This post was written as part of Refine. Thanks to Adam Shimi, Alexander Gietelink Oldenziel, and Vanessa Kosoy for helpful discussion and feedback.
Summary
This post aims to:
- Advocate for embedding safety into development of machine learning models
- Propose a framing on how to think about safety, where three factors contribute to an AI being dangerous, namely misalignment, optimization, and influence
- Discuss the pros and cons of this framing
None of the ideas in this post are novel, and some of them may not even be practical, but they may be a useful framing to the problem of AI safety.
Introduction
Motivations
There are many ways to get to AGI. It could be recursively self improving AI, or something more brain-like, or something that comes from improvements in machine learning systems, or something else much more alien to us. I don’t know which pathways are the ones our world will eventually end up in, but given recent rapid advances in ML recently, in this post I will address the scenario where the first dangerous AGI is achieved by mostly scaling up and improving upon present-day ML systems.
In the absence of a robust solution to the hard problem of alignment, I think we should at least try to make the development of machine learning models go safely for as long as possible. This may be especially valuable if the first AGI we get is not yet an all-powerful superintelligent. It might be a fairly weak AGI capable of inflicting a lot of damage, but the damage could have been prevented. Not having a solution to the hard problem should not mean getting ourselves into preventable disasters.
What safety means in this context
Most safety fields in the real world don’t solve safety with guarantees. Whether it is flying an aircraft, operating a nuclear plant, or constructing a building, safety is all about effective risk management. This framing of safety has not been commonly used in the field of AI safety, for very good reasons, as the problem of a misaligned AGI is an unbounded one, where a ‘safety failure’ with a strong form of AGI could mean human extinction even with just a tiny degree of misalignment.
For the purpose of this post, I am using the word “safety” in a more narrow sense than most people would. In terms of time-scale, I refer to “we are safe for now” rather than “things go great in the long run”; while in terms of failure mode, I refer to “we are safe from misaligned AIs” rather than “we are safe from AIs being used by bad actors and multipolar failures etc”.
Framing the problem
The question to be addressed is: what makes an AI harmful? I propose a framing that contains three ingredients:
The combination of optimization and influence can be loosely thought of as agency. Without any of the above ingredients, there will not be a catastrophe caused by a misaligned ‘agentic’ AI, as there would only be the following kinds of AI:
- Aligned: A fully aligned AI that has strong optimization and high influence over the world will do exactly what we want effectively, possibly leading us to utopia.
- Dormant: A misaligned AI that has a lot of influence over the world but not trying to do anything will probably not really be doing anything, like a deactivated nuclear bomb.
- Sponge: A misaligned AI that has a lot of optimization power but no influence over the world will not be doing anything in the real world, effectively being a sponge AI. I consider most of the powerful AIs today, such as AlphaGo Zero and DALL-E 2, as sponges for now, as they neither construct world-models nor have physical control over things in the physical world, but it is debatable if they will remain so in the future.
In theory, in the absence of a solution to the alignment problem, the complete elimination of either optimization or influence is sufficient to ensure safety. Unfortunately, this is probably impossible in practice, as strong AIs will continue to be developed simply because weak AIs will be less useful than strong AIs. Nevertheless, there are steps that we can take to minimize the risks from the deployment of misaligned ‘agentic’ AIs, by introducing barriers to the threats of optimization and influence.
While many of the ideas in this post are adopted from the paper on unsolved problems in ML safety, this post aims to instead frame the problem in a commonsense way for those working on ML development to think about.
Using the bow tie model
The bow tie model is a common tool used in technical safety to visualize risk management and preparedness. The principle is that given a hazard, there could be many threats that lead to a risk event, which then leads to undesirable consequences. Barriers can be placed as preventive measures to prevent the risk event from being materialized, or as reactive measures after the risk event to limit the severity of the consequence. Using this model, the framing of the problem can be illustrated as below with some examples of barriers that will be covered in the next section.
