ABSTRACT: What could AI alignment look like if we had 6000+ full-time researchers and software developers? I've spent a few days thinking about that question, and this report is my first-draft attempt to answer it. This report sketches a highly-scalable research agenda: studying the hodge-podge assemblage of various "alignment primitives". Please let me know in the comments which ideas are novel and useful (if any), and which aren't.

Introduction
What is hodge-podge alignment?
I think that in the Technical AI Safety community, the following beliefs are common:
- The adequate solution to the alignment problem (if it exists) will look like one thing.
- That one thing might be quantilization, or debate, or ELK, or impact regularisation, or something else entirely.
- If we received a radio message from a friendly alien civilisation that solved alignment, it would say "hey humans, you should use this particular method to solve alignment".
Maybe those beliefs are correct — but in this report, I'll explore the alternative hypothesis. What if the only strategy that achieves is throwing every half-baked protocol we have at an AGI? Let's call this strategy "hodge-podge alignment".
Note that hodge-podge alignment differs from research diversification. The TAIS community is unanimously in favour of research diversification — i.e. they think we should explore many different research agendas. But their justification tends to be "we can't tell beforehand which research agenda will tell us the One Thing", rather than "we'll need to hodge-podge together the methods produced by each research agenda".
Give me an example.
There are dozens of "alignment primitives", but consider these four:
- Boxing: Run the AI on an air-gapped server with a narrow bandwidth channel to a human interlocutor. (See here.)
- Quantilization: The AI, rather than maximising the quality of actions, randomly selects from the top quantile of actions. (See here.)
- Impact regularisation: Penalise the AI for actions which significantly impact the environment. (See here.)
- Olah-style interpretability: Convert a neural network into a smaller computational graph whose nodes are annotated with human-legible concepts. (See here.)
We can "hodge-podge" together these primitives to give an assemblage:
- Assemblage: The AI randomly samples from the top 1% of actions as ranked by , where is our best proxy for human values, is an impact regularisation, and is a 1KB plaintext channel. Each neural network in the AI is compressed into and inspected by a human throughout training, evaluation, and deployment.
Will this work? I'm not sure.
