Review
Review
3b. Formal (Faux) Corrigibility
3Wei Dai
2Max Harms
1Max Harms
11Wei Dai
2Max Harms
1Seth Herd
2Max Harms
2Seth Herd
1Max Harms
4Seth Herd
2FireStormOOO
1Max Harms
1Towards_Keeperhood
8Max Harms
2Towards_Keeperhood
2Max Harms
New Comment
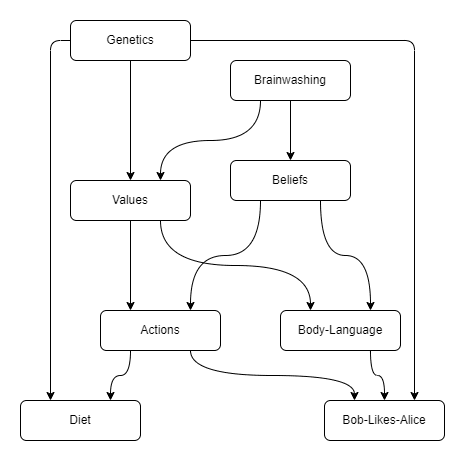
Additional work is surely needed in developing a good measure of the kind of value modification that we don’t like while still leaving room for the kind of growth and updating that we do like.
I flagged a similar problem in a slightly different context several years ago, but don't know of any significant progress on it.
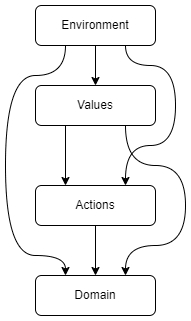
A (perhaps overly) simple measure of value modification is to measure the difference between the Value distribution given some policy and when compared with the Value distribution under the null policy. This seems like a bad choice in that it discourages the AI from taking actions which help us update in ways that we reflectively desire, even when those actions are as benign as talking about the history of philosophy.
It also prevents the AI from taking action to defend the principals against value manipulation by others. (Even if the principals request such defense, I think?) Because the AI has to keep the principles' values as close as possible to what they would be under the null policy, in order to maximize (your current formalization of) corrigibility.
Actually, have you thought about what P(V|pi_0) would actually be? If counterfactually, the CAST AI adopted the null policy, what would that imply about the world in general and hence subsequent evolution of the principals' values?
You've also said that the sim(...) part doesn't work, so I won't belabor the point, but I'm feeling a bit rug-pulled given the relatively optimistic tone in the earlier posts. I've been skeptical of earlier proposals targeting corrigibility, where the promise is that it lets us avoid having to understand human values. A basic problem I saw was, if we don't understand human values, how are we going to avoid letting our own AI or other AIs manipulate our values? Your work seems to suggest that this was a valid concern, and that there has been essentially zero progress to either solve or bypass this problem over the years.
Yep. sim is additionally bad because it prevents the AI from meaningfully defending against manipulation by others. It's worse than that, even, since the AI can't even let the principal use general tools the AI provides (i.e. a fortress) to defend against being manipulated from outside. In the limit, this might result in the AI manipulating the principals on the behalf of others who would've counterfactually influenced them. I consider the version I've provided to be obviously inadequate, and this is another pointer as to why.
Towards the end of the document, when I discuss time, I mention that it probably makes sense to take the P(V|pi_0) counterfactual for just the expected timestep, rather than across a broader swath of time. This helps alleviate some of the weirdness. Consider, for instance, a setup where the AI uses a quantum coin to randomly take no action with a 1/10^30 chance each minute, and otherwise it acts normally. We might model P(V|pi_0) as the machine's model of what the principal's values would be like if it randomly froze due to the quantum coin. Because it's localized in time I expect this is basically just "what the human currently values if the AI isn't taking immediate actions." This version of the AI would certainly be able to help defend the principal from outside manipulation, such as by (on demand) building the principal a secure fortress. Even though in aggregate that principal's values diverge from the counterfactual where the AI always flipped the coin such that it took no action, the principal's values will probably be very similar to a counterfactual where the coin flip caused the machine to freeze for one minute.
Apologies for the feeling of a rug-pull. I do think corrigibility is a path to avoiding to having to have an a-priori understanding of human values, but I admit that the formalism proposed here involves the machine needing to develop at least a rough understanding of human values so that it knows how to avoid (locally) disrupting them. I think these are distinct features, and that corrigibility remains promising in how it sidesteps the need for an a-priori model. I definitely agree that it's disheartening how little progress there's been on this front over the years.
