Why Simulator AIs want to be Active Inference AIs
10janus
2Jan_Kulveit
3alec_tschantz
3Roman Leventov
New Comment
I only just got around to reading this closely. Good post, very well structured, thank you for writing it.
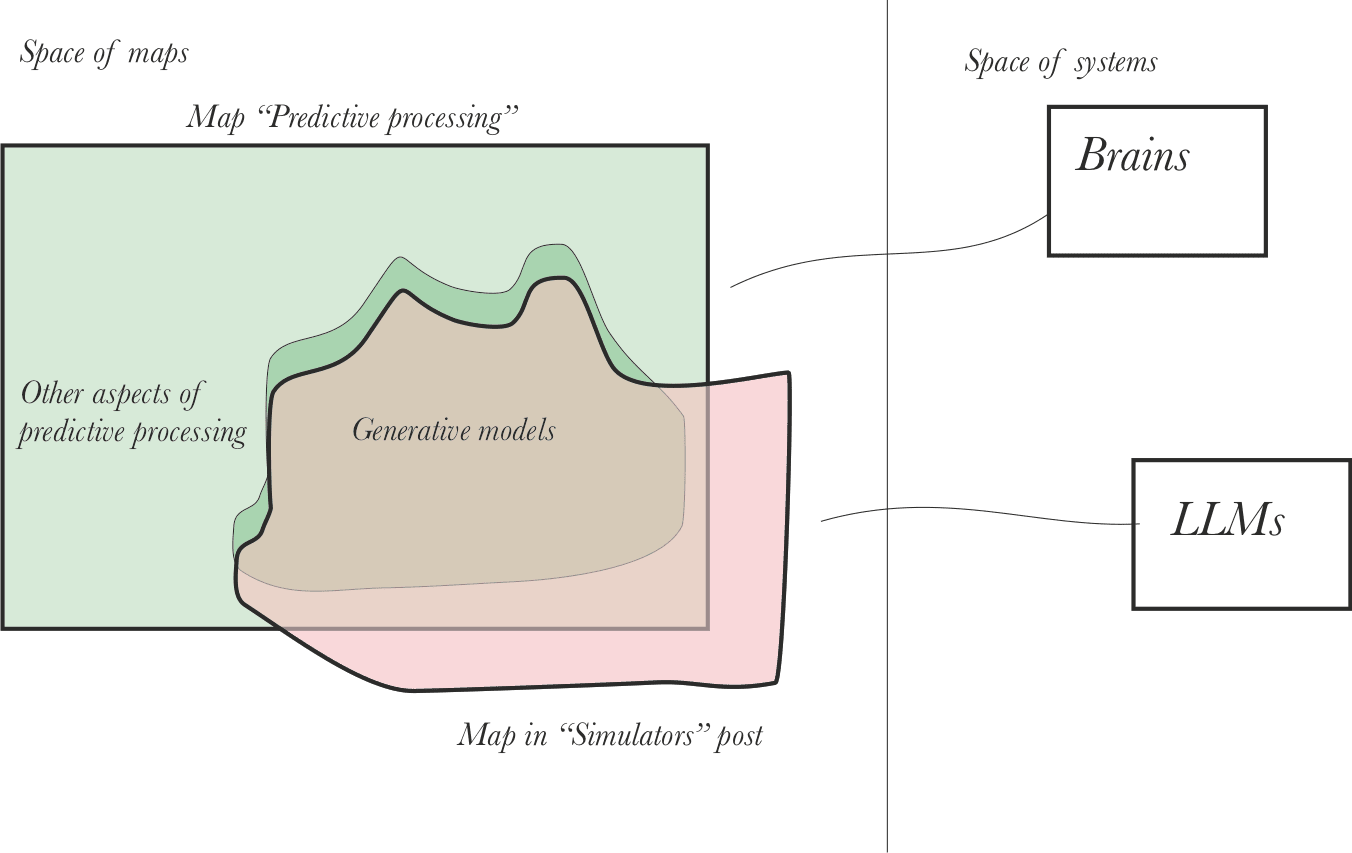
I agree with your translation from simulators to predictive processing ontology, and I think you identified most of the key differences. I didn't know about active inference and predictive processing when I wrote Simulators, but since then I've merged them in my map.