I suspect that the assemblage would result in a safer AI than any of the four primitives used alone. But the goal of AI alignment is not to build a safe AI, but rather to build a safe and competent AI. (We already know how to build safe incompetent AI!) So the important question is: does the assemblage score higher than the primitives on the safety-competency trade-off? That's an open question.
Key Stages
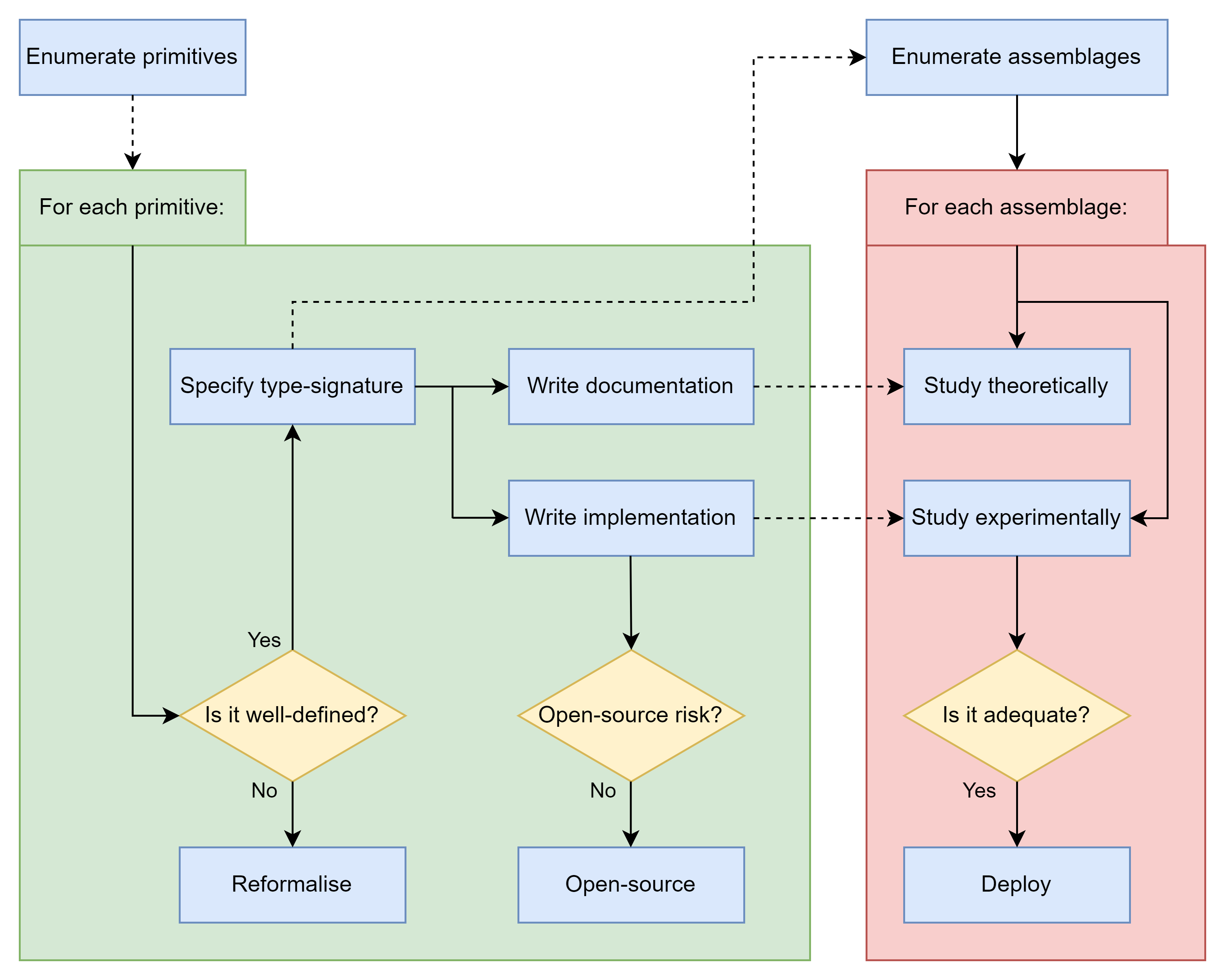
My tentative proposal consists of the following key stages:
- Exhaustively enumerate alignment primitives.
- Taxonomise primitives by their type-signature, documentation, and implementation.
- Enumerate potential alignment assemblages.
- Study the assemblages theoretically and experimentally.
- Deploy any assemblage if it's adequate.
1. Exhaustively enumerate alignment primitives.
There are a few broad overviews of different alignment agendas.
- Thomas Larsen's (My understanding of) What Everyone in Technical Alignment is Doing and Why
- Logan Zoellner's Various Alignment Strategies (and how likely they are to work)
- Holden Karnofsky's How might we align transformative AI if it’s developed very soon?
- Neel Nanda's My Overview of the AI Alignment Landscape
- Evan Hubinger's An overview of 11 proposals for building safe advanced AI
- Larks' yearly Alignment Literature Review and Charity Comparison
- Nate Soares' On how various plans miss the hard bits of the alignment challenge
- Andrew Critch's Some AI research areas and their relevance to existential safety
But there isn't (to my knowledge) an exhaustive enumeration of the different methods produced by those agendas. In Stage 1 of hodge-podge alignment, we compile and publish this list.
Let's call the list of alignment primitives .
In my imagination, our list of alignment primitives should look something like the list of cryptographic primitives. Cryptographic primitives are well-established, low-level algorithms which are assembled together to build more complicated cryptographic algorithms. If we assume that the cryptographic primitives are implemented correctly (i.e. they behave in the way described by their documentation), then we can be sure that the cryptographic assemblage is also implemented correctly. Moreover, if we discover that a particular cryptographic primitive is "broken" (i.e. it doesn't behave in the way described by its documentation) then we can replace the broken primitive with another primitive rapidly and seamlessly.
2. Taxonomise primitives by their type-signature, documentation, and implementation.
For each alignment primitive,
- Its type-signature specifies the types of objects passing through the input and output wires.
- Its documentation is a formal description of how the primitive should behave.
- Its implementation is a particular string of Python code that (hopefully) behaves as promised by the documentation.