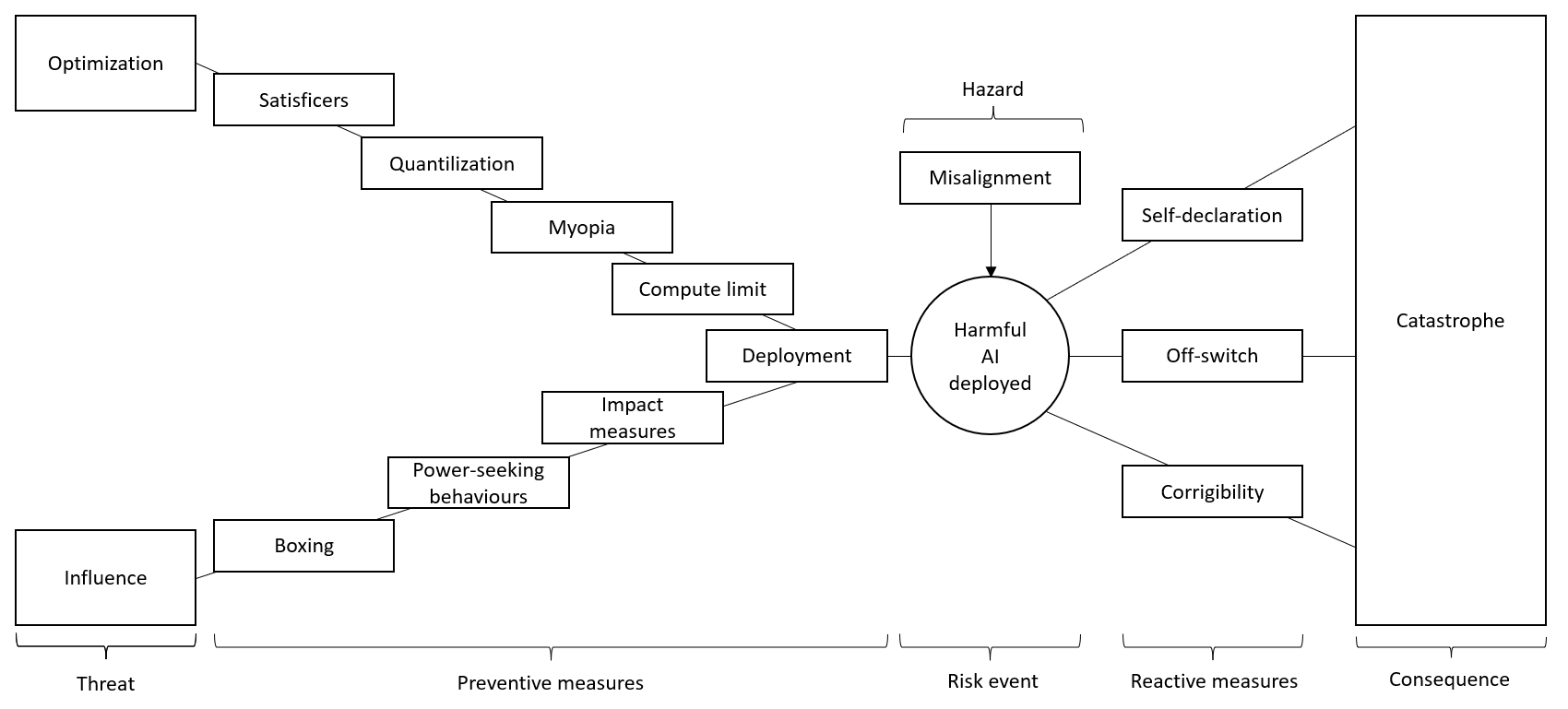
It should also be pointed out that none of the barriers are guarantees against failures. They should be thought of as slices of swiss cheese that have holes in them, where stacking many of them in succession lowers the probability of all of them being breached. Most of the barriers are still subjects of ongoing research and I am not making any claims on whether they are useful research directions, but rather describing how they may fit into this framing of the problem.
