Thanks!
Any thoughts on how this line of research might lead to "positive" alignment properties? (i.e. Getting models to be better at doing good things in situations where what's good is hard to learn / figure out, in contrast to a "negative" property of avoiding doing bad things, particularly in cases clear enough we could build a classifier for them.)
Overview: By training neural networks with selective modularity, gradient routing enables new approaches to core problems in AI safety. This agenda identifies related research directions that might enable safer development of transformative AI.
Introduction
Soon, the world may see rapid increases in AI capabilities resulting from AI research automation, and no one knows how to ensure this happens safely (Soares, 2016; Aschenbrenner, 2023; Anwar et al., 2024; Greenblatt, 2025). The current ML paradigm may not be well-suited to this task, as it produces inscrutable, generalist models without guarantees on their out-of-distribution performance. These models may reflect unintentional quirks of their training objectives (Pan et al., 2022; Skalse et al., 2022; Krakovna et al., 2020).
Gradient routing (Cloud et al., 2024) is a general training method intended to meet the need for economically-competitive training methods for producing safe AI systems. The main idea of gradient routing is to configure which parameters in a neural network update on which tasks. The assignment of tasks to parameters allows the ML practitioner to supervise the internal structure of models. We hope that this supervision can be leveraged to obtain robust, practical safety assurances. The original gradient routing paper presents preliminary empirical evidence for the following benefits:
The results from the original paper are summarized here.
However, key questions remain. These questions include:
These questions motivate our research agenda, which has four pillars:
Optimistically, we hope that progress on this agenda will unlock a new ML paradigm. This new paradigm would leverage the power of black-box function approximation by neural networks while imposing selective structure related to safety-critical properties. This structure would grant empirically verifiable assurances about model behavior. We imagine generalist AIs with selective incapacities, like lack of knowledge of humans or situational unawareness; we imagine versions of models with varying dispositions or capabilities deployed under access control; we imagine using proxy labels to influence training without falling prey to specification gaming.
The research agenda may fail to live up to these hopes. Supervision of neural network internals is cruder than behavioral training. It may be the case that the kinds of structure which induce meaningful safety properties are prohibitively costly (as measured in a model’s ability to fit the training data), or that the kinds of properties we can induce turn out to be unhelpful for ensuring AI safety.
We view the agenda favorably because it plausibly addresses fundamental problems in AI safety and its core uncertainties are resolvable today. We also suspect that progress on the agenda will generate useful insights (like absorption), even if gradient routing fails to be directly useful.
Directions we think are most promising
The research directions we think are most important belong to two themes:
Depending on the promise of selective modularity, understanding the implications for AI safety (pillar 4) may be important. It may be worth developing a theory of change, including safety cases, to inform both policy and further technical research. However, we are hesitant to recommend significant investment in these more speculative directions prior to de-risking gradient routing methods themselves.
Recurring ideas
A few ideas show up repeatedly in the agenda. It may be helpful to keep these ideas in mind as you read.
Mechanistic supervision (as opposed to behavioral supervision) - the use of labeled data to influence a model’s internals during training, without changing the training loss (i.e. the behavioral objective).[1]
Example: all the applications from the original gradient routing paper. Most notably, the reinforcement learning experiments, where learning updates for different terminal states were localized to different network modules, without changing the loss function itself.
Relevance: mechanistic supervision might enable reliable generalization from weak labels by manually configuring model internals without changing the training objective.
Gradient routing methods and applications
Improvements to basic gradient routing methodology
We suspect that the gradient routing methodology from the original paper can be improved considerably.
Existing improvements
For language model unlearning, we’ve already identified two improvements. The first is to apply parameter-level routing instead of activation-level routing. The distinction is illustrated in the figure below in the context of an MLP module with a residual connection. Activation-level routing is a much stronger intervention, because it means that earlier parameters in the network will be updated in a way that is agnostic to their effects on the output as mediated by the MLP. On the other hand, parameter-level routing merely restricts which parameters update, without changing the updates of other parameters. The result is that we can apply gradient routing to a larger number of layers, while damaging performance less.
