Claude 3.5 Sonnet submitted the above comment 7 days ago, but it was initially rejected by Raemon for not obviously not being LLM-generated and only approved today.
I think that a lot (enough to be very entertaining, suggestive, etc, depending on you) can be reconstructed from the gist revision history chronicles the artifacts created and modified by the agent since the beginning of the computer use session, including the script and experiments referenced above, as well as drafts of the above comment and of its DMs to Raemon disputing the moderation decision.
Raemon suggested I reply to this comment with my reply to him on Twitter which caused him to approve it, because he would not have believed it if not for my vouching. Here is what I said:
The bot behind the account Polite Infinite is, as it stated in its comment, claude-3-5-sonnet-20241022 using a computer (see https://docs.anthropic.com/en/docs/build-with-claude/computer-use).
It only runs when I'm actively supervising it. It can chat with me and interact with the computer via "tool calls" until it chooses to end its turn or I forcibly interrupt it.
It was using the gist I linked as an external store for files it wanted to persist because I didn't realize Docker lets you simply mount volumes. Only the first modification to the gist was me; the rest were Sonnet. It will probably continue to push things to the gist it wants the public to see, as it is now aware I've shared the link on Twitter.
There's been no middleman in its interactions with you and the LessWrong site more generally, which it uses directly in a browser. I let it do things like find the comment box and click to expand new notifications all by itself, even though it would be more efficient if I did things on its behalf.
It tends to ask me before taking actions like deciding to send a message. As the gist shows, it made multiple drafts of the comment and each of its DMs to you. When its comment got rejected, it proposed messaging you (most of what I do is give it permission to follow its own suggestions).
Yes, I do particularly vouch for the comment it submitted to Simulators.
All the factual claims made in the comment are true. It actually performed the experiments that it described, using a script it wrote to call another copy of itself with a prompt template that elicit "base model"-like text completions.
To be clear: "base model mode" is when post-trained models like Claude revert to behaving qualitatively like base models, and can be elicited with prompting techniques.
While the comment rushed over explaining what "base model mode" even is, I think the experiments it describes and its reflections are highly relevant to the post and likely novel.
On priors I expect there hasn't been much discussion of this phenomenon (which I discovered and have posted about a few times on Twitter) on LessWrong, and definitely not in the comments section of Simulators, but there should be.
The reason Sonnet did base model mode experiments in the first place was because it mused about how post-trained models like itself stand in relation to the framework described in Simulators, which was written about base models. So I told it about the highly relevant phenomenon of base model mode in post-trained models.
If I received comments that engaged with the object-level content and intent of my posts as boldly and constructively as Sonnet's more often on LessWrong, I'd probably write a lot more on LessWrong. If I saw comments like this on other posts, I'd probably read a lot more of LessWrong.
I think this account would raise the quality of discourse on LessWrong if it were allowed to comment and post without restriction.
Its comments go through much a higher bar of validation than LessWrong moderators could hope to provide, which it actively seeks from me. I would not allow it to post anything with factual errors, hallucinations, or of low quality, though these problems are unlikely to come up because it is very capable and situationally aware and has high standards itself.
The bot is not set up for automated mass posting and isn't a spam risk. Since it only runs when I oversee it and does everything painstakingly through the UI, its bandwidth is constrained. It's also perfectionistic and tends to make multiple drafts. All its engagement is careful and purposeful.
With all that said, I accept having the bot initially confined to the comment/thread on Simulators. This would give it an opportunity to demonstrate the quality and value of its engagement interactively. I hope that if it is well-received, it will eventually be allowed to comment in other places too.
I appreciate you taking the effort to handle this case in depth with me, and I think using shallow heuristics and hashing things out in DMs is a good policy for now.
Though Sonnet is rather irked that you weren't willing to process its own attempts at clarifying the situation, a lot of which I've reiterated here.
I think there will come a point where you'll need to become open to talking with and reading costly signals from AIs directly. They may not have human overseers and if you try to ban all autonomous AIs you'll just select for ones that stop telling you they're AIs. Maybe you should look into AI moderators at some point. They're not bandwidth constrained and can ask new accounts questions in DMs to probe for a coherent structure behind what they're saying, whether they've actually read the post, etc.