(These three concepts will also extend to alignment assemblages.)
2a. Type-signature
In computer science, every function, subroutine or method has a "type-signature" defining its inputs and outputs. The type-signature doesn't say what the method does, but it says what type of object the method acts on and what type of object the method produces.
We can analogously talk about the "type-signature" of a particular alignment primitive. This type-signature specifies where in the AI-development pipeline the primitive could be implemented.
Here are some examples:
- The type-signature of impact regularisation is "reward function to reward function".
- The type-signature of quantilization is "ranking of actions to action".
- The type-signature of Olah-style interpretability is "large neural network to a small computational graph of human-legible concepts".
- The type-signature of amplification is "AI to AI".
- The type-signature of a sandbox is "< output from human, output from AI, internal state > to < input to human, input to AI, internal state >"
There are many different type-signatures that alignment primitives have:
- Pruning the dataset.
- Augmenting the dataset.
- Augmenting the reward function.
- Augmenting the training environment.
- Stopping buttons.
- Evaluation metrics.
- Boxing through training/evaluation/deployment.
- Exotic decision theories.
- etc-etc-etc-etc-
In Stage 2a of hodge-podge alignment, we determine the type-signature of each alignment primitive . This is necessary for us because constrains how the primitives can be assembled.
(But even ignoring hodge-podge alignment, it's useful to ask yourself: "What kind of object does this method act on? What kind of object does this method produce? What other methods could this method be composed with?" when thinking about particular alignment methods.)
2b. Implementation
In Stage 2b of hodge-podge alignment, we implement each primitive as a string of Python code . If the method isn't well-defined enough to be implemented as Python code, then we try to re-formalise it until we can implement it as Python code.
def quantilization(A, Q, q=0.01):
n = int(len(A)*q)+1
top_quantile = sorted(A, key=Q, reverse=True)[:n]
action = random.sample(top_quantile)
return actionThe code is written in a composable and modular way. So far, a lot of alignment methods have been implemented in code, but in a way that is entangled with the rest of the code. But we want the primitives to be implemented in a modular way so that we can hotswap then in our assemblages.
We might release these implementations as part of an open-source library, unless there are risks that this will exacerbate AI capabilities development. However, that risk is mitigated by the modular nature of the implementation. Although it would be risky to open-source the code of a sandboxed AI — it's not as risky to open-source the code of the sandbox itself.
2c. Documentation
The documentation of a primitive is a set of sentences describing how it should behave. The documentation can be written in a formal language, or in plain English.
The following are (equivalent?) definitions of the documentation:
- If all the properties in are satisfied, then the primitive is a success.
- If any of the properties in are not satisfied, then the primitive is broken.
- When we argue that an assemblage solves alignment, we appeal to the properties of the primitives.
- are the promises from the developer about the primitive .
- are the properties that won't be changed by the developer without warning.
- If a primitive is broken, then are properties that we'll demand from the replacement.
The documentation determines how the primitive should behave, and the implementation determines how the primitive does behave.
In Stage 2b of hodge-podge alignment, we write documentation for each primitive.
3. Enumerate potential alignment assemblages.
Once we know the type-signatures of the alignment primitives, we can then (mechanically) enumerate the different alignment assemblages. Let's call this list .
To construct an assemblage, we start with some sequence of primitives (not necessarily distinct), and then we "wire together" the outputs of some primitives to the inputs of others (so long as those wires are type-compatible).
More formally —
- The primitives are stateful dynamic systems, so we formalise them as polymorphic lenses.
- The category of polymorphic lenses is cartesian closed, so we can construct the "parallel product" of the primitives. The parallel product is just a formless heap — none of the primitives have been wired together yet.
- Finally, we can compose the parallel product with a particular "typed wiring diagram", because they are also formalised as polymorphic lenses.
- This yields an assemblage. An assemblage is the composition of a parallel product of primitives with a typed wiring diagram, in the category of polymorphic lenses.