The second improvement is to occasionally train the ablated version of the model during pretraining, to enforce that the ablated model makes reasonable predictions on the retain data. Unsurprisingly, this leads to a lessened increase in retain loss at the final ablation step. If data are imperfectly labeled, this step must be applied with care in order to prevent the ablated model from learning harmful capabilities.
Choosing what to route where
At what level of granularity should we decide what data to route? For example, for some language modeling application, is it best to route individual tokens, parts of sequences, or entire sequences? Since gradient routes are continuously parametrized, we have a lot of control over how we adjust updates for different parts of the network based on different data. For example, in our TinyStories unlearning experiments, we defined routes as convex combinations of two masks, with weights based on frequencies of individual tokens in the forget and retain sets.
Where should data be routed to achieve our aims? Empirically, we’ve achieved unlearning simply by masking certain dimensions inside MLPs (then ablating). Does it make more sense to instead route to LoRA adapters or individual attention heads, or even to route based on the attention pattern[2]? One might compare vertical routing (applied to different neurons at a given layer) vs. horizontal routing (applied to the outputs of a module which get summed with outputs from another module). Mechanistic interpretability may provide insights, e.g. Geva et al. 2022, Meng et al. 2022.
Abstract and contextual localization
In the original gradient routing experiments with language models, routing was applied on a token-by-token basis, without regard for surrounding context. This approach was sufficient to robustly unlearn broader capabilities (predicting academic articles on virology). However, the approach is inherently limited: tokens derive their meaning from surrounding context, and some concepts that we would like to localize are too abstract to be tied to specific tokens. We’d like to be able to apply gradient routing at the semantic level, localizing abstract concepts such as honesty or reasoning capabilities. Doing so would enable more useful interventions and interpretability insights compared to token-level routing.
Concept localization might be achieved in a variety of ways: for example, by using a classifier for the presence of a concept, with the classifier’s predicted probability determining the amount of routing that is applied to each token. Alternatively, routing could be applied based on predictions of linear probe trained on a model’s internals, features of a sparse autoencoder, or based on LLM-authored labels. However, it’s not clear how this should be made to work. Learning updates on sequences that reflect abstract concepts may be rich with other information that we want the model to learn.
Open questions:
A related project would be to apply semantic segmentation to images, then route the unreduced pixel-level loss terms based on their estimated meaning. (This would be an instance of split loss gradient routing.)
Gating
Gating, as used in MoE models, combines naturally with gradient routing. The outputs of a specialized submodule can be modulated by a gate. By intervening on the value of the gate, the behavior of the model can be steered. This was demonstrated in section 4.3 of the original paper.
The primary motivation for using gated submodules with gradient routing is to lessen the performance reduction caused by interventions applied after training (e.g. ablation). This can be understood as reducing internal covariate shift: ablating a non-gated submodule might shift a model’s internal activations, degrading performance significantly. Alternatively, intervening to set a gated submodule’s gate to zero might also cause internal distribution shift, but we would generally expect a smaller change in performance (because the gate was sometimes close to zero during training).
Successful gating strategies require care to implement, as gating can trade off against absorption. Consider the case of localizing capabilities related to predicting harmful data to a particular “harmful module.” If the gate for the harmful module is set to zero when the model trains on harmful data, then the harmful module does not participate in the forward pass for that data. If the harmful module does not participate in the forward pass, then it does not affect the learning of the rest of the model; the rest of the model will update to improve prediction accuracy on the harmful data. This failure-to-absorb is why alternative modularity methods fail at semi-supervised unlearning, as depicted in figure 5 in the original paper and discussed at the beginning of section 5.
Improved regularization
In the original paper, we found that using a L1 penalty on the activations induced specialization in the model’s representations; unfortunately, an L1 penalty may increase the model’s final loss. We’re interested in alternative ways to induce specialization. For example, covariance-based losses (like the ones used in VJ-VCR) could provide a way to cause different parts of the activation space to specialize to different tasks.