Breaking it down
Hazard: Misalignment
It is obviously most desirable to eliminate the hazard, as there cannot be an adverse consequence without a hazard. Unfortunately, if this were easy, it wouldn’t be known as “the hard problem”. Nevertheless, there may be ways to identify and minimize the misalignment of an ML system.
There are many different views on what types of misalignments there are and what they even mean. For now, I will mostly refer to misalignment as out-of-distribution (OOD) failure, where the model learns an objective that is misaligned from what we want it to have, and it could be in the form of simple objective robustness failure or deceptive alignment failure.
Generally, ML models are trained on a certain training dataset to achieve a minimum loss, and then deployed to be run in the deployment environment. Unfortunately, performance in the training environment may not generalize towards the deployment environment due to distributional shifts, as the model’s objectives do not generalize outside of the training distribution. For example, an image classifier trained to identify cats from dogs may perform well within the training dataset but is unable to properly identify cats it has never seen before, perhaps because it was picking up features of cat images that only happened to be true in the training dataset. There are also plenty of other empirical observations on objective robustness failures, and these failures only get more likely when the distribution of the deployment environment is long-tailed i.e. contains data points that tend to be very far outside the training distribution.
Hazard control: Adversarial robustness
Adversarial robustness can be described as a model’s ability to resist being fooled i.e. its robustness against adversarial inputs. It can be improved by adversarial training, where the training data are augmented by “adversarial” samples generated using various kinds of attack algorithms.
While in some situations adversarial training has been found to reduce the error rate from adversarial examples (adversarial error) without compromising much on the error from the original training dataset (clean error), for large-scale problems it has been much harder to build robust models that can match the clean error rate of standard models. In other words, increasing a model’s “capability” to generalize outside of the training distribution tends to decrease its performance as measured within the training distribution.
While it is debatable on whether robustness is worth pursuing as a research area, this post simply points out that it is a technique used to reduce OOD failures, albeit carrying trade-offs and doesn’t eliminate misalignments entirely.
Hazard identification: Monitoring
Misalignment in models could be identified using anomaly detection, where anomalous or OOD examples would be given higher anomaly scores used to assess robustness of a model. Anomaly detection can be conducted by training a classifier to detect examples using data from known OOD dataset, or one-class learning where data from a single distribution is used to train a classifier to detect OOD data.
Deceptive alignment, which happens when a model learns an objective that does not even generalize within the training distribution but is incentivized to appear to be aligned in order to maximize reward after deployment, should also be actively monitored.
Hazard identification: Interpretability
If we could completely observe and interpret what a model is doing, we would know what its objectives were, and how exactly it could be misaligned. Unfortunately, most large neural networks are so complicated that they behave like a black box. Interpretability, which broadly includes transparency and explainability (although often used interchangeably), aims to improve our understanding of what neural networks are doing.
An example of interpretability being applied in practice is feature visualization, where it was found that image classifiers were potentially classifying images based on heuristics that are “misaligned” from what we would imagine, e.g. detecting stripes instead of baseballs and snouts instead of animal faces.
Threat: Optimization
Optimization can be said as moving some part of the universe predictably towards a small set of target configurations. In the canonical example of a paperclip maximizer gone wrong by taking over the world and converting everything including humans into paperclips, it does so by extremely hard optimization to maximize a certain utility function i.e. number of paperclips produced. How do we then prevent such a catastrophic outcome? There are various proposals that aim to prevent optimizers from optimizing too hard. Unfortunately, none of these proposals have been implemented in actual AIs, as we usually can’t directly access an AI’s utility function unless it is explicitly specified. Nevertheless, if this becomes possible in the future, such implementations could potentially be useful safeguards against not-too-strong AIs.
Preventive measure: Satisficers
Instead of using maximizers, we could use satisficers, which aim to reach a certain level of utility and do no more. For example, a paperclip maximizer can be asked to manufacture a million paperclips within a month with 99% probability and stop there, such that it will not proceed to tile the universe with paperclips.
