I'm trying to prevent doom from AI. Currently trying to become sufficiently good at alignment research. Feel free to DM for meeting requests.
Wikitag Contributions
Thanks!
Another thing is, if the programmer wants CEV (for the sake of argument), and somehow (!!) writes an RL reward function in Python whose output perfectly matches the extent to which the AGI’s behavior advances CEV, then I disagree that this would “make inner alignment unnecessary”. I’m not quite sure why you believe that.
I was just imagining a fully omnicient oracle that could tell you for each action how good that action is according to your extrapolated preferences, in which case you could just explore a bit and always pick the best action according to that oracle. But nvm, I noticed my first attempt of how I wanted to explain what I feel like is wrong sucked and thus dropped it.
- The AGI was doing the wrong thing but got rewarded anyway (or doing the right thing but got punished)
- The AGI was doing the right thing for the wrong reasons but got rewarded anyway (or doing the wrong thing for the right reasons but got punished).
This seems like a sensible breakdown to me, and I agree this seems like a useful distinction (although not a useful reduction of the alignment problem to subproblems, though I guess you agree here).
However, I think most people underestimate how many ways there are for the AI to do the right thing for the wrong reasons (namely they think it's just about deception), and I think it's not:
I think we need to make AI have a particular utility function. We have a training distribution where we have a ground-truth reward signal, but there are many different utility functions that are compatible with the reward on the training distribution, which assign different utilities off-distribution.
You could avoid talking about utility functions by saying "the learned value function just predicts reward", and that may work while you're staying within the distribution we actually gave reward on, since there all the utility functions compatible with the ground-truth reward still agree. But once you're going off distribution, what value you assign to some worldstates/plans depends on what utility function you generalized to.
I think humans have particular not-easy-to-pin-down machinery inside them, that makes their utility function generalize to some narrow cluster of all ground-truth-reward-compatible utility functions, and a mind with a different mind design is unlikely to generalize to the same cluster of utility functions.
(Though we could aim for a different compatible utility function, namely the "indirect alignment" one that say "fulfill human's CEV", which has lower complexity than the ones humans generalize to (since the value generalization prior doesn't need to be specified and can instead be inferred from observations about humans). (I think that is what's meant by "corrigibly aligned" in "Risks from learned optimization", though it has been a very long time since I read this.))
Actually, it may be useful to distinguish two kinds of this "utility vs reward mismatch":
1. Utility/reward being insufficiently defined outside of training distribution (e.g. for what programs to run on computronium).
2. What things in the causal chain producing the reward are the things you actually care about? E.g. that the reward button is pressed, that the human thinks you did something well, that you did something according to some proxy preferences.
Overall, I think the outer-vs-inner framing has some implicit connotation that for inner alignment we just need to make it internalize the ground-truth reward (as opposed to e.g. being deceptive). Whereas I think "internalizing ground-truth reward" isn't meaningful off distribution and it's actually a very hard problem to set up the system in a way that it generalizes in the way we want.
But maybe you're aware of that "finding the right prior so it generalizes to the right utility function" problem, and you see it as part of inner alignment.
Note: I just noticed your post has a section "Manipulating itself and its learning process", which I must've completely forgotten since I last read the post. I should've read your post before posting this. Will do so.
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
Calling problems "outer" and "inner" alignment seems to suggest that if we solved both we've successfully aligned AI to do nice things. However, this isn't really the case here.
