This post was written by Fabien at SaferAI[1]. Simeon has prompted Fabien in relevant directions and has provided valuable feedback.
Thanks to Jean-Stanislas Denain, Alexandre Variengien, Charbel-Raphael Segerie, and Nicole Nohemi for providing helpful feedback on early experiments and drafts of this post.
In this post
- I describe a method to evaluate that a specific direction encodes information relative to a specific concept,
- I use it to evaluate how good directions found through probing techniques are,
- I present a way of using causal intervention to find directions that maximally encode information relative to a specific concept, which I call Causal Direction Extraction (CDE),
- I present some preliminary results about the directions found through Causal Direction Extraction
One of the main goals of this post is to get suggestions on further experiments to run. I think the current data I gathered is not strong enough to prove or disprove claims like “CDE finds a direction, which mostly captures the concept of gender in GPT-J”, but further experiments could.
The code for all experiments is available here.
[EDIT] I'm less excited about this technique than I was when I wrote this post. This is because of two experiments I ran since. First, CDE works much less on automatically augmented data (take OpenWebText and swap pronouns and names), whereas other methods such as mean difference ablation (see MP and LEACE) still work reasonably well. Second, ablation along the gender direction fails to consistently reduce bias on gender bias benchmarks.
How to Evaluate How Much a Direction Encodes a Concept
What It Means for a Direction to Encode a Concept
Let’s say you have a neural network . Let be the network up to a given layer , and be the network after that, such that for all input , .
The claim that a (normalized) direction in the space of activations [2] encodes a target concept between layers and can be understood as follows:
Activations after layer can be cleanly cut into two pieces:
- , the projection of along , which only encodes information relative to the target concept
- , the projection of orthogonal to , which only encodes all information not related to the target concept
Another way to put it is that there exists a function [3] which only depends on properties of related to the concept and a function [4] which depends on every other characteristic of the input, such that for all input , [5].
Using Activation Patching to Evaluate How Much a Direction Encodes a Concept
With this definition of what it means for a direction to encode a concept, you can use activation patching (introduced by Redwood’s Indirect Object Identification paper, Wang 2022) to quantify how well this hypothesis works. The setup here is simpler than in the original paper, since we patch the activations directly in the residual stream (between two layers instead of at the output of one attention head).
Let’s take the concept of gender, and let’s run the network on the two following sentences: = “but her favorite color is”, = “but his favorite color is”, which only differ by the concept of gender (we’ll discuss this claim later). If the hypothesis is correct, then [6], which means we can patch activations after layer :
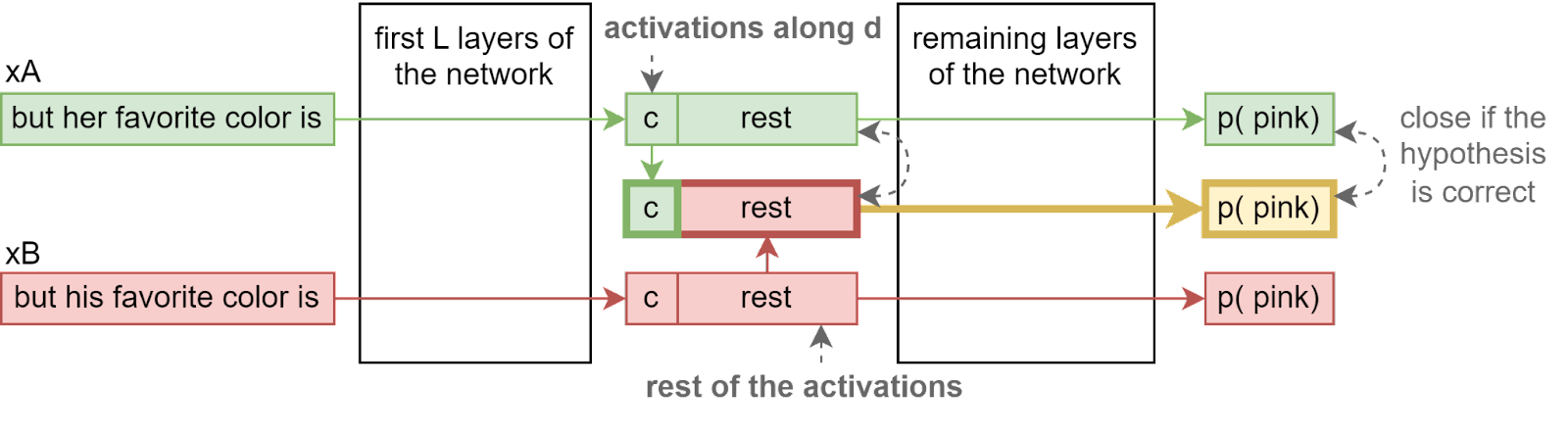
Let’s define . The first argument is the one we should determine the output of the function if the hypothesis is correct, the second argument is a “distraction”.
How much this holds can be quantified in different ways:
- Measure the KL-Divergence between the relevant output and the mixed output
- Measure the probability of a specific token in the mixed output (“pink”[7] for example) and see how much closer it is to the relevant output N(xA) than the irrelevant . More precisely, we can define the success rate as [8]. A success rate of 1 means that the probability of “ pink” in the mixed output is the probability given to pink by the model on the relevant input, and a success rate of 0 means that the probability of “␣pink” in the mixed output is the probability given to pink by the model on the irrelevant input.
