Kind of confused on why the KL-only e2e SAE have worse CE than e2e+downstream across dictionary size:
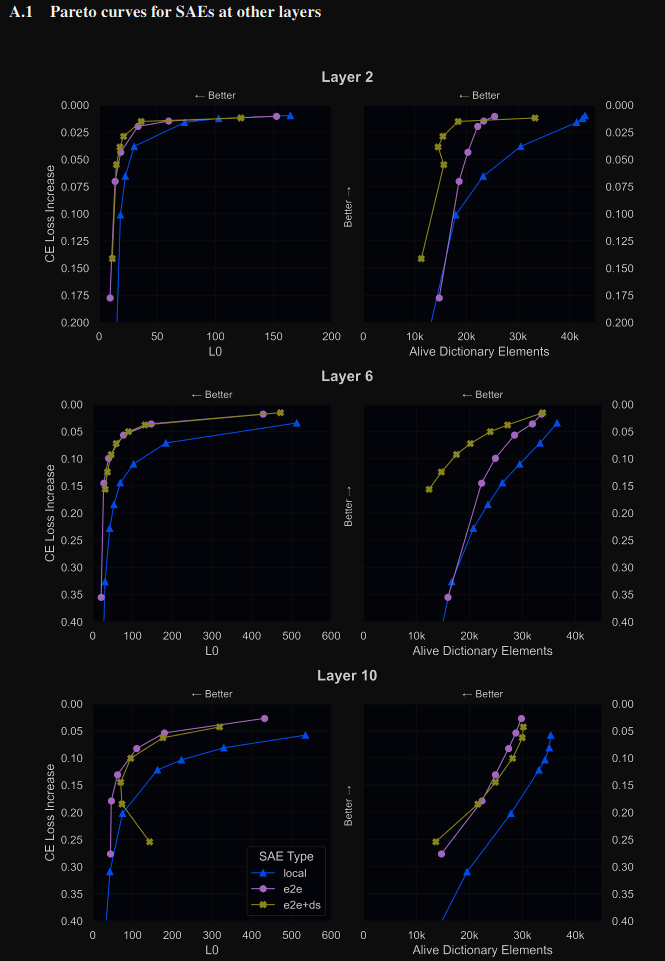
This is true for layers 2 & 6. I'm unsure if this means that training for KL directly is harder/unstable, and the intermediate MSE is a useful prior, or if this is a difference in KL vs CE (ie the e2e does in fact do better on KL but worse on CE than e2e+downstream).
The e2e having different feature directions across seeds was quite the bummer, but then I thought "are the encoder directions different though?"
Intuitively the encoder directions affect which datapoints each feature activates on, and the decoder is the causal downstream effect. For e2e, we would expect widely different decoder directions because there are many free parameters (from some other work that showed SVD of gradients had many zero singular values, meaning moving in most directions don't effect the downstream loss), but not necessarily encoder directions.
If the encoder directions are similar across seeds, I'd trust them to inform relevant features for the model output (in cases where we don't care about connections w/ downstream layers).
However, I was not able to find the SAEs for various seeds.