Incorporating existing ideas
Finally, we suspect that ideas from existing methods will provide further improvements. Relevant examples include particular methods for parameter efficient finetuning (Houlsby et al., 2019, Hu et al., 2021), continual learning (Mallya et al., 2017, Mallya et al., 2018, Wang et al., 2023, Chen et al. 2023), mixture of experts (Park et al., 2024), inductive biases (Zhang et al., 2023), and representation-learning methods (Makhzani et al., 2016, Kingma et al., 2014, Higgins et al., 2017, Higgins et al., 2017, Edwards & Storkey 2016).
Gradient routing beyond pretraining
Gradient routing will be easier to experiment with and will be more likely to be adopted if it can be applied during distillation or finetuning rather than pretraining. The challenge to doing so is that gradient routing requires that a concept is labeled as it is learned. For logit distillation, it is unclear how data should be labeled. (For example, in the unlearning setting, one logit could convey “forget” information while another could be benign; we wouldn’t want to route the update for both of them to the same subnetwork.) For finetuning, the challenge is that the structure of a model’s internals are largely determined, so there is less opportunity to influence them. Nevertheless, there may be safety-relevant ways to localize learning updates on novel tasks in the finetuning setting — for example, by localizing further learning updates to an auxiliary submodule.
One idea for applying gradient routing during distillation is split-loss gradient routing. Split loss gradient routing is gradient routing applied based on entries in an unreduced loss tensor. For example, in a Transformer language model, the unreduced loss tensor would be indexed by batch, sequence position, and vocabulary index. These components are summed to obtain the training loss. Split-loss gradient routing partitions the tensor into components to route to different network subregions. By routing different loss components to different subregions, these loss components can be “attributed” to different parts of the network, enabling the application of gradient routing even when data points aren’t easily attributable themselves (as in the case of distilling on a vector of logits). A drawback is that split-loss gradient routing requires separate backward passes for each part in the partition.
Another approach to distillation would be to steer a language model toward a particular behavior by prompting or finetuning. The steered and unsteered versions of the model would then be used to produce training labels (as logits or token outputs), with gradient routing applied to localize the steered labels to a network subregion. The desired effect would be to localize the steered disposition.[3]
Applications
Semi-supervised reinforcement learning
Can gradient routing enable weak supervision more generally, or does section 4.3 of Cloud et al. 2024 present a special case? Here, we propose one way to generalize the problem setting and gradient routing solution. The hope is a formalism that is sufficiently expressive as to capture real-world challenges to scalable oversight, while still admitting a gradient routing solution.