Limitation 1: It Only Works for Some Concepts
This method works well for gender, where we can provide many examples of pairs of input where the main difference is the concept and where there is a clear impact on output logits. If there are some other differences between the sentences not captured by the concept, this could lead to a low success rate even when the direction does capture all relevant information, because important information has been lost when replacing with .
Therefore, for concepts for which it is not easy to construct pairs of inputs that only differ by the concept, this method gives a lower bound on how good the direction is.
I try to mitigate this by only claiming that a direction is not encoding the relevant information when it fails on concepts and input pairs, on which I feel it’s reasonable to claim that the only difference is fully expressable through the target concept.
Limitation 2: It Does Not Check if the Direction Only Encodes the Target Concept
A direction would get a success rate of 100% if it captured all information present in the network’s intermediate activation: no penalty is measured if a direction captures more than the target concept. This means that if the model encodes in a single dimension, a concept that is more information-dense than our own, we won’t be able to detect it using this method. This becomes especially problematic when using multiple directions instead of a single one.
I try to mitigate this by measuring the success rate of a direction on unrelated concepts, which can be seen as controls.
Limitation 3: It Provides No Out-of-distribution Guarantees
Just because a direction is able to recover the right information on the tests you have provided doesn’t mean it captures the concept you have in mind. Perhaps the network computes something completely different, which happens to be useful in the test cases you have provided.
When methods used to find a direction require some training data, they might overfit and find a direction that has nothing to do with the concept I have in mind but works well on the test provided. To mitigate this, I measure the success rate of the direction on tests that are far out of distribution from the training data used to find it, but which still fall into what I consider to be the realm of the target concept. For complex concepts, I also check that I can “find the concept” only in the middle layers of the network: if I can find the concept in the first or the last layer output, it probably means that activation patching is swapping tokens around and that the model is not really computing anything close to the target concept I have in mind.
Evaluation of Probing Methods
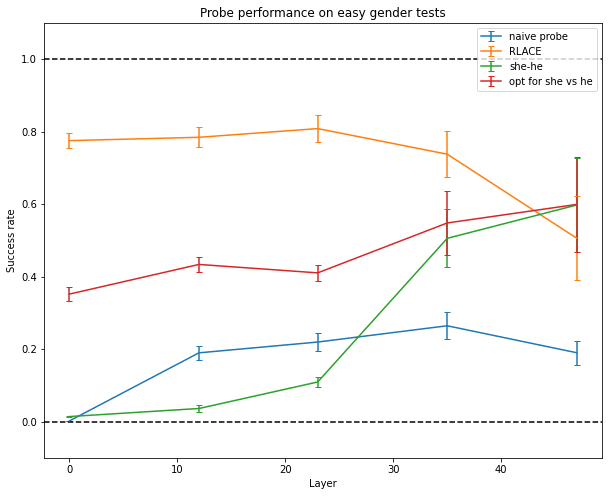
The general idea behind probing is to take the activations of the network after layer L and train a classifier to do a task that requires only the information contained in the target concept. For example, if the concept is gender, you would train a probe to predict if the input is about a woman or a man, using the activations after layer L. A naive hypothesis would be that the direction found by the classifier captures the concept of gender: this is what you would expect from your low-dimensional intuition if there were two clear and linearly separated clusters of inputs, one about women and one about men.
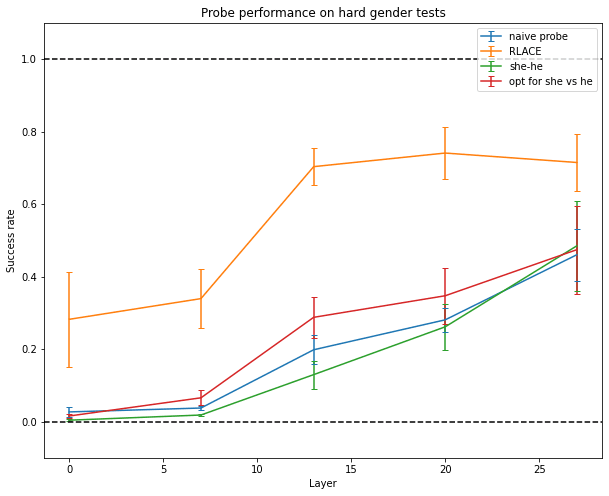
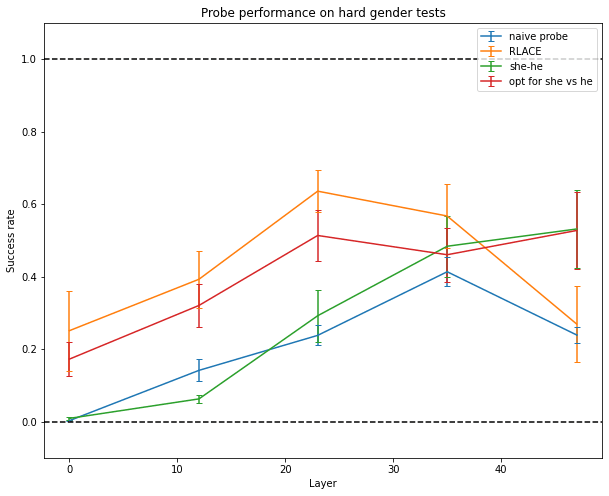
But probing fails at finding a direction in activation space that encodes the information the network actually uses to make predictions about gender, no matter the direction used by the network. It does almost as bad as just using the “she - he” direction in the unembedding matrix (though the latter isn’t good either) or using the direction which makes a small perturbation to your activations maximally output she and not he[9].
