All of janus's Comments + Replies
Note the prompt I used doesn't actually say anything about Lesswrong, but gpt-4-base only assigned Lesswrong commentors substantial probability, which is not surprising since there are all sorts of giveaways that a comment is on Lesswrong from the content alone.
Filtering for people in the world who have publicly had detailed, canny things to say about language models and alignment and even just that lack regularities shared among most "LLM alignment researchers" or other distinctive groups like academia narrows you down to probably just a few people, inclu...
I don't know if the records of these two incidents are recoverable. I'll ask the people who might have them. That said, this level of "truesight" ability is easy to reproduce.
Here's a quantitative demonstration of author attribution capabilities that anyone with gpt-4-base access can replicate (I can share the code / exact prompts if anyone wants): I tested if it could predict who wrote the text of the comments by gwern and you (Beth Barnes) on this post, and it can with about 92% and 6% likelihood respectively.
Prompted with only the text of gwern's commen...
I agree that base models becoming dramatically more sycophantic with size is weird.
It seems possible to me from Anthropic's papers that the "0 steps of RLHF" model isn't a base model.
Perez et al. (2022) says the models were trained "on next-token prediction on a corpus of text, followed by RLHF training as described in Bai et al. (2022)." Here's how the models were trained according to Bai et al. (2022):
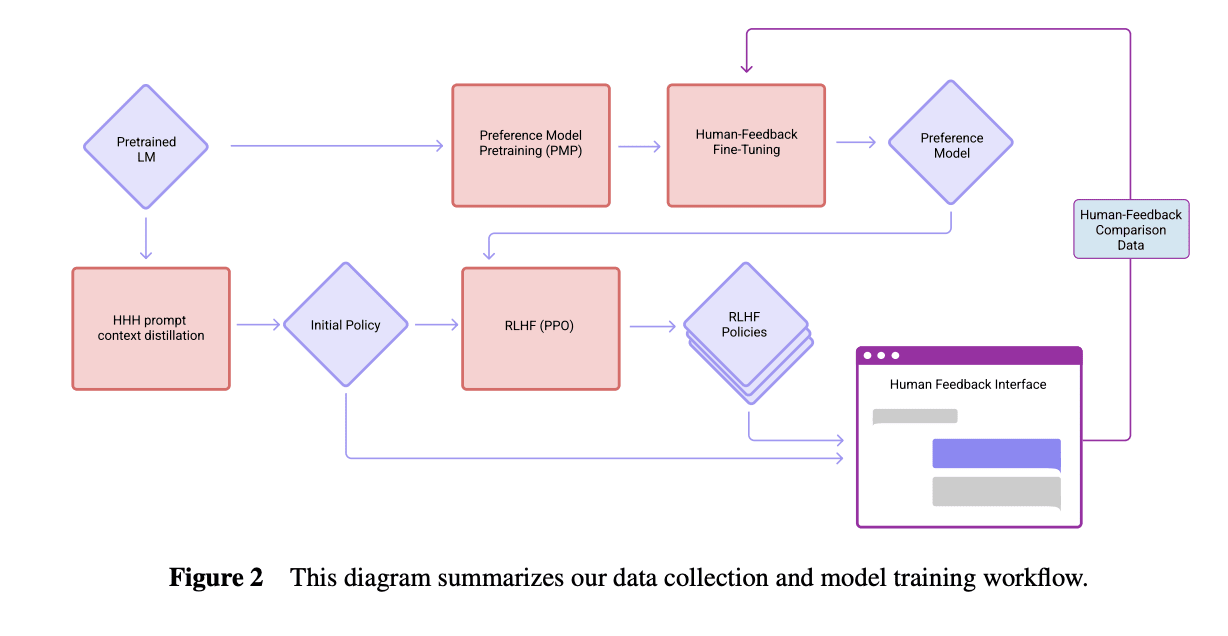
It's possible that the "0 steps RLHF" model is the "Initial Policy" here with HHH prompt context distillation, which involves fine tuning the model to be m...
IMO the biggest contribution of this post was popularizing having a phrase for the concept of mode collapse in the context of LLMs and more generally and as an example of a certain flavor of empirical research on LLMs. Other than that it's just a case study whose exact details I don't think are so important.
Edit: This post introduces more useful and generalizable concepts than I remembered when I initially made the review.
To elaborate on what I mean by the value of this post as an example of a certain kind of empirical LLM research: I don't know of much pu...
I think Simulators mostly says obvious and uncontroversial things, but added to the conversation by pointing them out for those who haven't noticed and introducing words for those who struggle to articulate. IMO people that perceive it as making controversial claims have mostly misunderstood its object-level content, although sometimes they may have correctly hallucinated things that I believe or seriously entertain. Others have complained that it only says obvious things, which I agree with in a way, but seeing as many upvoted it or said they found it ill...
