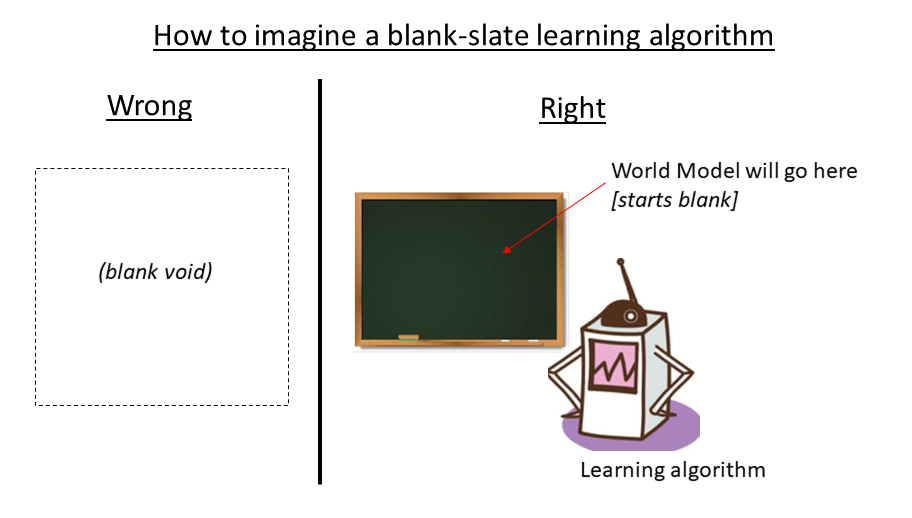
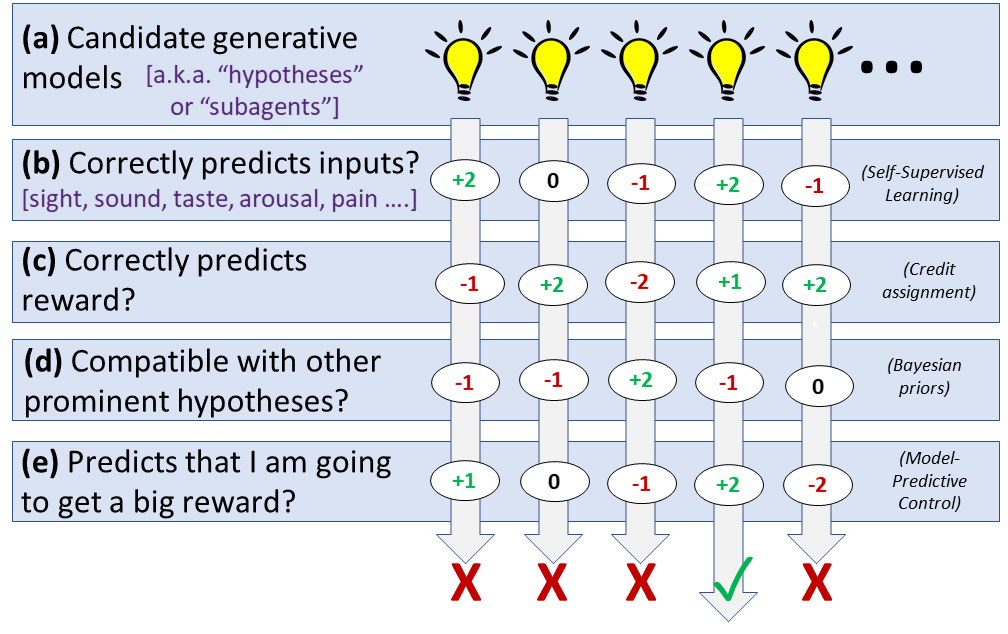
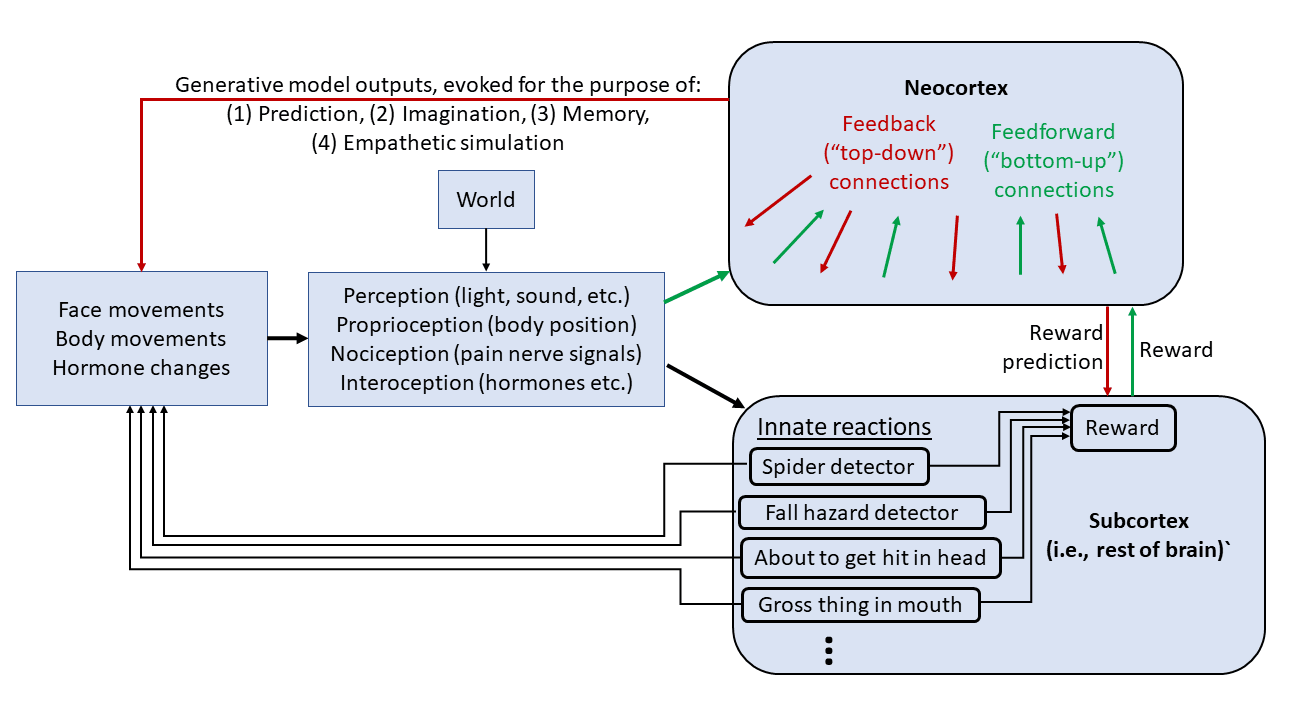
My computational framework for the brain
11evhub
5Steven Byrnes
8romeostevensit
7habryka
7Adam Scholl
5Steven Byrnes
5Steven Byrnes
2Steven Byrnes
6Steven Byrnes
New Comment
Some things which don't fully make sense to me:
- If the cortical algorithm is the same across all mammals, why do only humans develop complex language? Do you think that the human neocortex is specialized for language in some way, or do you think that other mammal's neocortices would be up to the task if sufficiently scaled up? What about our subcortex—do we get special language-based rewards? How would the subcortex implement those?
- Furthermore, there are lots of commonalities across human languages—e.g. word order patterns and grammar similarities, see e.g. linguistic universals—how does that make sense if language is neocortical and the neocortex is a blank slate? Do linguistic commonalities come from the subcortex, from our shared environment, or from some way in which our neocortex is predisposed to learn language?
- Also, on a completely different note, in asking “how does the subcortex steer the neocortex?” you seem to presuppose that the subcortex actually succeeds in steering the neocortex—how confident in that should we be? It seems like there are lots of things that people do that go against a naive interpretation of the subcortical reward algorithm—abstaining from sex, for example, or pursuing complex moral theories like utilitarianism. If the way that the subcortex steers the neocortex is terrible and just breaks down off-distribution, then that sort of cuts into your argument that we should be focusing on understanding how the subcortex steers the neocortex, since if it's not doing a very good job then there's little reason for us to try and copy it.
Thanks!!
why do only humans develop complex language?
Here's what I'm thinking: (1) I expect that the subcortex has an innate "human speech sound" detector, and tells the neocortex that this is an important thing to model; (2) maybe some adjustment of the neocortex information flows and hyperparameters, although I couldn't tell you how. (I haven't dived into the literature in either case.)