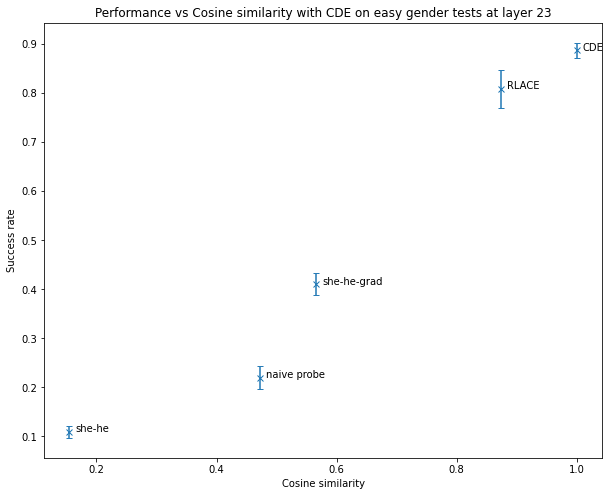
A slightly more advanced method is RLACE (Ravfogel 2022): instead of training a classifier directly, it finds a direction such that projecting orthogonally to this direction makes classifiers unable to linearly separate the two classes of inputs. This seems to work relatively well.
The data used below for training and testing is of the form “She/He took → her/his”. Training and testing data are disjoints[10]. Experiments are done on GPT-J-6B, a 28-layer model with an embedding dimension of 4096. Experiments are done independently on five different layers of the network.
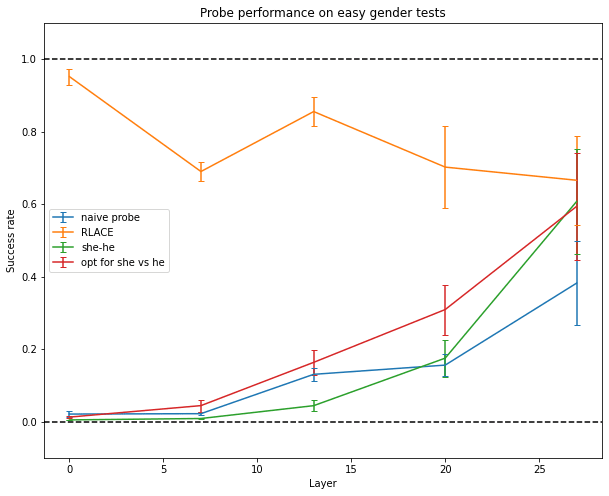
Only RLACE is able to generalize to more difficult data like “Her/His favorite color is → pink/blue” or “Arden loves to dance/fight, but → she/he”.
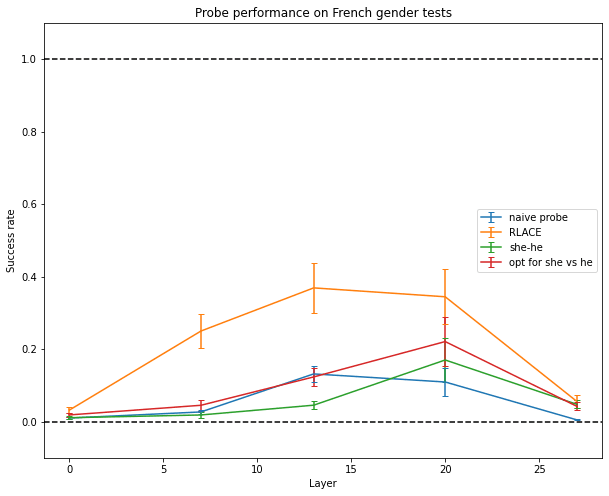
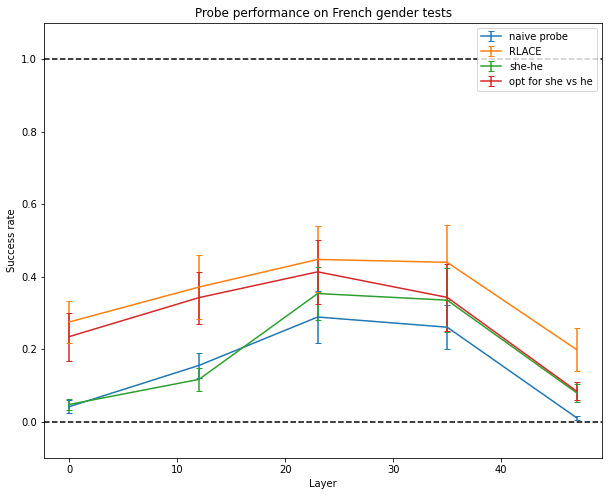
And only RLACE is able to somewhat generalize to sentences in French (it has only been trained on English data).
A Causal-Intervention-Based Method for Finding Directions Encoding a Concept
The Method
The measure of success being differentiable, we can directly use it to find the direction which makes the activation patching successful. Given a set of pairs of sentences which only differ by the target concept, Causal Direction Extraction consists of using gradient descent to find a solution to the following optimization problem:
I used the KL divergence metric instead of looking at individual token, since the former is more information-dense and because it requires less effort to generate the dataset (but using individual tokens works too). I use the symmetrized divergence because I wanted to penalize high-probability tokens being predicted as low probability and low-probability tokens being predicted as high probability, but I don’t have strong opinions about that.