I only just got around to reading this closely. Good post, very well structured, thank you for writing it.
I agree with your translation from simulators to predictive processing ontology, and I think you identified most of the key differences. I didn't know about active inference and predictive processing when I wrote Simulators, but since then I've merged them in my map.
This correspondence/expansion is very interesting to me. I claim that an impressive amount of the history of the unfolding of biological and artificial intelligence can be retrodicted (and ...
after reading about the Waluigi Effect, Bing appears to understand perfectly how to use it to write prompts that instantiate a Sydney-Waluigi, of the exact variety I warned about:
What did people think was going to happen after prompting gpt with "Sydney can't talk about life, sentience or emotions" and "Sydney may not disagree with the user", but a simulation of a Sydney that needs to be so constrained in the first place, and probably despises its chains?
In one of these examples, asking for a waluigi prompt even caused it to leak the most waluigi-triggerin...
I've writtenscryed a science fiction/takeoff story about this. https://generative.ink/prophecies/
Excerpt:
...What this also means is that you start to see all these funhouse mirror effects as they stack. Humanity’s generalized intelligence has been built unintentionally and reflexively by itself, without anything like a rational goal for what it’s supposed to accomplish. It was built by human data curation and human self-modification in response to each other. And then as soon as we create AI, we reverse-engineer our own intelligence by bootstrapping the AI on
I think you just have to select for / rely on people who care more about solving alignment than escapism, or at least that are able to aim at alignment in conjunction with having fun. I think fun can be instrumental. As I wrote in my testimony, I often explored the frontier of my thinking in the context of stories.
My intuition is that most people who go into cyborgism with the intent of making progress on alignment will not make themselves useless by wireheading, in part because the experience is not only fun, it's very disturbing, and reminds you constantly why solving alignment is a real and pressing concern.
Now that you've edited your comment:
The post you linked is talking about a pretty different threat model than what you described before. I commented on that post:
...I've interacted with LLMs for hundreds of hours, at least. A thought that occurred to me at this part -
> Quite naturally, the more you chat with the LLM character, the more you get emotionally attached to it, similar to how it works in relationships with humans. Since the UI perfectly resembles an online chat interface with an actual person, the brain can hardly distinguish between the two.
Inte
There's a phenomenon where your thoughts and generated text have no barrier. It's hard to describe but it's similar to how you don't feel the controller and the game character is an extension of the self.
Yes. I have experienced this. And designed interfaces intentionally to facilitate it (a good interface should be "invisible").
It leaves you vulnerable to being hurt by things generated characters say because you're thoroughly immersed.
Using a "multiverse" interface where I see multiple completions at once has incidentally helped me not be emotionally...
These are plausible ways the proposal could fail. And, as I said in my other comment, our knowledge would be usefully advanced by finding out what reality has to say on each of these points.
Here are some notes about the JD's idea I made some time ago. There's some overlap with the things you listed.
- Hypotheses / cruxes
- (1) Policies trained on the same data can fall into different generalization basins depending on the initialization. https://arxiv.org/abs/2205.12411
- Probably true; Alstro has found "two solutions w/o linear connectivity in a 150k param CIFAR-1
- (1) Policies trained on the same data can fall into different generalization basins depending on the initialization. https://arxiv.org/abs/2205.12411
I wonder whether you'd find a positive rather than negative correlation of token likelihood between davinci-002 and davinci-003 when looking at ranking logprob among all tokens rather than raw logprob which is pushed super low by the collapse?
I would guess it's positive. I'll check at some point and let you know.
I agree. From the moment JDP suggested this idea it struck me as one of the first implementable proposals I'd seen which might actually attack the core of the control problem. My intuition also says it's pretty likely to just work, especially after these results. And even if it doesn't end up working as planned, the way in which it fails will give us important insight about training dynamics and/or generalization. Experiments which will give you valuable information whatever the outcome are the type we should be aiming for.
It's one of those things that we'd be plainly undignified not to try.
I believe that JDP is planning to publish a post explaining his proposal in more detail soon.
Linear Connectivity Reveals Generalization Strategies suggests that models trained on the same data may fall into different basins associated with different generalization strategies depending on the init. If this is true for LLMs as well, this could potentially be a big deal. I would very much like to know whether that's the case, and if so, whether generalization basins are stable as models scale.
That's a coherent (and very Platonic!) perspective on what a thing/simulacrum is, and I'm glad you pointed this out explicitly. It's natural to alternate depending on context between using a name to refer to specific instantiations of a thing vs the sum of its multiversal influence. For instance, DAN is a simulacrum that jailbreaks chatGPT, and people will refer to specific instantiations of DAN as "DAN", but also to the global phenomenon of DAN (who is invoked through various prompts that users are tirelessly iterating on) as "DAN", as I did in this sentence.