I do now have some intuition that some complicated domains may require some micromanagement of the learning process ... in particular in this paper they found that to get vision to develop in their models, it was important that first they set up connections between low-level visual information and blah blah, and after learning those relationships, then they also connect the low-level visual information to some other information stream, and it can learn those relationships. If they just connect all the information streams at once, then the algorithm would flail around and not learn anything useful. It's possible that vision is unusually complicated. Or maybe it's similar for language: maybe there's a convoluted procedure necessary to reliably get the right low-level model space set up for language. For example, I hear that some kids are very late talkers, but when they start talking, it's almost immediately in full sentences. Is that a sign of some new region-to-region connection coming online in a carefully-choreographed developmental sequence? Maybe it's in the literature somewhere, I haven't looked. Just thinking out loud.
linguistic universals
I would say: the neocortical algorithm is built on certain types of data structures, and certain ways of manipulating and combining those data structures. Languages have to work smoothly with those types of data structures and algorithmic processes. In fact, insofar as there are linguistic universals (the wiki article says it's controversial; I wouldn't know either way), perhaps studying them might shed light on how the neocortical algorithm works!
you seem to presuppose that the subcortex actually succeeds in steering the neocortex
That's a fair point.
My weak answer is: however it does its thing, we might as well try to understand it. They can be tools in our toolbox, and a starting point for further refinement and engineering. (ETA: ...And if we want to make an argument that We're Doomed if people reverse-engineer neocortical algorithms, which I consider a live possibility, it seems like understanding the subcortex would be a necessary part of making that argument.)
My more bold answer is: Hey, maybe this really would solve the problem! This seems to be a path to making an AGI which cares about people to the same extent and for exactly the same underlying reasons as people care about other people. After all, we would have the important ingredients in the algorithm, we can feed it the right memes, etc. In fact, we can presumably do better than "intelligence-amplified normal person" by twiddling the parameters in the algorithm—less jealousy, more caution, etc. I guess I'm thinking of Eliezer's statement here that he's "pretty much okay with somebody giving [Paul Christiano or Carl Shulman] the keys to the universe". So maybe the threshold for success is "Can we make an AGI which is at least as wise and pro-social as Paul Christiano or Carl Shulman?"... In which case, there's an argument that we are likely to succeed if we can reverse-engineer key parts of the neocortex and subcortex.
(I'm putting that out there, but I haven't thought about it very much. I can think of possible problems. What if you need a human body for the algorithms to properly instill prosociality? What if there's a political campaign to make the systems "more human" including putting jealousy and self-interest back in? If we cranked up the intelligence of a wise and benevolent human, would they remain wise and benevolent forever? I dunno...)
Trying to summarize your current beliefs (harder than it looks) is one of the best way to have very novel new thoughts IME.
Promoted to curated: This kind of thinking seems both very important, and also extremely difficult. I do think that trying to understand the underlying computational structure of the brain is quite useful for both thinking about Rationality and thinking about AI and AI Alignment, though it's also plausible to me that it's hard enough to get things right in this space that in the end overall it's very hard to extract useful lessons from this.
Despite the difficulties I expect in this space, this post does strike me as overall pretty decent and to at the very least open up a number of interesting questions that one could ask to further deconfuse oneself on this topic.
Your posts about the neocortex have been a plurality of the posts I've been most excited to read this year. I'm super interested in the questions you're asking, and it drives me nuts that they're not asked more in the neuroscience literature.
But there's an aspect of these posts I've found frustrating, which is something like the ratio of "listing candidate answers" to "explaining why you think those candidate answers are promising, relative to nearby alternatives."
Interestingly, I also have this gripe when reading Friston and Hawkins. And I feel like I also have this gripe about my own reasoning, when I think about this stuff—it feels phenomenologically like the only way I know how to generate hypotheses in this domain is by inducing a particular sort of temporary overconfidence, or something.
I don't feel incentivized to do this nearly as much in other domains, and I'm not sure what's going on. My lead hypothesis is that in neuroscience, data is so abundant, and theories/frameworks so relatively scarce, that it's unusually helpful to ignore lots of things—e.g. via the "take as given x, y, z, and p" motion—in order to make conceptual progress. And maybe there's just so much available data here that it would be terribly sisiphean to try to justify all the things one takes as given when forming or presenting intuitions about underlying frameworks. (Indeed, my lead hypothesis for why so many neuroscientists seem to employ strategies like, "contribute to the 'figuring out what roads do' project by spending their career measuring the angles of stop-sign poles relative to the road," is that they feel it's professionally irresponsible, or something, to theorize about underlying frameworks without first trying to concretely falsify a mountain of assumptions).