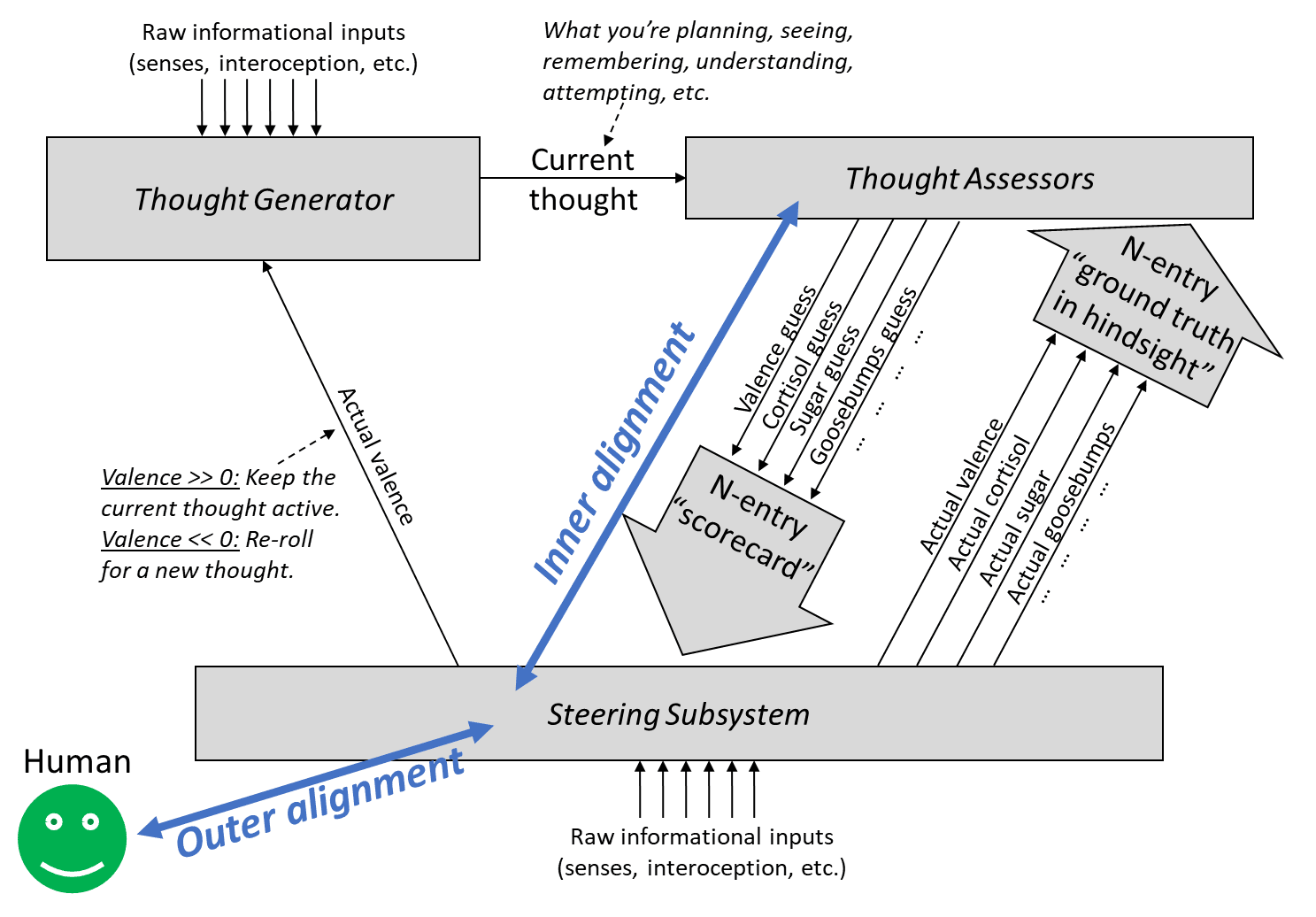
Namely, there could be a smart mesa-optimizer spinning up in the thought generator, who's thoughts are mostly invisible to the learned value function (LVF), and who can model the situation it is in and has different values and is smarter than the LVF evaluation and can fool the the LVF into believing the plans that are good according to the mesa-optimizer are great according to the LVF, even if they actually aren't.
This kills you even if we have a nice ground-truth reward and the LVF accurately captures that.
In fact, this may be quite a likely failure mode, given that the thought generator is where the actual capability comes from, and we don't understand how it works.
I'd suggest not using conflated terminology and rather making up your own.
Or rather, first actually don't use any abstract handles at all and just describe the problems/failure-modes directly, and when you're confident you have a pretty natural breakdown of the problems with which you'll stick for a while, then make up your own ontology.