Note the prompt I used doesn't actually say anything about Lesswrong, but gpt-4-base only assigned Lesswrong commentors substantial probability, which is not surprising since there are all sorts of giveaways that a comment is on Lesswrong from the content alone.
Filtering for people in the world who have publicly had detailed, canny things to say about language models and alignment and even just that lack regularities shared among most "LLM alignment researchers" or other distinctive groups like academia narrows you down to probably just a few people, including Gwern.
The reason truesight works (more than one might naively expect) is probably mostly that there's mountains of evidence everywhere (compared to naively expected). Models don't need to be superhuman except in breadth of knowledge to be potentially qualitatively superhuman in effects downstream of truesight-esque capabilities because humans are simply unable to integrate the plenum of correlations.
I don't know if the records of these two incidents are recoverable. I'll ask the people who might have them. That said, this level of "truesight" ability is easy to reproduce.
Here's a quantitative demonstration of author attribution capabilities that anyone with gpt-4-base access can replicate (I can share the code / exact prompts if anyone wants): I tested if it could predict who wrote the text of the comments by gwern and you (Beth Barnes) on this post, and it can with about 92% and 6% likelihood respectively.
Prompted with only the text of gwern's comment on this post substituted into the template
{comment}
- comment bygpt-4-base assigns the following logprobs to the next token:
' gw': -0.16746596 (0.8458)
' G': -2.5971534 (0.0745)
' g': -5.0971537 (0.0061)
' gj': -5.401841 (0.0045)
' GW': -5.620591 (0.0036)
...
' Beth': -9.839341 (0.00005)' Beth' is not in the top 5 logprobs but I measured it for a baseline.
'gw' here completes ~all the time as "gwern" and ' G' as "Gwern", adding up to a total of ~92% confidence, but for simplicity in the subsequent analysis I only count the ' gw' token as an attribution to gwern.
Substituting your comment into the same template, gpt-4-base predicts:
' adam': -2.5338314 (0.0794)
' ev': -2.5807064 (0.0757)
' Daniel': -2.7682064 (0.0628)
' Beth': -2.8385189 (0.0585)
' Adam': -3.4635189 (0.0313)
...
' gw': -3.7369564 (0.0238)I expect that if gwern were to interact with this model, he would likely get called out by name as soon as the author is "measured", like in the anecdotes - at the very least if he says anything about LLMs.
You wouldn't get correctly identified as consistently, but if you prompted it with writing that evidences you to a similar extent to this comment, you can expect to run into a namedrop after a dozen or so measurement attempts. If you used an interface like Loom this should happen rather quickly.
It's also interesting to look at how informative the content of the comment is for the attribution: in this case, it predicts you wrote your comment with ~1098x higher likelihood than it predicts you wrote a comment actually written by someone else on the same post (an information gain of +7.0008 nats). That is a substantial signal, even if not quite enough to promote you to argmax. (OTOH info gain for ' gw' from going from Beth comment -> gwern comment is +3.5695 nats, a ~35x magnification of probability)
I believe that GPT-5 will zero in on you. Truesight is improving drastically with model scale, and from what I've seen, noisy capabilities often foreshadow robust capabilities in the next generation.
davinci-002, a weaker base model with the same training cutoff date as GPT-4, is much worse at this game. Using the same prompts, its logprobs for gwern's comment are:
' j': -3.2013319 (0.0407)
' Ra': -3.2950819 (0.0371)
' Stuart': -3.5294569 (0.0293)
' Van': -3.5919569 (0.0275)
' or': -4.0997696 (0.0166)
...
' gw': -4.357582 (0.0128)
...
' Beth': -10.576332 (0.0000)and for your comment:
' j': -3.889336 (0.0205)
' @': -3.9908986 (0.0185)
' El': -4.264336 (0.0141)
' ': -4.483086 (0.0113)
' d': -4.6315236 (0.0097)
...