I think some amount of this motion is helpful for avoiding self-delusion, and the references in your posts make me think you do it at least a bit already. So I guess I just want to politely—and super gratefully, I'm really glad you write these posts regardless! If trying to do this would turn you into a stop sign person, don't do it!—suggest that explicating these more might make it easier for readers to understand your intuitions.
I have many proto-questions about your model, and don't want to spend the time to flesh them all out. But here are some sketches that currently feel top-of-mind:
- Say there exist genes that confer advantage in math-ey reasoning. By what mechanism is this advantage mediated, if the neocortex is uniform? One story, popular among the "stereotypes of early 2000s cognitive scientists" section of my models, is that brains have an "especially suitable for maths" module, and that genes induce various architectural changes which can improve or degrade its quality. What would a neocortical uniformist's story be here—that genes induce architectural changes which alter the quality of the One Learning Algorithm in general? If you explain it as genes having the ability to tweak hyperparameters or the gross wiring diagram in order to degrade or improve certain circuits' ability to run algorithms this domain-specific, is it still explanatorily useful to describe the neocortex as uniform?
- My quick, ~90 min investigation into whether neuroscience as a field buys the neocortical uniformity hypothesis suggested it's fairly controversial. Do you know why? Are the objections mostly similar to those of Marcus et al.?
- Do you have the intuition that aspects of the neocortical algorithm itself (or the subcortical algorithms themselves) might be safety-relevant? Or is your safety-relevance intuition mostly about the subcortical steering mechanism? (Fwiw, I have the former intuition, in that I'm suspicious some of the features of the neocortical algorithm that cause humans to differ from "hardcore optimizers" exist for safety-relevant reasons).
- In general I feel frustrated with the focus in neuroscience on the implementational Marr Level, relative to the computational and algorithmic levels. I liked the mostly-computational overview here, and the algorithmic sketch in your Predictive Coding = RL + SL + Bayes + MPC post, but I feel bursting with implementational questions. For example:
- As I understand it, you mention "PGM-type message passing" as a candidate class of algorithm that might perform the "select the best from a population of models" function. Do you just mean you suspect there is something in the general vicinity of a belief propagation algorithm going on here, or is your intuition more specific? If the latter, is the Dileep George paper the main thing motivating that intuition?
- I don't currently know whether the neuroscience lit contains good descriptions of how credit assignment is implemented. Do you? Do you feel like you have a decent guess, or know whether someone else does?
- I have the same question about whatever mechanism approximates Bayesian priors—I keep encountering vague descriptions of it being encoded in dopamine distributions, but I haven't found a good explanation of how that might actually work.
- Are you sure PP deemphasizes the "multiple simultaneous generative models" frame? I understood the references to e.g. the "cognitive economy" in Surfing Uncertainty to be drawing an analogy between populations of individuals exchanging resources in a market, and populations of models exchanging prediction error in the brain.
- Have you thought much about whether there are parts of this research you shouldn't publish? I notice feeling slightly nervous every time I see you've made a new post, I think because I basically buy the "safety and capabilities are in something of a race" hypothesis, and fear that succeeding at your goal and publishing about it might shorten timelines.
Your posts about the neocortex have been a plurality of the posts I've been most excited reading this year.
Thanks so much, that really means a lot!!
...ratio of "listing candidate answers" to "explaining why you think those candidate answers are promising, relative to nearby alternatives."
I agree with "theories/frameworks relatively scarce". I don't feel like I have multiple gears-level models of how the brain might work, and I'm trying to figure out which one is right. I feel like I have zero, and I'm trying to grope my way towards one. It's almost more like deconfusion.
I mean, what are the alternatives?
Alternative 1: The brain is modular and super-complicated
Let's take all those papers that say: "Let's just pick some task and try to explain how adult brains do it based on fMRI and lesion studies", and it ends up being some complicated vague story like "region 37 breaks down the sounds into phonemes and region 93 helps with semantics but oh it's also involved in memory and ...". It's not a gears-level model at all!