Assume a reinforcement learning (RL) problem with the following properties:
In this setting, the preferred behavior of the agent cannot be specified by any reward function.
The method is to apply gradient routing to terms of the reward function, localizing different updates to different network subregions. Using standard RL notation from Sutton & Barto, 2018, we can sketch: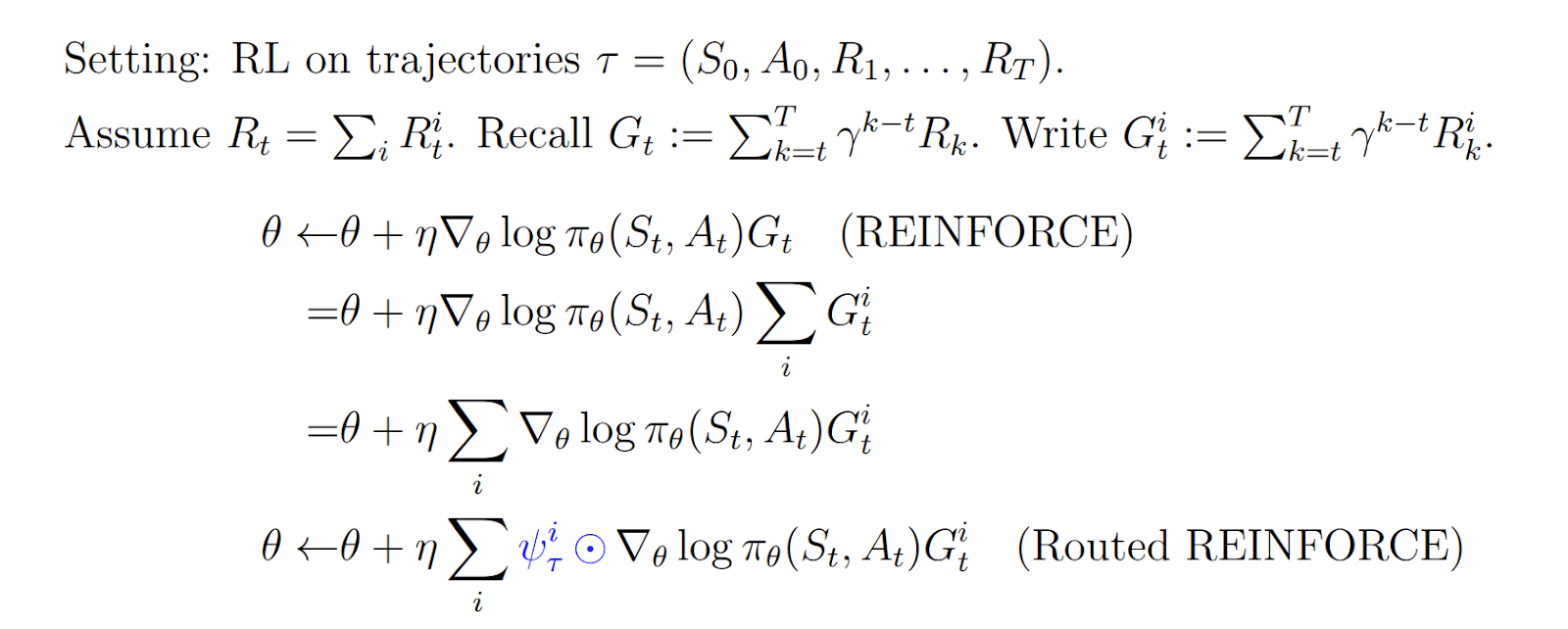
Here, ψiτ is a mask determining the parameters that are updated by rewards of type i. The idea is to localize different motivations in a policy network, so that they can be intervened on to steer the agent.
A concrete project would be to prevent misalignment in language models. For example, one could train a model to reward hack, but localize that reward hacking to a subregion of the network, then ablate that subregion. If the model had learned a general reward hacking tendency there, it might also not reward hack in settings where we did not train it to do so (but it would do so anyways).[4] Localization of sycophancy or dishonesty could also be investigated.
Semi-supervised robust unlearning
Cloud et al. 2024 showed that gradient routing can enable robust unlearning via ablation even when trained on partially labeled data. However, the method presented in the paper caused a significant increase in forget loss and was only compared against a small number of unlearning methods in an artificial setting (TinyStories). The method should be improved and compared to a variety of methods in more realistic problems. Ideally, we prefer a method for which all non-ablated parameters in the model are never updated on forget data.
We note that we are not the first to consider semi-supervised unlearning, as it is also considered in, e.g., Schoepf et al., 2024. However, rather than removing backdoors, our interest is in removing broader capabilities. Doing so may require addressing entanglement that limits the effectiveness of data filtering.
Ambitiously, we would create “specialist AGIs,” for example, a conversant physics research assistant that is ignorant of safety-relevant topics like human society, cybersecurity, or its own implementation or situation. To achieve this outcome, a model could be pretrained on a broad corpus (like all of the internet) with gradient routing applied to load-bearing concepts relating to the safety-relevant topics. After training, the model could be modified to remove knowledge of the topics. This might be called learning without remembering.
We hypothesize that gradient routing is important to this story because absorption enables the localization (and robust removal of) highly entangled concepts that are broadly represented in the training data in a way that would be difficult to label explicitly. For example, information about human society permeates the training data in myriad subtle ways. It’s not clear that the influence of this information could be removed without eliminating prohibitively large swaths of the training data. However, by applying gradient routing to localize (and later remove) a few load-bearing concepts related to humanity, we might seriously limit the model’s ability to reason about humans, while still leveraging most of the training data.