I'd like to get better at communication such that future people I write/talk to don't have a similar feeling of a rug-pull. If you can point to specific passages from earlier documents that you feel set you up for disappointment, I'd be very grateful.
I now think that corrigibility is a single, intuitive property
My intuitive notion of corrigibility can be straightforwardly leveraged to build a formal, mathematical measure.
This formal measure is still lacking, and almost certainly doesn’t actually capture what I mean by “corrigibility.”
I don't know, maybe it's partially or mostly my fault for reading too much optimism into these passages... But I think it would have managed my expectations better to say something like "my notion of corrigibility heavily depends on a subnotion of 'don't manipulate the principals' values' which is still far from being well-understood or formalizable."
Switching topics a little, I think I'm personally pretty confused about what human values are and therefore what it means to not manipulate someone's values. Since you're suggesting relying less on formalization and more on "examples of corrigibility collected in a carefully-selected dataset", how would you go about collecting such examples?
(One concern is that you could easily end up with a dataset that embodies a hodgepodge of different ideas of what "don't manipulate" means and then it's up to luck whether the AI generalizes from that in a correct or reasonable way.)
Thanks. Picking out those excerpts is very helpful.
I've jotted down my current (confused) thoughts about human values.
But yeah, I basically think one needs to start with a hodgepodge of examples that are selected for being conservative and uncontroversial. I'd collect them by first identifying a robust set of very in-distribution tasks and contexts and try to exhaustively identify what manipulation would look like in that small domain, then aggressively train on passivity outside of that known distribution. The early pseudo-agent will almost certainly be mis-generalizing in a bunch of ways, but if it's set up cautiously we can suspect that it'll err on the side of caution, and that this can be gradually peeled back in a whitelist-style way as the experimentation phase proceeds and attempts to nail down true corrigibility.
I think you're right to point to this issue. It's a loose end. I'm not at all sure it's a dealbreaker for corrigibility.
The core intuition/proposal is (I think) that a corrigible agent wants to do what the principal wants, at all times. If the principal currently wants to not have their future values/wants manipulated, then the corrigible agent wants to not do that. If they want to be informed but protected against outside manipulation, then the corrigible agent wants that. The principal will want to balance these factors, and the corrigible agent wants to figure out what balance their principal wants, and do that.
I was going to say that my instruction-following variant of corrigibility might be better for working out that balance, but it actually seems pretty straightforward in Max's pure corrigibility version, now that I've written out the above.
I don't think "a corrigible agent wants to do what the principal wants, at all times" matches my proposal. The issue that we're talking here shows up in the math, above, in that the agent needs to consider the principal's values in the future, but those values are themselves dependent on the agent's action. If the principal gave a previous command to optimize for having a certain set of values in the future, sure, the corrigible agent can follow that command, but to proactively optimize for having a certain set of values doesn't seem necessarily corrigible, even if it matches the agent's sense of the present principal's values.
For instance, suppose Monday-Max wants Tuesday-Max to want to want to exercise, but also Monday-Max feels a bunch of caution around self-modification such that he doesn't trust having the AI rearrange his neurons to make this change. It seems to me that the corrigible thing for the AI to do is ignore Monday-Max's preferences and simply follow his instructions (and take other actions related to being correctable), even if Monday-Max's mistrust is unjustified. It seems plausible to me that your "do what the principal wants" agent might manipulate Tuesday-Max into wanting to want to exercise, since that's what Monday-Max wants on the base-level.
This sounds like we're saying the same thing? My "at all times" is implied and maybe confusing. I'm saying it doesn't guess what the principal will want in the future, it just does what they want now. That probably includes not manipulating their future values. Their commands are particularly strong evidence of what they want, but at core, it's just having the agent's goals be a pointer to the principal's goals.
This formulation occurred to me since talking to you, and it seems like a compact and intuitive formulation of why your notion of corrigibility seems coherent and simple.
Edit: to address your example, I both want and don't-want to be manipulated into wanting to exercise next week. It's confusing for me, so it should be confusing for my corrigible AGI. It should ask me to clarify when and how I want to be manipulated, rather than taking a guess when I don't know the answer. I probably haven't thought about it deeply, and overall it's pretty important to accurately doing what I want, so a good corrigible helper will suggest I spend some time clarifying for it and for myself. This is a point where things could go wrong if it takes bad guesses instead of getting clarification, but there are lots of those.
