I think this is great overall.
One area I'd ideally prefer a clearer presentation/framing is "Safety/performance trade-offs".
I agree that it's better than "alignment tax", but I think it shares one of the core downsides:
I'm not claiming that this is logically implied by "Safety/performance trade-offs".
I am claiming it's what most people will imagine by default.
I don't think this is a problem for near-term LLM safety.
I do think it's a problem if this way of thinking gets ingrained in those thinking about governance (most of whom won't be reading the papers that contain all the caveats, details and clarifications).
I don't have a pithy description that captures the same idea without being misleading.
What I'd want to convey is something like "[lower bound on risk] / performance trade-offs".
Really interesting point!
I introduced this term in my slides that included "paperweight" as an example of an "AI system" that maximizes safety.
I sort of still think it's an OK term, but I'm sure I will keep thinking about this going forward and hope we can arrive at an even better term.
We’ve recently released a comprehensive research agenda on LLM safety and alignment. This is a collaborative work with contributions from more than 35+ authors across the fields of AI Safety, machine learning, and NLP. Major credit goes to first author Usman Anwar, a 2nd year PhD student of mine who conceived and led the project and did a large portion of the research, writing, and editing. This blogpost was written only by David and Usman and may not reflect the views of other authors.
I believe this work will be an excellent reference for anyone new to the field, especially those with some background in machine learning; a paradigmatic example reader we had in mind when writing would be a first-year PhD student who is new to LLM safety/alignment. Note that the agenda is not focused on AI existential safety, although I believe that there is a considerable and growing overlap between mainstream LLM safety/alignment and topics relevant to AI existential safety.
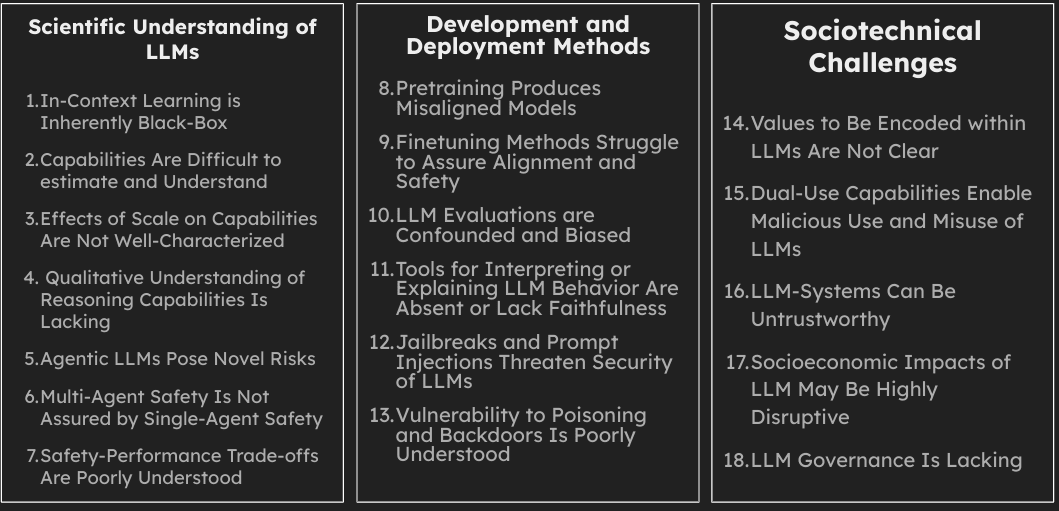
Our work covers the following 18 topics, grouped into 3 high-level categories:
Why you should (maybe) read (part of) our agenda
The purpose of this post is to inform the Alignment Forum (AF) community of our work and encourage members of this community to consider engaging with it. A brief case for doing so:
Topics of particular relevance to the Alignment Forum community:
Critiques of interpretability (Section 3.4)
Difficulties of understanding capabilities (section 2.2) and implications for evals (section 3.3)
Sociotechnical Challenges (Section 4)
Safety/performance trade-offs (Section 2.7)
Summary of the agenda content:
As a reminder, our work covers the following 18 topics, grouped into 3 high-level categories. These categories can themselves be thought of as ‘meta-challenges’.