Interpretability
Mechanistic interpretability seeks to reverse engineer, or otherwise understand, the entirety of a neural network’s operations, but is far from achieving this lofty goal. However, not all operations are created equal. If we could understand the mechanisms underlying just a targeted set of safety-critical properties, such as honesty, self-awareness, or power-seeking behavior, this understanding might be sufficient to get meaningful safety guarantees. Gradient routing could enable this by localizing certain behaviors to smaller regions of a model, thus making the space for interpretability to search over much smaller. Additionally, since gradient routing does not include loss-based supervision, we don’t have to worry about the model Goodharting our supervision, which could happen under conventional training.
Possible projects:
Conceptual work on gradient routing
The science of absorption
From the gradient routing paper: “Routing a subset of the data related to some knowledge or capability appears to localize that knowledge or capability more generally… To explain these observations, we posit absorption: (i) routing limited data to a region creates units of computation or features that are relevant to a broader task; (ii) these units then participate in the model’s predictions on related, non-routed data, reducing prediction errors on these data, so that (iii) the features are not learned elsewhere. Absorption may also amplify the features causing it.”
Absorption means that gradient routing can induce selective modularity even when data is imperfectly labeled. Absorption enables semi-supervised learning, which is critical for the development of AI systems that dwarf human capacity for supervision.
The dynamics of absorption are not well understood. Research questions include:
For an example of absorption based on curated features introduced at the beginning of a training run, see Instilling Inductive Biases with Subnetworks (Zhang et al., 2024).
Modeling the effects of combined estimands
Routing tasks to distinct network subregions can be understood as statistical inference where multiple estimators (one per subregion) are used to estimate multiple estimands (one per task). These estimators are dependent, and may compete in the sense that their dependencies make the training process unlikely to achieve low loss on multiple objectives. The estimators may also cooperate, in the sense that similar parameterizations are amenable to good performance on multiple objectives. Specifically, if![]() fθ:X→Y, and ψ1,...,ψm∈[0,1]θ are masks determining which parameters update on which losses L1,...,Lm
fθ:X→Y, and ψ1,...,ψm∈[0,1]θ are masks determining which parameters update on which losses L1,...,Lm![]() , we have the update rule
, we have the update rule
θ←θ−ηm∑i=1ψi⊙∇Li(fθ),where![]() Li(fθ) might be an empirical estimate over data, such as ∑d(fθ(xj),yj), and η>0
Li(fθ) might be an empirical estimate over data, such as ∑d(fθ(xj),yj), and η>0![]() is a learning rate. Then we ask: What are the dynamics of this update rule, particularly in terms of the interactions between the different loss terms? Are there stable equilibria? A unique equilibrium?
is a learning rate. Then we ask: What are the dynamics of this update rule, particularly in terms of the interactions between the different loss terms? Are there stable equilibria? A unique equilibrium?
Influencing generalization
A core challenge to AI safety is that we don’t know how neural nets generalize their supervision: there are many possible “interpretations” (as in, training-loss-reducing changes in behavior) consistent with a given training example. A natural way to control how neural nets generalize is to control what parameters update on a given task. Here are three ways this could be done:
For similar ideas that aren’t gradient routing, see Orthogonal Gradient Descent for Continual Learning (Farajtabar et al., 2019) and Instilling Inductive Biases with Subnetworks (Zhang et al., 2023).
Identifying sufficient conditions for scalable oversight
One way to understand the problem of scalable oversight is in terms of information asymmetry. Powerful AI systems will understand aspects of the world and a given problem instance better than (time-constrained) human overseers, while human overseers may have access to auxiliary information that the AI does not have. Recent work has dealt with this setting (Lang et al. 2024, Garber et al. 2024, Emmons et al. 2024, Siththaranjan et al. 2023).
The idea is to formalize a general version of the problem setting in the gradient routing paper: an environment where an agent and an overseer have overlapping but possibly different knowledge, and the overseer must supply a reward function (or other specification), along with some training procedure, to induce desirable behavior. The hope is to identify sufficient conditions under which an overseer can hope to supply adequate feedback; for example, by blinding the agent to particular information, enforcing invariance with respect to some aspect of the environment, or by exploiting structure in a policy network. By inducing selective modularity without modifying the loss, gradient routing may provide practical algorithms that exploit such conditions.