In fact, while in your framework there's a crisp difference between ground-truth reward and learned value-estimator, it might not make sense to just split the alignment problem in two parts like this:
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
First attempt of explaining what seems wrong: If that was the first I read on outer-vs-inner alignment as a breakdown of the alignment problem, I would expect "rewards that agree with what we want" to mean something like "changes in expected utility according to humanity's CEV". (Which would make inner alignment unnecessary because if we had outer alignment we could easily reach CEV.)
Second attempt:
"in a way that agrees with its eventual reward" seems to imply that there's actually an objective reward for trajectories of the universe. However, the way you probably actually imagine the ground-truth reward is something like humans (who are ideally equipped with good interpretability tools) giving feedback on whether something was good or bad, so the ground-truth reward is actually an evaluation function on the human's (imperfect) world model. Problems:
- Humans don't actually give coherent rewards which are consistent with a utility function on their world model.
- For this problem we might be able to define an extrapolation procedure that's not too bad.
- The reward depends on the state of the world model of the human, and our world models probably often has false beliefs.
- Importantly, the setup needs to be designed in a way that there wouldn't be an incentive to manipulate the humans into believing false things.
- Maybe, optimistically, we could mitigate this problem by having the AI form a model of the operators, doing some ontology translation between the operator's world model and its own world model, and flagging when there seems to be a relavant belief mismatch.
- Our world models cannot evaluate yet whether e.g. filling the universe computronium running a certain type of programs would be good, because we are confused about qualia and don't know yet what would be good according to our CEV. Basically, the ground-truth reward would very often just say "i don't know yet", even for cases which are actually very important according to our CEV. It's not just that we would need a faithful translation of the state of the universe into our primitive ontology (like "there are simulations of lots of happy and conscious people living interesting lives"), it's also that (1) the way our world model treats e.g. "consciousness" may not naturally map to anything in a more precise ontology, and while our human minds, learning a deeper ontology, might go like "ah, this is what I actually care about - I've been so confused", such value-generalization is likely even much harder to specify than basic ontology translation. And (2), our CEV may include value-shards which we currently do not know of or track at all.
- So while this kind of outer-vs-inner distinction might maybe be fine for human-level AIs, it stops being a good breakdown for smarter AIs, since whenever we want to make the AI do something where humans couldn't evaluate the result within reasonable time, it needs to generalize beyond what could be evaluated through ground-truth reward.
So mainly because of point 3, instead of asking "how can i make the learned value function agree with the ground-truth reward", I think it may be better to ask "how can I make the learned value function generalize from the ground-truth reward in the way I want"?
(I guess the outer-vs-inner could make sense in a case where your outer evaluation is superhumanly good, though I cannot think of such a case where looking at the problem from the model-based RL framework would still make much sense, but maybe I'm still unimaginative right now.)
Note that I assumed here that the ground-truth signal is something like feedback from humans. Maybe you're thinking of it differently than I described here, e.g. if you want to code a steering subsystem for providing ground-truth. But if the steering subsystem is not smarter than humans at evaluating what's good or bad, the same argument applies. If you think your steering subsystem would be smarter, I'd be interested in why.
(All that is assuming you're attacking alignment from the actor-critic model-based RL framework. There are other possible frameworks, e.g. trying to directly point the utility function on an agent's world-model, where the key problems are different.)
So the lab implements the non-solution, turns up the self-improvement dial, and by the time anybody realizes they haven’t actually solved the superintelligence alignment problem (if anybody even realizes at all), it’s already too late.
If the AI is producing slop, then why is there a self-improvement dial? Why wouldn’t its self-improvement ideas be things that sound good but don’t actually work, just as its safety ideas are?
Because you can speed up AI capabilities much easier while being sloppy than to produce actually good alignment ideas.
If you really think you need to be similarly unsloppy to build ASI than to align ASI, I'd be interested in discussing that. So maybe give some pointers to why you might think that (or tell me to start).
Thanks for providing a concrete example!
Belief propagation seems too much of a core of AI capability to me. I'd rather place my hope on GPT7 not being all that good yet at accelerating AI research and us having significantly more time.