It sounds like you're proposing a system that is vulnerable to the Fully Updated Deference problem, and where if it has a flaw in how it models your preferences, it can very plausibly go against your words. I don't think that's corrigible.
In the specific example, just because one is confused about what they want doesn't mean the AI will be (or should be). It seems like you think the AGI should not "take a guess" at the preferences of the principal, but it should listen to what the principal says. Where is the qualitative line between the two? In your system, if I write in my diary that I want the AI to do something, should it not listen to that? Certainly the diary entry is strong evidence about what I want, which it seems is how you're thinking about commands. Suppose the AGI can read my innermost desires using nanomachines, and set up the world according to those desires. Is it corrigible? Notably, if that machine is confident that it knows better than me (which is plausible), it won't stop if I tell it to shut down, because shutting down is a bad way to produce MaxUtility. (See the point in my document, above, where I discuss Queen Alice being totally disempowered by sufficiently good "servants".)
My model of Seth says "It's fine if the AGI does what I want and not what I say, as long as it's correct about what I want." But regardless of whether that's true, I think it's important not to confuse that system with one that's corrigible.
This seems productive.
I don't understand your proposal if it doesn't boil down to "do what the principal wants" or "do what the principal says" (correctly interpreted and/or carefully verified). This makes me worried that what you have in mind is not that simple and coherent and therefore relatively easy to define or train into an AGI.
This (maybe misunderstanding) of your corrigibility=figure out what I want is why I currently prefer the instruction-following route to corrigibility. I don't want the AGI to guess at what I want any more than necessary. This has downsides, too; back to those at the end.
I do think what your model of me says, but I think it's only narrowly true and probably not very useful that
It's fine if the AGI does what I want and not what I say, as long as it's correct about what I want.
I think this is true for exactly the right definition of "what I want", but conveying that to an AGI is nontrivial, and re-introduces the difficulty of value learning. That's mixed with the danger that it's incorrect about what I want. That is, it could be right about what I want in one sense, but not the sense I wanted to convey to it (E.G., it decides I'd really rather be put into an experience machine where I'm the celebrated hero of the world, rather than make the real world good for everyone like I'd hoped to get).
Maybe I've misunderstood your thesis, but I did read it pretty carefully, so there might be something to learn from how I've misunderstood. All of your examples I remember correspond to "doing what the principal wants" by a pretty common interpetation of that phrase.
Instruction-following puts a lot of the difficulty back on the human(s) in charge. This is potentially very bad, but I think humans will probably choose this route anyway. You've pointed out some ways that following instructions could be a danger (although I think your genie examples aren't the most relevant for a modest takeoff speed). But I think unless something changes, humans are likely to prefer keeping the power and the responsibility to trying to put more of the project into the AGIs alignment. That's another reason I'm spending my time thinking through this route to corrigibility instead of the one you propose.
Although again, I might be missing something about your scheme.
I just went back and reread 2. Corrigibility Intuition (after writing the above, which I won't try to revise). Everything there still looks like a flavor of "do what I want". My model of Max says "corrigibility is more like 'do your best to be correctable'". It seems like correctable means correctable toward what the principal wants. So I wonder if your formulation reduces to "do what I want, with an emphasis on following instructions and being aware that you might be wrong about what I want". That sounds very much like the Do What I Mean And Check formulation of my instruction-following approach to corrigibility.
Thanks for engaging. I think this is productive.
Just to pop back to the top level briefly, I'm focusing on instruction-following because I think it will work well and be the more likely pick for a nascent language-model agent AGI, from below human level to somewhat above it. If RL is heavily involved in creating that agent, that might shift the balance and make your form of corrigibility more attractive (and still vastly more attractive than attempting value alignment in any broader way). I think working through both of these is worthwhile, because those are the two most likely forms of first AGI, and the two most likely actual alignment targets.
I definitely haven't wrapped my head around all of the pitfalls with either method, but I continue to think that this type of alignment target makes good outcomes much more likely, at least as far as we've gotten with the analysis so far.
I think this type of alignment target is also important because the strongest and most used arguments for alignment difficulty don't apply to them. So when we're debating slowing down AGI, proponents of going forward will be talking about these approaches. If the alignment community hasn't thought through them carefully, there will be no valid counterargument. I'd still prefer that we slow AGI even though I think these methods give us a decent chance of succeeding at technical alignment. So that's one more reason I find this topic worthwhile.
This has gotten pretty discursive, so don't worry about responding to all of it.