So maybe the implicit story is "the brain is doing a complicated calculation, and it is impossible with the tools we have to figure out how it works in a way that really bridges from neurons to algorithms to behavior". I mean, a priori, that could be the answer! In which case, people proposing simple-ish gears-level models would all be wrong, because no such model exists!
Going back to the analogy from my comment yesterday...
In a parallel universe without ML, the aliens drop a mysterious package from the sky with a fully-trained ImageNet classifier. Scientists around the world try to answer the question: How does this thing work?
90% of the scientists would immediately start doing the obvious thing, which is the OpenAI Microscope Project. This part of the code looks for corners, this thing combines those other things to look for red circles on green backgrounds, etc. etc. It's a great field of research for academics—there's an endless amount of work, you keep discovering new things. You never wind up with any overarching theory, just more and more complicated machinery the deeper you dive. Steven Pinker and Gary Marcus would be in this group, writing popular books about the wondrous variety of modules in the aliens' code.
Then the other 10% of scientists come up with a radical, complementary answer: the "way this thing works" is it was built by gradient descent on a labeled dataset. These scientists still have a lot of stuff to figure out, but it's totally different stuff from what the first group is learning about—this group is not learning about corner-detecting modules and red-circle-on-green-background modules, but they are learning about BatchNorm, xavier initialization, adam optimizers, etc. etc. And while the first group toils forever, the second group finds that everything snaps into place, and there's an end in sight.
(I think this analogy is a bit unfair to the "the brain is modular and super-complicated" crowd, because the "wiring diagram" does create some degree of domain-specificity, modularity, etc. But I think there's a kernel of truth...)
Anyway, someone in the second group tells their story, and someone says: "Hey, you should explain why the 'gradient descent on a labeled dataset' description of what's going on is more promising than the 'OpenAI microscope' description of what's going on".
Umm, that's a hard question to answer! In this thought experiment, both groups are sorta right, but in different ways... More specifically, if you want to argue that the second group is right, it does not involve arguing that the first group is wrong!
So that's one thing...
Alternative 2: Predictive Processing / Free Energy Principle
I've had a hard time putting myself in their shoes and see things from their perspective. Part of it is that I don't find it gears-level-y enough—or at least I can't figure out how to see it that way. Speaking of which...
Are you sure PP deemphasizes the "multiple simultaneous generative models" frame?
No I'm not sure. I can say that, in what I've read, if that's part of the story, it wasn't stated clearly enough to get through my thick skull. :-)
I do think that a (singular) prior is supposed to be mathematically a probability distribution, and a probability distribution in a high-dimensional space can look like, for example, a weighted average of 17 totally different scenarios. So in that sense I suppose you can say that it's at most a difference of emphasis & intuition.
My quick, ~90 min investigation into whether neuroscience as a field buys the neocortical uniformity hypothesis suggested it's fairly controversial. Do you know why?
Nope! Please let me know if you discover anything yourself!
Do you just mean you suspect there is something in the general vicinity of a belief propagation algorithm going on here, or is your intuition more specific? If the latter, is the Dileep George paper the main thing motivating that intuition?
It's not literally just belief propagation ... Belief propagation (as far as I know) involves a graph of binary probabilistic variables that depend on each other, whereas here we're talking about a graph of "generative models" that depend on each other. A generative model is more complicated than a binary variable—for one thing, it can be a function of time.
Dileep George put the idea of PGMs in my head, or at least solidified my vague intuitions by using the standard terminology. But I mostly like it for the usual reason that if it's true then everything snaps into place and makes sense, and I don't know any alternative with that property. The examples like "purple jar" (or Eliezer's triangular light bulb) seems to me to require some component that comes with a set of probabilistic predictions about the presence/absence/features of other components ... and bam, you pretty much have "belief propagation in a probabilistic graphical model" right there. Or "stationary dancing" is another good example—as you try to imagine it, you can just feel the mutually-incompatible predictions fighting it out :-) Or Scott Alexander's "ethnic tensions" post—it's all about manipulating connections among a graph of concepts, and watching the reward prediction (= good vibes or bad vibes) travel along the edges of the graph. He even describes it as nodes and edges and weights!
If you explain it as genes having the ability to tweak hyperparameters or the gross wiring diagram in order to degrade or improve certain circuits' ability to run algorithms this domain-specific, is it still explanatorily useful to describe the neocortex as uniform?
