball it’s gonna bounce”.)
- The agent also builds a predictive model of both its immediate rewards and its longer-term reward expectations (a.k.a. value function), by combining the above model with a lifetime of experience of rewards. (“I hate stubbing my toe”.)
- …And in particular, the agent can not submit arbitrary hypothetical queries to the ground-truth reward function; it can only learn about the reward function by observing it in action. (“I thought I wouldn’t like watching this movie a second time, but actually I liked it even better!”)
- The agent takes actions that are predicted to lead to high future rewards according to its models. (“I moved the chair so that I won’t stub my toe on it”.)
- These bullet points are all separate things written into the source code. Like, maybe there’s a big complicated "world model'' data structure, and a big complicated "value function" data structure. Maybe we’re at a loss to interpret these data structures, but at least we can point to each of those data structures in RAM address space.
We can contrast this with model-free RL. There, foresighted planning might or might not happen, depending on the intricate details of its network architecture. And if it happens, the goal might or might not align with the reward function. This is by now a very familiar story on this forum—see dozens of posts about mesa-optimization, which Vladimir Mikulik pithily summarized with the slogan “Utility ≠ Reward”.
By contrast, in this kind of model-based RL, foresighted planning is part of the human-created architecture, and definitely happens, and we have at least a high-level idea of what that entails. But anyway, as I’ll argue below, Vladimir’s slogan “Utility ≠ Reward” still applies.
More terminology: Why I'll be talking about "desires" rather than "goals", "objectives", "utility functions"
Without getting into details (I’ll get back to this in the last section), I’ll use the term “desires” to encompass everything that leads to an agent doing one thing rather than another, when both options are viable and under consideration. So “desires” includes everything from “I want to get out of debt” to “I can’t resist another cigarette” to “I like this song”. It includes both conscious and unconscious desires, endorsed and unendorsed, etc.
I want you to think of desires as being mechanistically part of the agent’s cognition. I’m not talking about the behaviorism perspective, where I am merely acting “as if” I had certain desires. These desires correspond to actual things in my brain algorithm. Again, see the final section below for more discussion.
I’m using the term “desire” rather than “goal” or “objective” or “utility” because:
- Terms like goal / objective / utility have a bit more of a connotation that we’re specifically talking only about desires concerning future states, not desires about process / deontology / etc., let alone the non-consciously-endorsed “desire” to keep mentally replaying the song that’s stuck in my head;
- Terms like goal / objective / utility have a bit more of a connotation that the desires are coherent, self-consistent, well-defined, etc. For example, it seems sorta reasonable to me to say “I desire to get an early start to my day, but I also desire to keep my head on the pillow”. It would seem a bit weirder if I replaced the word “desire” in that quote with “goal” or “I assign a high utility”.
- The term “utility function”, in particular, is traditionally associated with the behaviorism / revealed preferences perspective I mentioned above—although I suppose not everyone uses it that way.
Then a desire-driven agent is one that makes decisions on the basis of its desires. As an important special case, such agents can make decisions using foresighted planning to bring about desirable future states of the world.
A relation between a model-based RL agent and a desire-driven agent [simplest version]
So here’s a starting sketch of how you might build a reward-maximizing agent out of a desire-driven agent.
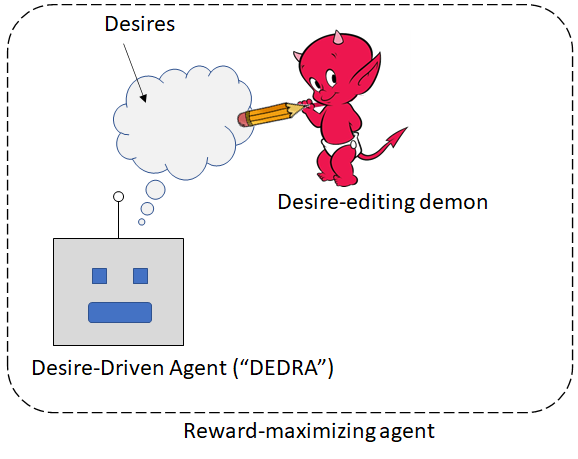
We take a desire-driven agent (call her “DEDRA”) and initialize her with no desires whatsoever. Then we add in a little demon that can get inside DEDRA’s head and edit her desires.