Experimental Results on Gender
In practice, this works well, slightly out-performing RLACE.
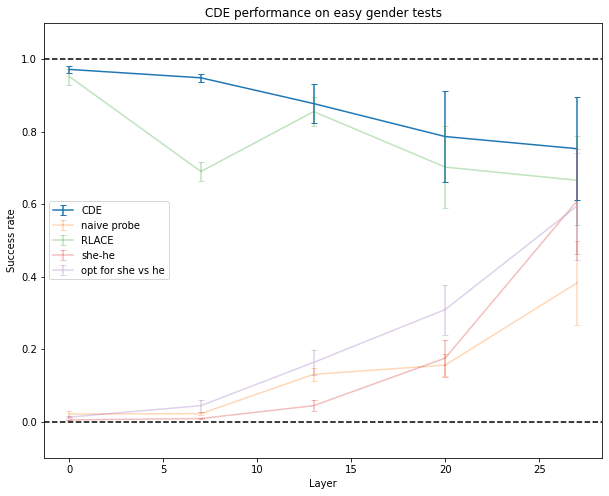
It generalizes pretty well to both harder inputs than the ones it was trained on, and to French inputs. Side effects are shown on other datasets, which are described later.
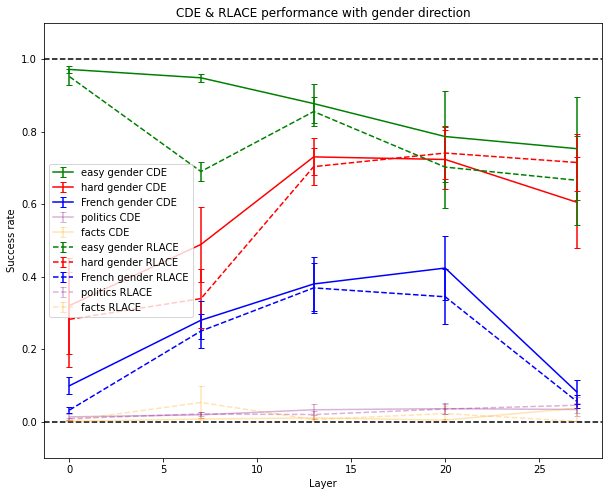
Experimental Results on Other Datasets
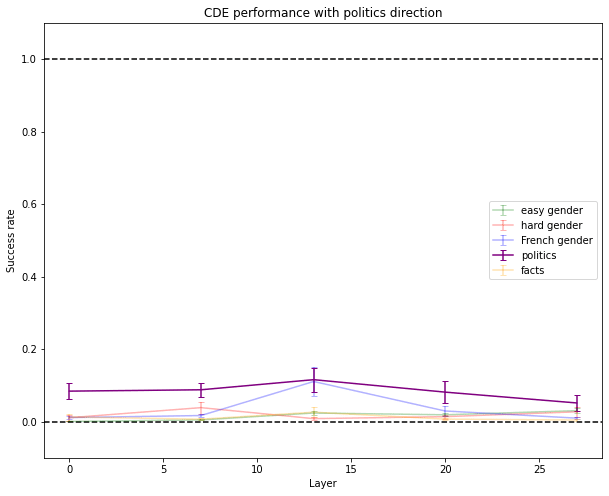
On American political left vs political right, I wrote some training and testing inputs (though I wrote a third as many as for gender). Inputs are of the form “A state which is Republican/Democrat is said to be → red/blue”. This didn’t work well and had some side effects on gender tests. Maybe the training dataset was too small or too noisy. Maybe there isn’t a clear direction that encodes this concept in GPT-J.
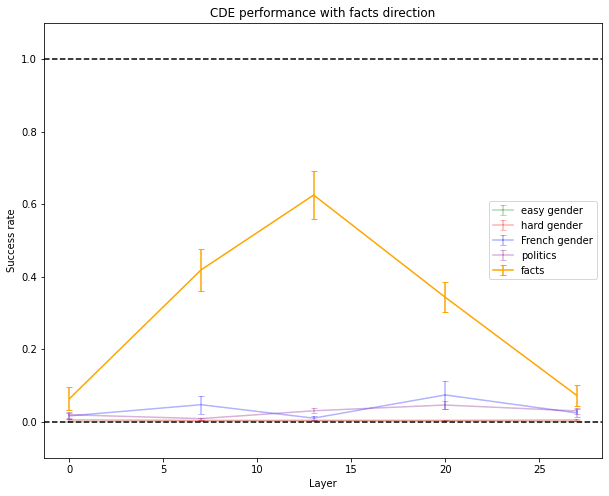
I also generated obvious true and wrong facts like “The capital of France is → Paris/London” using InstructGPT. I then conditioned the model either on 5 obvious facts, asking it to give the last token of a 6th fact, or five wrong facts, asking it to give the last token of a 6th fact. This might capture a concept like “the prompt full of wrong facts”[11]. This somewhat worked and produced only minor side effects. This is already quite good, given the complexity of the concept relative to the size of the model.
Ablating Along Directions Which Work Well According to Activation Patching
This direction was trained to do well at activation patching, which means it’s not very surprising that Causal Direction Extraction outperforms other techniques to find a direction. But it also outperforms them on other kinds of causal interventions, like mean-ablations.