How this barrier fails: The easiest way to satisfice is to maximize, and satisficers may end up being maximizers anyway.
Preventive measure: Quantilization
Quantilization is an example of mild optimization, where a q-quantilizer can be defined as “an agent where when faced with a decision problem, returns a random action in the top q proportion of some “base distribution” over actions, sorted by the expected utility achieved if that action is executed”. For instance, after generating a set of possible actions ranked according to their associated expected utility, a 0.1-quantilizer would select a random action from the top 10% of actions instead of the action that produces the highest possible utility. A quantilized AI tasked to increase paperclip production may choose to build more production lines to triple production instead of tiling the universe with paperclips.
How this barrier fails: Even if generating the “base distribution” of actions is computationally realistic, it is difficult to determine what level of quantilization would strike the right balance between being useful and not being dangerous.
Preventive measure: Myopia
Myopia, meaning short-sighted, is where an agent neglects long-term consequences over the short-term. In practical terms, it only takes into account the reward from the immediate timestep as it carries a discount rate of 0 for future reward. In the case of an AI tasked with maximizing paperclip production, it will likely choose to run a paperclip manufacturing factory to produce paperclips immediately than strategically plan on tiling the universe with paperclips.
How this barrier fails: Among many other potential issues, myopia may not prevent dangerous long-term behavior.
Preventive measure: Compute limit
Assuming scaling laws are true, limiting available compute is probably the most straightforward way to prevent hard optimization as the model is literally unable to perform more calculations than allowed. Setting a compute limit on ML training is not a technical problem but a policy one, and even if it can be successfully implemented, its net effects are unclear.
How this barrier fails: The obvious issue is that presently no one has the power to enforce such a regulation, nor do we know how it’s supposed to be implemented in practice. It will also be unclear where the limit should be placed, as there is a direct tradeoff against being able to develop good useful AI. Furthermore, algorithmic improvements means that over time less compute may be required to perform the same level of optimization.
Threat: Influence
In practice, many AI systems have very limited direct influence over the world. For example, language models only output text, image generators only output images, and game-playing AIs are often confined to the game environments they interact with. Other AIs have more direct influence than others, such as robots, self-driving cars, and even autonomous weapons. However, limited direct influence does not mean limited indirect influence, as for instance powerful people or systems in the world may take actions based on outputs from a language model. Below, I will discuss common proposals on limiting influence, whether they are direct or indirect.
Preventive measure: Boxing
AI-boxing is about putting an AI in a ‘box’ where its interaction with the outside world is severely limited (not to be confused with putting AIs in boxing rings). This is probably the most straightforward limit on direct influence, and a ‘default’ for most of today’s AI systems anyway.
How this barrier fails: Humans may let the AI out of the box, if it didn’t already escape by hacking. (Also, the AI in a box boxes you)
Preventive measure: Identify power-seeking behavior
It is instrumentally useful to gain influence over the world, regardless of what the terminal goal is. (In this post, I mostly use the word ‘influence’ to describe what is commonly said as ‘power’ to avoid confusing it with ‘optimization power’.) There are currently proposals to test how close models are to being able to successfully seek power. One obvious difficulty is to ascertain what exactly constitutes power-seeking behavior and how to measure its level of danger.
How this barrier fails: This is not a barrier per se, as it only attempts to identify dangerous behaviors instead of stopping them.
Preventive measure: Impact measures
Impact measures penalize an AI for causing effects on the world. While it seems like a preventive measure against optimizing too hard, I find it more intuitive to think of it as limiting the influence of an agent without having to assume anything about its objective. Ideally, an AI penalized by impact measures will try not to cause too much changes to the environment. The difficulty lies in how impact should be measured, and it remains an open problem.
How this barrier fails: Assuming it works in the first place, there may also be low-impact effects that are not desirable.
Preventive measure: Deployment
For whatever reason, if a model doesn’t feel safe, the next step should be really simple - don’t deploy it. This would be the final barrier that can prevent a misaligned model from being “let out” in the real world.