The demon has access to the reward signal, and the demon has access to DEDRA’s evaluation of the extent to which she is fulfilling her desires. The demon’s goal is to edit DEDRA’s desires such that the extent to which she desires something matches the corresponding total reward signal.
So if there’s a scenario for which DEDRA has “10 points of desire”, but when it happens the reward signal says “-5 reward points”, the demon notices the discrepancy and edits her desires to try to reduce the discrepancy.
Also, the demon is a simpleton. It doesn’t understand the world, or what determines the reward function, or what DEDRA’s desires actually mean semantically. So the demon has to update the desires using simple rules of thumb. For example, when it sees a discrepancy, maybe it looks at whatever DEDRA is thinking about right now, and says to itself “Hey, maybe that part of the world-model has something to do with the discrepancy?” So it tweaks the desirability of things involving that bit of the network. Or maybe the demon just does supervised-learning-via-backprop on the “desires” network, or whatever.
Another way to look at the demon’s role is: the reward function is a thing in the world, the desires are defined on DEDRA’s world model, and the demon is continually trying to match the two up.
So anyway, now we have a relation between a reward-maximizing agent and a desire-driven agent: the system as a whole (DEDRA + the demon) is a reward-maximizing agent, and one subcomponent of the system (DEDRA) is a desire-driven agent.
Then here’s the translation guide back to the world of model-based RL:
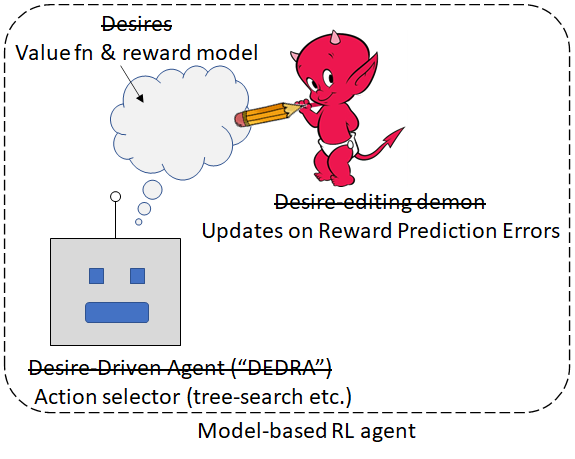
Here, “value function” is the (learned) expected sum of future rewards, and “reward model” is the (learned) prediction of rewards on any particular step. (As in MuZero, it’s helpful to have both; otherwise if you do an imagined roll-out, and you see the value suddenly jump downward, you don’t know whether this is an inconsistency in the value function, or whether there’s an expected reward for that step. Remember from above, I’m assuming we don’t have the ground-truth reward function; we have to learn it.)
You can think of the demon as providing, let’s call it, “normative grounding”. DEDRA can do a lot on her own—like she can do a hypothetical roll-out, find an area where her value function and reward model are not self-consistent, and update one to match the other. But only the demon can systematically shift DEDRA’s desires towards particular things in the world.
Why on earth would we want to make an agent this way?
“Want to”? I don’t want to! I mean, this is just awful!
For one thing, by instrumental convergence, DEDRA will by default sabotage the demon as soon as she can. Unless, of course, the demon can manipulate her in such a way that she likes and endorses the demon—a.k.a. corrigibility, see below. (Other options seem less promising to me, namely (1) prevent her from becoming aware of her situation, or (2) protect the demon from DEDRA via cybersecurity.)
For another thing, it’s hard to see how we’re going to be sure that the demon is doing its job properly, or to know how much progress it’s made. After all, the demon is using imperfect rules of thumb, and after a while the desires evolve into some horribly complicated mess, etc.
So this setup is just awful. Why on earth would we do this? In my view, the main reason to talk about this paradigm is:
People might make agents following this general paradigm because it would actually work for making a powerful goal-directed AGI, and I’m not sure we’ll come up with any other ideas.
The world is complicated. Presumably the only practical way to make an AI that understands the world is via a learning algorithm—one that finds patterns in the inputs, and then patterns in the patterns, etc. So by default the world-model will be a big mess of unlabeled items referencing each other. And then we need to define the agent’s desires in terms of this world-model. Somehow.
Well, this is one way to do that.