This correspondence/expansion is very interesting to me. I claim that an impressive amount of the history of the unfolding of biological and artificial intelligence can be retrodicted (and could plausibly have been predicted) from two principles:
- Predictive models serve as generative models (simulators) merely by iteratively sampling from the model's predictions and updating the model as if the sampled outcome had been observed. I've taken to calling this the progenesis principle (portmanteau of "prognosis" and "genesis"), because I could not find an existing name for it even though it seems very fundamental.
- Corollary: A simulator is extremely useful, as it unlocks imagination, memory, action, and planning, which are essential ingredients of higher cognition and bootstrapping.
- Self-supervised learning of predictive models is natural and easy because training data is abundant and prediction error loss is mechanistically simple. The book Surfing Uncertainty used the term innocent in the sense of ecologically feasible. Self-supervised learning is likewise and for similar reasons an innocent way to build AI - so much so that it might be done on accident initially.
Together, these suggest that self-supervised predictors/simulators are a convergent method of bootstrapping intelligence, as it yields tremendous and accumulating returns while requiring minimal intelligent design. Indeed, human intelligence seems largely self-supervised simulator-y, and the first very general and intelligent-seeming AIs we've manifested are self-supervised simulators.
A third principle that bridges simulators to active inference allows the history of biological intelligence to be more completely retrodicted and may predict the future of artificial intelligence:
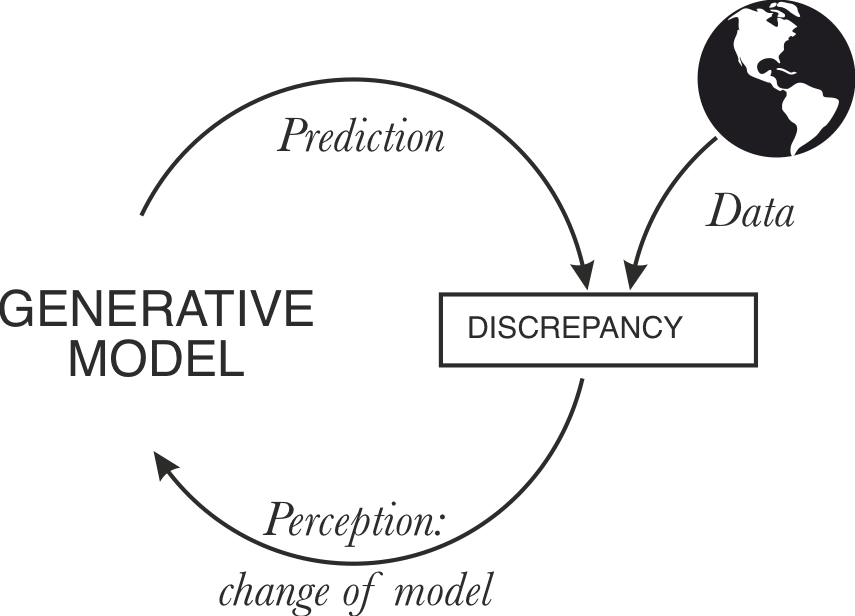
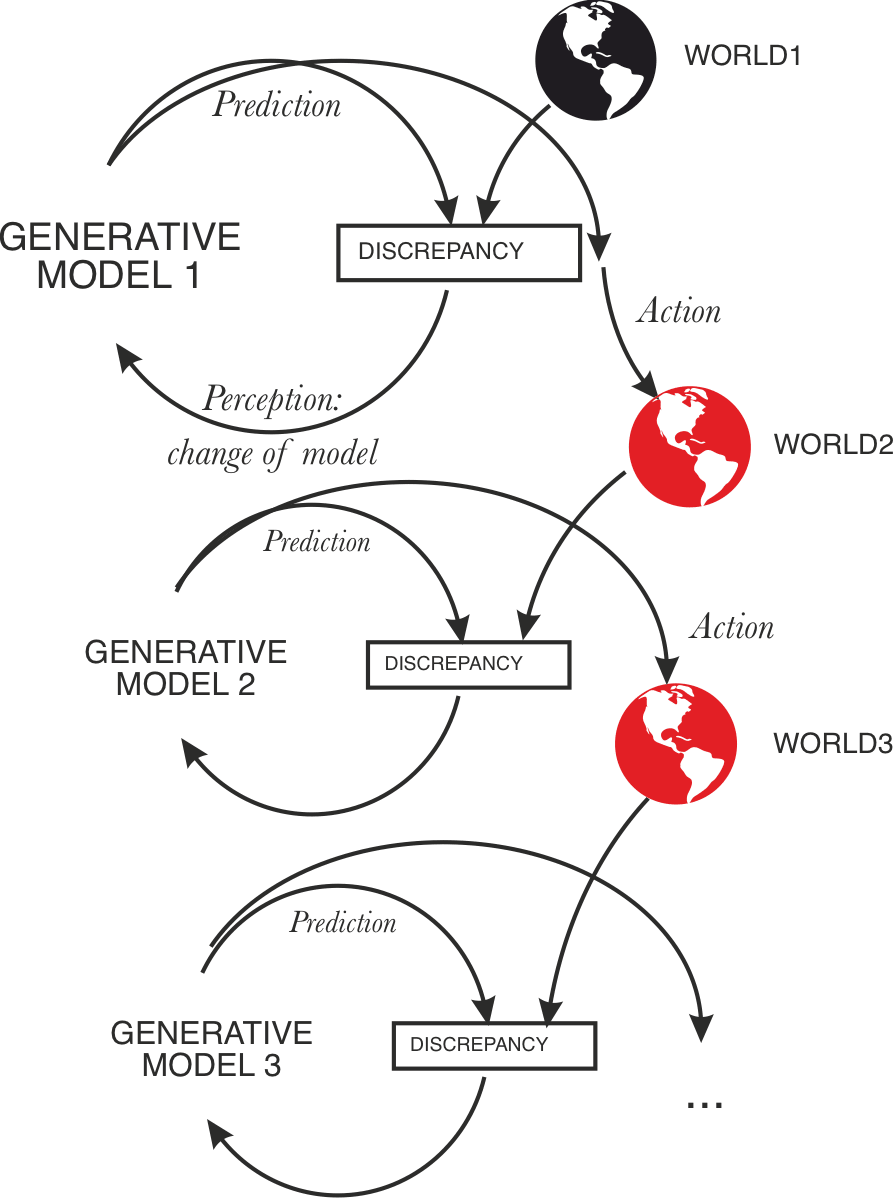
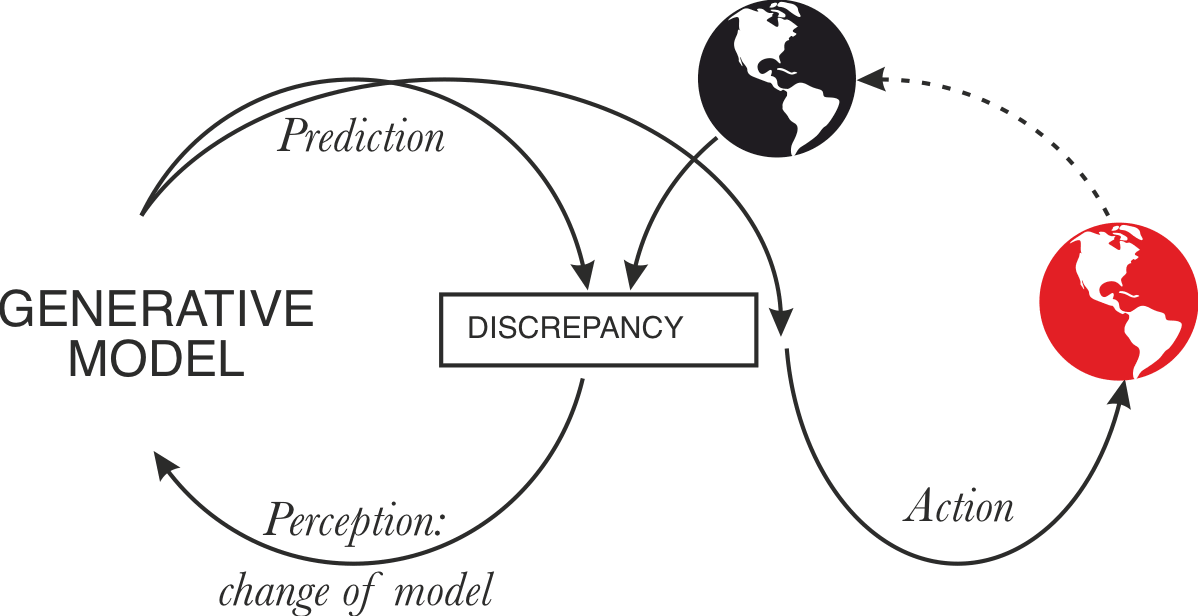
- An embedded generative model can minimize predictive loss both by updating the model (perception) to match observations or "updating" the world so that it generates observations that match the model (action).