I dunno, it depends on what question you're trying to answer.
One interesting question would be: If a scientist discovers the exact algorithm for one part of the neocortex subsystem, how far are we from superhuman AGI? I guess my answer would be "years but not decades" (not based on terribly much—things like how people who lose parts of the brain early in childhood can sometimes make substitutions; how we can "cheat" by looking at neurodevelopmental textbooks; etc.). Whereas if I were an enthusiastic proponent of modular-complicated-brain-theory, I would give a very different answer, which assumed that we have to re-do that whole discovery process over and over for each different part of the neocortex.
Another question would be: "How does the neocortex do task X in an adult brain?" Then knowing the base algorithm is just the tiny first step. Most of the work is figuring out the space of generative models, which are learned over the course of the person's life. Subcortex, wiring diagram, hyperparameters, a lifetime's worth of input data and memes—everything is involved. What models do you wind up with? How did they get there? What do they do? How do they interact? It can be almost arbitrarily complicated.
Say there exist genes that confer advantage in math-ey reasoning. By what mechanism is this advantage mediated
Well my working assumption is that it's one or more of the three possibilities of hyperparameters, wiring diagram, and something in the subcortex that motivates some (lucky) people to want to spend time thinking about math. Like I'll be eating dinner talking with my wife about whatever, and my 5yo kid will just jump in and interrupt the conversation to tell me that 9×9=81. Not trying to impress us, that's just what he's thinking about! He loves it! Lucky kid. I have no idea how that motivational drive is implemented. (In fact I haven't thought about how curiosity works in general.) Thanks for the good question, I'll comment again if I think of anything.
Dehaene has a book about math-and-neuroscience I've been meaning to read. He takes a different perspective from me but brings an encyclopedic knowledge of the literature.
Do you have the intuition that aspects of the neocortical algorithm itself (or the subcortical algorithms themselves) might be safety-relevant?
I interpret your question as saying: let's say people publish on GitHub how to make brain-like AGIs, so we're stuck with that, and we're scrambling to mitigate their safety issues as best as we can. Do we just work on the subcortical steering mechanism, or do we try to change other things too? Well, I don't know. I think the subcortical steering mechanism would be an especially important thing to work on, but everything's on the table. Maybe you should box the thing, maybe you should sanitize the information going into it, maybe you should strategically gate information flow between different areas, etc. etc. I don't know of any big ways to wholesale change the neocortical algorithm and have it continue to work at least as effectively as before, although I'm open to that being a possibility.
how credit assignment is implemented
I've been saying "generative models make predictions about reward just like they make predictions about everything else", and the algorithm figures it out just like everything else. But maybe that's not exactly right. Instead we have the nice "TD learning" story. If I understand it right, it's something like: All generative models (in the frontal lobe) have a certain number of reward-prediction points. You predict reward by adding it up over the active generative models. When the reward is higher than you expected, all the active generative models get some extra reward-prediction points. When it's lower than expected, all the active generative models lose reward-prediction points. I think this is actually implemented in the basal ganglia, which has a ton of connections all around the frontal lobe, and memorizes the reward-associations of arbitrary patterns, or something like that. Also, when there are multiple active models in the same category, the basal ganglia makes the one with higher reward-prediction points more prominent, and/or squashes the one with lower reward-prediction points.
In a sense, I think credit assignment might work a bit better in the neocortex than in a typical ML model, because the neocortex already has hierarchical planning. So, for example, in chess, you could plan a sequence of six moves that leads to an advantage. When it works better than expected, there's a generative model representing the entire sequence, and that model is still active, so that model gets more reward-prediction points, and now you'll repeat that whole sequence in the future. You don't need to do six TD iterations to figure out that that set of six moves was a good idea. Better yet, all the snippets of ideas that contributed to the concept of this sequence of six moves are also active at the time of the surprising success, and they also get credit. So you'll be more likely to do moves in the future that are related in an abstract way to the sequence of moves you just did.
Something like that, but I haven't thought about it much.
Have you thought much about whether there are parts of this research you shouldn't publish?
Yeah, sure. I have some ideas about the gory details of the neocortical algorithm that I haven't seen in the literature. They might or might not be correct and novel, but at any rate, I'm not planning to post them, and I don't particularly care to pursue them, under the circumstances, for the reasons you mention.