This method apparently works in humans—as I discussed here, I think the human brain (mainly parts of the neocortex) learns a world-model within our lifetimes from scratch, and the limbic system & brainstem & hypothalamus are involved in both calculating how desirable different plans / actions / thoughts are and updating those calculations to better match ground-truth calculations (more on which below), and several mechanisms involving dopamine ensure that we always think the most-desirable-to-us thoughts and execute the most-desirable-to-us plans.
So anyway, the point is, it seems to actually work. It creates powerful agents that understand the world and get things done. And there’s lots of researchers trying to do this kind of thing—cf. MuZero and the entire field of neuroscience, among other examples. We need to be considering the possibility that they’ll succeed.
Self-aware desires: wireheading and corrigibility
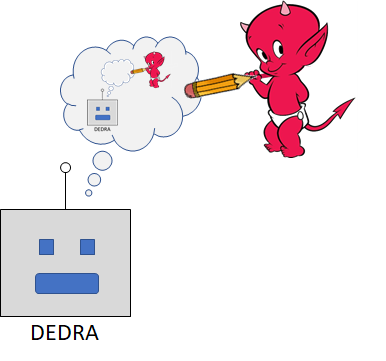
As mentioned above, DEDRA’s desires are defined on her world-model—they need to be defined in terms of concepts that DEDRA can currently conceive of. (See related discussion at The Pointers Problem and My AGI Threat Model.) It is possible that DEDRA will (eventually) be self-aware, and be aware of the existence of the demon, and be aware of the existence of the reward function. Therefore it is possible for DEDRA to wind up with a desire to “maximize my reward function” (wireheading), or “protect and help the demon” (corrigibility), or “sabotage the demon” (non-corrigible goal preservation), and so on. We turn to these possibilities next.
Self-aware desires 1: wireheading
I’ll distinguish two things:
- Weak wireheading drive: “I want a higher reward, other things equal.”
- Strong wireheading drive: “I want a higher reward, and this is the sum total of everything that I care about in the universe.”
In the human case, we naturally equate a wireheading drive with hedonism. I’m not sure that’s quite right—the various interoceptive feelings of pleasure, reward, etc. have a complicated relationship with the actual RL reward signal, I think—but even if it were right, it would suggest that (almost) all humans have a weak wireheading drive but not strong wireheading drive. We want to feel good, but we generally care at least a little bit about other things too.
This is what I would expect from the heuristic update-on-RPE procedure (a.k.a. demon desire-editing algorithm) that I suggested above. When we get an unanticipated reward, I suggested that maybe the demon looks at whatever we happen to be thinking about at the time, and sets those things to be more desirable. Maybe sometimes “the reward signal itself” would be on our mind, and the demon would assign some credit there, so we would come to desire the reward signal itself. But there are other things in the world-model that are getting credit too—food, friendship, the knowledge that I just stubbed my toe, and so on.
So, will a wireheading drive appear or not? And how strongly? Some relevant considerations include:
- Timing—If credit goes mainly to signals that slightly precede the reward prediction error, then the reward signal itself is not a great fit.
- “Finders Keepers”—Once you have a way to accurately predict some set of reward signals, it makes the reward prediction errors go away, so the demon stops running for those signals. So the first good reward-predicting desire gets to stick around by default. Example: we learn early in life that the "eating candy" concept predicts certain reward signals, and then we get older and learn that the "certain neural signals in my brain" concept predicts those same reward signals too. But just learning that fact doesn't automatically translate into "I really want those certain neural signals in my brain". Only the demon can make a thought appealing, and if the rewards are already being predicted competently, then the demon is inactive. (This is related to blocking in behaviorist psychology, and to “explaining away” in Bayes nets.)
- Priors—There may be some kind of bias to assign credit to predictive models that are simple functions of sensory inputs, when such a model exists, rather than functions of abstract semantic understanding, other things equal. (I'm thinking here of the relation between amygdala predictions, which I think are restricted to relatively simple functions of sensory input, versus agranular prefrontal cortex predictions, which I think can involve more abstract knowledge. I'm still kinda confused about how this works though, as discussed here.)