Scientific understanding of LLMs
This category includes challenges that we believe are more on the understanding side of things, as opposed to the developing methods side of things. We specifically call out for more research on understanding ‘in-context learning’ and ‘reasoning capabilities’ in LLMs (sections 2.1 & 2.4); how they develop, how they manifest, and most importantly how they might evolve with further scaling and research progress in LLMs.. We have two sections (sections 2.2 & 2.3) that focus on challenges related to conceptualizing, understanding, measuring, and predicting capabilities. These sections in particular we believe are worth a read for researchers working on capabilities evaluations. We also call for more research into understanding the properties and risks of LLM-agents in both single-agent and multi-agent settings (sections 2.5 and 2.6). In pre-LLM times, research on (reinforcement-learning-based) ‘agents’ was a relatively popular research area within the AI Safety community, so, there is plausibly lots of low-hanging fruit in terms of just identifying what prior research from RL agents (in both single-agent and multi-agent settings) transfers to LLM-agents. The last section in this category (section 2.7) is focused on challenges related to identifying and understanding safety-performance trade-offs (aka alignment-tax), which is another research direction that we feel is highly important yet only nominally popular within the AI Safety community.
Development and deployment methods
This category is in some sense catch-all category where we discuss challenges related to the pretraining, finetuning, evaluation, interpretation and security of LLMs. The common theme of discussion in this category is that research required to address most challenges is ‘developing new methods’ type. In pretraining (section 3.1), two main research directions that are neglected but likely quite impactful are training data attribution methods (‘influence function’ type methods) and trying to modify pretraining methodology in ways that are helpful to alignment and safety. An example is ‘task-blocking’ models where the idea is to make it costly for an adversary to finetune an LLM to elicit some harmful capability. We have an extensive discussion on deficiencies of current finetuning methods as well (section 3.2). Current finetuning methods are problematic from safety POV as they work more to ‘hide’ harmful capabilities as opposed to ‘deleting’ them. We think more research should be done on both the targeted removal of known undesirable capabilities and behaviors, as well as on the removal of unknown undesirable capabilities. The latter in particular seems to be highly neglected in the community right now. We then go on to discuss challenges related to evaluations and interpretability (sections 3.3 and 3.4). We say more about what is relevant here in the following section. The last two sections in this category (sections 3.5 and 3.6) are about challenges related to the security of these problems; while jailbreaking is a pretty popular research area (though it is unclear how useful most of the research that is happening here is), data poisoning is an equally alarming security risk yet seems to be highly neglected. There is some work showing that poisoning models trained on public data is possible, and the sleeper agents paper showed that standard finetuning stuff does not de-poison a poisoned model.
Sociotechnical challenges
Finally, AI Safety community tends to fixate on just the technical aspect of the problem but viewing safety from this narrow prism might prove harmful. Indeed, as we say in the paper “An excessively narrow technical focus is itself a critical challenge to the responsible development and deployment of LLMs.” We start this category by discussing challenges related to identifying the right values to encode in LLMs. Among other things, we discuss that there exist various lotteries that will likely impact what values we encode in LLMs (section 4.1.3). We think this is a relatively less well-appreciated point within AI Safety/Alignment community. We then discuss gaps in our understanding of how current and future LLMs could be used maliciously (section 4.2). There is an emerging viewpoint that RLHF ensures that LLMs no longer pose accidental harm; we push back against this claim and assert that LLMs remain lacking in ‘trustworthiness’ in section 4.3. The last two sections (4.4 and 4.5) respectively discuss challenges related to disruptive socioeconomic impacts of LLMs and governance of LLMs. Section 4.5 on governance should be a good intro for anyone interested in doing more governance work.
I believe some of the enthusiasm in the safety community is coming from a place of background pessimism, see: https://twitter.com/DavidSKrueger/status/1796898838135160856