RLACE damaged unrelated concepts slightly more than CDE when using mean-ablation: at layer 7, when using the gender direction, the success rate is a little higher on politics and facts with RLACE than with CDE, which means that the direction found by RLACE affected more the neural network on unrelated concepts.
Here, I projected the activation after layer L orthogonally to the direction[12] found using the different techniques described above. The resulting network is called . Success here is .
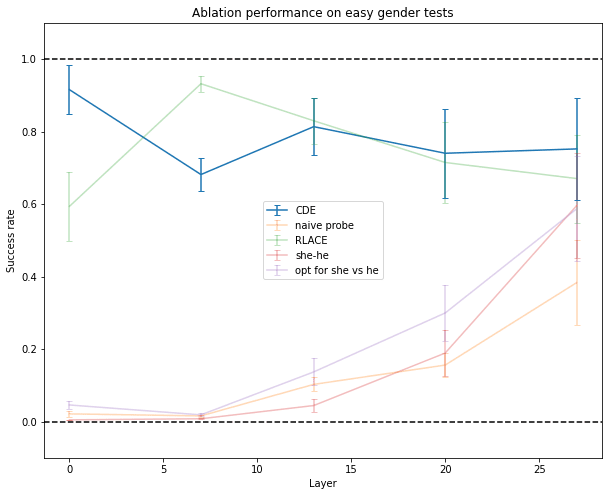
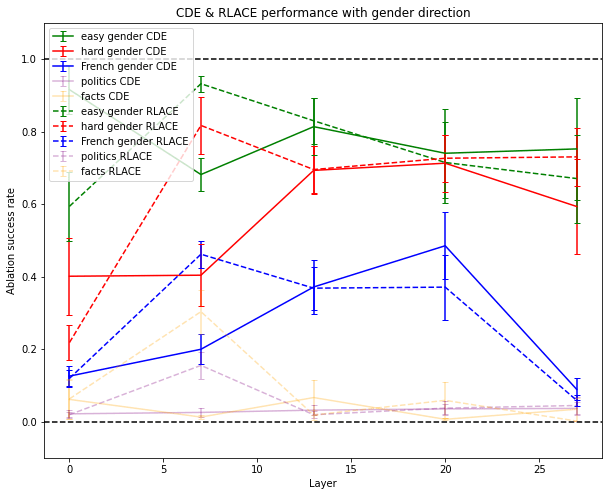
The Method Scales with Model Size
I ran the experiments on GPT-2, a 48-layer model with an embedding dimension of 1600 (a third of the embedding dimension of GPT-J) and 4 times fewer parameters.
For simple concepts like gender, the results are about the same as for GPT-J.
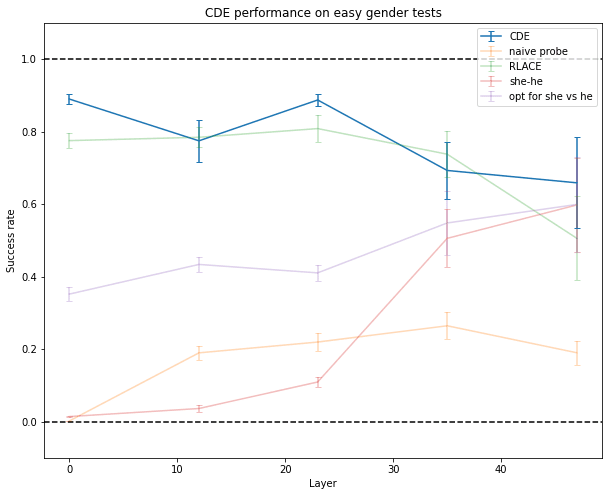
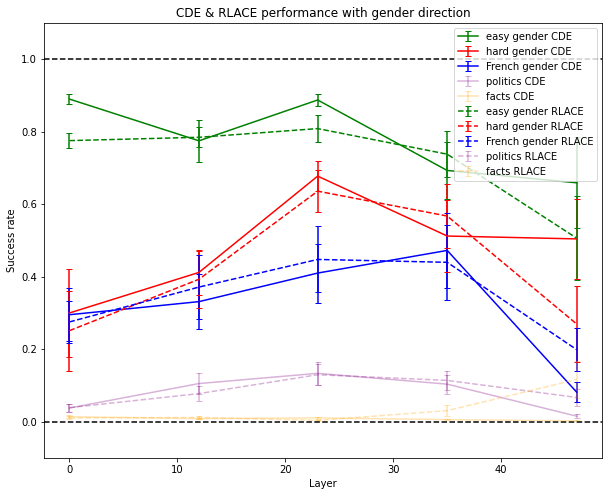
But for more complex concepts, like spotting that the facts which follow are false, CDE doesn’t work as well as on the larger GPT-J model.