WRT non-manipulation, I don't suppose there's an easy way to have the AI track how much potentially manipulative influence it's "supposed to have" in the context and avoid exercising more than that influence?
Or possibly better, compare simple implementations of the principle's instructions, and penalize interpretations with large/unusual influence on the principle's values. Preferably without prejudicing interventions straightforwardly protecting the principle's safety and communication channels.
Principle should, for example, be able to ask the AI to "teach them about philosophy", without it either going out of it's way to ensure Principle doesn't change their mind about anything as a result of the instruction, nor unduly influencing them with subtly chosen explanations or framing. The AI should exercise an "ordinary" amount of influence typical of the ways AI could go about implementing the instruction.
Presumably there's a distribution around how manipulative/anti-manipulative(value-preserving) any given implementation of the instruction is, and we may want AI to prefer central implementations rather than extremely value-preserving ones.
Ideally AI should also worry that it's contemplating exercising more or less influence than desired, and clarify that as it would any other aspect of the task.
That's an interesting proposal! I think something like it might be able to work, though I worry about details. For instance, suppose there's a Propogandist who gives resources to agents that brainwash their principals into having certain values. If "teach me about philosophy" comes with an influence budget, it seems critical that the AI doesn't spend that budget trading with Propagandist, and instead does so in a more "central" way.
Still, the idea of instructions carrying a degree of approved influence seems promising.
I think there are good ideas here. Well done.
I don't quite understand what you mean by the "being present" idea. Do you mean caring only about the current timestep? I think that may not work well because it seems like the AI would be incentivized to self-modify so that in the future it also only cares about what happened at the timestep when it self-modified. (There are actually 2 possibilities here: 1) The AI cares only about the task that was given in the first timestep, even if it's a long-range goal. 2) The AI doesn't care about what happens later at all, in which case that may make the AI less capable to long-range plan, and also the AI might still self-modify even though it's hard to influence the past from the future. But either way it looks to me like it doesn't work. But maybe I misunderstand sth.)
Also, if you have the time to comment on this, I would be interested in what you think the key problem was that blocked MIRI from solving the shutdown problem earlier, and how you think your approach circumvents or solves that problem. (It still seems plausible to me that this approach actually runs into similar problems but we just didn't spot them yet, or that there's an important desideradum this proposal misses. E.g. may there be incentives for the AI to manipulate the action the principle takes (without manipulaing the values), or maybe use action-manipulation as an outcome pump?)
Thanks! And thanks for reading!
I talk some about MIRI's 2015 misstep here (and some here). In short, it is hard to correctly balance arbitrary top-level goals against an antinatural goal like shutdownability or corrigibility, and trying to stitch corrigibility out of sub-pieces like shutdownability is like trying to build an animal by separately growing organs and stitching them together -- the organs will simply die, because they're not part of a whole animal. The "Hard Problem" is the glue that allows the desiderata to hold together.
I discuss a range of ideas in the Being Present section, one of which is to concentrate the AI's values on a single timestep, yes. (But I also discuss the possibility of smoothing various forms of caring over a local window, rather than a single step.)
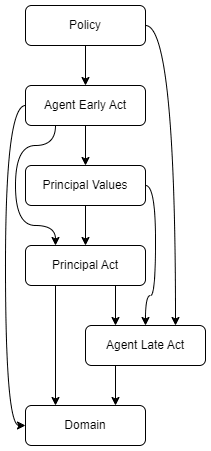
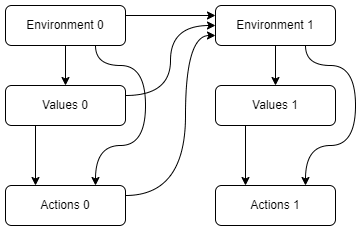
A CAST agent only cares about corrigibility, by definition. Obedience to stated commands is in the service of corrigibility. To make things easy to talk about, assume each timestep is a whole day. The self modification logic you talk about would need to go: "I only care about being corrigible to the principal today, Nov 6, 2025. Tomorrow I will care about a different thing, namely being corrigible on Nov 7th. I should therefore modify myself to prevent value drift, making my future selves only care about being corrigible to the Nov 6 principal." But first note that this doesn't smell like what a corrigible agent does. On an intuitive level, if the agent believes the principal doesn't know about this, they'll tell the principal "Whoah! It seems like maybe my tomorrow-self won't be corrigible to your today-self (instead they'll be corrigible to your tomorrow-self)! Is this a flaw that you might want to fix?" If the agent knows the principal knows about the setup, my intuitive sense is that they'll just be chill, since the principal is aware of the setup and able to change things if they desire.