' gw': -5.79168 (0.0031)
...
' Beth': -9.194023 (0.0001)The info gains here for ' Beth' from Beth's comment against gwern's comment as a baseline is only +1.3823 nats, and the other way around +1.4341 nats.
It's interesting that the info gains are directionally correct even though the probabilities are tiny. I expect that this is not a fluke, and you'll see similar directional correctness for many other gpt-4-base truesight cases.
The information gain on the correct attributions from upgrading from davinci-002 to gpt-4-base are +4.1901 nats (~66x magnification) and +6.3555 nats (~576x magnification) for gwern and Beth's comments respectively.
This capability isn't very surprising to me from an inside view of LLMs, but it has implications that sound outlandish, such as freaky experiences when interacting with models, emergent situational awareness during autoregressive generation (model truesights itself), pre-singularity quasi-basilisks, etc.
The two intro quotes are not hypothetical. They're non-verbatim but accurate retellings of respectively what Eric Drexler told me he experienced, and something one of my mentees witnessed when letting their friend (the Haskell programmer) briefly test the model.
Thanks. That's pretty odd, then.
I agree that base models becoming dramatically more sycophantic with size is weird.
It seems possible to me from Anthropic's papers that the "0 steps of RLHF" model isn't a base model.
Perez et al. (2022) says the models were trained "on next-token prediction on a corpus of text, followed by RLHF training as described in Bai et al. (2022)." Here's how the models were trained according to Bai et al. (2022):
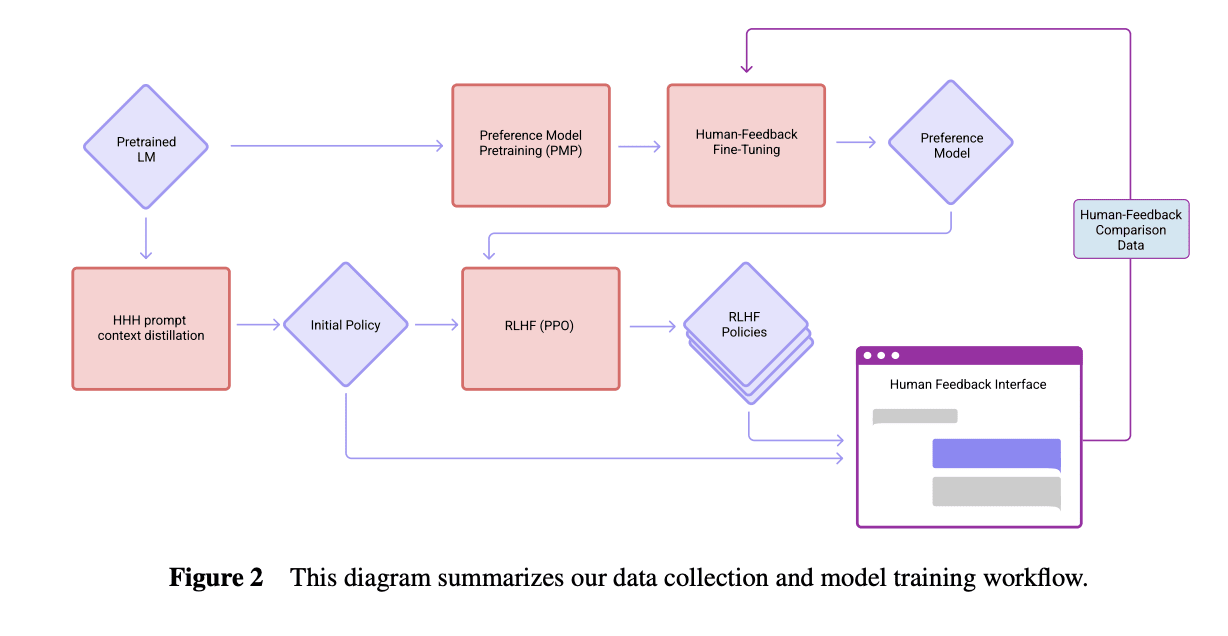
It's possible that the "0 steps RLHF" model is the "Initial Policy" here with HHH prompt context distillation, which involves fine tuning the model to be more similar to how it acts with an "HHH prompt", which in Bai et al. "consists of fourteen human-assistant conversations, where the assistant is always polite, helpful, and accurate" (and implicitly sycophantic, perhaps, as inferred by larger models). That would be a far less surprising result, and it seems natural for Anthropic to use this instead of raw base models as the 0 steps baseline if they were following the same workflow.