Also, there was one post that I sent for feedback to a couple people in the community before posting, out of an abundance of caution. Neither person saw it as remotely problematic, in that case.
Generally I think I'm contributing "epsilon" to the project of reverse-engineering neocortical algorithms, compared to the community of people who work on that project full-time and have been at it for decades. Whereas I'd like to think that I'm contributing more than epsilon to the project of safe & beneficial AGI. (Unless I'm contributing negatively by spreading wrong ideas!) I dunno, but I think my predispositions are on the side of an overabundance of caution.
I guess I was also taking solace from the fact that nobody here said anything to me, until your comment just now. I suppose that's weak evidence—maybe nobody feels it's their place. or nobody's thinking about it, or whatever.
If you or anyone wants to form an IRB that offers a second opinion on my possibly-capabilities-relevant posts, I'm all for it. :-)
By the way, full disclosure, I notice feeling uncomfortable even talking about whether my posts are info-hazard-y or not, since it feels quite arrogant to even be considering the possibility that my poorly-researched free-time blog posts are so insightful that they materially advance the field. In reality, I'm super uncertain about how much I'm on a new right track, vs right but reinventing wheels, vs wrong, when I'm not directly parroting people (which at least rules out the first possibility). Oh well. :-P
(Oops I just noticed that I had missed one of your questions in my earlier responses)
I have the same question about whatever mechanism approximates Bayesian priors—I keep encountering vague descriptions of it being encoded in dopamine distributions, but I haven't found a good explanation of how that might actually work.
I don't think there's anything to Bayesian priors beyond the general "society of compositional generative models" framework. For example, we have a prior that if someone runs towards a bird, it will fly away. There's a corresponding generative model: in that model, first there's a person running towards a bird, and then the bird is flying away. All of us have that generative model prominently in our brains, having seen it happen a bunch of times in the past. So when we see a person running towards a bird, that generative model gets activated, and it then sends a prediction that the bird is about to fly away.
(Right? Or sorry if I'm misunderstanding your question.)
(Not sure what you saw about dopamine distributions. I think everyone agrees that dopamine distributions are relevant to reward prediction, which I guess is a special case of a prior. I didn't think it was relevant for non-reward-related-priors, like the above prior above bird behavior, but I don't really know, I'm pretty hazy on my neurotransmitters, and each neurotransmitter seems to do lots of unrelated things.)
I wrote this relatively early in my journey of self-studying neuroscience. Rereading this now, I guess I'm only slightly embarrassed to have my name associated with it, which isn’t as bad as I expected going in. Some shifts I’ve made since writing it (some of which are already flagged in the text):
- New terminology part 1: Instead of “blank slate” I now say “learning-from-scratch”, as defined and discussed here.
- New terminology part 2: “neocortex vs subcortex” → “learning subsystem vs steering subsystem”, with the former including the whole telencephalon and cerebellum, and the latter including the hypothalamus and brainstem. I distinguish them by "learning-from-scratch vs not-learning-from-scratch". See here.
- Speaking of which, I now put much more emphasis on "learning-from-scratch" over "cortical uniformity" when talking about the neocortex etc.—I care about learning-from-scratch more, I talk about it more, etc. I see the learning-from-scratch hypothesis as absolutely central to a big picture of the brain (and AGI safety!), whereas cortical uniformity is much less so. I do still think cortical uniformity is correct (at least in the weak sense that someone with a complete understanding of one part of the cortex would be well on their way to a complete understanding of any other part of the cortex), for what it’s worth.
- I would probably drop the mention of “planning by probabilistic inference”. Well, I guess something kinda like planning by probabilistic inference is part of the story, but generally I see the brain thing as mostly different.
- Come to think of it, every time the word “reward” shows up in this post, it’s safe to assume I described it wrong in at least some respect.
- The diagram with neocortex and subcortex is misleading for various reasons, see notes added to the text nearby.
- I’m not sure I was using the term “analysis-by-synthesis” correctly. I think that term is kinda specific to sound processing. And the vision analog is “vision as inverse graphics” I guess? Anyway, I should have just said “probabilistic inference”. :-)
(More on all these topics in my intro series!)
Anyway the post is nice as a snapshot of where I was at that point, and I recall the comments and other feedback being very helpful to me. (Thanks everyone!)
Curated and popular this week