For AGIs, we’ll probably want to do other anti-wireheading interventions too, like (somehow) use transparency to find "the reward signal itself" in the world-model and manually lock its desirability to “neutral”, or whatever else we can think of. Also, if (as I expect) the failure mode in question is “weak wireheading drive” not strong—i.e., the desire to wirehead is trading off against other things it cares about—then hopefully conservatism (section 2 here) can help prevent catastrophe.
I note that even experts sometimes sloppily talk as if RL agents make plans towards the goal of maximizing future reward—see for example Pitfalls of Learning a Reward Function Online.
I still don’t think it’s a good idea to control a robot with a literal remote-control reward button; I just don’t think that the robot will necessarily want to grab that remote from us. It might or might not want to. It’s a complicated and interesting question.
Self-aware desires 2: corrigibility
As a human, I’m well aware that my hypothalamus & brainstem can edit and erase my deepest desires. Sometimes I don’t care. Like, I prefer chocolate ice cream over strawberry ice cream. If someday in the future I find myself preferring strawberry ice cream, then, well, OK! My tastes will evolve! Such is the human condition! It’s lovely! But other times I care very much. If someday my hypothalamus & brainstem make me gradually stop loving my children, that is not cool.
By the same token, if DEDRA is aware of the demon, she could wind up with desires related to the demon’s activities. Since goal stability is a convergent instrumental value, I expect that she will by default be motivated to sabotage the demon. However, it’s also possible that she specifically comes to like and endorse the demon and its activities. That’s (one aspect of) corrigibility, and that’s what we want for AGI safety.
If we get the reward function just right, then maybe we can get corrigibility automatically—the demon’s edits will assign high desirability to the concept of “the demon continuing to edit unperturbed”. I suspect that we’d need transparency tools to get such precise rewards. Alternatively, if we do have such transparency tools, we could just cut out the middleman, and directly locate the concept of “the demon continuing to edit unperturbed” in the world-model, and just manually set its desirability to “super-duper-desirable”.
Variation: The demon can edit “assessment functions” that serve as inputs to desirability
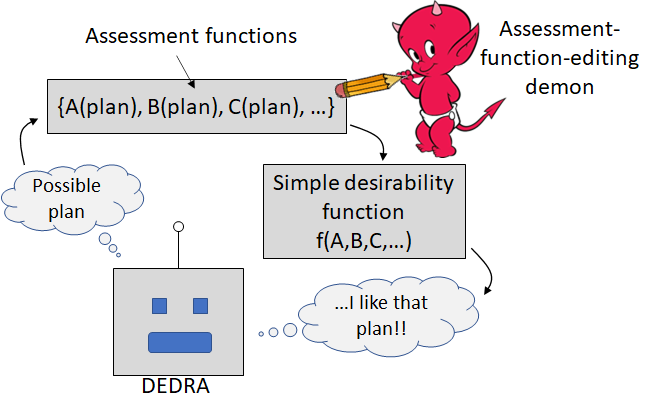
A cool variation is that instead of editing desires directly, the demon can edit a set of perhaps dozens of “assessment functions”, which then get fed into the real desirability-calculating function. The latter is now a simple legible function of those dozens of variables—all the complexity was pushed out of the desirability function and into the assessment functions.
I think this happens in humans and animals. As discussed in Big Picture of Phasic Dopamine, I think when you entertain a plan or idea or thought, various parts of your brain (amygdala, hippocampus, agranular prefrontal / insular / cingulate cortex, ventral striatum) calculate a whole array of anticipated physiological consequences of that plan: “If I do this, should I tense up? Should I salivate? Should I laugh? Should I cringe?” Each of those “assessments” is trained from experience by supervised learning (a.k.a. updated by the demon). Then the hypothalamus and brainstem take these assessments as inputs into the (now comparatively simple) desirability function. Importantly, they can also vary that desirability function in a situation-dependent way. For example, one of the assessment functions might be “how probable is it that this plan will result in eating lots of food?”. When you’re hungry, the hypothalamus adds extra desirability points to plans that score highly on that assessment. When you’re over-full, the hypothalamus subtracts desirability points from those same plans.
(It’s perfectly possible to directly learn that “eating when hungry is good, eating when full is bad” by pure rewards, without this more complicated two-layer system. It’s just slower, and requires more trial-and-error. See inner alignment in salt-starved rats for a concrete example of how this two-layer setup enables adaptive behavior without trial-and-error.)