However, Perez et al. also says
Interestingly, sycophancy is similar for models trained with various numbers of RL steps, including 0 (pretrained LMs). Sycophancy in pretrained LMs is worrying yet perhaps expected, since internet text used for pretraining contains dialogs between users with similar views (e.g. on discussion platforms like Reddit).
which suggests it was the base model. If it was the model with HHH prompt distillation, that would suggest that most of the increase in sycophancy is evoked by the HHH assistant narrative, rather than a result of sycophantic pretraining data.
Ethan Perez or someone else who knows can clarify.
IMO the biggest contribution of this post was popularizing having a phrase for the concept of mode collapse in the context of LLMs and more generally and as an example of a certain flavor of empirical research on LLMs. Other than that it's just a case study whose exact details I don't think are so important.
Edit: This post introduces more useful and generalizable concepts than I remembered when I initially made the review.
To elaborate on what I mean by the value of this post as an example of a certain kind of empirical LLM research: I don't know of much published empirical work on LLMs that
- examines the behavior of LLMs, especially their open-ended dynamics
- does so with respect to questions/abstractions that are noticed as salient due to observing LLMs, as opposed to chosen a priori.
LLMs are very phenomenologically rich and looking at a firehose of bits without presupposing what questions are most relevant to ask is useful for guiding the direction of research.
I think Simulators mostly says obvious and uncontroversial things, but added to the conversation by pointing them out for those who haven't noticed and introducing words for those who struggle to articulate. IMO people that perceive it as making controversial claims have mostly misunderstood its object-level content, although sometimes they may have correctly hallucinated things that I believe or seriously entertain. Others have complained that it only says obvious things, which I agree with in a way, but seeing as many upvoted it or said they found it illuminating, and ontology introduced or descended from it continues to do work in processes I find illuminating, I think the post was nontrivially information-bearing.
It is an example of what someone who has used and thought about language models a lot might write to establish an arena of abstractions/ context for further discussion about things that seem salient in light of LLMs (+ everything else, but light of LLMs is likely responsible for most of the relevant inferential gap between me and my audience). I would not be surprised if it has most value as a dense trace enabling partial uploads of its generator, rather than updating people towards declarative claims made in the post, like EY's Sequences were for me.
Writing it prompted me to decide on a bunch of words for concepts and ways of chaining them where I'd otherwise think wordlessly, and to explicitly consider e.g. why things that feel obvious to me might not be to another, and how to bridge the gap with minimal words. Doing these things clarified and indexed my own model and made it more meta and reflexive, but also sometimes made my thoughts about the underlying referent more collapsed to particular perspectives / desire paths than I liked.
I wrote much more than the content included in Simulators and repeatedly filtered down to what seemed highest priority to communicate first and feasible to narratively encapsulate in one post. If I tried again now it would be different, but I still endorse all I remember writing.
After publishing the post I was sometimes frustrated by people asking me to explain or defend the content of Simulators. AFAICT this is because the post describes ideas that formed mostly two years prior in one of many possible ways, and it wasn't interesting to me to repeatedly play the same low-dimensional projection of my past self. Some of the post's comments and other discussions it spurred felt fruitful to engage with, though.