I also think the "drowned out in the noise" isn't that realistic. You ought to be able to show some quite impressive results relative to computing power used. Though when you maybe should try to convince the AI labs of your better paradigm is going to be difficult to call. It's plausible to me we won't see signs that make us sufficiently confident that we only have a short time left, and it's plausible we do.
In any case before you publish something you can share it with trustworthy people and then we can discuss that concrete case in detail.
Btw tbc, sth that I think slightly speeds up AI capability but is good to publish is e.g. producing rationality content for helping humans think more effectively (and AIs might be able to adopt the techniques as well). Creating a language for rationalists to reason in more Bayesian ways would probably also be good to publish.
Can you link me to what you mean by John's model more precisely?
If you mean John's slop-instead-scheming post, I agree with that with the "slop slightly more likely than scheming" part. I might need to reread John's post to see what the concrete suggestions for what to work on might be. Will do so tomorrow.
I'm just pessimistic that we can get any nontrivially useful alignment work out of AIs until a few months before the singularity, at least besides some math. Or like at least for the parts of the problem we are bottlenecked on.
So like I think it's valuable to have AIs that are near the singularity be more rational. But I don't really buy the differentially improving alignment thing. Or like could you make a somewhat concrete example of what you think might be good to publish?
Like, all capabilities will help somewhat with the AI being less likely to make errors that screw its alignment. Which ones do you think are more important than others? There would have to be a significant difference in usefulness pf some capabilities, because else you could just do the same alignment work later and still have similarly much time to superintelligence (and could get more non-timeline-upspeeding work done).
Thanks.
True, I think your characterization of tiling agents is better. But my impression was sorta that this self-trust is an important precursor for the dynamic self-modification case where alignment properties need to be preserved through the self-modification. Yeah I guess calling this AI solving alignment is sorta confused, though maybe there's sth into this direction because the AI still does the search to try to preserve the alignment properties?
Hm I mean yeah if the current bottleneck is math instead of conceptualizing what math has to be done then it's a bit more plausible. Like I think it ought to be feasible to get AIs that are extremely good at proving theorems and maybe also formalizing conjectures. Though I'd be a lot more pessimistic about finding good formal representations for describing/modelling ideas.
Do you think we are basically only bottlenecked on math so sufficient math skill could carry us to aligned AI, or only have some alignment philosophy overhang you want to formalize but then more philosophy will be needed?
What kind of alignment research do you hope to speed up anyway?
For advanced philosophy like stuff (e.g. finding good formal representations for world models, or inventing logical induction) they don't seem anywhere remotely close to being useful.
My guess would be for tiling agents theory neither but I haven't worked on it, so very curious on your take here. (IIUC, to some extent the goal of tiling-agents-theory-like work there was to have an AI solve it's own alignment problem. Not sure how far the theory side got there and whether it could be combined with LLMs.)
Or what is your alignment hope in more concrete detail?
This argument might move some people to work on "capabilities" or to publish such work when they might not otherwise do so.
Above all, I'm interested in feedback on these ideas. The title has a question mark for a reason; this all feels conjectural to me.
My current guess:
I wouldn't expect much useful research to come from having published ideas. It's mostly just going to be used in capabilities and it seems like a bad idea to publish stuff.
Sure you can work on it and be infosec cautious and keep it secret. Maybe share it with a few very trusted people who might actually have some good ideas. And depending on how things play out if in a couple years there's some actual effort from the joined collection of the leading labs to align AI and they only have like 2-8 months left before competition will hit the AI improving AI dynamic quite hard, then you might go to the labs and share your ideas with them (while still trying to keep it closed within those labs - which will probably only work for a few months or a year or so until there's leakage).
Thanks.
Yeah I guess I wasn't thinking concretely enough. I don't know whether something vaguely like what I described might be likely or not. Let me think out loud a bit about how I think about what you might be imagining so you can correct my model. So here's a bit of rambling: (I think point 6 is most important.)
I don't have a clear take here. I'm just curious if you have some thoughts on where something importantly mismatches your model.