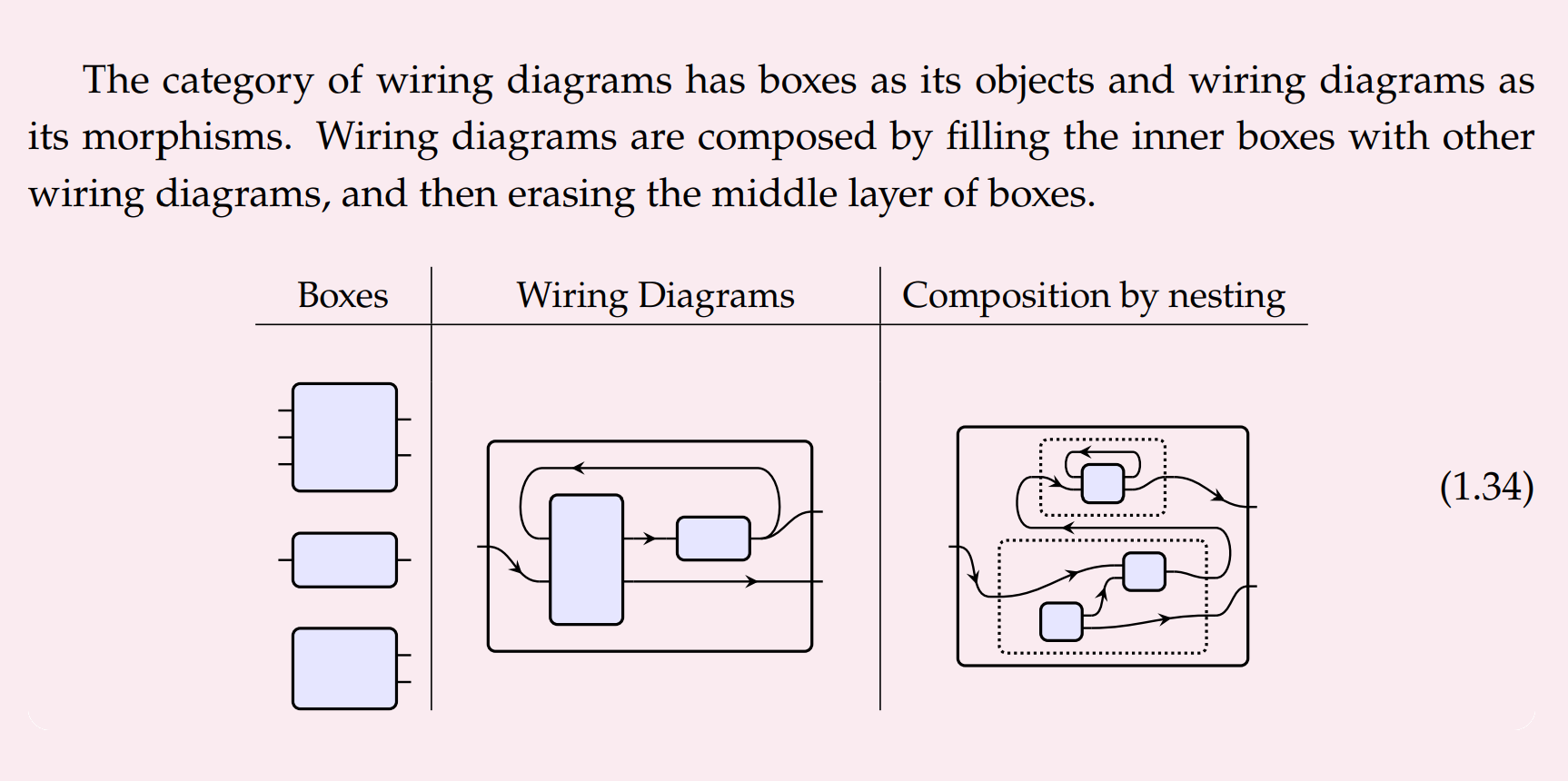
- The type-signature of the assemblage is determined by the wiring diagram.
- The implementation of the assemblage is straightforwardly determined by the wiring diagram and the implementations of the primitives.
- The documentation are the properties derivable (formally or informally) from the documentations of the primitives.
- This is because (I think) , , and are functors (ish).
Note that is different from :
- For a subset , there might exist no corresponding assemblage. This is because the type-signatures of the primitives in might forbid wiring.
- For a subset , there might exist many distinct corresponding assemblages — possibly infinitely many. This is because a primitive can appear more than once in an assemblage.