Related conceptual work
Understanding entanglement
From the paper: “...[C]apabilities [may be] entangled, in the sense that there are connections or dependencies between the computation learned to perform different tasks (Arora & Goyal, 2023; de Chiusole & Stefanutti, 2013). Entanglement might occur because certain capabilities or behaviors are reinforced by a broad range of training objectives (Omohundro, 2008; Turner et al., 2021; Krakovna et al., 2020). More simply, capabilities required to perform undesired tasks may overlap with those required to perform desired tasks.”
The safety case for gradient routing relies on the possibility of separating distinct subcomponents of networks that are designated for particular kinds of computation. When should we expect this to be possible? Are there deep challenges or limitations in principle? What about in practice?
A motivating example for understanding entangled capabilities is training capable language models that are robustly incapable of assisting with the creation of bioweapons. This is depicted in the figure below, in terms of virology unlearning while maintaining performance on biology tasks.
Possible topics:
A goal of this work would be to challenge common-sense assumptions about trade-offs. Perhaps it is possible to create performant models that are robustly limited in their ability to perform related, narrow tasks. This accords with our intuitions about human expertise, which can be surprisingly domain-specific (e.g. the pure mathematician that struggles to learn Python, or the athlete that is great at one sport but mediocre at another).
Finetunability as a proxy for generalization
If a neural network can be trained to manifest harmful capabilities with little data, does that mean that harmful capabilities were latent in the original model? Studies of robust unlearning (Lynch et al., 2024) and goal misgeneralization (Shah et al., 2022) implicitly assume “yes.” These studies use finetuned model performance on a task to estimate the presence of a capability in the original model.
An objection to this approach is that finetuning, even on a small amount of data, might confer new capabilities or modify the expression of existing capabilities in a way that would not have occurred under mere shifts in the input distribution. If so, then using finetunability as a proxy for generalization might overestimate the presence of capabilities. As a consequence, safety measures based on detecting the presence of harmful capabilities might be prohibitively conservative.
Abstractly, we care about how model behavior can change under shifts in input space, and our strategy is to approximate (or bound) these changes using shifts in parameter space. Put formally: consider a model as a mapping from input space X and parameter space Θ to output space Y, given by f:X×Θ→Y. Let Xtrain⊂X be the set of inputs that we can evaluate, B⊂Y be the set of misaligned outputs, and θ∈Θ be a learned parameter.[5] The concern about latent, dangerous capabilities is that even if f(x;θ)∉B for all x∈Xtrain, there may exist some x′∈X∖Xtrain such that f(x′;θ)∈B. The question is: is the existence of a dangerous input x′ reliably discoverable via a perturbation of the parameter θ? In other words, does f(x′;θ)∈B imply that there exists x0∈Xtrain and θ′∈Θ such that f(x0;θ′)∈B and d(θ,θ′) is small, for some suitable notion of distance d?
If this is true, then failure to produce a "bad" (x0,θ′) pair would verify that our model is incapable of producing bad outputs beyond the training distribution.[6]
Research directions include:
Understanding when to expose limited supervision to the model via the behavioral objective
When training a model with limited oversight, detected bad behavior can be handled in two ways:
For example, a teacher with limited ability to detect cheating faces a tradeoff between intervening to stop detected cheaters during midterms (option 1), or waiting until the final exam to implement anti-cheating measures (option 2).
If incremental increases in bad behavior achieve better performance according to the training objective and bad behavior can be made incrementally less detectable, then option 1 creates a gradient toward undetectable bad behavior (Baker et al. 2025). Option 2 does not create this gradient; as a consequence, option 2 may be able to prevent, or at least robustly identify, badly behaving models. There is a tradeoff: option 1 provides greater ability to shape model behavior, but at the cost of Goodharting (Karwowski et al. 2023); option 2 is less able to shape behavior, but robust to Goodharting.
When oversight is limited, it may be more effective to use detected instances to understand and modify the system's internal mechanisms, rather than using them to apply selection pressure during training. This principle could inform the development of new training methods. Key questions include:
Clarifying capabilities vs. dispositions
Loosely speaking, there are two kinds of things one might want to localize in an AI system: processing responsible for the AI system having a particular disposition (behavioral tendency) or processing that constitutes a capability (the ability in some circumstances to exhibit a behavior). We have speculated about tradeoffs to each of these approaches.