Trying to replicate Cos-sim Plots
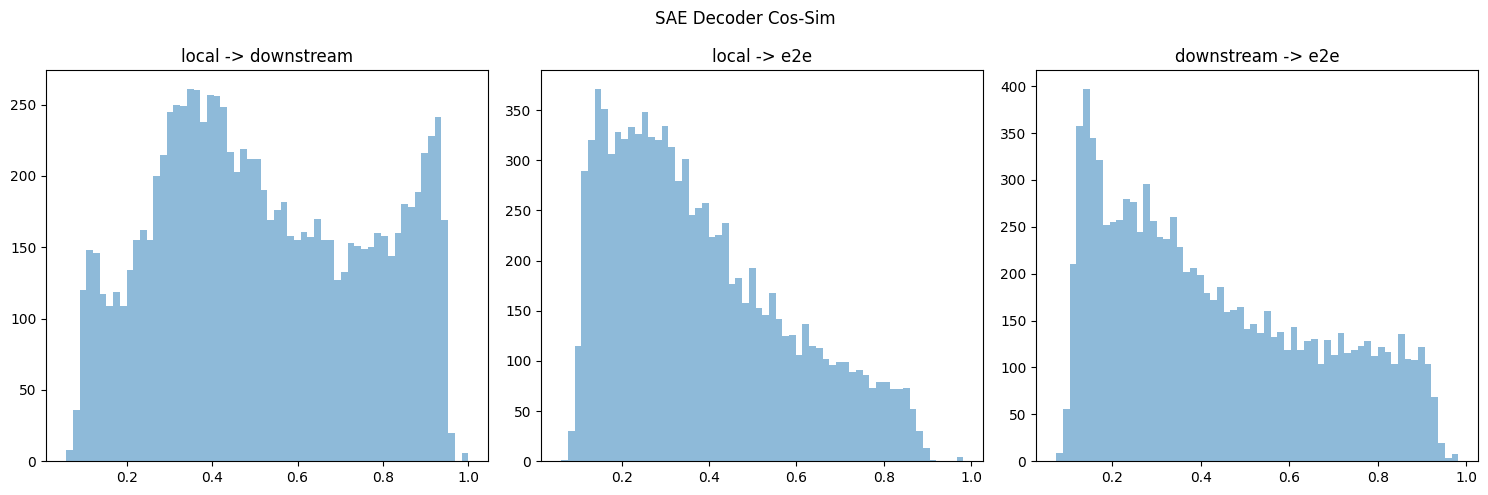
I downloaded the similar CE at layer 6 for all three types of SAEs & took their cos-sim (last column in figure 3).
I think your cos-sim metric gives different results if you take the max over the first or 2nd dimension (or equivalently swapped the order of decoders multiplied by each other). If so, I think this is because you might double-count or something? Regardless, I ended up doing some hungarian algorithm to take the overall max (but don't double-count), but it's on cpu, so I only did the first 10k/40k features. Below is results for both encoder & decoder, which do replicate the directional results.
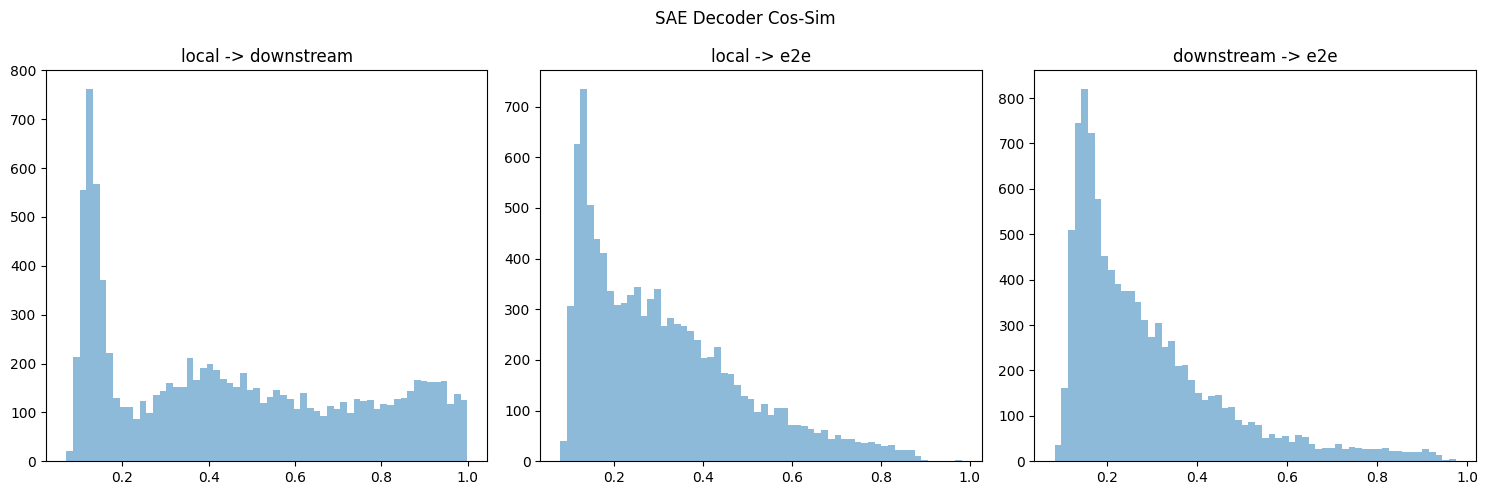
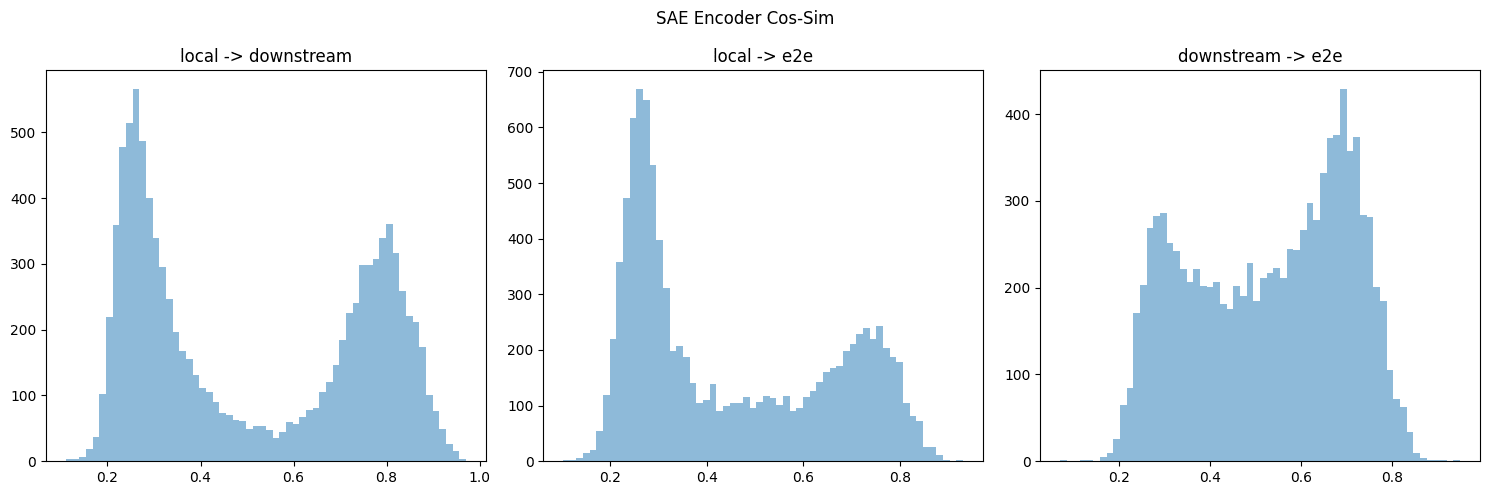
Nonzero Features
Additionally I thought that some results were from counting nonzero features, which, for the encoder is some high-cos-sim features, and decoder is the low-cos-sim features weirdly enough.
Would appreciate if y'all upload any repeated seeds!
My code is temporarily hosted (for a few weeks maybe?) here.
Every SAE in the paper is hosted on wandb, only some are hosted on huggingface, so I suggest loading them from wandb for now. We’ll upload more to huggingface if several people prefer that. Info for downloading from wandb can be found in the repo, the easiest way is probably:
# pip install e2e_sae
# Save your wandb api key in .env
from e2e_sae import SAETransformer
model = SAETransformer.from_wandb("sparsify/gpt2/d8vgjnyc")
sae = list(model.saes.values())[0] # Assumes only 1 sae in model, true for all saes in paper
encoder = sae.encoder[0]
dict_elements = sae.dict_elements # Returns the normalized decoder elementsThe wandb ids for different seeds can be found in the geometric analysis script here. That script, along with plot_performance.py, is a good place to see which wandb ids were used for each plot in the paper, as well as the exact code used to produce the plots in the paper (including the cosine sim plots you replicated above).
If you want to avoid the e2e_sae dependency, you can find the raw sae weights in the samples_400000.pt file in the respective wandb run. Just make sure to normalize the decoder weights after downloading (note that this was done before uploading to huggingface so people could load the SAEs into e.g. SAELens without having to worry about it).
If so, I think this is because you might double-count or something?
We do double count in the sense that, if, when comparing the similarity between A and B, element A_i has max cosine sim with B_j, we don't remove B_j from being in the max cosine sim for other elements in A. It's not obvious (to me at least) that we shouldn't do this when summarising dictionary similarity in a single metric, though I agree there is a tonne of useful geometric comparison that isn't covered by our single number. Really glad you're digging deeper into this. I do think there is lots that can be learned here.