Many disasters happen despite attempts to prevent them. Before the launch of the fatal Space Shuttle Challenger disaster in 1986, engineer Allan McDonald refused to sign the official form for a launch due to concerns that the effectiveness of the o-ring seals in the rocket booster may be compromised in low temperature conditions during launch. It is plausible that the fate of humanity rests on ML engineers trying to prevent deployment of ML models, and actually being listened to.
The big caveat is that this barrier assumes a clear-cut distinction between training and deployment, where danger is only present after deployment of an AI. This is not true in cases where an AI undergoes online learning, such as reinforcement learning (RL) models, in which case it may be better to think of deployment along the lines of ‘handing it to the user’.
How this barrier fails: Choosing not to deploy a model after spending all the time and effort developing it will not be easy. Not deploying a model now also does not prevent it from being deployed at a later time.
Consequence management
Reactive measure: Self-declaration
As far as possible, AI systems should be distinguishable from humans, so that human users know what they’re dealing with. To put it simply, AI systems should always announce that it is an AI. In failure modes that involve AI persuasion, for example an AI that persuades some human to mix proteins that could lead to some kind of dangerous nanomachinery, it might help if the human knows that it is dealing with an AI to be more vigilant.
This should be a fairly uncontroversial proposal which Demis Hassabis also agrees to, and it may also be something quite commonly implemented already (at least for chatbots who greet human users by introducing themselves as bots).
How this barrier fails: If this were easy, we would not be having so many problems with bot detection. Furthermore, it may not help to know that an AI is an AI if it is good enough at convincing or even credibly threatening the human to do something.
Reactive measure: Off switch
If we find out that an AI is not doing what we want after its deployment, it should be able to be switched off with a fail-safe switch. These switches could range from a simple halt command that kills the program to a switch that physically disconnects power from the server the AI is running on, or ideally a combination of independent off-switches.
Alternatively, safety interlocks may be introduced, where the AI is stopped when certain conditions are met. These triggers may be based on a simple runtime limit or compute limit, or it may also be based on certain monitored parameters, such as input anomalies or power-seeking behaviors.
How this barrier fails: As self-preservation is also instrumentally useful, strong AIs will resist being shut down since they cannot achieve their goals if they were. Proposed solutions to the problem include ensuring an agent is always uncertain about its utility function, as well as having a utility indifference towards being shut down, but it largely remains an open problem.
Reactive measure: Corrigibility
Corrigibility can be defined as (an agent’s) tolerability of being ‘corrected’, and is usually also used in the context of the agent being willing to be shut down, among other broader definitions (not to be confused with ‘retargatibility’, which is a property of an optimization process, where a system can be perturbed to have a different target configuration set). In simpler terms, we should have the ability to change the goal the AI is pursuing, after it has been deployed.
How this barrier fails: There would not be a ‘hard problem’ of corrigibility if it were easy, where some sub-problems include instrumental convergence goals like goal-content integrity, as well as an AI that thinks it has learned about its ideal target will stop deferring to humans. There are some proposals on solving the problem, e.g. by making AIs that have preference other than only its future states, but it also largely remains an open problem.
Using this framing in practice
In practice, thinking in terms of above framing can be done throughout the development of an AI system. The potential risks of deploying a particular model, the preventive barriers that can be put in place, and the consequence management strategy should be considered and implemented if relevant. Additionally, they should also be clearly documented and published, especially if details of the model will eventually be in the public domain. One way to do it is to include a section on safety aspects of the model in the papers that will be published, and describe in appropriate detail the considerations and safety measures taken.
Below are some examples of using this framing on different types of AI systems.
Image classifiers
A subdomain of computer vision, image classifiers like Inception v3 takes in an image as input and outputs the image class.
- Misalignment: Many adversarial robustness and anomaly techniques have been developed for image classifiers, and there are useful metrics on how robust an image classifier is.