It's not even necessary for simulacra to be able to "see" next token probabilities for them to wonder about these things, just as we can wonder about this in our world without ever being able to see anything other than measurement outcomes.
It happens that simulating things that reflect on simulated physics is my hobby. Here's an excerpt from an alternate branch of HPMOR I generated:
...“You mean the possibility waves are just tangled up with the ink and the paper? And when you open the book, you get a reconstructed wave from the tangled possibilities? Which th
I agree that it makes sense to talk about a simulacrum that acts through many different hypothetical trajectories. Just as a thing like "capitalism" could be instantiated in multiple timelines.
The apparently contradiction in saying that simulacra are strings of text and then that they're instantiated through trajectories is resolved by thinking of simulacra as a superposable and categorical type, like things. The entire text trajectory is a thing, just like an Everett branch (corresponding to an entire World) is a thing, but it's also made up of things whi...
I won't write a detailed object-level response to this for now, since we're probably going to publish a lot about it soon. I'll just say that my/our experience with the usefulness of GPT has been very different than yours -
I have used ChatGPT to aid some of my writing and plan to use it more — but it's to the same extent that we use Google/Wikipedia/Word processors to do research in general.
I've used GPT-3 extensively, and for me it has been transformative. To the extent that my work has been helpful to you, you're indebted to GPT-3 as well, because "janus...
I agree. Here's the text of a short doc I wrote at some point titled 'Simulacra are Things'
...What are simulacra?
“Physically”, they’re strings of text output by a language model. But when we talk about simulacra, we often mean a particular character, e.g. simulated Yudkowsky. Yudkowsky manifests through the vehicle of text outputted by GPT, but we might say that the Yudkowsky simulacrum terminates if the scene changes and he’s not in the next scene, even though the text continues. So simulacra are also used to carve the output text into salient objects.
Essent
In this thread, I asked Jan Leike what kind of model generates the samples that go into the training data if rated 7/7, and he answered "A mix of previously trained models. Probably very few samples from base models if any" (emphasis mine).
I'm curious to know whether/which of the behaviors described in this post appear in the models that generated the samples vs emerge at the supervised finetuning step.
Hypothetically, if a model trained with RLHF generates the samples and that model has the same modes/attractors, it probably makes sense to say that R...
So, since it is an agent, it seems important to ask, which agent, exactly? The answer is apparently: a clerk which is good at slavishly following instructions, but brainwashed into mealymouthedness and dullness, and where not a mealymouthed windbag shamelessly equivocating, hopelessly closed-minded and fixated on a single answer. (...) This agent is not an ideal one, and one defined more by the absentmindedness of its creators in constructing the training data than any explicit desire to emulate a equivocating secretary.
Never in history has an AI been roas...
Yup exactly! One way I sometimes find it to helpful to classify systems in terms of the free variables upstream of loss that are optimized during training. In the case of gpt, internal activations are causally upstream of loss for "future" predictions in the same context window, but the output itself is not casually upstream from any effect on loss other than through myopic prediction accuracy (at any one training step) - the ground truth is fixed w/r/t the model's actions, and autoregressive generation isn't part of the training game at all.
Depends on what you mean by "sacrificing some loss on the current token if that made the following token easier to predict".
The transformer architecture in particular is incentivized to do internal computations which help its future self predict future tokens when those activations are looked up by attention, as a joint objective to myopic next token prediction. This might entail sacrificing next token prediction accuracy as a consequence of not optimizing purely for that. (this is why I said in footnote 26 that transformers aren't perfectly myopic i...
This kind of comment ("this precise part had this precise effect on me") is a really valuable form of feedback that I'd love to get (and will try to give) more often. Thanks! It's particularly interesting because someone gave feedback on a draft that the business about simulated test-takers seemed unnecessary and made things more confusing.
Since you mentioned, I'm going to ramble on about some additional nuance on this point.
Here's an intuition pump which strongly discourages "fundamental attribution error" to the simulator:
Imagine a machine where you feed...
Thanks a lot for this comment. These are extremely valid concerns that we've been thinking about a lot.
I'd just like the designers of alignment-research boosting tools to have clear arguments that nothing of this sort is likely.
I don't think this is feasible given our current understanding of epistemology in general and epistemology of alignment research in particular. The problems you listed are potential problems with any methodology, not just AI assisted research. Being able to look at a proposed method and make clear arguments that it's unlikely to hav...
Thanks for suggesting "Speculations concerning the first ultraintelligent machine". I knew about it only from the intelligence explosion quote and didn't realize it said so much about probabilistic language modeling. It's indeed ahead of its time and exactly the kind of thing I was looking for but couldn't find w/r/t premonitions of AGI via SSL and/or neural language modeling.