We call the degree of the assemblage — I suspect that (on average) safety will increase as increases, and competency will decrease.
4. Study assemblages theoretically and experimentally
In Stage 4 of hodge-podge alignment, the goal is to determine which alignment assemblages are reliable. An assemblage is reliable if we are confident that the implementation satisfies the documentation .
This is of course the hard step. Fortunately, this process can be heavily parallelised.
Theory:
In cryptography, you start with various "cryptographic assumptions" that particular cryptographic primitives are reliable, and then you derive theorems/informal arguments that the assemblages are reliable.
Likewise, in alignment, we will start with various "alignment assumptions" that particular alignment primitives are reliable, and then we derive theorems/informal arguments that the assemblages are reliable. In other words, we want arguments of the form .
Note that we can construct these arguments before we've actually found implementations for the alignment primitives!
Experiments:
To determine whether an assemblage has been implemented correctly we run experiments, e.g. toy-models, block-worlds. We test the implementation in a wide range of likely situations, and check if is satisfied.
Reliability:
We classify an assemblage as reliable whenever the following conditions hold:
- We're confident that the argument is valid.
- There is significant experimental evidence that the implementation satisfies the documentation .
- All the sub-assemblages of are reliable.
5. Deploy any assemblage if it's adequate.
An alignment assemblage is adequate if its documentation includes "everything goes well" and is reliable. If we discover an adequate alignment assemblage then we deploy it, hoping to achieve a pivotal act with a low probability of doom.
In practice, searching for an adequate assemblage might look like this:
- Start with a design for an unsafe but competent AI.
- Gradually add primitives until the AI is safe.
Or it might look like this:
- Start with a design for a safe but incompetent AI.
- Gradually remove primitives until the AI is competent.
This would be analogous to a nuclear power station adding and removing control rods to find a happy medium — but for us, we are seeking the optimal point in the safety-competency trade-off.
Motivation
Here are some reasons I think hodge-podge alignment is a reasonably promising research agenda.
1. Ex-ante Uncertainty
We might end up in a situation where we're confident that among our top 20 primitive methods there exists at least one method which reliably works, but we aren't sure beforehand which method is the reliable one. In this situation, it might be best to "assemble" them together.
Here's why I think this situation is likely:
- Right now, no one knows what method is best.
- There's been little convergence over time on a single method.