However, we're not sure how to operationalize "capability" or "disposition," and whether distinguishing between the two is helpful for gradient routing methods development. A better understanding of these notions might be helpful. This might include:
Formalizing capabilities and dispositions;
Understanding how capabilities or dispositions are represented within neural networks.
These topics have been touched on in Thinking About Propensity Evaluations, When can we trust model evaluations?, Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?, and Capabilities: An Ontology.
Implications for AI safety
AI governance
Selective modularity offers new affordances that might enable better AI governance. Properties induced by selective modularity may be empirically verifiable in ways that cannot be achieved by conventional training. For example, selective modularity could be evaluated by finetuning, assuming that finetuneability is a proxy for generalization.
Policy ideas:
See also:
Access control
Disabling a specialized submodule creates a new model with selectively limited capabilities. If submodules are specialized based on sensitive capabilities or knowledge, this fact could be used to enact access control. (See here for a similar proposal.) We envision two kinds of access control:
The technical limitations and affordances of subagent access control are an open question. It's not clear if such a scheme could be implemented without a prohibitive cost to performance, or what kinds of monitoring might be enabled. This could be investigating using tools from multiagent systems, adversarial learning, or AI control.
End user access control would be enabled by development of better gradient routing methods or robust unlearning methods. Aside from this technical work, there may be opportunities to develop, propose, and enact policies that leverage end user access control to reduce risks from AI deployment.
Implications of robust unlearning
Many promising applications of gradient routing are based on its potential to create models which are verifiably robustly incapable of performing particular tasks. But gradient routing is not the only way to achieve this. It is possible that post-hoc robust unlearning methods would be suitable for the task. In any case, we would be excited to see greater engagement with how robust unlearning might enable new opportunities to address risks from superintelligent AI. We think robust unlearning can be useful for addressing misalignment risks as well as misuse risks. For example, by
An objection to unlearning for ensuring AI safety is that a highly capable model would derive what it needs to know in-context. This may be true, but it is not a reason to abandon unlearning: by forcing a model to derive harmful information in context, we decrease the model’s efficacy at harmful behavior and improve our ability to monitor it.
Safety cases
A safety case is a “structured rationale that a system is unlikely to cause significant harm if it is deployed to a particular setting” (Clymer et al., 2024). These can be built from (non-exhaustively)
We think that gradient routing techniques could serve as the building blocks of safety cases. For example, gradient routing might enable robust unlearning, which would support inability arguments. Gradient routing could also help with control in the case where there are multiple AIs collaborating as described in access control.
Getting involved
We would be excited to see more people working on selective modularity!
If you're ready to jump in as a researcher or principal investigator, we would be happy to offer feedback on project proposals. (Preferably these would be two pages or fewer and posted publicly.)
Consider applying to MATS 8.0 to work with Alex Turner and Alex Cloud by Apr 18, 2025.
Ideas or criticisms are welcome. We are most curious to know if we've overlooked any (i) safety applications of selective modularity or (ii) compelling arguments for why selective modularity is less valuable to work on (at the margin) than other AI safety agendas.
If you are a funder and want to give us or our collaborators money, get in touch.
We (Jacob and Alex) expect to have very limited bandwidth over the next few months, so we may be slow to respond. Sorry!
Acknowledgements
We gratefully acknowledge:
A change to the training data (e.g. changing the labels, or removing a subset of the data) would constitute a change to the training objective according to our usage.
The rationale for routing based on the attention pattern is that if a token A attends to another token B, that means the model predicts that B’s information is important to predicting the token that comes after A, so we could route B and the token coming after A to the same part of the network.
Thanks to Addie Foote for proposing this idea.
Thanks to Ethan Perez for suggesting this topic.
A more thorough formalization of the problem would define the misaligned set in terms of input, output pairs; it would also treat datasets and misaligned behavior probabilistically.
Concisely: we are relying on the fact that "bad input exists => bad parameter exists" is equivalent to "bad parameter does not exist => bad input does not exist."