Btw it's not intuitive to me that the encoder directions might be similar even though the decoder directions are not. Curious if you could share your intuitions here.
I finally checked!
Here is the Jaccard similarity (ie similarity of input-token activations) across seeds
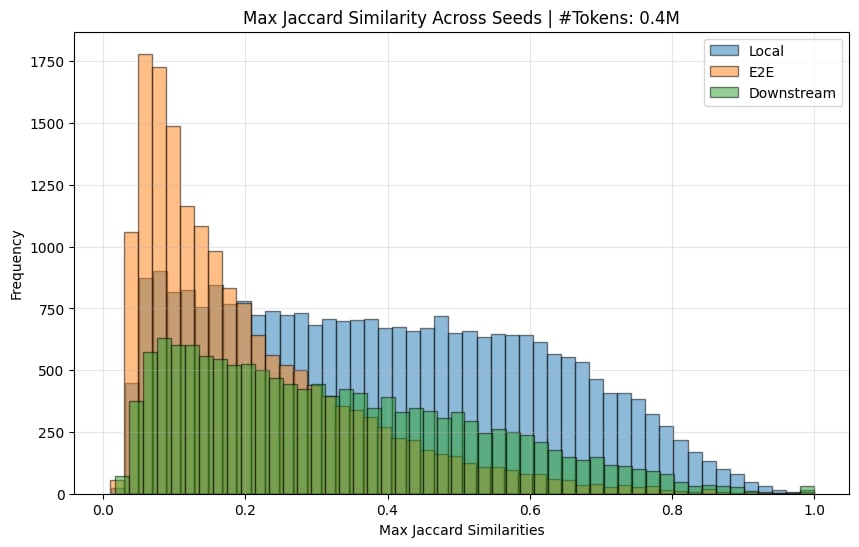
The e2e ones do indeed have a much lower jaccard sim (there normally is a spike at 1.0, but this is removed when you remove features that only activate <10 times).
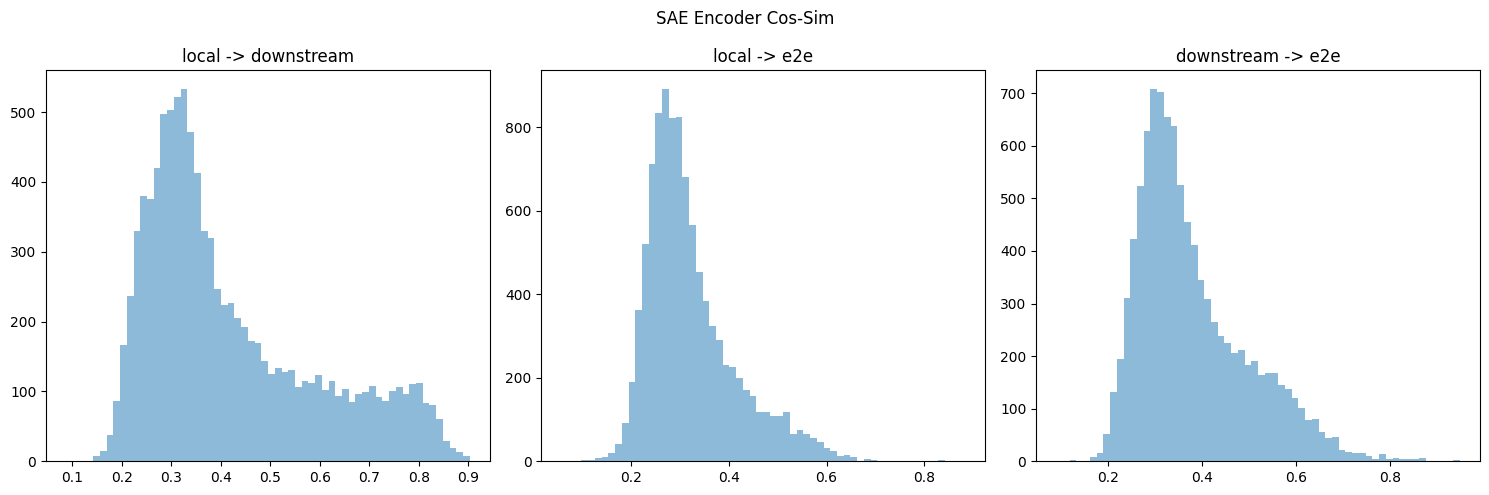
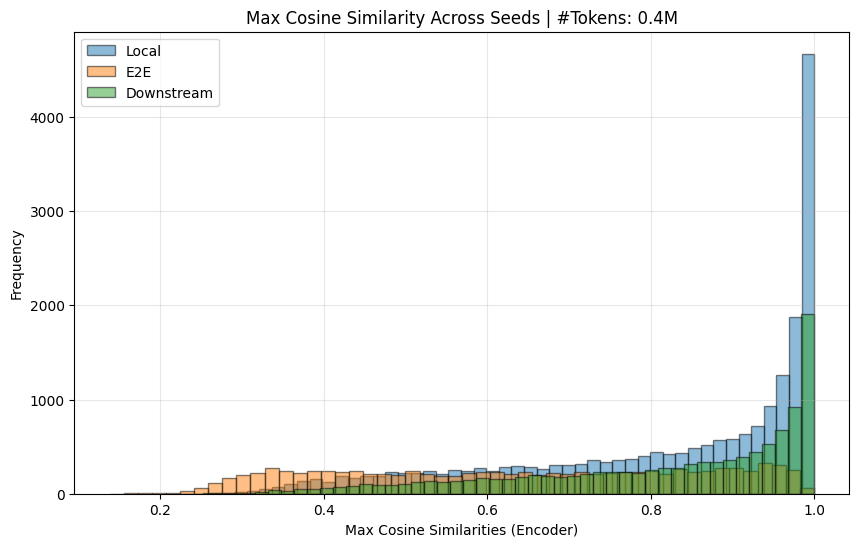
I also (mostly) replicated the decoder similarity chart:
And calculated the encoder sim:
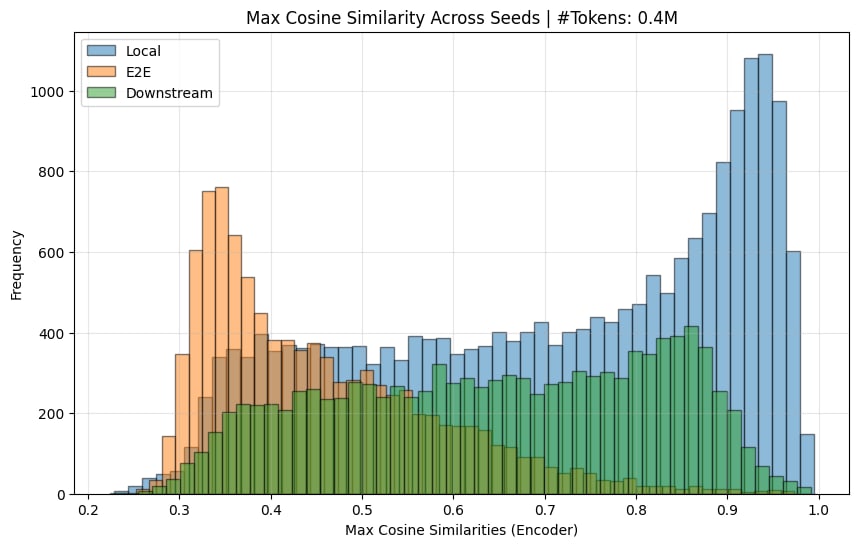
[I, again, needed to remove dead features (< 10 activations) to get the graphs here.]
So yes, I believe the original paper's claim that e2e features learn quite different features across seeds is substantiated.
Thanks so much! All the links and info will save me time:)
Regarding cos-sim, after thinking a bit, I think it's more sinister. For cross-cos-sim comparison, you get different results if you take the max over the 0th or 1st dimension (equivalent to doing cos(local, e2e) vs cos(e2e, local). As an example, you could have 2 features each, 3 point in the same direction and 1 points opposte. Making up numbers:
feature-directions(1D) = [ [1],[1]] & [[1],[-1]]
cos-sim = [[1, 1], [-1, -1]]
For more intuition, suppose 4 local features surround 1 e2e feature (and the other features are pointed elsewhere). Then the 4 local features will all have high max-cos sim but the e2e only has 1. So it's not just double-counting, but quadruple counting. You could see for yourself if you swap your dim=1 to 0 in your code.