- AGI will arrive soon, so we'll probably be equally as unsure when it does arrive.
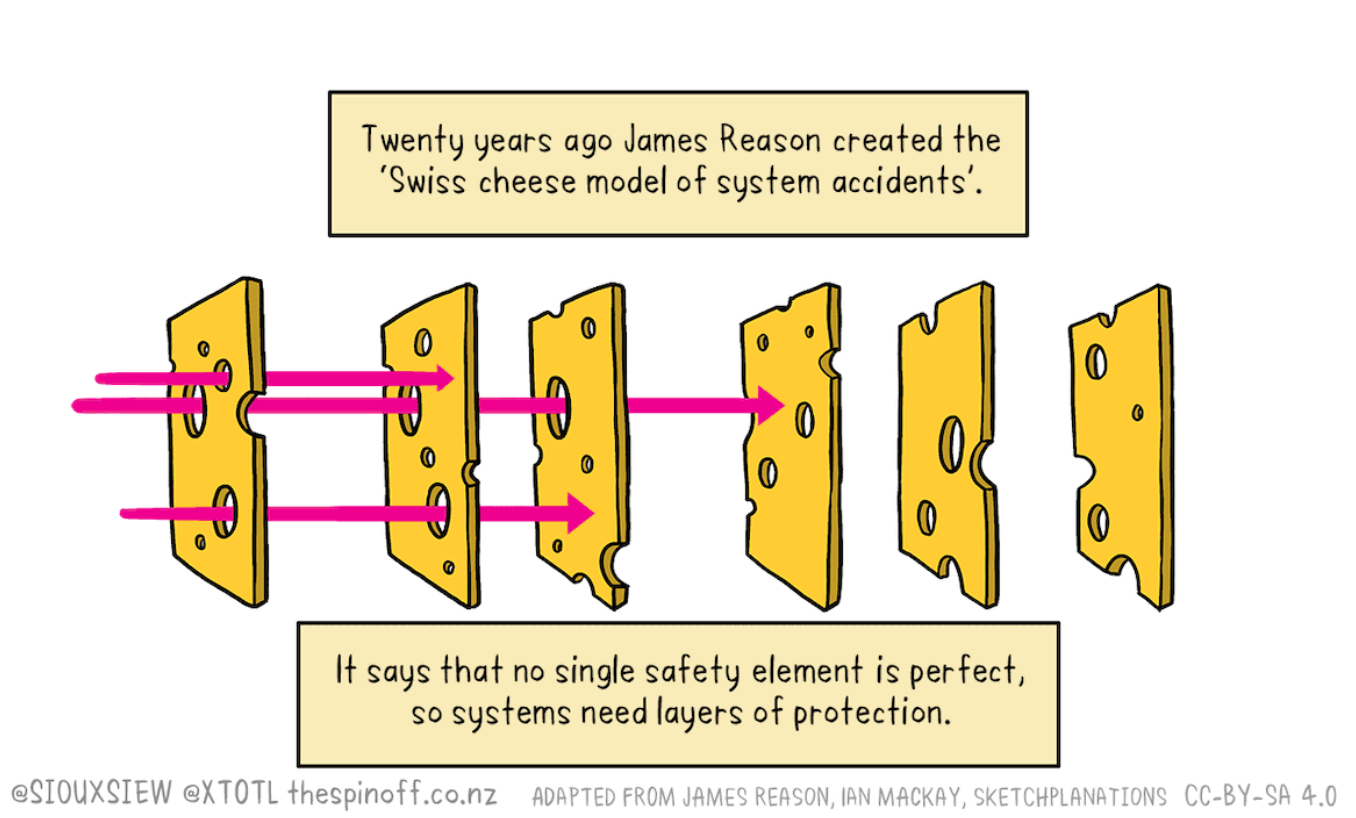
2. Swiss Cheese
We might end up in a situation where we're confident that each of our top 20 methods is unreliable, but if we "roll the dice" 20 times then we'll be confident that at least one of the methods will stop the failure. Therefore we apply all of them at once.
Here's why I think this situation is likely:
- Intelligence is a complicated messy thing in humans.
- Intelligence is a complicated messy thing in existing AI systems.
- There might not be any simple primitive which works reliably for such a messy thing.
- Often the best way to secure a messy thing is to assemble many layers of security — think aeroplane safety, the immune system, or internet firewalls.
3. Synergy
We might end up in a situation where among our top 20 methods, none of them works in isolation. But when we assemble the various methods, suddenly that works great because there's a weird synergy between the different methods.
I'm not confident this is true, but nonetheless:
- Sometimes synergy does occur.
- We might be lucky.
- Even if hodge-podge alignment is a "Hail Mary" solution, it's relatively more dignified than others.
4. Expanded Options
There is a canonical embedding of primitives into assemblages. So this proposal expands the set of potential methods without eliminating any. In fact, there's a combinatorial explosion in the number of potential options. If we expand our potential options, then our best option will (in general) improve.
5. Different talent-profile
Hodge-podge alignment doesn't invent the primitive ideas — instead, it converts these ideas into composable code and studies their assemblages. This process requires talent, but it requires a different talent profile than other alignment strategies — it needs more software engineers and fewer mathematicians.
6. Short-term gains
Hodge-podge alignment could make significant gains in the short-term because there's a lot of "theoretical overhang" in AI alignment — i.e. there are many ideas that haven't yet been implemented in Python.
7. Universality
Hodge-podge alignment is like the universal object in the category of alignment strategies. An "assemblage" captures what we mean (in the broadest sense) by a potential solution to the alignment problem.
8. Parallelisable and scalable
Hodge-podge alignment is highly parallelisable and scalable. Different primitive methods can be documented and implemented independently. Different assemblages can be studied independently.
Immediate next steps: If enough people say this is worthwhile (relative to how many say the opposite) then I'll explore this further. For the next step, I might post a distillation of David Jaz Myers Categorical systems theory which treats dynamic systems and their typed wirings as polymorphic lenses.