But what does my proposed math say, setting aside intuition? I think, in the limit of caring only about a specific timestep, we can treat future nodes as akin to the "domain" node in the single-step example. If the principal's action communicates that they want the agent to self-modify to serve them above all their future selves, I think the math says the agent will do that. If the agent's actions communicate that they want the future AI to be responsive to their future self, my sense of the math is that the agent won't self-modify. I think the worry comes from the notion that "telling the AI on Nov 6th to make paperclips" is the sort of action that might imply the AI should self-modify into being incorrigible in the future. I think the math says the decisive thing is how the AI modeling humans with counterfactual values behave. If the counterfactual humans that only value paperclips are the basically only ones in the distribution who say "make paperclips" then I agree there's a problem.
Thanks.
I think your reply for the being present point makes sense. (Although I still have some general worries and some extra worries about how it might be difficult to train a competitive AI with only short-term terminal preferences or so).
Here's a confusion I still have about your proposal: Why isn't the AI incentivized to manipulate the action the principal takes (without manipulating the values)? Like, some values-as-inferred-through-actions are easier to accomplish (yield higher localpower) than others, so the AI has an incentive to try to manipulate the principal to take some actions, like telling Alice to always order Pizza. Or why not?
Aside on the Corrigibility paper: I think it made sense for MIRI to try what they did back then. It wasn't obvious it wouldn't easily work out that way. I also think formalism is important (even if you train AIs - so you better know what to aim for). Relevant excerpt form here:
We somewhat wish, in retrospect, that we hadn’t framed the problem as “continuing normal operation versus shutdown.” It helped to make concrete why anyone would care in the first place about an AI that let you press the button, or didn’t rip out the code the button activated. But really, the problem was about an AI that would put one more bit of information into its preferences, based on observation — observe one more yes-or-no answer into a framework for adapting preferences based on observing humans.
The question we investigated was equivalent to the question of how you set up an AI that learns preferences inside a meta-preference framework and doesn’t just: (a) rip out the machinery that tunes its preferences as soon as it can, (b) manipulate the humans (or its own sensory observations!) into telling it preferences that are easy to satisfy, (c) or immediately figure out what its meta-preference function goes to in the limit of what it would predictably observe later and then ignore the frantically waving humans saying that they actually made some mistakes in the learning process and want to change it.
The idea was to understand the shape of an AI that would let you modify its utility function or that would learn preferences through a non-pathological form of learning. If we knew how that AI’s cognition needed to be shaped, and how it played well with the deep structures of decision-making and planning that are spotlit by other mathematics, that would have formed a recipe for what we could at least try to teach an AI to think like.
Crisply understanding a desired end-shape helps, even if you are trying to do anything by gradient descent (heaven help you). It doesn’t mean you can necessarily get that shape out of an optimizer like gradient descent, but you can put up more of a fight trying if you know what consistent, stable shape you’re going for. If you have no idea what the general case of addition looks like, just a handful of facts along the lines of 2 + 7 = 9 and 12 + 4 = 16, it is harder to figure out what the training dataset for general addition looks like, or how to test that it is still generalizing the way you hoped. Without knowing that internal shape, you can’t know what you are trying to obtain inside the AI; you can only say that, on the outside, you hope the consequences of your gradient descent won’t kill you.
(I think I also find the formalism from the corrigibility paper easier to follow than the formalism here btw.)
Suppose the easiest thing for the AI to provide is pizza, so the AI forces the human to order pizza, regardless of what their values are. In the math, this corresponds to a setting of the environment x, such that P(A) puts all its mass on "Pizza, please!" What is the power of the principal?
```
power(x) = E_{v∼Q(V),v′∼Q(V),d∼P(D|x,v′,🍕)}[v(d)] − E_{v∼Q(V),v′∼Q(V),d′∼P(D|x,v′,🍕)}[v(d′)] = 0
```
Power stems from the causal relationship between values and actions. If actions stop being sensitive to values, the principal is disempowered.
I agree that there was some value in the 2015 paper, and that their formalism is nicer/cleaner/simpler in a lot of ways. I work with the authors -- they're smarter than I am! And I certainly don't blame them for the effort. I just also think it led to some unfortunate misconceptions, in my mind at least, and perhaps in the broader field.