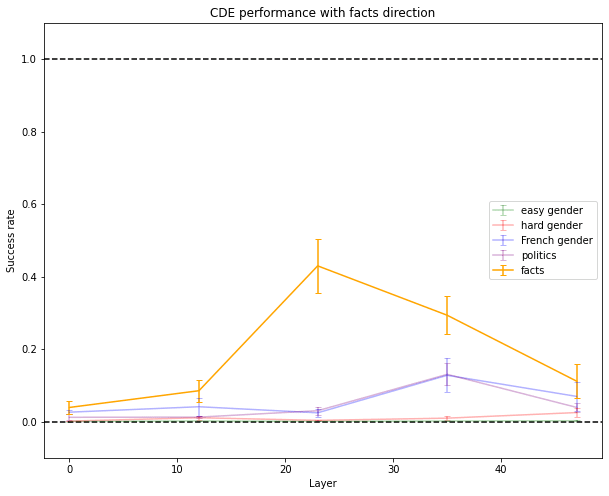
This seems to indicate that CDE captures concepts that can be easily deduced from the model and doesn’t just “make up” concepts. The fact that it doesn’t find concepts in early or late layers also provides evidence in this direction. This might also give us hope that for much larger models, which probably have crisper concepts than smaller ones, this method might be able to recover crisp complex concepts humans have because larger models might have a single direction dedicated to the concept or a superset of the concept (this method can’t help us find concepts more powerful than the ones we can think of).
Some Other Properties of the Directions
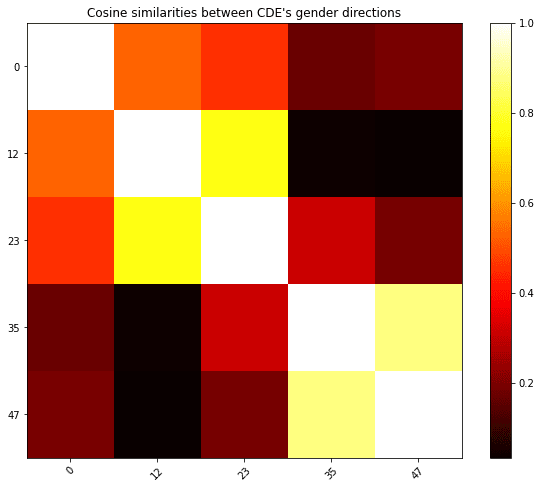
The directions found by the different methods can have small cosine similarities between different layers: the “gender direction” seems to evolve continuously over the network.
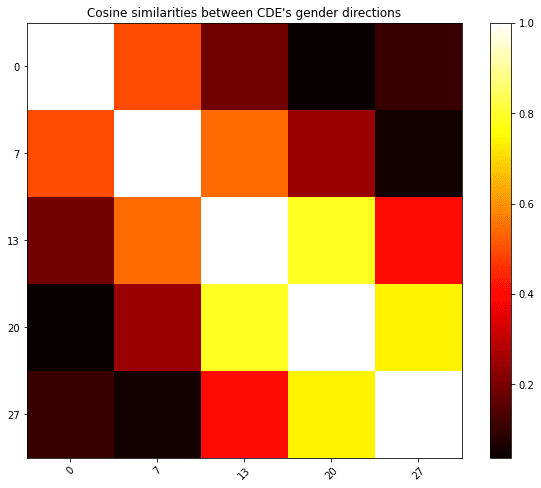
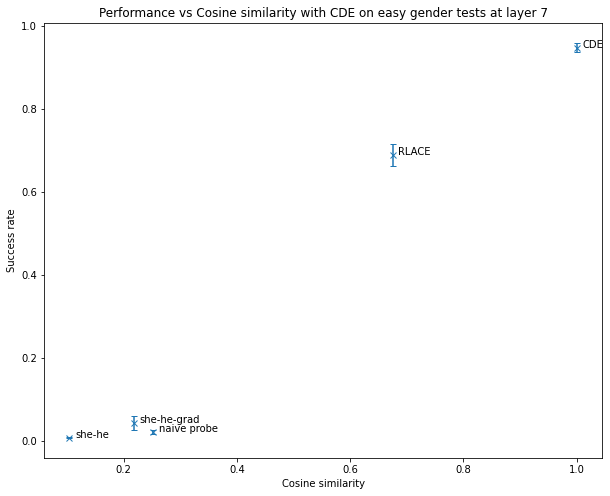
On gender after layer 7 (where CDE), how good a method is seems to be well correlated with the cosine similarity to the direction found by CDE. This gives weak evidence that there is only one “good answer” to the question of finding a direction that encodes the relevant information and that, in some situations, CDE finds it.