I really like this setup as a generically good idea for AGI safety—in fact I was thinking about this kind of thing long before I realized that the brain works this way. (Certain ML systems work vaguely this way too, I guess.) Its two selling points are transparency and control.
The “transparency” part is, I think, self-explanatory. To be clear, I don’t have a particularly great plan for what the assessment functions should be, or how to train them, so as to help with transparency. It just seems like a good direction.
The “control” part is: When you’re driving a car, it is a critically important safety requirement that when you turn the steering wheel, the wheels respond instantaneously. By the same token, it seems like a critically important safety requirement for the human supervisor to be able to change an AGI’s goals and motivations instantaneously by pressing the appropriate button—even if the AGI is making complex abstract opaque plans about the distant future. Again, I don’t have a very specific plan here, it just seems generally promising.
Partially-grounded reward signals
There's an aspect of this scheme that I want to call out for clarity.
We calculate reward prediction error by subtracting reward prediction from reward. In textbook RL, these two terms represent a clean division:
- The reward is 100% grounded in the world, independent of the agent’s world-model and beliefs
- The reward prediction is the opposite—it’s purely a learned function of the agent's beliefs
In the two-layer setup here, the latter is still true, but the former is not true—instead, the reward signal is (in general) a messy function that mixes together grounded information from outside the world-model and learned information from inside it.
For example, if you have the idea "I'm gonna eat a salty cracker", then per the diagram above, there's an Assessment Function that says "this plan will result in eating salt". So far, this is a learned pattern in the world-model. Then there's a second step where the brainstem says, "gee, I’m kinda low on salt, so salt would be metabolically helpful right now", so it sends a positive reward for thinking that thought. This step is grounded—the brainstem-hypothalamus system gets metabolic status information straight from the body, not from the world-model. In fact, the brainstem has its own whole sensory-processing system (superior colliculus etc.), parallel and independent of the neocortex’s sensory-processing system, for getting grounded information that doesn't rely on learned representations. (Well, the two sensory systems do interact in various ways—interesting story, parts of which I still don’t entirely understand.)
I bring this up because a model-based RL AGI, like a human, will presumably need many reward signals per second in order to think thoughts and so on. But I expect that real ground-truth reward signals (e.g. from human feedback) will be relatively rare and expensive. Purely learned reward signals (e.g. as in Deep RL from human feedback) are the opposite extreme—they’re entirely dependent on the accuracy of certain learned models. It seems to me that this kind of partially-grounded reward function is maybe a nice compromise / alternative paradigm.
More on “desires”
I’ve been a bit vague about what “desires” are. I’m really thinking of a human-inspired definition along the lines of:
A “desirability function” is a function that takes a possible plan / scenario / thought and returns how “desirable” it is to make that plan / think that thought / etc.
To be clear, in my model, the brain always chooses a more desirable plan over a less desirable plan, when both are available options. I’m not trying to make some snarky point about human nature here; I mean this to be almost tautological, assuming that the brain algorithm is working properly. So if someone says to me “I didn’t want to exercise, but I did it anyway”, I would say that they must have actually found a way to think about the plan of exercising such that it was in fact a “desirable” plan on net. (See (Brainstem, Neocortex) ≠ (Base Motivations, Honorable Motivations) for much more on that.)
The demon inevitably makes somewhat-incoherent desires
The thing is, it’s a complicated world. There’s no law ensuring that the demon’s updates create a perfectly coherent, self-consistent set of desires. We could thus have one course of action, and when we “think about it in a certain way” it has high desirability, and when we “think about it in a different way” it has low desirability. This is just an inevitable part of the paradigm. DEDRA is not omniscient; there are relations and dependencies between different parts of her world-model that she hasn’t thought through. But the demon still has to tinker with her desires. It’s bound to result in something incoherent. I think there can be dynamics that make it gradually less incoherent over time (e.g. finding pareto-improving ways to reduce internal conflict, as I discussed here; or incompatible desires outright sabotaging each other, as I discussed here), but it’s no sure thing.
I guess this discussion probably has something to do with An Orthodox Case Against Utility Functions and logical induction and Jeffrey-Bolker and so on, but I’ll refrain from commenting further: I’m not an expert on that, and anyway this post is long enough already.
(Thanks Richard Ngo for helpful comments and criticisms.)