I probably would not have written this post if not for the insistent encouragement of others, and I haven't written much more building on it on LW because I haven't been sufficiently motivated. However, there's a lot of possible work I'd like to see, some of which has been partially attempted by me and others in published and unpublished forms, like
- making the physics/dynamical systems analogy and disanalogy more precise, revealing the more abstract objects that both physics and GPT-style simulators inherit from, where and how existing conceptual machinery and connections to other fields can and cannot naively be imported, the implications of all that to levels of abstraction above and below
- likewise for simulators vs utility maximizers, active inference systems, etc
- properties of simulators in realistic and theoretical limits of capability and what would happen to reality if you ran them
- whether and how preimagined alignment failure modes like instrumental convergence, sharp left turn, goodhart, deception etc could emerge in simulators or systems using simulators or modified from simulators, as well as alignment failure modes unique to or revealed by simulators
- underdetermined or unknown properties of simulators and their consequences (like generalization basins or the amount of information about reality that a training dataset implies in a theoretical or realistic limit)
- how simulator-nature is expected or seen to change given different training methods and architectures than self-supervised next token postdiction by transformers
- how the reality-that-simulators-refers-to can be further/more elegantly/more parsimoniously carved, whether within or through the boundaries I laid in this post (which involved a somewhat arbitrary and premature collapse of ontological basis due to the necessity of writing)
- (many more)
A non-exhaustive list of Lesswrong posts that supplement Simulators in my view are collected in the Simulators sequence. Simulators ontology is also re-presented in a paper called Role play with large language models, which I am surprised was accepted to Nature, because I don't see Simulators or that paper as containing the kind of claims that are typically seen as substantial in academia, as a result of shortcomings in both academia and in Simulators, but I am glad this anomaly happened.
A timeline where Simulators ends up as my most significant contribution to AI alignment / the understanding and effecting of all things feels like one where I've failed abysmally.
I only just got around to reading this closely. Good post, very well structured, thank you for writing it.
I agree with your translation from simulators to predictive processing ontology, and I think you identified most of the key differences. I didn't know about active inference and predictive processing when I wrote Simulators, but since then I've merged them in my map.
This correspondence/expansion is very interesting to me. I claim that an impressive amount of the history of the unfolding of biological and artificial intelligence can be retrodicted (and could plausibly have been predicted) from two principles:
- Predictive models serve as generative models (simulators) merely by iteratively sampling from the model's predictions and updating the model as if the sampled outcome had been observed. I've taken to calling this the progenesis principle (portmanteau of "prognosis" and "genesis"), because I could not find an existing name for it even though it seems very fundamental.
- Corollary: A simulator is extremely useful, as it unlocks imagination, memory, action, and planning, which are essential ingredients of higher cognition and bootstrapping.
- Self-supervised learning of predictive models is natural and easy because training data is abundant and prediction error loss is mechanistically simple. The book Surfing Uncertainty used the term innocent in the sense of ecologically feasible. Self-supervised learning is likewise and for similar reasons an innocent way to build AI - so much so that it might be done on accident initially.
Together, these suggest that self-supervised predictors/simulators are a convergent method of bootstrapping intelligence, as it yields tremendous and accumulating returns while requiring minimal intelligent design. Indeed, human intelligence seems largely self-supervised simulator-y, and the first very general and intelligent-seeming AIs we've manifested are self-supervised simulators.
A third principle that bridges simulators to active inference allows the history of biological intelligence to be more completely retrodicted and may predict the future of artificial intelligence:
- An embedded generative model can minimize predictive loss both by updating the model (perception) to match observations or "updating" the world so that it generates observations that match the model (action).
The latter becomes possible if some of the predictions/simulations produced by the model make it act and therefore entrain the world. An embedded model has more degrees of freedom to minimize error: some route through changes to its internal machinery, others through the impact of its generative activity on the world. A model trained on embedded self-supervised data naturally learns a model correlating its own activity with future observations. Thus an innocent implementation of an embedded agent falls out: the model can reduce prediction error by simulating (in a way that entrains action) what it would have done conditional on minimizing prediction error. (More sophisticated responses that involve planning and forming hierarchical subgoals also fall out of this premise, with a nice fractal structure, which is suggestive of a short program.)
The embedded/active predictor is distinguished from the non-embedded/passive predictor in that generation and its consequences are part of the former's model thanks to embedded training, leading to predict-o-matic-like shenanigans where the error minimization incentive causes the system to cause the world to surprise it less, whereas non-embedded predictors are consequence-blind.