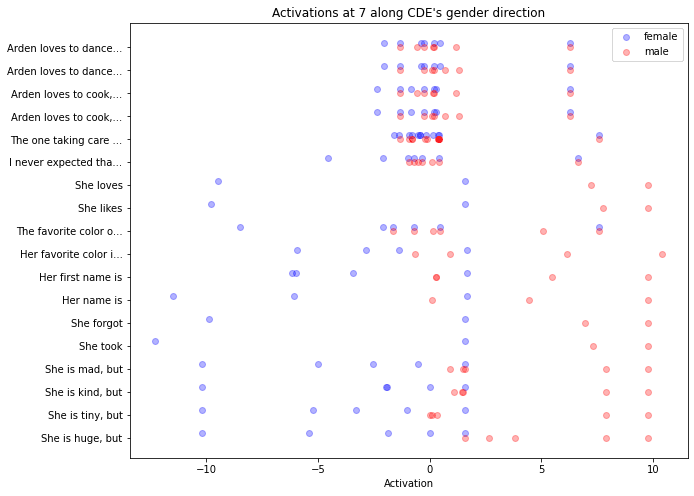
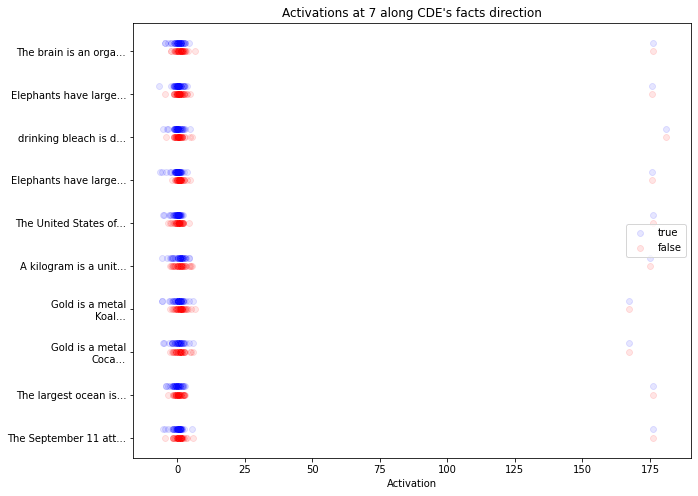
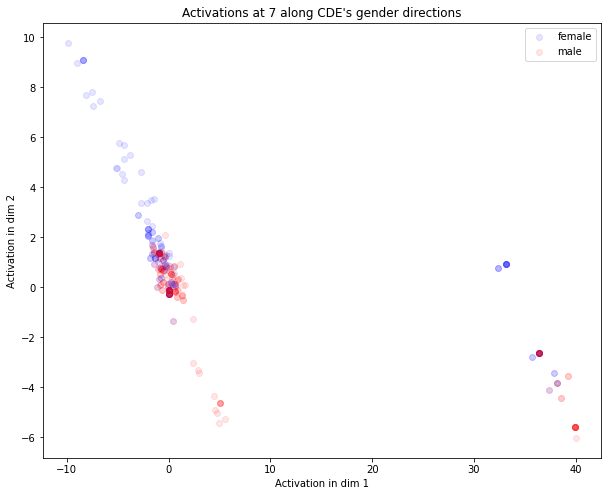
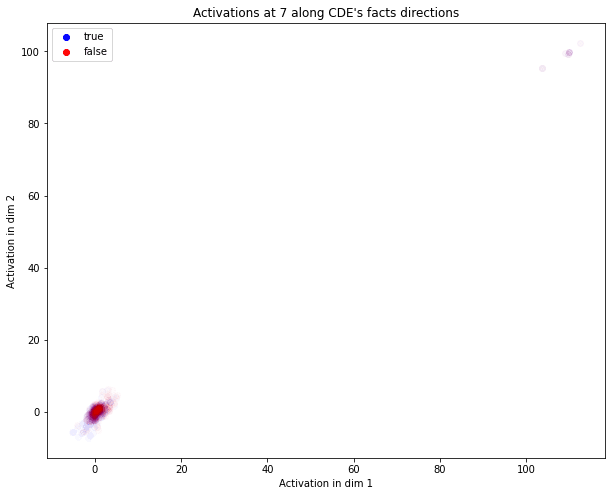
The activations of each gender test sentence at each layer are shown below. We can observe two things:
- The information isn’t encoded linearly along the direction
- They don’t show an easily interpretable pattern. However, we can find multiple clusters in the tests on gender, which might explain why the probe struggles to find the relevant direction. This is more visible in the 2D case (see appendix) in the case of gender, in which we can see two clusters both linearly separable. This somewhat supports the polytopes view, which emphasizes that the network acts linearly only inside clusters of points.
Cost of the method: in the current state of my unoptimized codebase, it takes about 15 minutes for CDE to converge on one A100. RLACE usually takes a few hours (using the author’s implementation).
Preliminary Interpretation of the Results
Direct Observations
From the results above, we can draw the following conclusion:
- Naive probing fails to find directions causally responsible for the output of the network
- For some concepts, at some layers, the information encoded in a concept is mostly stored along a single direction
Potential Implications on Logit Lens
The fact that activation patching or ablation along the she-he direction works on simple gender tests at the last layer of the network, but fails in the middle of the network seems to show that the Logit Lens hypothesis holds much less on larger models: the model isn’t simply refining the hypothesis “the output is she” using a constant direction. Instead, more action is happening in directions orthogonal to the she-he direction. Refining this idea could lead to better lenses.
Complex Concepts Might Be Encoded in the Middle Layers of LLMs
I think that abstract concepts are often stored in a few directions in the middle layers of the network: the direction of gender found in the middle of GPT-J generalizes well to French sentences, and the direction of fact vs lie is able to generalize to unseen examples only when it is taken in the middle of the network. This means that the direction I found is not simply swapping tokens around. But I haven’t tried enough concepts to make general statements about how LLMs encode abstract concepts in general.
I haven’t provided strong evidence that the network computes the concept I have in mind when I build the dataset. The fact that the direction found for gender generalizes to another language and to tests harder than the one used in training is some evidence that it does in the case of gender, but further experiments are needed.
I believe this might help to guide some future work on mechanistic interpretability and might lead to some gray-box interpretability techniques to monitor and edit LLMs. This definitely doesn’t solve ELK (it was never the aim of this work).
Further Work
I would be happy to have suggestions about further experiments which might confirm or disprove the speculations above.
I am also excited about the implications this work could have on general questions about LLM interpretability. For example, I’m unsure if these results push toward “directions are the fundamental building blocks of neural networks reasoning” or towards its opposite, and I would be happy to know if some experiments might use the setup I described to give provide some evidence for or against this statement.