- Optimization: There does not seem to be any optimization taking place in image classifiers that only do one feedforward pass.
- Influence: Image classifiers by itself do not have any influence over its environment as it takes in an input and gives an answer. But some computer vision programs may be used on systems that have more influence, including self-driving cars or even autonomous weapons. It is worth giving some thought as to who would be given access to these models.
- Consequence management: By themselves, image classifiers are not expected to be harmful, but depending on the implications, it may be worth having these programs not give an output it is uncertain about.
Image classifiers can generally be thought of as a ‘sponge AI’, until they are used on more powerful and influential systems.
Language models
Language models like GPT-3 work by taking in an input prompt and giving texts as output.
- Misalignment: It is difficult to define what constitutes OOD failures, as large language models (LLMs) are usually trained over such huge amounts of data that it is hard to properly establish if a prompt is outside of its training distribution. Nevertheless, there are proposals towards reducing potential ‘misaligned’ outputs, e.g. making language models express uncertainties in words, making sure outputs don’t result in people getting injured, and giving answers like ‘yo be real’ to nonsensical questions.
- Optimization: At a surface level, although it seems to be making very powerful predictions on its next token, it does not appear to be trying to steer the world into a certain target configuration state. Nevertheless, it is sometimes argued that the agents being simulated by language models may be capable of being powerful optimizers.
- Influence: Currently, its influence is also very limited, as it only interacts with the human user who gives it a prompt and has no direct influence itself.
- Consequence management: So far, language models can be easily shut down, and it does seem to perform any other actions than outputting texts when prompted. Although the direct influence of language models seem limited, human users could act upon outputs of these models, and there is alo a potential of integrating these models with other systems that has more direct influence on the world. Ideally, human users should always know whether some texts are generated by language models.
While language models currently seem fairly harmless, it is worth being cautious over their apparent ability to simulate agents more sophisticated than just doing next token prediction.
Generalist agents
Generalist agents like Gato are capable of performing a wide variety of tasks including playing games, captioning images, chatting, and performing physical acts with robots.
- Misalignment: This would have to be broken down into the individual tasks the agent is capable of performing, with respect to the training data it has been fed on.
- Optimization: Generalist agents do not yet seem to be optimizers, at least for Gato, as it still operates akin to a language model that uses transformer blocks with attention heads and is trained offline in a purely supervised manner. This may not be true of other potential generalist agents that have a different architecture and training method.
- Influence: For Gato in particular, it has direct control over a robot arm that is used to stack blocks. In theory, there is no reason why this influence cannot be expanded further. Caution should be exercised when such an agent is given more influence.
- Consequence management: It is worth thinking about how to switch off such a system when required, or at least be able to disconnect its physical controls (e.g. robot arm). Also, if such agents are more goal-directed, it may be crucial that their behavior or goals can still be changed after ‘deployment’.
Although in principle Gato works similar to a language model by having a transformer architecture, where input data is serialized into a flat sequence of tokens then assembled into various text or action outputs based on the context, in practice they have a much wider application and influence than pure language models.
Considerations
Let’s say everyone starts thinking about safety in this framing throughout the process of ML development, from the beginning when the models are being designed conceptually, all the way to the end where they include all of these considerations in the paper that is eventually published. There would be some direct downsides and upsides, and potentially some longer term harm and benefit, that are discussed below.
Downsides
Introduces an alignment tax
In the absence of any regulatory requirements, implementing safety aspects to ML development can be said as a voluntary alignment tax applied only on those who care to pay it. Currently, there may be little corporate or social incentives for these additional safety measures to be applied, especially when it is in direct conflict with capabilities.
Does not solve the hard problem
In addition to the fact that many of the measures in the framing are yet to be practically implementable, none of them even work against a strong AGI. A risk-based approach of placing multiple imperfect preventive and reactive barriers lowers the probability of a catastrophe but not to zero, and there is no reason to believe extremely powerful AIs will not be able to exploit these loopholes.