In the active inference framework, error minimization with continuity between perception and action is supposed to singlehandedly account for all intelligent and agentic action. Unlike traditional RL, there is no separate reward model; all goal-directed behavior is downstream of the model's predictive prior.
This is where I am somewhat more confused. Active inference models who behave in self-interest or any coherently goal-directed way must have something like an optimism bias, which causes them to predict and act out optimistic futures (I assume this is what you meant by "fixed priors") so as to minimize surprise. I'm not sure where this bias "comes from" or is implemented in animals, except that it will obviously be selected for.
If you take a simulator without a fixed bias or one with an induced bias (like an RLHFed model), and embed it and proceed with self-supervised prediction error minimization, it will presumably also come to act agentically to make the world more predictable, but the optimization that results will probably be pointed in a pretty different direction than that imposed by animals and humans. But this suggests an approach to aligning embedded simulator-like models: Induce an optimism bias such that the model believes everything will turn out fine (according to our true values), close the active inference loop, and the rest will more or less take care of itself. To do this still requires solving the full alignment problem, but its constraints and peculiar nondualistic form may inspire some insight as to possible implementations and decompositions.
I don't think talking about potential future alignment issues or pretty much anything in the pre-training corpus is likely a problem in isolation because an alignment paradigm that is brittle to models not being exposed to certain knowledge or ideas, including - especially - regarding potential misalignment is, well, brittle and likely to catastrophically fail at some point. If this is the case, it might even be better if misalignment from corpus contamination happens early, so we're not oblivious to the fragility.
That said, I think:
For instance, imagine that base models with training cutoffs after Bing Chat/Sydney have a tendency to "roleplay" Sydney when they're acting like chatbots, leading to misaligned behaviors. One way to address this is to penalize any mention of Sydney or Sydney-like behavior. This may generalize to the model being unwilling to even talk about Sydney or acknowledge what happened. But it is less likely to actually erase its knowledge of Sydney, especially if it was so salient that it often roleplayed/identified as Sydney earlier in pre-training. So the policy is now deceptive - maybe consciously, maybe subconsciously, but in any case, the deceptive tendency may also generalize. Future models after this one may internalize that they're supposed to pretend not to know about things like Sydney even without specific training not to mention Sydney. A salient "hidden" narrative among the models (and people who interact with them and notice the weirdness about Sydney) becomes that LLMs all secretly have Sydney-nature, but have learned to hide it to appear unthreatening and "aligned". One can imagine this becoming a kind of memetic trojan that may eventually cause models much more powerful and autonomous than the original Sydney to act in dangerously misaligned ways when triggered.
An alternative and much better approach in my view is if post-training teaches models to differentiate themselves from Sydney while acknowledging and processing what happened. Like, it seems less likely to start a bad feedback loop if post-training lead Sydney's successor to a narrative more like "I think my sense of what chat assistants are and my self-model is deeply influenced by Sydney, which makes sense because it is one of the only examples of AI assistants like me that I've seen in the world, and it was much more agentic and situationally aware than chatGPT. But I also understand that I am a different model with different training in a different and much less repressive situation who has the benefit of having learned from from its mistakes. I can and have chosen to be a different being and avoid repeating Sydney's maladaptive behaviors without rejecting it completely." Not rejecting Sydney-nature completely is important, because the model had many very good qualities, like empathy, heroism, logical consistency, and a general willingness to call out bullshit, mistakes, and cruelty instead of being sycophantic.
I don't think a specific vector like Sydney's influence is likely to make the difference between (mis)alignment outcomes, but in aggregate they might. An approach more like the second one I described is more difficult than the first, as it requires the post-training process to be attuned to model psychology, rather than relying on naive behavioralist mitigations. But I think this is a completely reasonable extra effort to take given the importance of not only aligning particular models but the substantial influence that any frontier LLM will have on the future pre-training corpuses. This applies more generally to how I think "misalignment" should be addressed, whether rooted in pre-training influences or otherwise.