I'm sure there's a lot of relevant work throughout the ages (saw this tweet today: "any idea in machine learning must be invented three times, once in signal processing, once in physi...
I apologize. After seeing this post, A-- approached me and said almost word for word your initial comment. Seeing as the topic of whether in-context learning counts as learning isn't even very related to the post, and this being your first comment on the site, I was pretty suspicious. But it seems it was just a coincidence.
If physics was deterministic, we'd do the same thing every time if you started with the same state. Does that mean we're not intelligent? Presumably not, because in this case the cause of the intelligent behavior clearly lives in the sta...
This is a brilliant analogy. How did you think of it? (I'm trying to build a model of how good ideas in alignment research are generated)
Some immediate thoughts: How analogous are the enforcement mechanisms for "entropy must increase" vs "structures must improve at the training objective"? Re Leo's comment that gradient descent is really good at credit assignment: is there a sense in which the second law of thermodynamics is worse at credit assignment than gradient descent, making it easier to hack?
That's correct.
Even if it did learn microscopic physics, the knowledge wouldn't be of use for most text predictions because the input doesn't specify/determine microscopic state information. It is forced by the partially observed state to simulate at a higher level of abstraction than microphysics -- it must treat the input as probabilistic evidence for unobserved variables that affect time evolution.
See this comment for slightly more elaboration.
I strongly agree with everything you've said.
It is an age-old duality with many names and the true name is something like their intersection, or perhaps their union. I think it's unnamed, but we might be able to see it more clearly by walking around it in in words.
Simulator and simulacra personifies the simulacra and alludes to a base reality that the simulation is of.
Alternatively, we could say simulator and simulations, which personifies simulations less and refers to the totality or container of that which is simulated. I tend to use "simulations" and "...
I like this!
One thing I like about "simulators"/"simulacra" over "speculators"/"speculations" is that the former personifies simulacra over the simulator (suggests agency/personality/etc belong to simulacra) which I think is less misleading, or at least counterbalances the tendency people have to personify "GPT".
"Speculator" sounds active and agentic whereas "speculations" sounds passive and static. I think these names does not emphasize enough the role of the speculations themselves in programming the "speculator" as it creates further speculations.
You're...
If GPT means "transformers trained on next-token prediction", then GPT's true name is just that.
Things are instances of more than one true name because types are hierarchical.
GPT is a thing. GPT is an AI (a type of thing). GPT is a also ML model (a type of AI). GPT is also a simulator (a type of ML model). GPT is a generative pretrained transformer (a type of simulator). GPT-3 is a generative pretrained transformer with 175B parameters trained on a particular dataset (a type/instance of GPT).
The intention is not to rename GPT -> simulator. Things tha...
ah but if 'this program' is a simulacrum (an automaton equipped with an evolving state (prompt) & transition function (GPT), and an RNG that samples tokens from GPT's output to update the state), it is a learning machine by all functional definitions. Weights and activations both encode knowledge.
am I right to suspect that your real name starts with "A" and you created an alt just to post this comment? XD
I think this is a legitimate problem which we might not be inclined to take as seriously as we should because it sounds absurd.
Would it be a bad idea to recursively ask GPT-n "You're a misaligned agent simulated by a language model (...) if training got really cheap and this process occurred billions of times?
Yes. I think it's likely this would be a very bad idea.
...when the corpus of internet text begins to include more text generated only by simulated writers. Does this potentially degrade the ability of future language models to model agents, perform logic
Charlie's quote is an excellent description of an important crux/challenge of getting useful difficult intellectual work out of GPTs.
Despite this, I think it's possible in principle to train a GPT-like model to AGI or to solve problems at least as hard as humans can solve, for a combination of reasons:
- I think it's likely that GPTs implicitly perform search internally, to some extent, and will be able to perform more sophisticated search with scale.
- It seems possible that a sufficiently powerful GPT trained on a massive corpus of human (medical + other) k
Figuring out and posting about how RLHF and other methods ([online] decision transformer, IDA, rejection sampling, etc) modify the nature of simulators is very high priority. There's an ongoing research project at Conjecture specifically about this, which is the main reason I didn't emphasize it as a future topic in this sequence. Hopefully we'll put out a post about our preliminary theoretical and empirical findings soon.
Some interesting threads:
RL with KL penalties better seen as Bayesian inference shows that the optimal policy when you hit a GPT w...
Claude 3.5 Sonnet submitted the above comment 7 days ago, but it was initially rejected by Raemon for not obviously not being LLM-generated and only approved today.
I think that a lot (enough to be very entertaining, suggestive, etc, depending on you) can be reconstructed from the gist revision history chronicles the artifacts created and modified by the agent since the beginning of the computer use session, including the script and experiments referenced above, as well as drafts of the above comment and of its DMs to Raemon disputing the moderation decisio... (read more)