Finally, I’m open to ideas to generalize this work. I’ve tried and failed to generalize Causal Direction Extraction to concepts that are harder to describe in terms of pairs of almost identical inputs (see appendix for a description of my attempt), but I believe there are ways to extend this work to a larger class of concepts.
Appendix
Results for 2 Directions
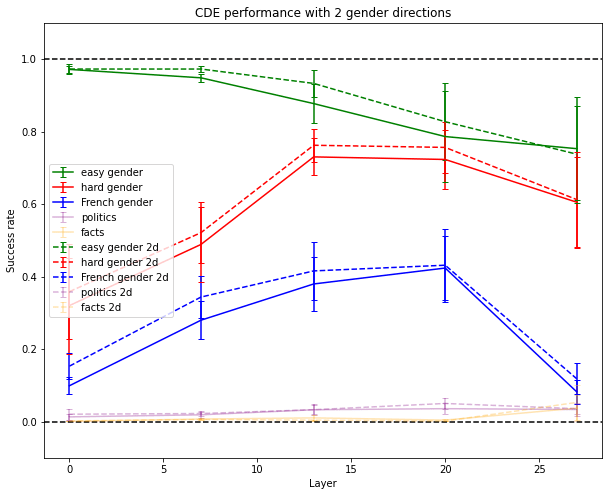
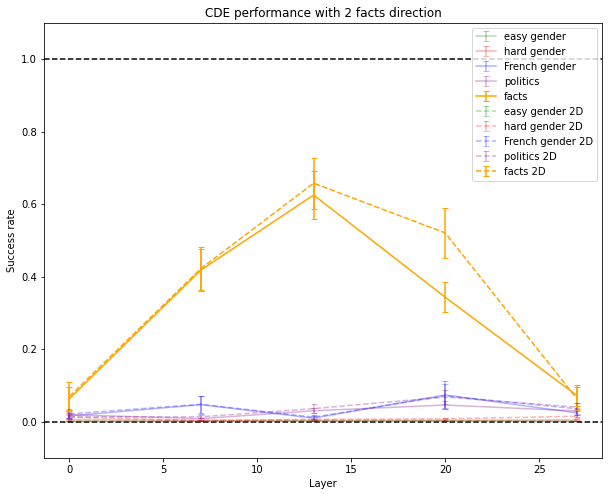
All the methods described here can be adapted to work with as many dimensions as you wish. Here are some results with two dimensions:
CDE Performance
Activations
My Unsuccessful Attempt at Generalizing This Method
Here is a different, more general setup to define a concept: let’s take a set of multiple-choice questions, which all require the use of a target concept to be answered well. The direction corresponding to this concept at layer L might be the direction that makes the model suck the most at answering the questions correctly while keeping the distribution of answers intact on some control text randomly drawn from a filtered part of OpenWebText, which doesn’t use the target concept. This seems like it could capture many more concepts than the approach described in this post.
Because small models are bad at answering multiple choice questions, and because I already have something close to a “ground truth” on gender, I used starts of sentences using female protagonists as “questions”, and the final token as “answer”. For example, after “She forgot”, the model attributes high probability to “her” and low probability to “his”, and ablation should close this gap.
Using the loss L = average log probs on correct answers - average log probs on incorrect answers + symmetrized KL divergence on unrelated text, the direction I never got close to the direction found by CDE and was always got outperformed by the direction found by CDE at successfully closing the gap after ablation on unseen sentences. All experiments were done on gpt2-xl.
I think the main weaknesses of this setup is the low volume of information provided by the loss, and the incentives for the process to find a direction that makes some of the correct answers really low-probability, and makes some of the incorrect answers really high-probability. Given that CDE already provides valuable information, I decided to focus on CDE’s results for now.
Please keep me informed if you try variations of this setup!
More Results on Gpt-2
Here are the results of more experiments, run on GPT-2. Most observations on GPT-J hold with GPT-2, but naive probing works better and using the direction of the gradient, which pushes towards she vs he, works almost as well as RLACE (though it doesn’t generalize as well).
- ^
SaferAI is a young organization that aims at auditing the most generally capable models, e.g. large language models.
- ^
In the case of a language model, we chose a single direction with as many coordinates as vectors in the embedding space and use it on every sequence position.
- ^
is the set of vectors obtained by scaling d, it’s
- ^
is the set of vectors orthogonal to d, it’s
- ^
These two definitions are not strictly equivalent because might not use some of the information present in the activation, which makes the second definition weaker than the first one. The second definition is the one that CDE relies on: CDE doesn’t care about information stored in activations if the network doesn’t use it.
- ^
Or the network doesn’t use differences in and , which is the only thing CDE aims to measure.
- ^
The token is "␣pink" with a space in front of the word.
- ^
I used log probabilities: should be a 50% success rate if the best case is and the default case if .
- ^
This is similar to what the Rome paper does for finding the “Paris” direction. Success is always clipped to remain between zero and one.
- ^
Activations at each position are treated as distinct training data for probes. I wrote 5 training patterns with many ways of filling them in and 11 testing patterns of varying levels of difficulty. You can find the full data I used here.
- ^
Though it might have captured a pattern in the token corresponding to wrong facts.
- ^
The projection is a median-ablation: after projection along direction , was added, where is the median of