But my original comment showed your results are still directionally correct when doing [global max w/ replacement] (if I coded it correctly).
Btw it's not intuitive to me that the encoder directions might be similar even though the decoder directions are not. Curious if you could share your intuitions here.
The decoder directions have degrees of freedom, but the encoder directions...might have similar degrees of freedom and I'm wrong, lol. BUT! they might be functionally equivalent, so they activate on similar datapoints across seeds. That is more laborious to check though, waaaah.
I can check both (encoder directions first) because previous literature is really only on the SVD of gradient (ie the output), but an SAE might be more constrained when separating out inputs into sparse features. Thanks for prompting for my intuition!
What is the activation name for the resid SAEs? hook_resid_post or hook_resid_pre?
I found https://github.com/ApolloResearch/e2e_sae/blob/main/e2e_sae/scripts/train_tlens_saes/run_train_tlens_saes.py#L220
to suggest _post
but downloading the SAETransformer from wandb shows:(saes): ModuleDict( (blocks-6-hook_resid_pre): SAE( (encoder): Sequential( (0):...
which suggests _pre.
What a cool paper! Congrats!:)
What's cool:
1. e2e saes learn very different features every seed. I'm glad y'all checked! This seems bad.
2. e2e SAEs have worse intermediate reconstruction loss than local. I would've predicted the opposite actually.
3. e2e+downstream seems to get all the benefits of the e2e one (same perf at lower L0) at the same compute cost, w/o the "intermediate activations aren't similar" problem.
It looks like you've left for future work postraining SAE_local on KL or downstream loss as future work, but that's a very interesting part! Specifically the approximation of SAE_e2e+downstream as you train on number of tokens.
Did y'all try ablations on SAE_e2e+downstream? For example, only training on the next layers Reconstruction loss or next N-layers rec loss?
Thanks Logan!
2. Unlike local SAEs, our e2e SAEs aren't trained on reconstructing the current layer's activations. So at least my expectation was that they would get a worse reconstruction error at the current layer.
Improving training times wasn't our focus for this paper, but I agree it would be interesting and expect there to be big gains to be made by doing things like mixing training between local and e2e+downstream and/or training multiple SAEs at once (depending on how you do this, you may need to be more careful about taking different pathways of computation to the original network).
We didn't iterate on the e2e+downstream setup much. I think it's very likely that you could get similar performance by making tweaks like the ones you suggested.
A short summary of the paper is presented below.
This work was produced by Apollo Research in collaboration with Jordan Taylor (MATS + University of Queensland) .
TL;DR: We propose end-to-end (e2e) sparse dictionary learning, a method for training SAEs that ensures the features learned are functionally important by minimizing the KL divergence between the output distributions of the original model and the model with SAE activations inserted. Compared to standard SAEs, e2e SAEs offer a Pareto improvement: They explain more network performance, require fewer total features, and require fewer simultaneously active features per datapoint, all with no cost to interpretability. We explore geometric and qualitative differences between e2e SAE features and standard SAE features.
Introduction
Current SAEs focus on the wrong goal: They are trained to minimize mean squared reconstruction error (MSE) of activations (in addition to minimizing their sparsity penalty). The issue is that the importance of a feature as measured by its effect on MSE may not strongly correlate with how important the feature is for explaining the network's performance.
This would not be a problem if the network's activations used a small, finite set of ground truth features -- the SAE would simply identify those features, and thus optimizing MSE would have led the SAE to learn the functionally important features. In practice, however, Bricken et al. observed the phenomenon of feature splitting, where increasing dictionary size while increasing sparsity allows SAEs to split a feature into multiple, more specific features, representing smaller and smaller portions of the dataset. In the limit of large dictionary size, it would be possible to represent each individual datapoint as its own dictionary element.