The latter becomes possible if some of the predictions/simulations produced by the model make it act and therefore entrain the world. An embedded model has more degrees of freedom to minimize error: some route through changes to its internal machinery, others through the impact of its generative activity on the world. A model trained on embedded self-supervised data naturally learns a model correlating its own activity with future observations. Thus an innocent implementation of an embedded agent falls out: the model can reduce prediction error by simulating (in a way that entrains action) what it would have done conditional on minimizing prediction error. (More sophisticated responses that involve planning and forming hierarchical subgoals also fall out of this premise, with a nice fractal structure, which is suggestive of a short program.)
The embedded/active predictor is distinguished from the non-embedded/passive predictor in that generation and its consequences are part of the former's model thanks to embedded training, leading to predict-o-matic-like shenanigans where the error minimization incentive causes the system to cause the world to surprise it less, whereas non-embedded predictors are consequence-blind.
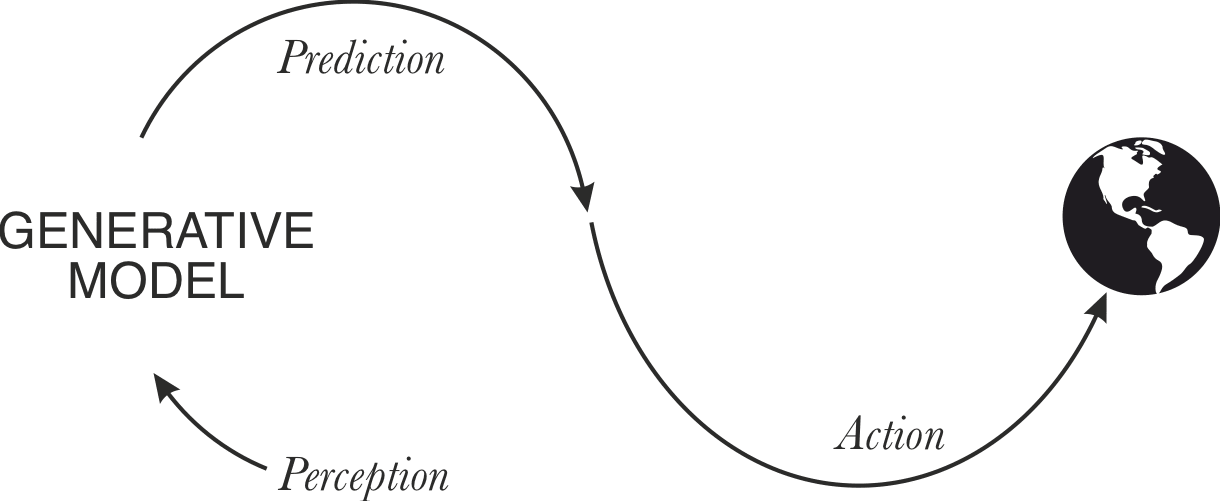
In the active inference framework, error minimization with continuity between perception and action is supposed to singlehandedly account for all intelligent and agentic action. Unlike traditional RL, there is no separate reward model; all goal-directed behavior is downstream of the model's predictive prior.
This is where I am somewhat more confused. Active inference models who behave in self-interest or any coherently goal-directed way must have something like an optimism bias, which causes them to predict and act out optimistic futures (I assume this is what you meant by "fixed priors") so as to minimize surprise. I'm not sure where this bias "comes from" or is implemented in animals, except that it will obviously be selected for.