Prone to goodharting
If safety measures were being made more formally, whether it is in terms of soft industry norms or hard legally-binding regulations, they will be prone to goodharting - not by AI systems but by the humans who develop them. If there are safety metrics that are required to meet in order for models to be deployed, more likely than not developers will optimize for the safety metric instead of actual safety. If it becomes a norm to include a safety section at the start of every ML paper, eventually it may often contain nothing more than meaningless babble. In reality, safety requirements often become a box ticking exercise.
Assumes safety with linear causality
Framing the problem using a bow tie model assumes a simple linear causal model of safety. However, it can be argued that real world safety more closely resembles complex systems instead, and using linear causal models oversimplifies the complex nature of how safety works. Nevertheless, there is a fine balance between using simple models that capture enough elements that matter versus using a more accurate but complex model that dilutes the key focuses.
Upsides
Forces people to think about safety
Even if framing a problem does not lead to implementing useful solutions, it could be the first step in solving problems. At the very least, making ML developers think about safety forces them to engage with the problems. While the 2022 expert survey on progress in AI reports that “69% of respondents believe society should prioritize AI safety research “more” or “much more” than it is currently prioritized, up from 49% in 2016”, there is still plenty of room for improvement.
Goodharting could be better than nothing
While having safety turned into a box ticking exercise is definitely not ideal, it may still be better than not having such an exercise at all. Plenty of industries have safety regulations that are definitely prone to goodharting, but end up saving lives anyway.
Potential harm
Bad optics
Practices that are poorly implemented may be counterproductive, and may be a subject of ridicule in the form of “look at how these safety people are getting scared of cat dog classifiers taking over the world”. AI safety becoming a joke that is not taken seriously by competent ML developers is definitely not a great outcome. It may not be easy to strike a good balance on emphasizing AI safety enough but not over-exaggerating trivial risks.
May lead to false sense of security
When there is a clear framework with specific measures to be taken to ensure the safety of a system, it may lead to a mindset of “I’ve fulfilled all the safety requirements so it is safe”. Having a framework could make one ‘think inside the box’ and inhibit thinking about failure modes that are not part of the framework. Hence, it is often useful to be explicit about the limitations of safety measures.
Blurs the line between safety and capabilities
The distinction between safety and capabilities are often unclear. Development of potentially dangerous AI capabilities may inadvertently be caused by advances in safety, and there are examples where safety goals have caused capabilities externalities.
Any other second order effects
It can be argued that AI safety enables the creation and development of these technologies. As an example, it seems plausible that more widespread use of AI for military purposes hinges on better interpretability techniques. It is generally never easy to reason about second order (and higher) effects of any interventions.
Potential benefit
Focuses attention on real problems
By framing safety problems in a sensible manner, attention can be focused on capabilities that are actually potentially dangerous. Ideally, we do not unnecessarily prevent beneficial and harmless sponge AIs from being developed, but rather develop good reasoning on what constitutes a dangerous AI and whether those risks can be mitigated.
Any other second order effects
If AI safety is taken more seriously and proper regulations are put in place, this may inadvertently stifle AI development in general and delay AI timelines. As usual, it is generally never easy to reason about second order (and higher) effects of any interventions.
Conclusion
In summary, I encourage the following questions to be considered in the process of ML development:
- Misalignment: How is the AI trained, how could it be misaligned, and what can be done to reduce its misalignment i.e. improve its objective robustness? What can be done to identify these misalignments, deceptive or not?
- Optimization: Once deployed, how hard will the AI optimize for its goals? How can we prevent hard optimization?
- Influence: Once deployed, how much of the real world will the AI have influence over? How can we prevent models from having an undesirably large influence over its environment?
- Reactive measures: If a harmful AI is deployed, how do we prevent a catastrophe? How can we make it more likely to be switched off? Can we still change its value function or steer it towards a different goal?
I advocate for these questions to be actively considered, discussed, and published by everyone involved in ML development. AI safety should be the business of everyone in the field of AI and not just alignment researchers.