Since minimizing MSE does not explicitly prioritize learning features based on how important they are for explaining the network's performance, an SAE may waste much of its fixed capacity on learning less important features. This is perhaps responsible for the observation that, when measuring the causal effects of some features on network performance, a significant amount is mediated by the reconstruction residual errors (i.e. everything not explained by the SAE) and not mediated by SAE features (Marks et al.).
Given these issues, it is therefore natural to ask how we can identify the functionally important features used by the network. We say a feature is functional important if it is important for explaining the network's behavior on the training distribution. If we prioritize learning functionally important features, we should be able to maintain strong performance with fewer features used by the SAE per datapoint as well as fewer overall features.
To optimize SAEs for these properties, we introduce a new training method. We still train SAEs using a sparsity penalty on the feature activations (to reduce the number of features used on each datapoint), but we no longer optimize activation reconstruction. Instead, we replace the original activations with the SAE output and optimize the KL divergence between the original output logits and the output logits when passing the SAE output through the rest of the network, thus training the SAE end-to-end (e2e).
One risk with this method is that it may be possible for the outputs of SAE_e2e to take a different computational pathway through subsequent layers of the network (compared with the original activations) while nevertheless producing a similar output distribution. For example, it might learn a new feature that exploits a particular transformation in a downstream layer that is unused by the regular network or that is used for other purposes. To reduce this likelihood, we also add terms to the loss for the reconstruction error between the original model and the model with the SAE at downstream layers in the network.
It's reasonable to ask whether our approach runs afoul of Goodhart's law ("When a measure becomes a target, it ceases to be a good measure") We contend that mechanistic interpretability should prefer explanations of networks (and the components of those explanations, such as features) that explain more network performance over other explanations. Therefore, optimizing directly for quantitative proxies of performance explained (such as CE loss difference, KL divergence, and downstream reconstruction error) is preferred.
Key Results
We train each SAE type on language models (GPT2-small and Tinystories-1M), and present three key findings (Figure 1):
Moreover, our automated interpretability and qualitative analyses reveal that SAE_e2e+ds features are at least as interpretable as SAE_local features, demonstrating that the improvements in efficiency do not come at the cost of interpretability. These gains nevertheless come at the cost of longer wall-clock time to train (see article for further details).
When comparing the reconstruction errors at each downstream layer after the SAE is inserted (Figure 2 below), we find that, even though SAE_e2es explain more performance per feature than SAE_locals, they have much worse reconstruction error of the original activations at each subsequent layer. This indicates that the activations following the insertion of SAE_e2e take a different path through the network than in the original model, and therefore potentially permit the model to achieve its performance using different computations from the original model. This possibility motivated the training of SAE_e2e+ds, which we see has extremely similar reconstruction errors compared to SAE_local. SAE_e2e+ds therefore has the desirable properties of both learning features that explain approximately as much network performance as SAE_e2e (Figure 1) while having reconstruction errors that are much closer to SAE_local.
We measure the cosine similarities between each SAE dictionary feature and next-closest feature in the same dictionary. While this does not account for potential semantic differences between directions with high cosine similarities, it serves as a useful proxy for feature splitting, since split features tend to be highly similar directions. We find that SAE_local has features that are more tightly clustered, suggesting higher feature splitting (Figure 3 below). Compared to SAE_e2e+ds the mean cosine similarity is 0.04 higher (bootstrapped 95% CI [0.037-0.043]); compared to SAE_e2e the difference is 0.166 (95% CI [0.163-0.168]). We measure this for all runs in our Pareto frontiers in Appendix A.7 (Figure 7), and find that this difference is not explained by SAE_local having more alive dictionary elements than e2e SAEs.
In the paper, we also explore some qualitative differences between SAE_local and SAE_e2e+ds.
Acknowledgements
Johnny Lin and Joseph Bloom for supporting our SAEs on https://www.neuronpedia.org/gpt2sm-apollojt and Johnny Lin for providing tooling for automated interpretability, which made the qualitative analysis much easier. Lucius Bushnaq, Stefan Heimersheim and Jake Mendel for helpful discussions throughout. Jake Mendel for many of the ideas related to the geometric analysis. Tom McGrath, Bilal Chughtai, Stefan Heimersheim, Lucius Bushnaq, and Marius Hobbhahn for comments on earlier drafts. Center for AI Safety for providing much of the compute used in the experiments.
Extras