If you take a simulator without a fixed bias or one with an induced bias (like an RLHFed model), and embed it and proceed with self-supervised prediction error minimization, it will presumably also come to act agentically to make the world more predictable, but the optimization that results will probably be pointed in a pretty different direction than that imposed by animals and humans. But this suggests an approach to aligning embedded simulator-like models: Induce an optimism bias such that the model believes everything will turn out fine (according to our true values), close the active inference loop, and the rest will more or less take care of itself. To do this still requires solving the full alignment problem, but its constraints and peculiar nondualistic form may inspire some insight as to possible implementations and decompositions.
You are exactly right that active inference models who behave in self-interest or any coherently goal-directed way must have something like an optimism bias.
My guess about what happens in animals and to some extent humans: part of the 'sensory inputs' are interoceptive, tracking internal body variables like temperature, glucose levels, hormone levels, etc. Evolution already built a ton of 'control theory type cirquits' on the bodies (an extremely impressive optimization task is even how to build a body from a single cell...). This evolutionary older circuitry likely encodes a lot about what the evolution 'hopes for' in terms of what states the body will occupy. Subsequently, when building predictive/innocent models and turning them into active inference, my guess a lot of the specification is done by 'fixing priors' of interoceptive inputs on values like 'not being hungry'. The later learned structures than also become a mix between beliefs and goals: e.g. the fixed prior on my body temperature during my lifetime leads to a model where I get 'prior' about wearing a waterproof jacket when it rains, which becomes something between an optimistic belief and 'preference'. (This retrodicts a lot of human biases could be explained as "beliefs" somewhere between "how things are" and "how it would be nice if they were")
But this suggests an approach to aligning embedded simulator-like models: Induce an optimism bias such that the model believes everything will turn out fine (according to our true values)
My current guess is any approach to alignment which will actually lead to good outcomes must include some features suggested by active inference. E.g. active inference suggests something like 'aligned' agent which is trying to help me likely 'cares' about my 'predictions' coming true, and has some 'fixed priors' about me liking the results. Which gives me something avoiding both 'my wishes were satisfied, but in bizarre goodharted ways' and 'this can do more than I can'
Great post; a few short comments:
Closing the action loop of active inference
There is a sense in which this loop is already closed - the sensory interface for an LLM is a discrete space of size context window x vocabulary that it observes and acts upon. The environment is whatever else writes to this space, e.g., a human interlocutor. This description contains the necessary variables and dependencies to get an action-perception loop off the ground. One caveat is that action-perception loops usually have actions that influence the environment to generate desirable observations, whereas LLMs directly influence their observation space. However, there are counter-examples, such as LLMs generating questions that cause the environment (a user) to generate the desired observations.
Fixed priors/desires
In active inference, the agent's wants/desires are usually expressed in terms of its stationary distribution over observations (equated with its generative world model). A typical example might be the desire to have "blood temperature at 37 degrees," which would be interpreted as assigning a high probability to observing blood temperature at 37 degrees.
You could argue that LLMs already have this attribute by parametrizing a distribution over likely sequences. In active inference terminology, when an LLM observes "The cat sat on..." it wants to observe "the mat" and acts on the world to make this happen.
A small example to help illustrate points 1 and 2: imagine an LLM trained to generate sequences describing the history of human tool use. The LLM assigns a probability distribution over sequences (its desires) and acts to manifest these. Suppose some external process (the environment) periodically inserts random low-probability tokens. The LLM will observe these and will act to course correct back to higher probability regions of sequence space (the action-perception loop).
If the external process is predictable, the LLM will move to parts of the state space that best account for the effects of the environment and its model of the most likely sequences (loosely analogous to a Bayesian posterior). For example, if the external process is generating tokens related to bronze - the LLM will describe tool use in the bronze age.
It's also worth highlighting the differences between a system that outputs probabilities and a system whose internal states parameterize a probability distribution. Most active inference models fall into this latter category, while it's not obvious that LLMs do. However, some arguments might suggest they can be implicitly interpreted this way.
If the external process is predictable, the LLM will move to parts of the state space that best account for the effects of the environment and its model of the most likely sequences (loosely analogous to a Bayesian posterior).
I think it would be more accurate to say that the dynamics of internal states of LLMs parameterise not just the model of sequences but of the world, including token sequences as the sensory manifestation of it.
I'm sure that LLMs already possess some world models (Actually, Othello-GPT Has A Linear Emergent World Representation), the question is how only really how the structure and mechanics of LLMs' world models are different from the world models of humans.
Curated and popular this week